大家好,我是独孤风,大数据流动的作者。
本文基于最新的 Hadoop 3.3.6 的版本编写,带大家通过单机版充分了解 Apache Hadoop 的使用。本文更强调实践,实践是大数据学习的重要环节,也能在实践中对该技术有更深的理解,所以一些理论知识建议大家多阅读相关的书籍(都在资料包中)。
本文档版权归大数据流动所有,请勿商用,全套大数据、数据治理、人工智能相关学习资料,请关注大数据流动。
(本文所使用资料包位置: 大数据流动 VIP 知识库 》大数据技术 》Apache Hadoop 3.3.6 单机安装包)
一、Hadoop 概述
Apache Hadoop 是一个开源框架,用于存储和处理大规模数据集。它是用 Java 编写的,并支持分布式处理。Hadoop 的关键特点包括:
分布式存储:通过 Hadoop 分布式文件系统(HDFS),它可以跨多个节点存储大量数据,提供高可靠性和数据冗余。
分布式计算:Hadoop 使用 MapReduce 编程模型来并行处理大数据,这样可以有效地处理和分析存储在 HDFS 中的大规模数据集。
可扩展性:Hadoop 能够通过添加更多节点来轻松扩展,处理更大量的数据。
容错性:Hadoop 设计中考虑到了故障的可能性,能够在节点故障时继续运行,确保数据不丢失。
5. 生态系统:Hadoop 的生态系统包括各种工具和扩展(如 Hive、HBase、Spark 等),用于数据处理、分析和管理。
Hadoop 广泛应用于大数据分析、数据挖掘、日志处理等领域,特别是在需要处理 PB 级别数据的场景中非常有效。
所以我们可以理解为 Hadoop 是一个生态,有了 Hadoop 为基础,后续的 Spark,Flink 等组件才相继出现,让大数据技术持续的发展。
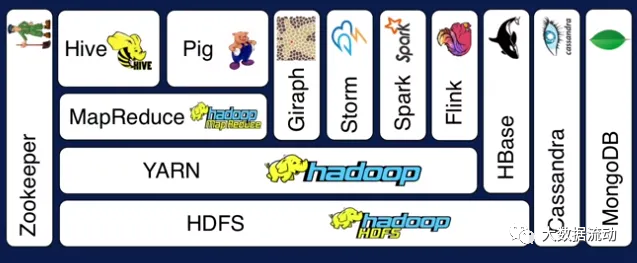
而从软件角度,Hadoop 本身自己是一个 Apache 的开源软件。

Apache Hadoop 主要由以下几个核心组件组成,每个组件都有其独特的功能:
1. Hadoop Common:这是 Hadoop 的基础库集合,提供了 Hadoop 模块所需要的通用工具和接口。它包括文件系统、操作系统级别的抽象,以及必要的 Java 库文件。
Hadoop MapReduce (MR):这是一个编程模型,用于处理大规模数据集的分布式计算。MapReduce 将作业分成两个阶段:Map(处理)和 Reduce(汇总)。这种方法使得并行处理大数据变得简单有效。
Hadoop YARN (Yet Another Resource Negotiator):YARN 是 Hadoop 的资源管理和任务调度器。它将计算资源管理和作业调度功能从 MapReduce 中分离出来,提高了 Hadoop 的灵活性和可扩展性。
Hadoop Distributed File System (HDFS):HDFS 是一个高度容错的分布式文件系统,设计用来存储大量数据。它可以在廉价的硬件上运行,提供高吞吐量以访问应用程序数据,并适用于具有大数据集的应用程序。
这些组件协同工作,使 Hadoop 成为一个强大的工具,用于存储、处理和分析大规模的数据集。

而 Common 是基础库,MapReduce 由于性能问题,分布式计算已经被更高效的 Spark,Flink 等计算引擎替代。
但是HDFS,YARN依然是最核心的两个组件,一定要认真学习,我也会单独发文章来学习这两个组件。




二、Hadoop 历史
当然,以下是用 Markdown 格式概述 Apache Hadoop 的历史:
2005 年 - 起源由 Doug Cutting 和 Mike Cafarella 创立,受 Google 的 MapReduce 和 GFS 论文启发。
(Google 三篇理论中文版资料位置: 大数据流动 VIP 知识库 》大数据技术 》Google 三家马车)
2006 年 - 加入Apache成为 Apache 软件基金会的一部分,最初是 Lucene 项目的一部分,后来在 2008 年成为顶级项目。
2008 年及以后 - 发展与普及快速获得关注,生态系统不断发展,增加了如 HBase、Hive 等工具。
2011 年 - Hadoop 1.0 发布标志着 Hadoop 的成熟,稳定 API 和核心组件,包括 HDFS 和 MapReduce。
2013 年 - Hadoop 2.0 和YARN的推出引入 YARN,将 Hadoop 从以 MapReduce 为中心的平台转变为更加多功能的数据处理平台。
持续演进 - Hadoop 不断更新,扩展其功能和生态系统,包括 Spark、Kafka、Flink 等工具。
云集成 - 近年来,与云服务集成,提供更灵活、可扩展的数据处理解决方案。
Hadoop 也不光只有 Apache Hadoop,很多公司都有自己的发行版本,不同的发行版针对不同的用途和场景进行了优化,用户可以根据自己的需求选择最适合的版本。随着时间的推移,这些发行版可能会有所变化,包括新的版本推出或旧版本停止维护。
除了 Apache Hadoop,还有 Cloudera 的 CDH(Cloudera Distribution Including Apache Hadoop)、Hortonworks Data Platform (HDP),也就是 CDH 和 Ambari,我也会在其他文章演示,本文我们带来 Apache Hadoop 的单机版本演示,Apache Hadoop 也是被使用最多的版本。
三、Hadoop 3.3.6 单机安装
下面我们进行 Hadoop3.3.6 的单机版安装。
1、版本情况与安装包准备
Apache Hadoop 的官网地址是 https://hadoop.apache.org/
我们在这里可以看到,最新的版本是 3.3.6,这也是 2023 年新发布的版本,各方面都做了很大的优化,本文也基于此版本进行演示。
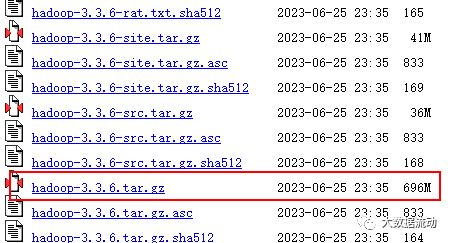
我们使用的 Hadoop 版本是 3.3.6,可以在官方网站进行下载:
https://archive.apache.org/dist/hadoop/common/hadoop-3.3.6/
696MB 这个。
2、服务器环境准备
不管是服务器和虚拟机环境的准备,大家都可以参考我之前的文章,在本地搭一个虚拟机,也可以去买一个现成的,这里不做赘述。
我们使用的 CentOS 版本是 7.8,可以通过下面的命令来查看版本。
cat /etc/redhat-release

CentOS7 的安装步骤基本一致,都可以参考本文档。
服务器需要做一下免密登陆设置,不然后面会有问题
ssh-keygen -t rsa -P ""回车即可,随后复制密钥
cat ~/.ssh/id_rsa.pub > ~/.ssh/authorized_keys可以验证一下
ssh bigdataflowing正常会直接登录过去。
3、JDK 安装
先卸载系统自带的 java
rpm -qa | grep -i java | xargs -n1 rpm -e --nodeps
上传安装包到服务器,安装包可在 Oracle 官网下载:https://www.oracle.com/java/technologies/downloads/
也可以用我的资料包里的。
jdk-8u221-linux-x64.tar.gz
建立文件夹。
mkdir /opt/jdk/
进入该文件夹,上传文件。
cd /opt/jdk/
解压安装包 tar -zxvf jdk-8u221-linux-x64.tar.gz
没有报错证明解压成功。
随后我们把 JDK 配置到环境变量里就可以了。
vi /etc/profile
在最下面加入这两句,其实就是我们刚刚解压 jdk 的位置。
export JAVA_HOME=/opt/jdk/jdk1.8.0_221
export PATH=$PATH:$JAVA_HOME/bin
最后让环境变量生效
source /etc/profile
查看 java 版本验证一下,java -version 成功!

这样我们这台机器就有 java 环境可用了。
4、Hadoop3.3.6 安装
有了 java 环境,hadoop 的依赖问题就解决了,可以直接进行安装。
将之前准备好的 hadoop 安装包,上传到 /opt/hadoop3.3.6 目录下
解压,tar -zxvf hadoop-3.3.6.tar.gz 没报错就是成功。
还是增加环境变量
vi /etc/profile
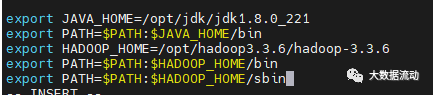
在最下面加入这三句,hadoop 的位置
export HADOOP_HOME=/opt/hadoop3.3.6/hadoop-3.3. 6
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
最后让环境变量生效
source /etc/profile
查看 java 版本验证一下,hadoop-version 成功!
使用 hadoop version 命令验证安装成功

5、配置
虽然安装成功,但是我们要使用的是单机伪集群,还需要进行一些配置。
hadoop 的目录有如下的文件夹
bin 目录:Hadoop 主服务脚本
etc 目录:Hadoop 的配置文件目录
lib 目录:存放 Hadoop 的本地库
sbin 目录:存放启动或停止 Hadoop 相关服务的脚本
首先进入 etc 配置文件夹 cd ``etc/hadoop 有如下配置,我们只修改核心的就可以。
首先修改 hadoop-env.sh 将 java 和 hadoop 的根路径加入
export JAVA_HOME=/opt/jdk/jdk1.8.0_221
export HADOOP_HOME=/opt/hadoop3.3.6/hadoop-3.3.6
同时加入 root 权限
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root修改 core-site.xml
在 configuration 标签中,添加如下内容:
<property>
<name>fs.defaultFS</name>
<value>hdfs://bigdataflowing:9090</value>
</property>
<!-- 指定 hadoop 数据的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop3.3.6/hdfs/tmp</value>
</property>
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>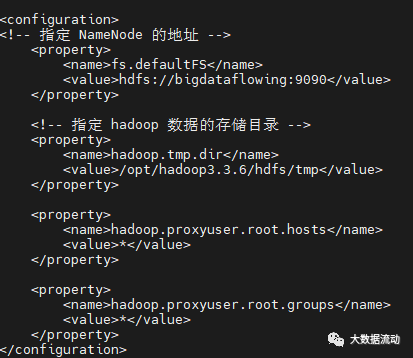
修改 hdfs-site.xml,在 configuration 标签中,添加如下内容:
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/opt/hadoop3.3.6/hdfs/name</value>
<final>true</final>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/opt/hadoop3.3.6/hdfs/data</value>
<final>true</final>
</property>
<property>
<name>dfs.http.address</name>
<value>0.0.0.0:50070</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>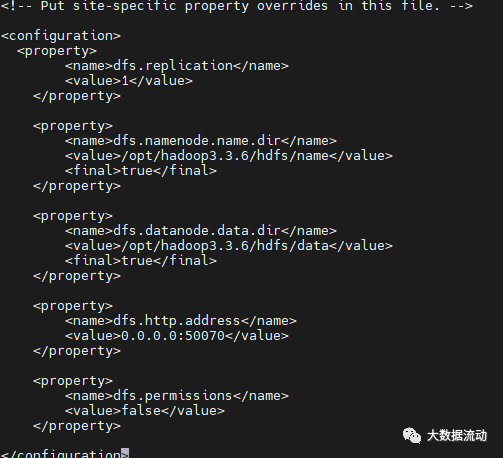
修改 mapre-site.xml,在 configuration 标签中,添加如下内容:
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>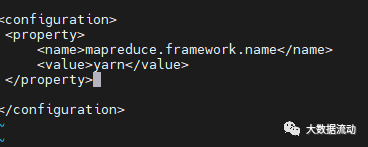
修改 yarn-site.xml,在 configuration 标签中,添加如下内容:
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>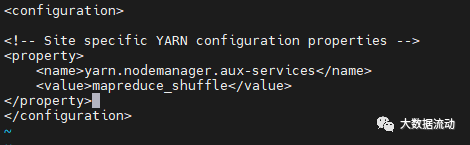
6、启动
首先格式化 HDFS,也就是对 hdfs 做最基本的配置:
hdfs namenode -format
格式化完成。
随后我们进入 sbin 目录
cd /opt/hadoop3.3.6/hadoop-3.3.6/sbin/
这里脚本较多,我们可以选择启动全部
./start-all.sh
正常不会有报错,同时使用 jps 命令查看,会有 Datanode,ResourceManager,SecondaryNameNode,NameNode,NodeManager 五个进程。
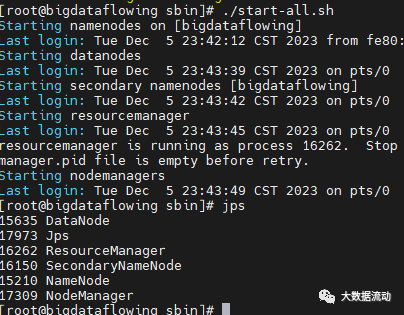
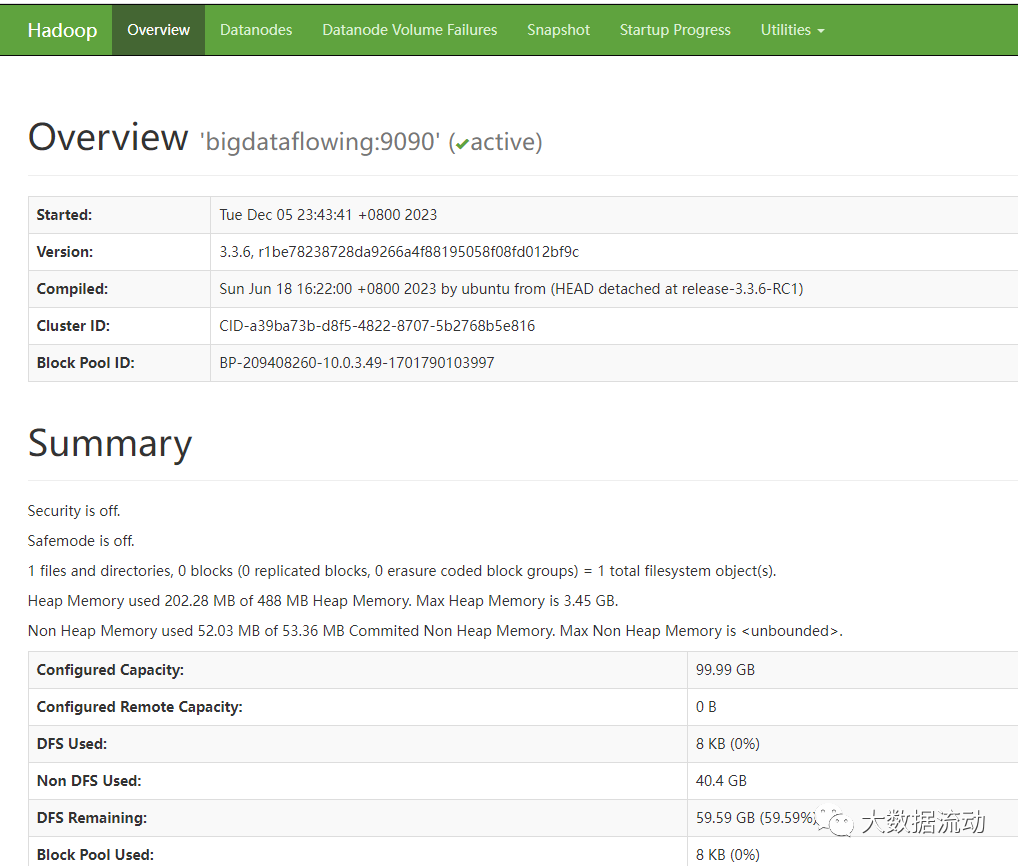
另一个验证启动成功的方法,是访问 Hadoop 管理页面
http://IP:50070/
http://IP:8088/
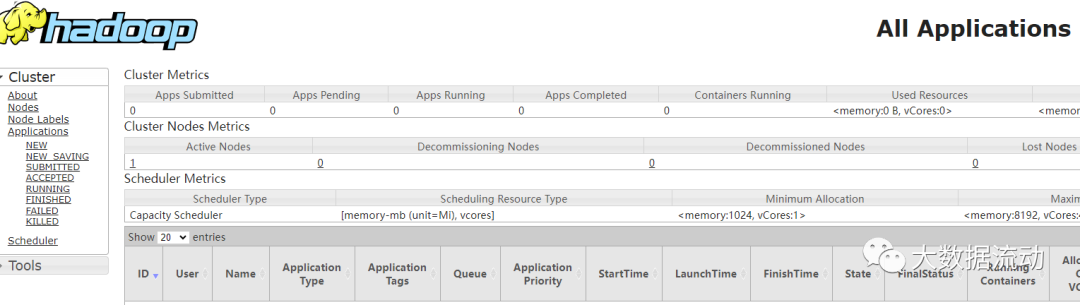
这些页面的使用,我们会在后续 Hdfs,Yarn 等章节再详细讲解。
7、报错汇总
启动报错,未设置 root 用户
ERROR: but there is no HDFS_NAMENODE_USER defined. Aborting operation.
Starting datanodes
ERROR: Attempting to operate on hdfs datanode as root
ERROR: but there is no HDFS_DATANODE_USER defined. Aborting operation.
Starting secondary namenodes [bigdataflowing]
ERROR: Attempting to operate on hdfs secondarynamenode as root
ERROR: but there is no HDFS_SECONDARYNAMENODE_USER defined. Aborting operation.
Starting resourcemanager
ERROR: Attempting to operate on yarn resourcemanager as root
ERROR: but there is no YARN_RESOURCEMANAGER_USER defined. Aborting operation.
Starting nodemanagers
ERROR: Attempting to operate on yarn nodemanager as root
ERROR: but there is no YARN_NODEMANAGER_USER defined. Aborting operation。启动报错,为进行免密登陆设置
localhost: Permission denied (publickey,password更多【大数据、数据治理、人工智能知识分享】【开源项目推荐】【学习社群加入】,请关注大数据流动。