文章目录
- 开场白
- 基本组件
- 搞事情从来不是一帆风顺
- 复旦方案分支
- 回归主线
开场白
-
老样子先说一下为什么我会看到这篇文章。答案是“自动标注”。
-
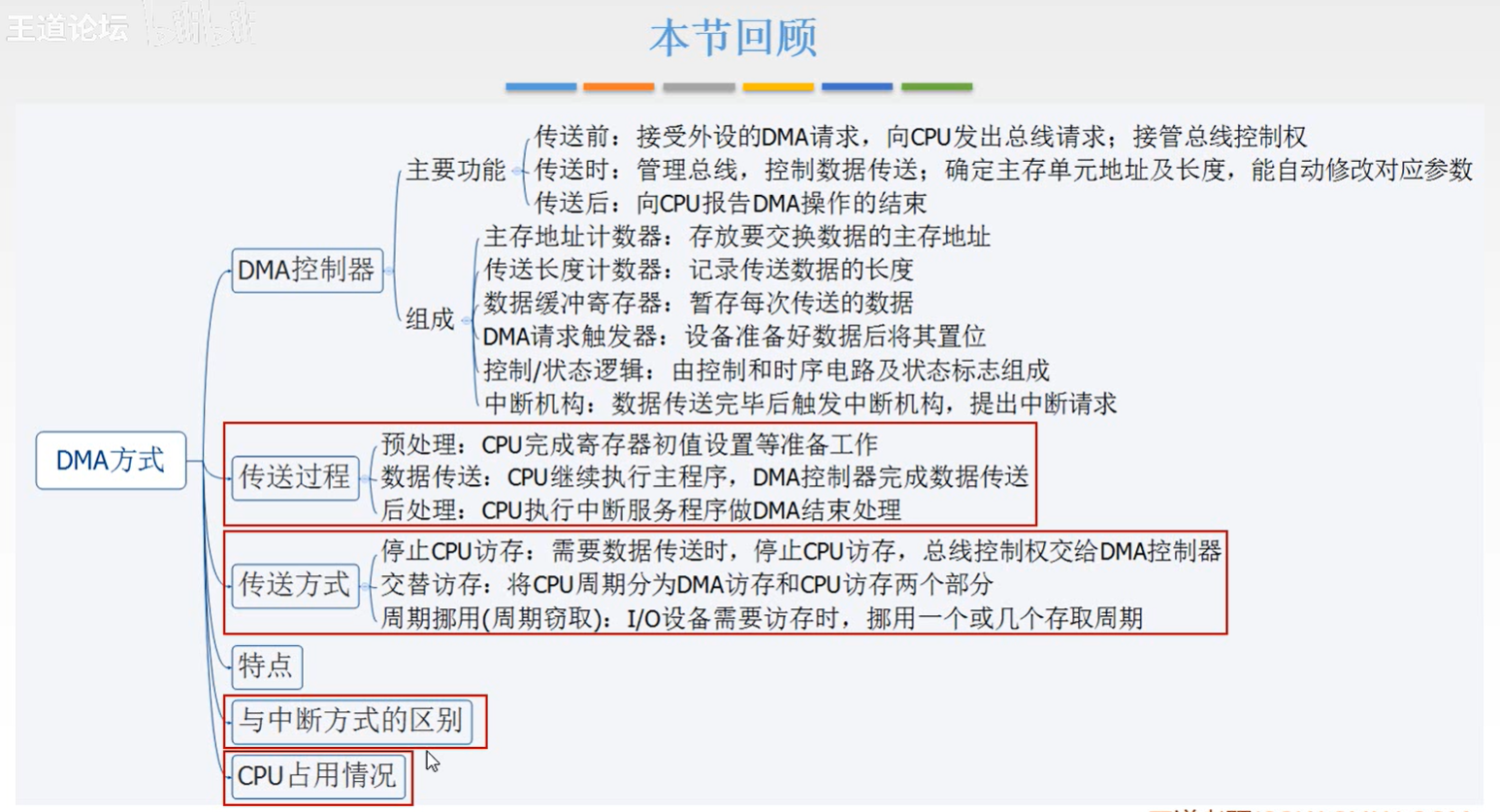
这个事情是这样,自动驾驶不光需要做目标检测任务也需要语义分割的信息给到后处理。当然现在做自动驾驶都在往BEV方案上靠了,但是传统的后融合方案还是有在做的。所以我们需要对一些目标检测和语义分割模型进行训练,就我知道的几家公司还是用yolo5或者其他版本,主要还是yolo,transformer当然也在搞。要训练神经网络就需要对训练的数据进行标注但是标注成本实在是太高了,对大公司来说直接劳动力密集型覆盖当然没什么问题,但是中小公司标注还是很慢的没法满足训练快速迭代的需要,所以就有了自动标注。我们用一个专门用来做语义分割的超大模型对现有标注好的数据进行训练,再用它对未标注数据进行预测生产伪标注。这个预测要求结果尽可能真实,最好和人工标注相差无异,理想是美好的,现实其实稍微差一点也可以接受。用人工标注的真实标签和大模型生成的伪标签来训练一个可以在车上跑的小模型,有提升就可以了。
-
然后恰好,前段时间的分割一切(segment anything)的模型出来以后非常热,那我们当然也要搞一搞。然后不出意外就会遇到很多问题。比如prompt怎么给,分割效果怎么样,怎么才能将模型特性和我们的需求比较好的结合等等。
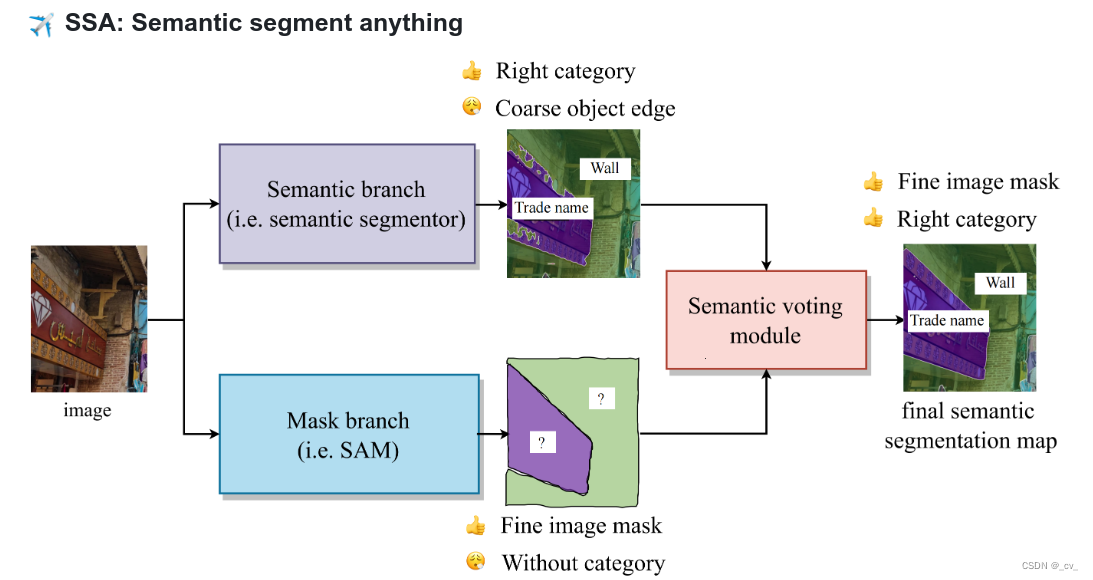
基本组件
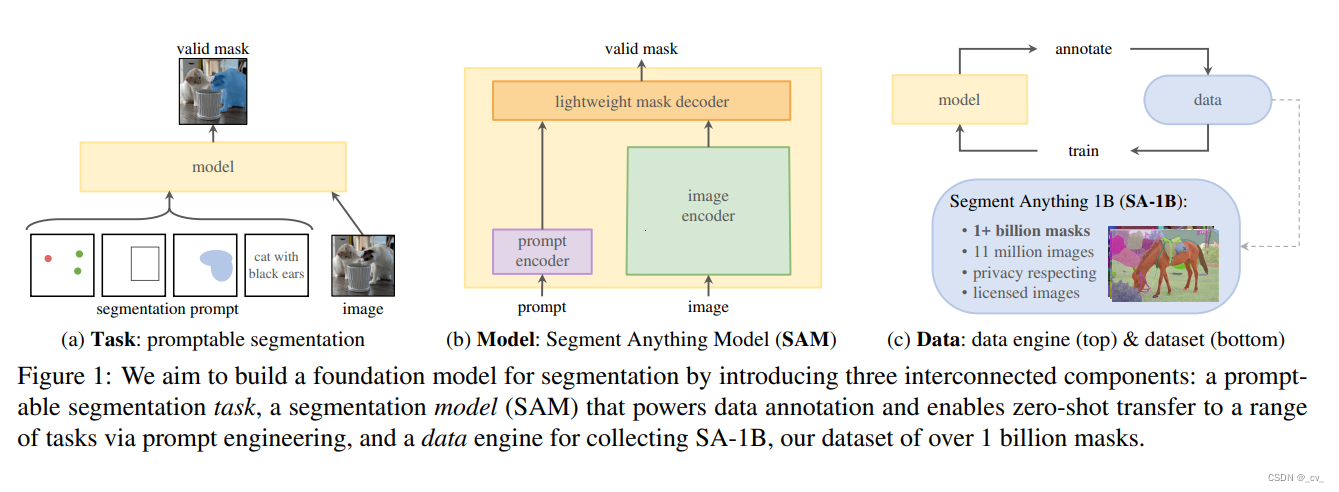
https://arxiv.org/pdf/2304.02643.pdf 这文章并不是说做了一个什么样的模型,而是一个项目,如上图C,通过标注数据,训练模型,然后又通过模型生成标注数据,不断迭代。最后的成果模型是一方面,另外还有一个数据集。后面模型,数据,都会单独出来讲。这篇主要说一下在搞SAM的过程中遇到的坑。
搞事情从来不是一帆风顺
首先,如果要搞自动标注要面对的第一个问题是,SAM的输出结果并没有语义信息,这是最要紧的,当然我花了一些时间去找paper看别人是怎么做的。稍微放出来一些;
- https://github.com/Curt-Park/segment-anything-with-clip .走sam加clip路线,在sam的文章里面有说prompt可以给文本信息,但是并没有把代码放出来不过还是有人做了尝试
- https://github.com/fudan-zvg/Semantic-Segment-Anything ,复旦的语义sam,但也只是一个demo
OK。路线有了现在就是走哪一条的问题,基于我现有的资源和个人技能,选择第二条。
我们有现成的语义分割模型,虽然训练数据不够效果差一些,但是做为语义来赋值应该还是可以的。
复旦方案分支
说到这了那就顺便来看一下这个投票模块。下面就是所谓“Semantic voting module",原理很简单,先对mask面积进行排序,然后遍历mask为有效值取出语义部分,如果语义部分只有一类那就赋值类别,如果不是那就按mask对应面积的最大语义来赋值,精髓torch.bincount(propose_classes_ids.flatten()).topk(1).indices
没什么好说的。oneformer,segformer后面有空再说。
def semantic_segment_anything_inference(filename, output_path, rank, img=None, save_img=False,
semantic_branch_processor=None,
semantic_branch_model=None,
mask_branch_model=None,
dataset=None,
id2label=None,
model='segformer'):
anns = {'annotations': mask_branch_model.generate(img)}
h, w, _ = img.shape
class_names = []
if model == 'oneformer':
class_ids = oneformer_func[dataset](Image.fromarray(img), semantic_branch_processor,
semantic_branch_model, rank)
elif model == 'segformer':
class_ids = segformer_func(img, semantic_branch_processor, semantic_branch_model, rank)
else:
raise NotImplementedError()
semantc_mask = class_ids.clone()
anns['annotations'] = sorted(anns['annotations'], key=lambda x: x['area'], reverse=True)
for ann in anns['annotations']:
valid_mask = torch.tensor(maskUtils.decode(ann['segmentation'])).bool()
# get the class ids of the valid pixels
propose_classes_ids = class_ids[valid_mask]
num_class_proposals = len(torch.unique(propose_classes_ids))
if num_class_proposals == 1:
semantc_mask[valid_mask] = propose_classes_ids[0]
ann['class_name'] = id2label['id2label'][str(propose_classes_ids[0].item())]
ann['class_proposals'] = id2label['id2label'][str(propose_classes_ids[0].item())]
class_names.append(ann['class_name'])
# bitmasks.append(maskUtils.decode(ann['segmentation']))
continue
top_1_propose_class_ids = torch.bincount(propose_classes_ids.flatten()).topk(1).indices
top_1_propose_class_names = [id2label['id2label'][str(class_id.item())] for class_id in top_1_propose_class_ids]
semantc_mask[valid_mask] = top_1_propose_class_ids
ann['class_name'] = top_1_propose_class_names[0]
ann['class_proposals'] = top_1_propose_class_names[0]
class_names.append(ann['class_name'])
# bitmasks.append(maskUtils.decode(ann['segmentation']))
del valid_mask
del propose_classes_ids
del num_class_proposals
del top_1_propose_class_ids
del top_1_propose_class_names
sematic_class_in_img = torch.unique(semantc_mask)
semantic_bitmasks, semantic_class_names = [], []
# semantic prediction
anns['semantic_mask'] = {}
for i in range(len(sematic_class_in_img)):
class_name = id2label['id2label'][str(sematic_class_in_img[i].item())]
class_mask = semantc_mask == sematic_class_in_img[i]
class_mask = class_mask.cpu().numpy().astype(np.uint8)
semantic_class_names.append(class_name)
semantic_bitmasks.append(class_mask)
anns['semantic_mask'][str(sematic_class_in_img[i].item())] = maskUtils.encode(np.array((semantc_mask == sematic_class_in_img[i]).cpu().numpy(), order='F', dtype=np.uint8))
anns['semantic_mask'][str(sematic_class_in_img[i].item())]['counts'] = anns['semantic_mask'][str(sematic_class_in_img[i].item())]['counts'].decode('utf-8')
回归主线
方案也确定了,如果事情可以按着原来的方案走就好啦。现实的情况是,SAM的分割效果并不完美。
- 如果以随机撒点的形式也就是”SamAutomaticMaskGenerator生成的mask是不受控制的,并且在边界上存在空隙和空洞,这也是paper里面有提到的。
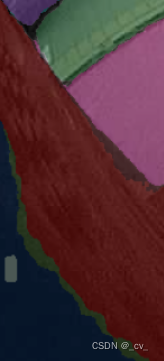
当这些空隙和空洞遇到不那么准确的语义分割就会导致一团糟。 - 如果想要尽可能少的空隙和空洞,有对sam的prompt输入尝试过修改, 但效果也并不会好。并且SAM虽然在paper中提及,Prompt的输入形式可以是点、框、掩码、文本。但现实是只有点和框是可用的,文本提示的代码没有放出,掩码输入并不会有什么作用(这个问题在官方的仓库中有很多人讨论,从代码上看掩码输入成为稠密编码以后直接加在了原图上)。
- 对于SAM存在的很多问题,如果真要着手去进行解决和适配,需要显卡资源也需要时间,但现在就是又缺时间又缺资源。也尝试过对SAM进行微调,github有同学搞过finetune-anything,以有监督的形式对SAM直接做修改和微调但这样做的话还不如直接更换其他专门用来做语义分割的模型,失去prompt encoder以后效果大降。
所以基于以上种种原因,SAM并不适合做全自动的标注,但是做一些半自动的辅助标注来说还是可以的,但辅助完的边界还是需要精修,得不偿失。