利用正则化完成字符串中的字符拆解。
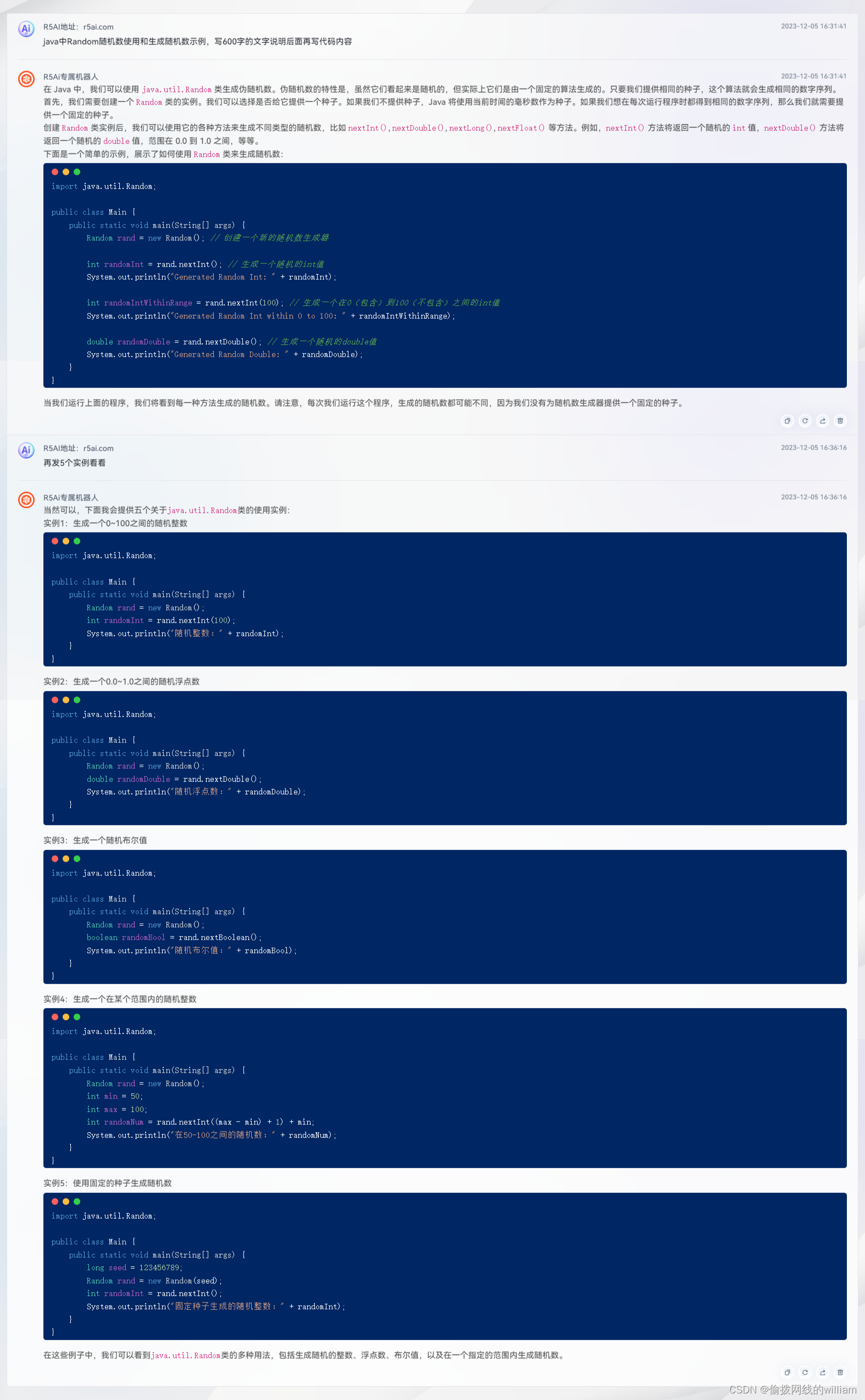
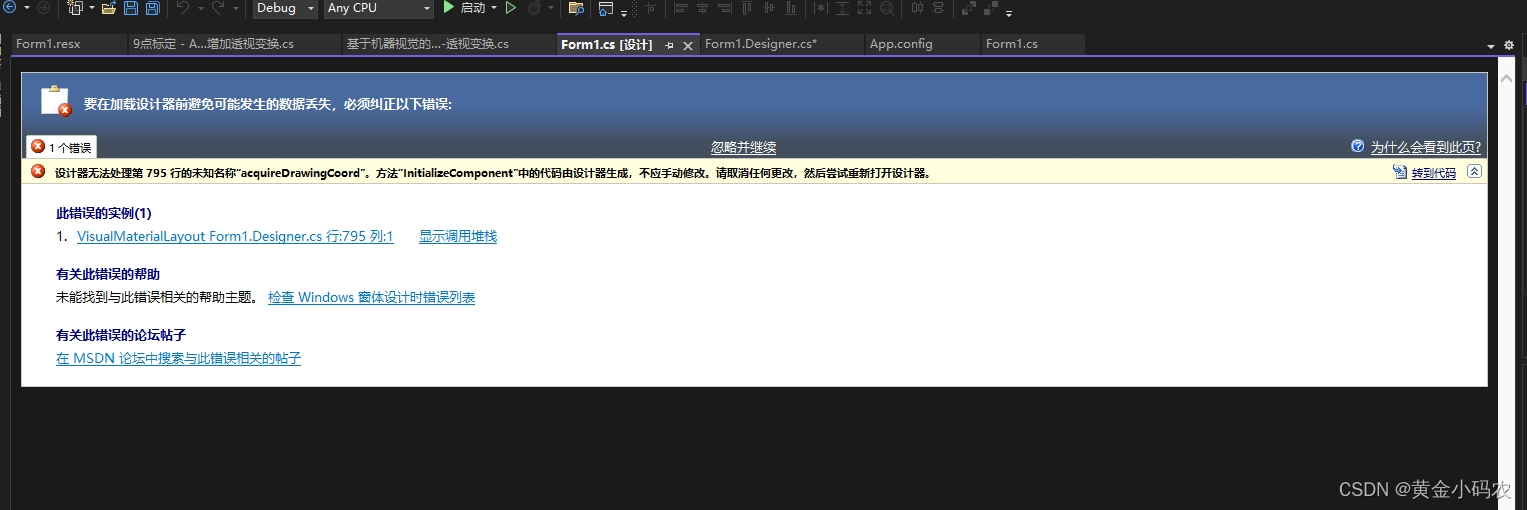
下面的代码是实现在“计算机组成原理-计科2101-123456-小明同学.docx”中提取出班级(grade),学号(id),姓名(name)。以下的代码都是github copilot实现的。代码很优美。
def get_info_from_file_name(file_name):
# 查找第一个"-"的位置
first_dash_index = file_name.find("-")
# 查找从第一个"-"之后开始的第一个"-"的位置
second_dash_index = file_name.index("-", first_dash_index + 1)
# 获取两个"-"之间的字符串
grade = file_name[first_dash_index + 1:second_dash_index]
# 查找最后一个"-"的位置
last_dash_index = file_name.rfind("-")
id = file[second_dash_index + 1:last_dash_index]
# 查找".docx"的位置
docx_index = file_name.rfind(".docx")
# 获取最后一个"-"和".docx"之间的字符串
person = file_name[last_dash_index + 1:docx_index]
print(grade, id, person)
return grade, id, person