项目地址: https://github.com/zhulf0804/ROPNet 在 MVP Registration Challenge (ICCV Workshop 2021)(ICCV Workshop 2021)中获得了第二名。项目可以在win10环境下运行。
论文地址: https://arxiv.org/abs/2107.02583
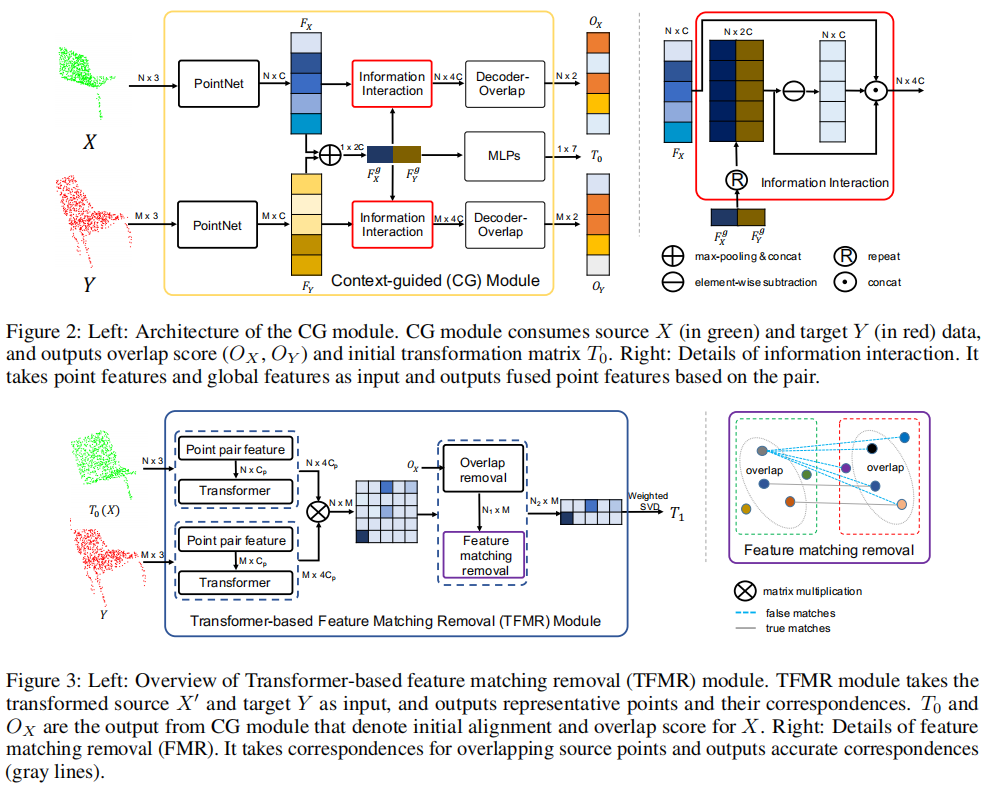
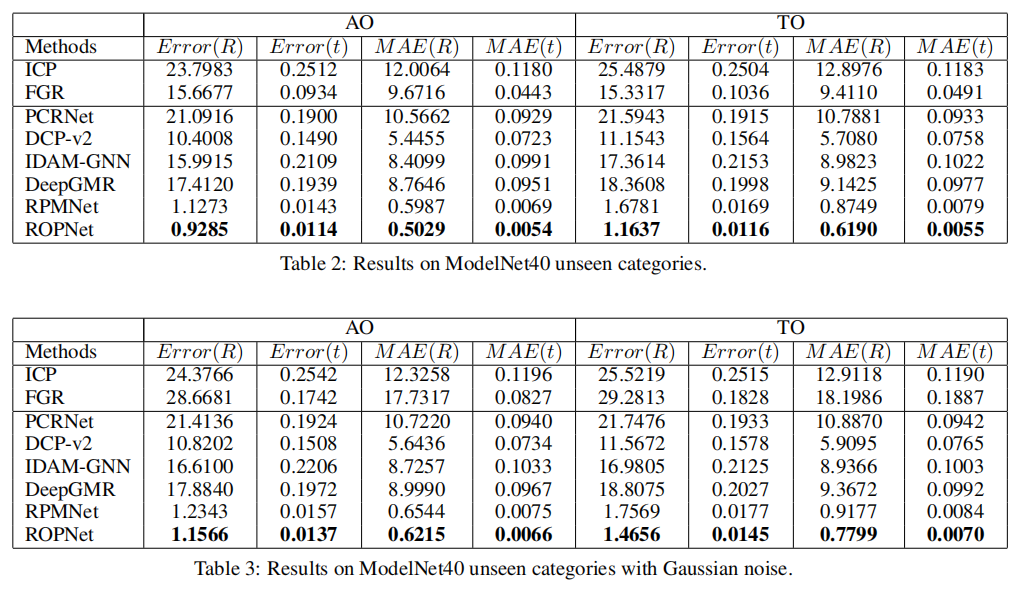
网络简介: 一种新的深度学习模型,该模型利用具有区别特征的代表性重叠点进行配准,将部分到部分配准转换为部分完全配准。基于pointnet输出的特征设计了一个上下文引导模块,使用一个编码器来提取全局特征来预测点重叠得分。为了更好地找到有代表性的重叠点,使用提取的全局特征进行粗对齐。然后,引入一种变压器来丰富点特征,并基于点重叠得分和特征匹配去除非代表性点。在部分到完全的模式下建立相似度矩阵,最后采用加权支持向量差来估计变换矩阵。
实施效果: 从数据上看ROPNet与RPMNet与保持了断崖式的领先地位
1、运行环境安装
1.1 项目下载
打开https://github.com/zhulf0804/ROPNet,点Download ZIP然后将代码解压到指定目录下即可。
1.2 依赖项安装
在装有pytorch的环境终端,进入ROPNet-master/src目录,执行以下安装命令。如果已经安装了torch 环境和open3d包,则不用再进行安装了
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
pip install open3d
1.3 模型与数据下载
modelnet40数据集 here [435M]
数据集下载后存储为以下路径即可。
官网预训练模型,无。
第三方预训练模型:使用ROPNet项目在modelnet40数据集上训练的模型
2、关键代码
2.1 dataloader
作者所提供的dataloader只能加载https://shapenet.cs.stanford.edu/media/modelnet40_ply_hdf5_2048.zip 数据集,其所返回的tgt_cloud, src_cloud实质上是基于一个点云采样而来的。 其中的self.label2cat, self.cat2label, self.symmetric_labels等对象代码实际上是没有任何作用的。
import copy
import h5py
import math
import numpy as np
import os
import torch
from torch.utils.data import Dataset
import sys
BASE_DIR = os.path.dirname(os.path.abspath(__file__))
ROOR_DIR = os.path.dirname(BASE_DIR)
sys.path.append(ROOR_DIR)
from utils import random_select_points, shift_point_cloud, jitter_point_cloud, \
generate_random_rotation_matrix, generate_random_tranlation_vector, \
transform, random_crop, shuffle_pc, random_scale_point_cloud, flip_pc
half1 = ['airplane', 'bathtub', 'bed', 'bench', 'bookshelf', 'bottle', 'bowl',
'car', 'chair', 'cone', 'cup', 'curtain', 'desk', 'door', 'dresser',
'flower_pot', 'glass_box', 'guitar', 'keyboard', 'lamp']
half1_symmetric = ['bottle', 'bowl', 'cone', 'cup', 'flower_pot', 'lamp']
half2 = ['laptop', 'mantel', 'monitor', 'night_stand', 'person', 'piano',
'plant', 'radio', 'range_hood', 'sink', 'sofa', 'stairs', 'stool',
'table', 'tent', 'toilet', 'tv_stand', 'vase', 'wardrobe', 'xbox']
half2_symmetric = ['tent', 'vase']
class ModelNet40(Dataset):
def __init__(self, root, split, npts, p_keep, noise, unseen, ao=False,
normal=False):
super(ModelNet40, self).__init__()
self.single = False # for specific-class visualization
assert split in ['train', 'val', 'test']
self.split = split
self.npts = npts
self.p_keep = p_keep
self.noise = noise
self.unseen = unseen
self.ao = ao # Asymmetric Objects
self.normal = normal
self.half = half1 if split in 'train' else half2
self.symmetric = half1_symmetric + half2_symmetric
self.label2cat, self.cat2label = self.label2category(
os.path.join(root, 'shape_names.txt'))
self.half_labels = [self.cat2label[cat] for cat in self.half]
self.symmetric_labels = [self.cat2label[cat] for cat in self.symmetric]
files = [os.path.join(root, 'ply_data_train{}.h5'.format(i))
for i in range(5)]
if split == 'test':
files = [os.path.join(root, 'ply_data_test{}.h5'.format(i))
for i in range(2)]
self.data, self.labels = self.decode_h5(files)
print(f'split: {self.split}, unique_ids: {len(np.unique(self.labels))}')
if self.split == 'train':
self.Rs = [generate_random_rotation_matrix() for _ in range(len(self.data))]
self.ts = [generate_random_tranlation_vector() for _ in range(len(self.data))]
def label2category(self, file):
with open(file, 'r') as f:
label2cat = [category.strip() for category in f.readlines()]
cat2label = {label2cat[i]: i for i in range(len(label2cat))}
return label2cat, cat2label
def decode_h5(self, files):
points, normal, label = [], [], []
for file in files:
f = h5py.File(file, 'r')
cur_points = f['data'][:].astype(np.float32)
cur_normal = f['normal'][:].astype(np.float32)
cur_label = f['label'][:].flatten().astype(np.int32)
if self.unseen:
idx = np.isin(cur_label, self.half_labels)
cur_points = cur_points[idx]
cur_normal = cur_normal[idx]
cur_label = cur_label[idx]
if self.ao and self.split in ['val', 'test']:
idx = ~np.isin(cur_label, self.symmetric_labels)
cur_points = cur_points[idx]
cur_normal = cur_normal[idx]
cur_label = cur_label[idx]
if self.single:
idx = np.isin(cur_label, [8])
cur_points = cur_points[idx]
cur_normal = cur_normal[idx]
cur_label = cur_label[idx]
points.append(cur_points)
normal.append(cur_normal)
label.append(cur_label)
points = np.concatenate(points, axis=0)
normal = np.concatenate(normal, axis=0)
data = np.concatenate([points, normal], axis=-1).astype(np.float32)
label = np.concatenate(label, axis=0)
return data, label
def compose(self, item, p_keep):
tgt_cloud = self.data[item, ...]
if self.split != 'train':
np.random.seed(item)
R, t = generate_random_rotation_matrix(), generate_random_tranlation_vector()
else:
tgt_cloud = flip_pc(tgt_cloud)
R, t = generate_random_rotation_matrix(), generate_random_tranlation_vector()
src_cloud = random_crop(copy.deepcopy(tgt_cloud), p_keep=p_keep[0])
src_size = math.ceil(self.npts * p_keep[0])
tgt_size = self.npts
if len(p_keep) > 1:
tgt_cloud = random_crop(copy.deepcopy(tgt_cloud),
p_keep=p_keep[1])
tgt_size = math.ceil(self.npts * p_keep[1])
src_cloud_points = transform(src_cloud[:, :3], R, t)
src_cloud_normal = transform(src_cloud[:, 3:], R)
src_cloud = np.concatenate([src_cloud_points, src_cloud_normal],
axis=-1)
src_cloud = random_select_points(src_cloud, m=src_size)
tgt_cloud = random_select_points(tgt_cloud, m=tgt_size)
if self.split == 'train' or self.noise:
src_cloud[:, :3] = jitter_point_cloud(src_cloud[:, :3])
tgt_cloud[:, :3] = jitter_point_cloud(tgt_cloud[:, :3])
tgt_cloud, src_cloud = shuffle_pc(tgt_cloud), shuffle_pc(
src_cloud)
return src_cloud, tgt_cloud, R, t
def __getitem__(self, item):
src_cloud, tgt_cloud, R, t = self.compose(item=item,
p_keep=self.p_keep)
if not self.normal:
tgt_cloud, src_cloud = tgt_cloud[:, :3], src_cloud[:, :3]
return tgt_cloud, src_cloud, R, t
def __len__(self):
return len(self.data)
2.2 模型设计
模型设计如下:
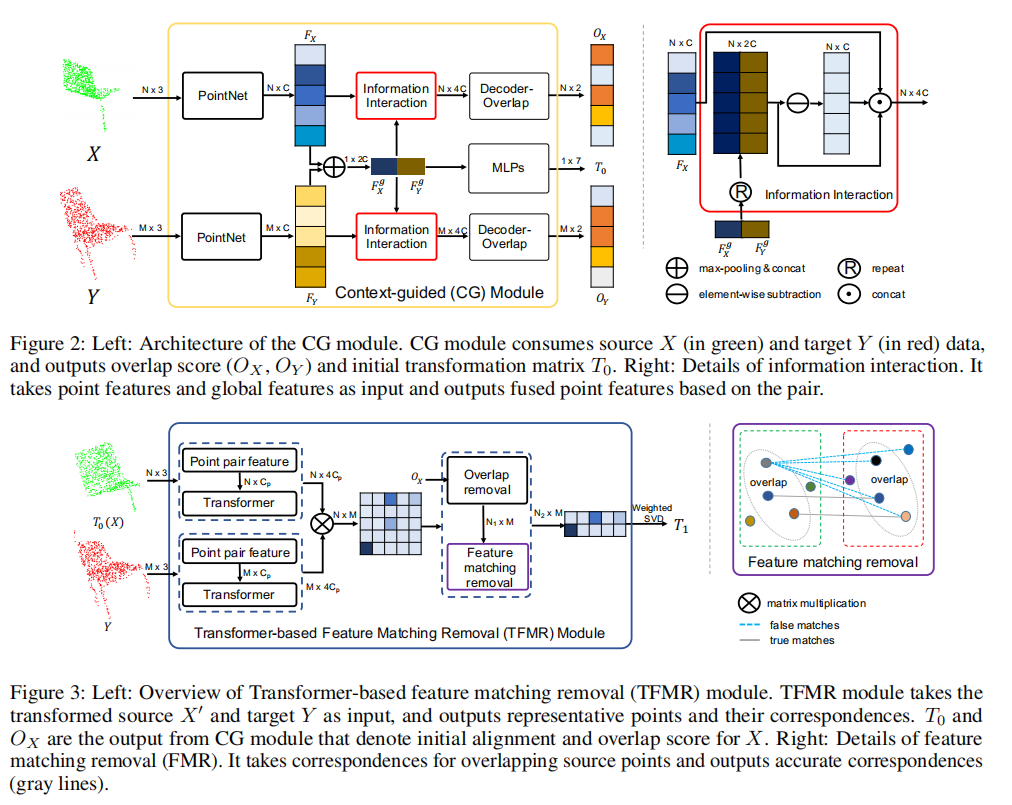
2.3 loss设计
其主要包含Init_loss、Refine_loss和Ol_loss。
其中Init_loss是用于计算
预测点
云
0
预测点云_0
预测点云0与目标点云的mse或mae loss,
Refine_loss用于计算
预测点
云
[
1
:
]
预测点云_{[1:]}
预测点云[1:]与目标点云的加权mae loss
Ol_loss用于计算两个输入点云输出的重叠分数,使两个点云对应点的重叠分数是一样的。

具体实现代码如上:
import math
import torch
import torch.nn as nn
from utils import square_dists
def Init_loss(gt_transformed_src, pred_transformed_src, loss_type='mae'):
losses = {}
num_iter = 1
if loss_type == 'mse':
criterion = nn.MSELoss(reduction='mean')
for i in range(num_iter):
losses['mse_{}'.format(i)] = criterion(pred_transformed_src[i],
gt_transformed_src)
elif loss_type == 'mae':
criterion = nn.L1Loss(reduction='mean')
for i in range(num_iter):
losses['mae_{}'.format(i)] = criterion(pred_transformed_src[i],
gt_transformed_src)
else:
raise NotImplementedError
total_losses = []
for k in losses:
total_losses.append(losses[k])
losses = torch.sum(torch.stack(total_losses), dim=0)
return losses
def Refine_loss(gt_transformed_src, pred_transformed_src, weights=None, loss_type='mae'):
losses = {}
num_iter = len(pred_transformed_src)
for i in range(num_iter):
if weights is None:
losses['mae_{}'.format(i)] = torch.mean(
torch.abs(pred_transformed_src[i] - gt_transformed_src))
else:
losses['mae_{}'.format(i)] = torch.mean(torch.sum(
weights * torch.mean(torch.abs(pred_transformed_src[i] -
gt_transformed_src), dim=-1)
/ (torch.sum(weights, dim=-1, keepdim=True) + 1e-8), dim=-1))
total_losses = []
for k in losses:
total_losses.append(losses[k])
losses = torch.sum(torch.stack(total_losses), dim=0)
return losses
def Ol_loss(x_ol, y_ol, dists):
CELoss = nn.CrossEntropyLoss()
x_ol_gt = (torch.min(dists, dim=-1)[0] < 0.05 * 0.05).long() # (B, N)
y_ol_gt = (torch.min(dists, dim=1)[0] < 0.05 * 0.05).long() # (B, M)
x_ol_loss = CELoss(x_ol, x_ol_gt)
y_ol_loss = CELoss(y_ol, y_ol_gt)
ol_loss = (x_ol_loss + y_ol_loss) / 2
return ol_loss
def cal_loss(gt_transformed_src, pred_transformed_src, dists, x_ol, y_ol):
losses = {}
losses['init'] = Init_loss(gt_transformed_src,
pred_transformed_src[0:1])
if x_ol is not None:
losses['ol'] = Ol_loss(x_ol, y_ol, dists)
losses['refine'] = Refine_loss(gt_transformed_src,
pred_transformed_src[1:],
weights=None)
alpha, beta, gamma = 1, 0.1, 1
if x_ol is not None:
losses['total'] = losses['init'] + beta * losses['ol'] + gamma * losses['refine']
else:
losses['total'] = losses['init'] + losses['refine']
return losses
3、训练与预测
先进入src目录,并将modelnet40_ply_hdf5_2048.zip解压在src目录下
3.1 训练
训练命令及训练输出如下所示
python train.py --root modelnet40_ply_hdf5_2048/ --noise --unseen
python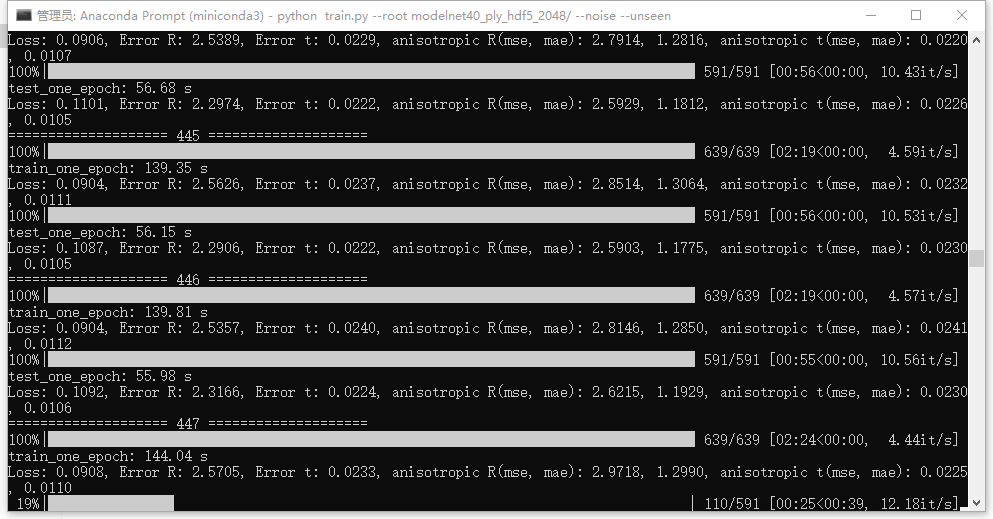
在训练过程中会在work_dirs\models\checkpoints目录下生成两个模型文件
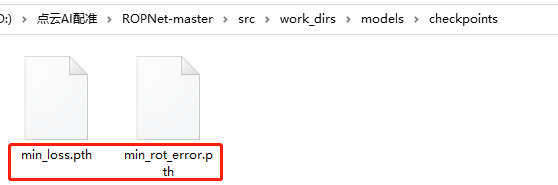
3.2 验证
训练命令及训练输出如下所示
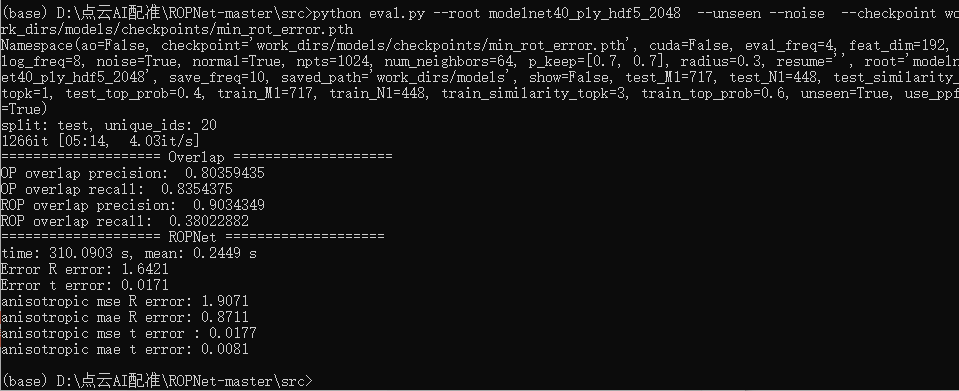
python eval.py --root modelnet40_ply_hdf5_2048/ --unseen --noise --cuda --checkpoint work_dirs/models/checkpoints/min_rot_error.pth
3.3 测试
测试训练数据的命令如下
python vis.py --root modelnet40_ply_hdf5_2048/ --unseen --noise --checkpoint work_dirs/models/checkpoints/min_rot_error.pth
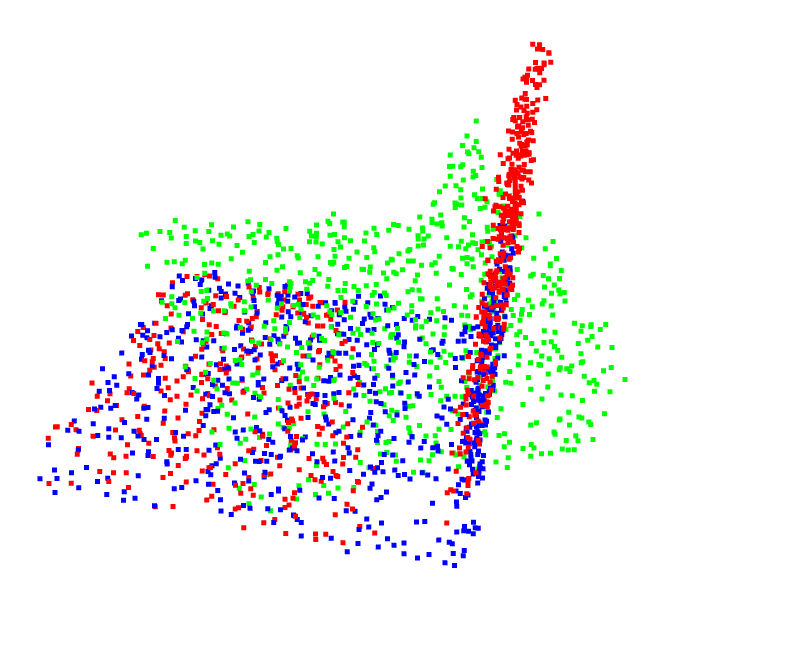
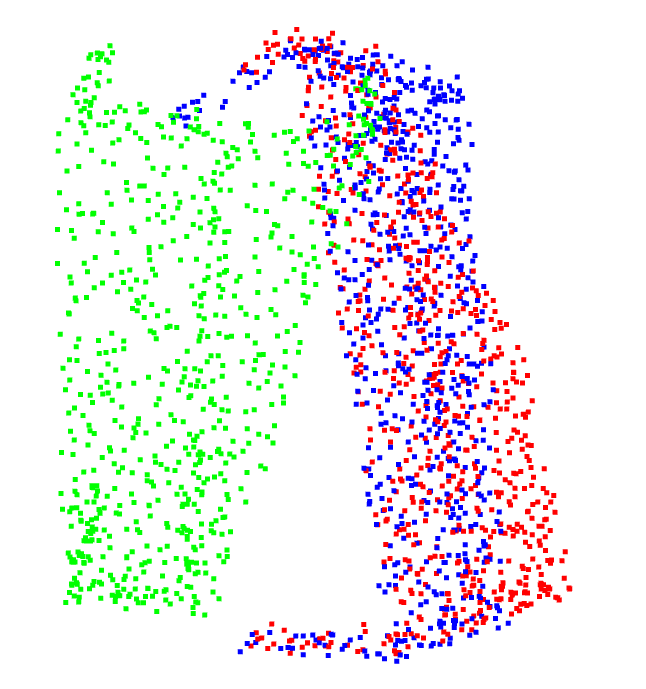
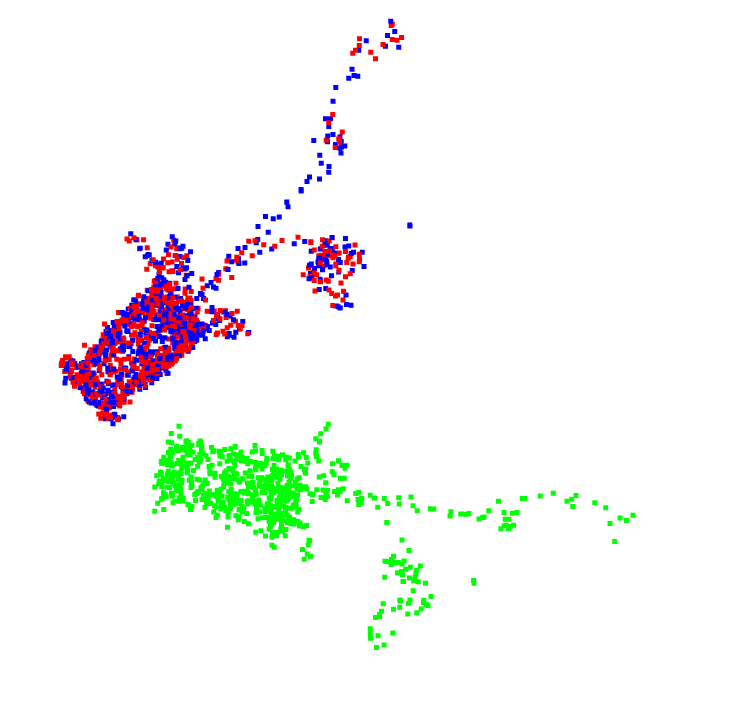
具体配准效果如下所示,其中绿色点云为输入点云,红色点云为参考点云,蓝色点云为配准后的点云。可以看到蓝色点云基本与红色点云重合,可以确定其配准效果十分完好。
3.4 处理自己的数据集
基于该项目训练并处理自己数据的教程后续会给出。