Online Decision Based Visual Tracking via Reinforcement Learning
概述
本文2020年发布于NeurIPS(CCF-A)。视觉跟踪通常基于目标检测或者模板区配,但它们都只适用于特定的场景或对象。因为它们遵循不同的跟踪原则,直接将它们融合在一起是不明智的。
本文主要提出了一种新的视觉跟踪集成框架DTNet,它基于层次强化学习(HRL)的决策机制。该框架提供了一个基于规则的动态转换策略,其中探测和模板跟踪器必须相互竞争来决定使用谁来跟踪。此外,提出了一个新的检测追踪器,它可以避免错误建议的普遍问题(不需要建议目标的候选边界框,从而使识别过程灵活)。实验结果表明,DTNet达到了最先进的跟踪性能,并且实现了性能和效率之间的平衡。
方法
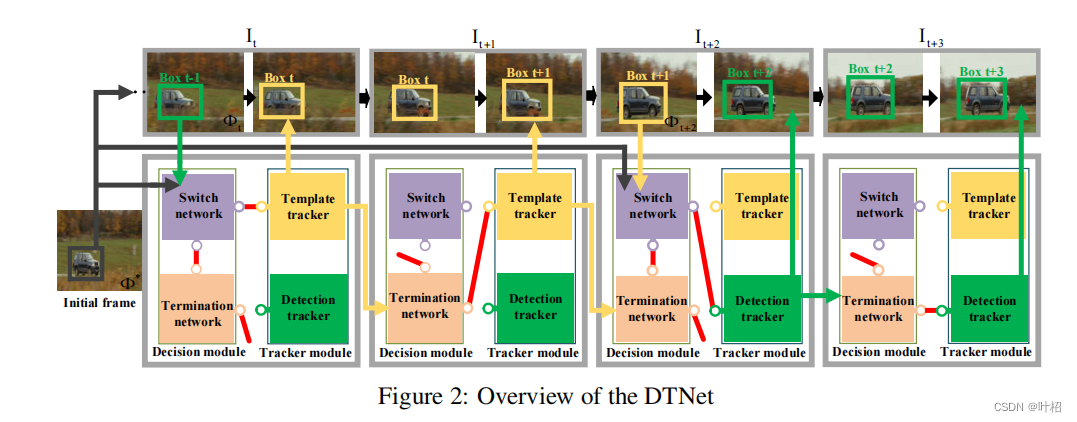
与融合方法不同,DTNet学习如何自动切换两种tracker适用于不同场景。该框架包含两个模块: decision module 和 tracker module。
-
decision module
- switch network:编码继承自前一帧 I t − 1 I_{t-1} It−1的 image patch Φ t \Phi_t Φt 和初始模板 Φ ∗ \Phi^* Φ∗,然后输出一个二进制信号选择tracker,该tracker从当前帧 I t I_t It中估计目标的位置。
- termination network:估计tracker的输出,并决定是继续使用当前tracker还是终止该tracker(这使得 decision module 不会在两个tracker之间振荡)。如果决定终止,只能证明当前tracker性能不是很好而不能证明另一个tracker性能更好,此时使用switch network从两个tracker中选择一个。
马尔可夫选择 w ∈ Ω w\in \Omega w∈Ω由三部分组成:intra-option策略 π : S × A → [ 0 , 1 ] \pi:S \times A →[0,1] π:S×A→[0,1],终止条件 β : S + → [ 0 , 1 ] \beta:S^+ → [0,1] β:S+→[0,1],初始集合 I ⊆ S I ⊆ S I⊆S。若采取 w w w,根据 π w \pi_w πw选择动作,直到 w w w根据 β w \beta_w βw终止。
Q Ω Q_\Omega QΩ表示switch network,可以被看做一个服从带网络权重 θ \theta θ和终止网络 β Ω , v \beta_{\Omega,v} βΩ,v的 Ω \Omega Ω的函数。决定当前tracker是否被终止的终止概率是由 β Ω , v \beta_{\Omega,v} βΩ,v根据选择 Ω \Omega Ω和其网络权重 v v v估计。将 Q Ω Q_\Omega QΩ定义如下,用HRL的方法评估option w w w的值:
Q Ω ( s , w ; θ ) = r ( s , w ) + λ U ( s ′ , w ) Q_\Omega(s,w;\theta)=r(s,w)+\lambda U(s^{'},w) QΩ(s,w;θ)=r(s,w)+λU(s′,w)
r ( s , w ) r(s,w) r(s,w)表示agent在采取 w w w,选择一个特定tracker后收到的奖励。 U ( s ′ , w ) U(s',w) U(s′,w)是在与终止概率 β w , v \beta_{w,v} βw,v相关的新状态 s ′ s' s′执行 w w w的值,通过结合switch和termination network输出的值来计算:
U ( s ′ , w ) = ( 1 − β w , ν ( s ′ ) ) Q Ω ( s ′ , w ) + β w , ν ( s ′ ) V Ω ( s ′ ) U(s',w)= (1 − β_{w,ν}(s'))Q_Ω(s', w) + β_{w,ν}(s')V_Ω(s') U(s′,w)=(1−βw,ν(s′))QΩ(s′,w)+βw,ν(s′)VΩ(s′)
β w , ν ( s ′ ) β_{w,ν}(s') βw,ν(s′)是在状态 s ′ s' s′的终止概率, V Ω V_\Omega VΩ是switch函数的最优解,它可以通过在option w w w上搜索switch函数 Q Ω Q_\Omega QΩ的最大值来得到:
V Ω = max w ( Q Ω ( s ′ , w ) ) V_\Omega=\max_w(Q_\Omega(s',w)) VΩ=wmax(QΩ(s′,w))
如果当前的option表现为 w g o o d w_{good} wgood,即 β w , ν β_{w,ν} βw,ν趋近于0, U ( s ′ , w g o o d ) ≈ Q Ω ( s ′ , w g o o d ) U(s',w_{good})≈Q_Ω(s', w_{good}) U(s′,wgood)≈QΩ(s′,wgood),反之, β w , ν β_{w,ν} βw,ν趋近于1,根据 V Ω = ( Q Ω ( s ′ , w g o o d ) ) V_\Omega=(Q_\Omega(s',w_{good})) VΩ=(QΩ(s′,wgood)),仍有 U ( s ′ , w g o o d ) ≈ Q Ω ( s ′ , w g o o d ) U(s',w_{good})≈Q_Ω(s', w_{good}) U(s′,wgood)≈QΩ(s′,wgood)。 U ( s , w ) U(s,w) U(s,w)是可微的,其关于termination network的权值 v v v的梯度表示为:
∂ U ( s ′ , w ) ∂ v = − ∂ β w , v ( s ′ ) ∂ v ( Q Ω ( s ′ , w ) − V Ω ( s ′ ) ) + ( 1 − β w , v ( s ′ ) ) ∂ U ( s ′ ′ , w ′ ) ∂ v \frac{\partial U(s',w)}{\partial v}=-\frac{\partial \beta_{w,v}(s')}{\partial v}(Q_\Omega(s',w)-V_{\Omega}(s'))+(1-\beta_{w,v}(s'))\frac{\partial U(s'',w')}{\partial v} ∂v∂U(s′,w)=−∂v∂βw,v(s′)(QΩ(s′,w)−VΩ(s′))+(1−βw,v(s′))∂v∂U(s′′,w′)
switch network Q Ω ( s , w ) Q_Ω(s, w) QΩ(s,w)作为"Critic"评估option的值,并且为 termination network β w , v \beta_{w,v} βw,v提供更新梯度, termination network 本质上作为"Actor",并且评估正在使用的tracker的性能以决定是否在当前帧终止它。switch network 的权重 θ \theta θ通过贝尔曼公式学习。
- Tracker Module
-
Template tracker:使用 SiamFC作为Template tracker,标准的暹罗架构以一个包含一个范例图像 z z z和一个候选图像 x x x的图像对作为输入。
- tips: Siamese network(https://zhuanlan.zhihu.com/p/35040994)
z z z表示感兴趣的目标,而 x x x通常更大,表示后续视频帧的搜索区域。 x x x和 z z z的特征由相同的 τ \tau τ参数化的 C N N φ CNN\ \varphi CNN φ提取:
f τ ( z , x ) = φ τ ( z ) ⋆ φ τ ( x ) + b f_{\tau}(z,x)=\varphi_\tau(z)\star\varphi_\tau(x)+b fτ(z,x)=φτ(z)⋆φτ(x)+b
⋆ \star ⋆表示卷积操作。该公式在 x x x上对 z z z进行了穷举搜索,目标是将响应映射 f f f中的最大值区配到目标位置。 -
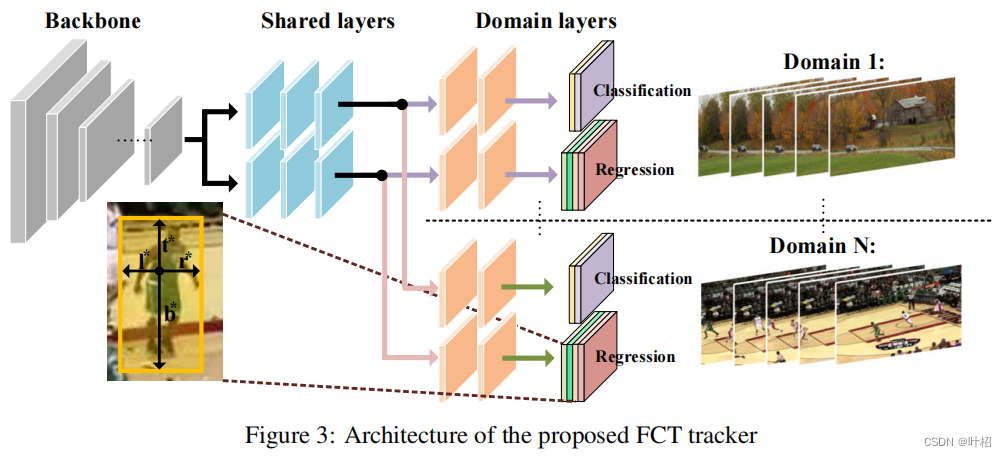
Detection tracker:为了构建一个基于目标检测的跟踪器,同时避免昂贵的提案生成过程,采用了一个全卷积tracker——FCT,包括一个分类分支和一个回归分支。分类分支预测目标位置,回归分支预测一个4D向量,表示从目标中心到其边界框的边缘的距离。
给定主干CNN的特征映射 F ∈ R H × W × C F\in R^{H×W×C} F∈RH×W×C和在前一层中应用的所有步长的和 s s s, F F F中的每个位置 ( x , y ) (x,y) (x,y)对应于图中的每个位置 ( ⌊ s 2 ⌋ + x s , ⌊ s 2 ⌋ + y s ) (\lfloor\frac{s}{2}\rfloor+xs,\lfloor\frac{s}{2}\rfloor+ys) (⌊2s⌋+xs,⌊2s⌋+ys),直接预测F每个位置的类标签和回归距离。
同一类object有可能被认为是一个序列的目标,但是另一个序列的背景,因此不能简单地使用传统分类器分配给目标‘1’或者‘0’。提出的分类branch,在每个域中,如果位置 ( x , y ) (x,y) (x,y)落在groundtruth box,类标签 c ∗ c^* c∗分配为‘1’,被视为正样本,否则类标签被分配为‘0’,视为负样本。
回归分支输出一个4D矢量 r e ∗ = ( l ∗ , t ∗ , r ∗ , b ∗ ) re^*=(l^*,t^*,r^*,b^*) re∗=(l∗,t∗,r∗,b∗),表示从目标的位置到边界框四个边界的距离(如图3)。跟踪器最终输出的分类得分映射 c c c和回归值 r e re re,训练损失函数如下所示:
L ( c , r ) = 1 N ∑ i = 1 N L c l s ( c i , c i ∗ ) + λ N [ W h e r e c ∗ > 0 ] ∑ i = 1 N L r e g ( r e i , r e i ∗ ) L(c,r)=\frac{1}{N}\sum^N_{i=1}L_{cls}(c_i,c^*_i)+\frac{\lambda}{N}[Where{c^*>0}]\sum^N_{i=1}L_{reg}(re_i,re^*_i) L(c,r)=N1i=1∑NLcls(ci,ci∗)+Nλ[Wherec∗>0]i=1∑NLreg(rei,rei∗)
N表示用来训练的视频帧的总数。
-
训练
给定
K
K
K个训练序列,对第
j
j
j个随机提取一条训练序列
I
j
=
{
I
1
j
,
I
2
j
,
.
.
.
,
I
T
j
}
I_j=\{I_{1j},I_{2j},...,I_{Tj}\}
Ij={I1j,I2j,...,ITj}依次对应ground truth
G
j
=
{
G
1
j
,
G
2
j
,
.
.
.
,
G
T
j
}
G_j=\{G_{1j},G_{2j},...,G_{Tj}\}
Gj={G1j,G2j,...,GTj},每对相邻的帧以一定概率跳过
n
n
n帧
(
0
≤
n
≤
5
)
(0≤n≤5)
(0≤n≤5)。初始目标在第一帧的ground truth附近随机采样并作为模板,switch network有选择地评估模板编码的特征,观察结果继承自前一帧,并且选择一个tracker。switch过程中奖励如下:
r
t
(
s
,
w
)
=
{
η
L
⋅
D
I
o
U
,
I
F
(
P
t
>
t
h
h
i
a
n
d
P
t
∗
<
t
h
e
l
o
)
η
L
⋅
D
I
o
U
,
I
F
(
P
t
<
t
h
h
i
a
n
d
P
t
∗
>
t
h
e
l
o
)
η
M
⋅
D
I
o
U
,
I
F
(
P
t
>
t
h
h
i
a
n
d
P
t
∗
>
t
h
e
l
o
)
η
S
⋅
D
I
o
U
,
I
F
(
P
t
<
t
h
h
i
a
n
d
P
t
∗
<
t
h
e
l
o
)
r_t(s,w)=\begin{cases}\eta_L·D_{IoU},IF(P_t>th_{hi}\ and\ P^*_t<the_{lo})\\ \eta_L·D_{IoU},IF(P_t<th_{hi}\ and\ P^*_t>the_{lo})\\ \eta_M·D_{IoU},IF(P_t>th_{hi}\ and\ P^*_t>the_{lo})\\ \eta_S·D_{IoU},IF(P_t<th_{hi}\ and\ P^*_t<the_{lo})\\ \end{cases}
rt(s,w)=⎩
⎨
⎧ηL⋅DIoU,IF(Pt>thhi and Pt∗<thelo)ηL⋅DIoU,IF(Pt<thhi and Pt∗>thelo)ηM⋅DIoU,IF(Pt>thhi and Pt∗>thelo)ηS⋅DIoU,IF(Pt<thhi and Pt∗<thelo)
(如下图所示)
P
t
P_t
Pt是所选tracker的预测边界框与ground truth
G
t
G_t
Gt和
P
t
∗
P^*_t
Pt∗之间的
I
o
U
IoU
IoU,
P
t
∗
P^*_t
Pt∗是未选tracker对应的
I
o
U
IoU
IoU,
D
I
o
U
D_{IoU}
DIoU是它们之间的差值。有三种情况:(1)一个成功一个失败;(2)两个都成功;(3)两个都失败。三个较大的系数降序分配,在指导跟踪竞争的同时选择具有更高精度的agent,这些样本由未被选择的tracker依次采集以更新相应的网络。也就是,继续训练更糟的那个来保证两个tracker的竞争。新状态
s
′
s'
s′由当前帧的预测更新,然后agent以
β
w
,
v
(
s
′
)
\beta_{w,v}(s')
βw,v(s′)的概率终止前一个option并且重新评估option的价值。
对switch module,‘Critic’ model
Q
Ω
(
s
,
w
)
Q_\Omega(s,w)
QΩ(s,w)可以通过贝尔曼公式学习,学习过程通过最小化如下损失实现:
L
=
1
N
∑
i
=
1
N
(
y
i
−
Q
Ω
(
s
i
,
w
i
;
θ
)
)
2
L=\frac{1}{N}\sum^N_{i=1}(y_i-Q_\Omega(s_i,w_i;\theta))^2
L=N1i=1∑N(yi−QΩ(si,wi;θ))2
其中
y
i
=
r
(
s
i
,
w
i
)
+
γ
(
1
−
β
w
i
,
v
(
s
i
′
)
Q
Ω
(
s
i
′
,
w
i
)
)
+
β
w
i
,
v
(
s
i
′
)
V
Ω
(
s
i
′
)
y_i=r(s_i,w_i)+\gamma(1-\beta_{w_i,v}(s_i')Q_\Omega(s_i',w_i))+\beta_{w_i,v}(s_i')V_\Omega(s_i')
yi=r(si,wi)+γ(1−βwi,v(si′)QΩ(si′,wi))+βwi,v(si′)VΩ(si′)。’Actor‘ module
β
w
,
v
\beta_{w,v}
βw,v更新如下:
v
=
v
−
α
v
∂
β
w
,
v
(
s
′
)
∂
v
(
Q
Ω
(
s
′
,
w
)
−
V
Ω
(
s
′
)
)
v=v-\alpha_v\frac{\partial\beta_{w,v}(s')}{\partial v}(Q_\Omega(s',w)-V_\Omega(s'))
v=v−αv∂v∂βw,v(s′)(QΩ(s′,w)−VΩ(s′))