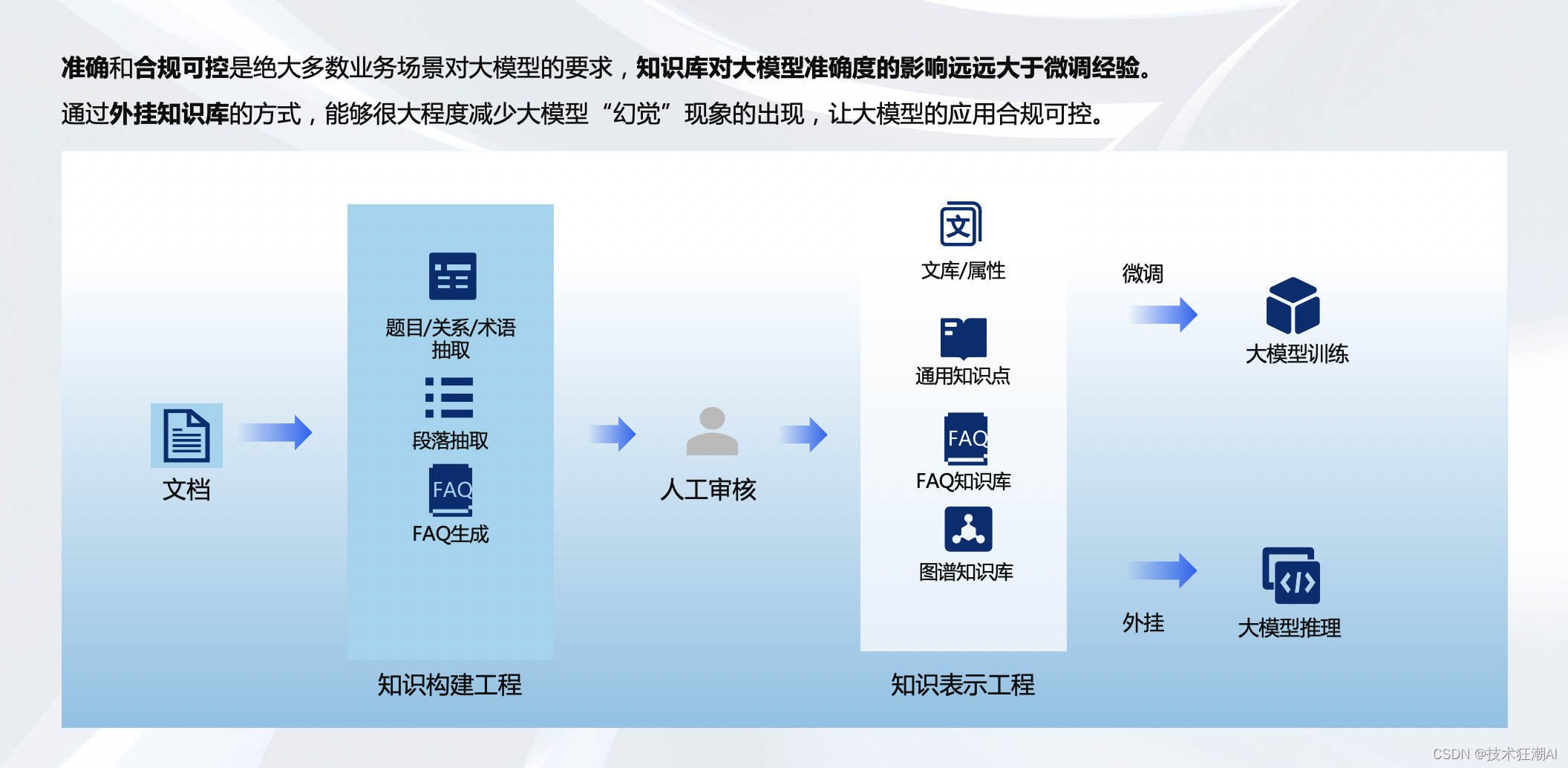
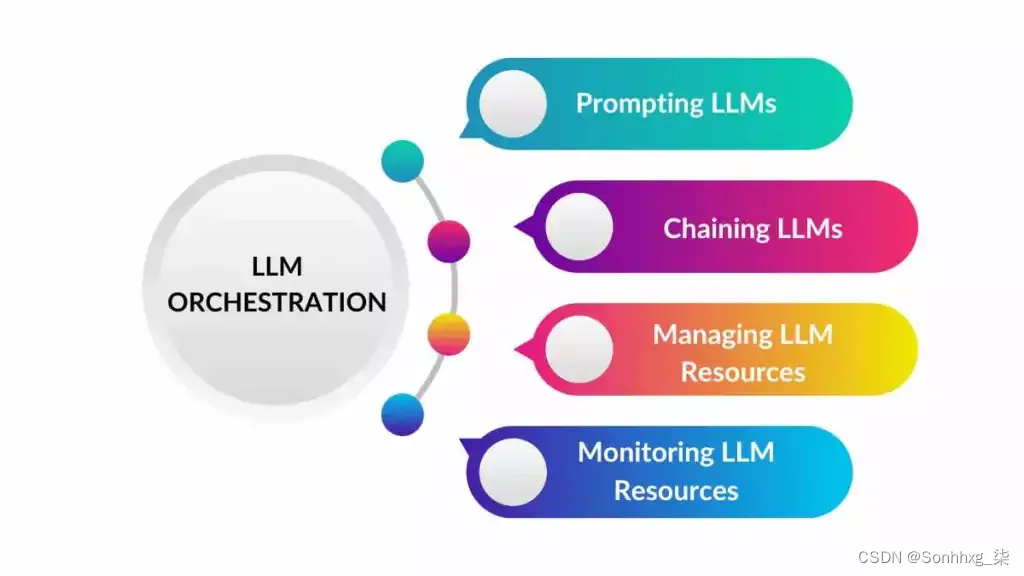
class Node :
def __init__ ( self, root= True , label= None , feature_name= None , feature= None ) :
self. root = root
self. label = label
self. feature_name = feature_name
self. feature = feature
self. tree = { }
self. result = {
'label:' : self. label,
'feature' : self. feature,
'tree' : self. tree
}
def __repr__ ( self) :
return '{}' . format ( self. result)
def add_node ( self, val, node) :
self. tree[ val] = node
def predict ( self, features) :
if self. root is True :
return self. label
return self. tree[ features[ self. feature] ] . predict( features)
class DTree :
def __init__ ( self, epsilon= 0.1 ) :
self. epsilon = epsilon
self. _tree = { }
@staticmethod
def calc_ent ( datasets) :
data_length = len ( datasets)
label_count = { }
for i in range ( data_length) :
label = datasets[ i] [ - 1 ]
if label not in label_count:
label_count[ label] = 0
label_count[ label] += 1
ent = - sum ( [ ( p / data_length) * log( p / data_length, 2 )
for p in label_count. values( ) ] )
return ent
def cond_ent ( self, datasets, axis= 0 ) :
data_length = len ( datasets)
feature_sets = { }
for i in range ( data_length) :
feature = datasets[ i] [ axis]
if feature not in feature_sets:
feature_sets[ feature] = [ ]
feature_sets[ feature] . append( datasets[ i] )
cond_ent = sum ( [ ( len ( p) / data_length) * self. calc_ent( p)
for p in feature_sets. values( ) ] )
return cond_ent
@staticmethod
def info_gain ( ent, cond_ent) :
return ent - cond_ent
def info_gain_train ( self, datasets) :
count = len ( datasets[ 0 ] ) - 1
ent = self. calc_ent( datasets)
best_feature = [ ]
for c in range ( count) :
c_info_gain = self. info_gain( ent, self. cond_ent( datasets, axis= c) )
best_feature. append( ( c, c_info_gain) )
best_ = max ( best_feature, key= lambda x: x[ - 1 ] )
return best_
def train ( self, train_data) :
"""
input:数据集D(DataFrame格式),特征集A,阈值eta
output:决策树T
"""
_, y_train, features = train_data. iloc[ : , :
- 1 ] , train_data. iloc[ : ,
- 1 ] , train_data. columns[ :
- 1 ]
if len ( y_train. value_counts( ) ) == 1 :
return Node( root= True , label= y_train. iloc[ 0 ] )
if len ( features) == 0 :
return Node(
root= True ,
label= y_train. value_counts( ) . sort_values(
ascending= False ) . index[ 0 ] )
max_feature, max_info_gain = self. info_gain_train( np. array( train_data) )
max_feature_name = features[ max_feature]
if max_info_gain < self. epsilon:
return Node(
root= True ,
label= y_train. value_counts( ) . sort_values(
ascending= False ) . index[ 0 ] )
node_tree = Node(
root= False , feature_name= max_feature_name, feature= max_feature)
feature_list = train_data[ max_feature_name] . value_counts( ) . index
for f in feature_list:
sub_train_df = train_data. loc[ train_data[ max_feature_name] ==
f] . drop( [ max_feature_name] , axis= 1 )
sub_tree = self. train( sub_train_df)
node_tree. add_node( f, sub_tree)
return node_tree
def fit ( self, train_data) :
self. _tree = self. train( train_data)
return self. _tree
def predict ( self, X_test) :
return self. _tree. predict( X_test)
import numpy as np
import pandas as pd
import math
from math import log
import pandas as pd
def create_data ( ) :
datasets = [ [ '青年' , '否' , '否' , '一般' , '否' ] ,
[ '青年' , '否' , '否' , '好' , '否' ] ,
[ '青年' , '是' , '否' , '好' , '是' ] ,
[ '青年' , '是' , '是' , '一般' , '是' ] ,
[ '青年' , '否' , '否' , '一般' , '否' ] ,
[ '中年' , '否' , '否' , '一般' , '否' ] ,
[ '中年' , '否' , '否' , '好' , '否' ] ,
[ '中年' , '是' , '是' , '好' , '是' ] ,
[ '中年' , '否' , '是' , '非常好' , '是' ] ,
[ '中年' , '否' , '是' , '非常好' , '是' ] ,
[ '老年' , '否' , '是' , '非常好' , '是' ] ,
[ '老年' , '否' , '是' , '好' , '是' ] ,
[ '老年' , '是' , '否' , '好' , '是' ] ,
[ '老年' , '是' , '否' , '非常好' , '是' ] ,
[ '老年' , '否' , '否' , '一般' , '否' ] ,
]
labels = [ u'年龄' , u'有工作' , u'有自己的房子' , u'信贷情况' , u'类别' ]
return datasets, labels
datasets, labels = create_data( )
train_data = pd. DataFrame( datasets, columns= labels)
datasets, labels = create_data( )
data_df = pd. DataFrame( datasets, columns= labels)
dt = DTree( )
tree = dt. fit( data_df)
tree
dt. predict( [ '老年' , '否' , '否' , '一般' ] )