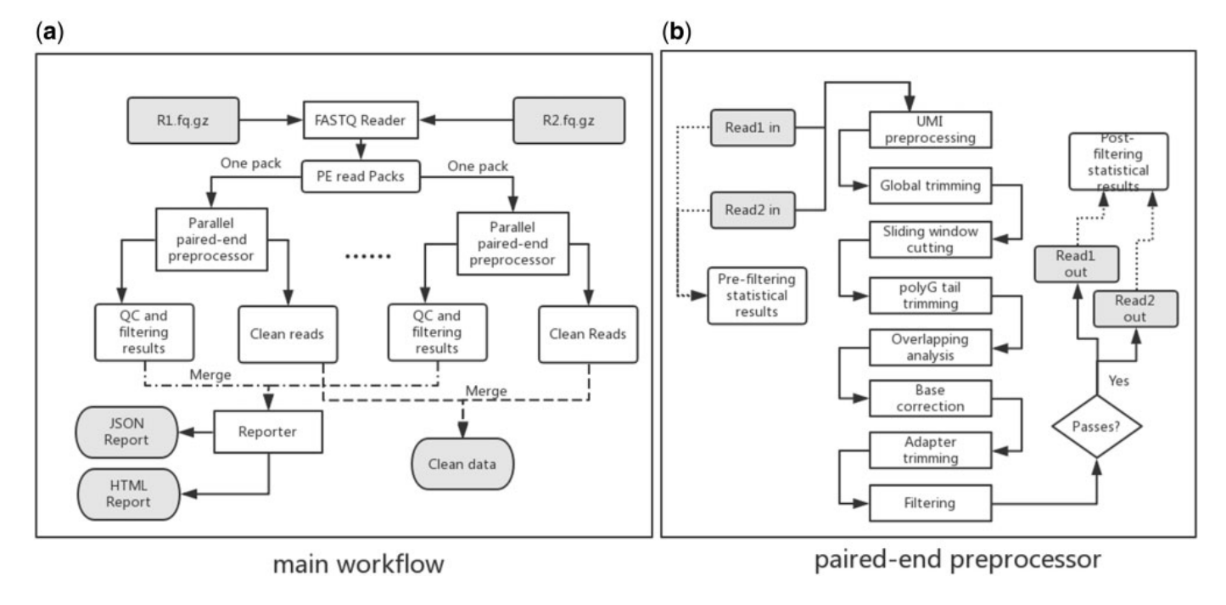
背景介绍
在编写Python爬虫程序时,我们经常会遇到需要控制爬取速度以及处理并发请求的情况。本文将深入探讨Python爬虫中使用time.sleep()和请求对象时可能出现的并发影响,并提供解决方案。
time.sleep()介绍
首先,让我们来了解一下time.sleep()。在Python中,time.sleep()是一个用于暂停程序执行一段时间的函数。它接受一个浮点数参数,代表暂停的秒数在爬虫程序中,我们通常会使用time.sleep()来控制爬取速度,对目标网站造成过大的访问压力,或者规避反爬虫机制。
使用场景会使用time.sleep在实际编写爬虫程序时,我们会在以下情况下使用time.sleep():
- 控制爬取速度,避免对目标网站造成过大的访问压力。
- 规避反爬虫机制,避免被目标网站封禁IP或账号。
问题示例
间隙使用time.sleep()来控制爬虫取速可能会导致程序效率低下。因为在等待的时间内,程序并不能进行其他有意义的操作,这就限制了爬虫的循环能力这意味着我们的爬虫程序在等待的一段时间内无法进行其他操作,从而影响了程序的效率和性能。
解决方案
解决time.sleep()可能带来的并发影响,我们可以考虑使用异步编程或多线程来提高程序的并发能力。下面我们将分别讨论这两种解决方案。
2.1 使用time.sleep 的影响
time.sleep()函数的主要影响是阻塞程序的执行。当调用time.sleep()时,程序将暂停执行指定的秒数,这意味着在等待的时段,程序无法进行其他有意义的操作。在爬虫程序中,如果间隔使用time.sleep()来控制爬取速度,会导致程序在等待的期限内无法进行其他操作,从而影响了程序的效率和运行速度尤其是在需要大量爬虫提取数据的情况下,过长的等待时间会使得爬虫程序的效率大幅降低。
示例代码
import time
import requests
def main():
for i in range(10):
# 爬取操作
time.sleep(1) # 每次爬取后暂停1秒
2.2 使用Request对象的影响
使用Request对象发送HTTP请求时,如果频繁创建新的连接,可能会导致连接池老化,从而影响程序的并发能力。每次创建新的连接都需要消耗一定的系统资源,如果连接池中的连接无法被充分恢复使用,就会导致资源的浪费和程序性能的下降。因此,在爬虫程序中,合理地管理和恢复HTTP连接是非常重要的,可以有效提升程序的并发能力和性能。
示例代码
import requests
def main():
for i in range(10):
# 爬取操作
response = requests.get('http://example.com')
2.3 解决方案总结
我们可以使用concurrent.futures模块来实现爬虫的并发能力。concurrent.futures提供了ThreadPoolExecutor和ProcessPoolExecutor两个类,可以帮助我们方便地实现爬虫编程。在这个例子中,我们还包含了代理信息,以保证爬虫程序的稳定性。通过使用线程池或进程池,我们可以同时处理多个爬虫程序,充分利用系统资源,提高爬虫程序的效率和吞吐量同时,合理地使用代理信息也可以帮助我们规避反爬虫机制,确保爬取的稳定性和持续性。
import requests
import concurrent.futures
proxyHost = "www.16yun.cn"
proxyPort = "5445"
proxyUser = "16QMSOML"
proxyPass = "280651"
proxies = {
"http": f"http://{proxyUser}:{proxyPass}@{proxyHost}:{proxyPort}",
"https": f"http://{proxyUser}:{proxyPass}@{proxyHost}:{proxyPort}"
}
def fetch_url(url):
response = requests.get(url, proxies=proxies)
return response.text
def main():
urls = ['http://example.com', 'http://example.org', 'http://example.net']
with concurrent.futures.ThreadPoolExecutor(max_workers=5) as executor:
results = executor.map(fetch_url, urls)
for result in results:
print(result)
结语
通过论文的分析,我们深入了解了在Python爬虫中,time.sleep()和Request对象对并发能力的影响,并提出了使用concurrent.futures模块来解决这些问题的方案。希望论文能够帮助读者更多很好地理解了提高爬虫程序在爬虫应用中的考虑。同时,我们也强调了在实际应用中,需要代理的使用以确保爬虫程序的稳定性。通过合理的并发处理,我们可以提高爬虫程序的效率和性能,从而更好地应对各种爬取场景。