文章目录
- 配置环境
- 环境准备
- 连接 Hadoop
- 查看 hadoop 文件
- 导入 Hadoop 包
- 创建 MapReduce 项目
- 测试 Mapreduce 编程代码
- 注意事项
- 常见报错
配置环境
环境准备
本次实验使用的 Hadoop 为 2.7.7 版本,实验可能会用到的文件
百度网盘链接:https://pan.baidu.com/s/1HZPOpg5MAiWXaN9DIcIUGg 提取码:gahr
迅雷云盘链接:https://pan.xunlei.com/s/VNkp2rp8az9m70YWCe5ifxm3A1?pwd=ggeq#
1)下载hadoop-eclipse-plugin-2.7.3.jar包
2)将jar包把放置到eclipse文件的plugins目录下
3)将hadoop解压到E盘
配置环境变量:添加用户变量HADOOP_HOME,值为E:\hadoop-2.7.7
Path新建%HADOOP_HOME%\bin、%HADOOP_HOME%\sbin
连接 Hadoop
1)打开 Eclipse ➡ Window ➡ Perspective ➡ Open Perspective ➡ other,

2)Map/Reduce ➡ Open,

3)进入界面后选择 Map/Reduce Locations,点击蓝色图标配置连接。

4)配置 hadoop 集群连接位置
Location name:myhadoop(随便填)
Host:192.168.88.102(填虚拟机IP地址)
Port:9000(填之前 Hadoop 中 core-site.xml 配置文件中,fs.defaultFS 对应的端口号)

查看 hadoop 文件
打开 myhadoop 查看文件内容,测试完全正确。

导入 Hadoop 包
选择:Window ➡ Perferencces ➡ Hadoop Map/Reduce ➡ Browse
选择所对应的 hadoop 安装包目录

创建 MapReduce 项目
1)创建 Project,File ➡ New ➡ Project

2)创建 MapReduce 项目

3)填写项目名 Wordcnt

4)打开引入的库可以看到 hadoop 的 jar 包已经导入,如图所示,不过我们此次要测试的 WordCount 类在测试包里面,我们现在需要先导入 hadoop 里自带的 examples 测试包。

5)构建路径配置步骤:Reference Libraries ➡ Build Path ➡ Configure Build Path

6)导入 jar 包:Java Build Path ➡ Add External JARs ➡ examples.jar ➡ Apply and Close 如图所示:

7)创建类


测试 Mapreduce 编程代码
1)Java 测试代码如下:
package org.apache.hadoop.examples;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.examples.WordCount.*;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class Wordcnt {
public Wordcnt() {
}
public static void main(String[] args) throws Exception {
// 使用 hadoop 的用户
System.setProperty("HADOOP_USER_NAME", "user");
Configuration conf = new Configuration();
String[] otherArgs = (new GenericOptionsParser(conf, args)).getRemainingArgs();
if (otherArgs.length < 2) {
System.err.println("Usage: wordcount <in> [<in>...] <out>");
System.exit(2);
}
// 每次运行前检查输出路径是否存在,存在就删除
FileSystem fs = FileSystem.get(conf);
Path outPath = new Path(otherArgs[1]);
if(fs.exists(outPath)) {
fs.delete(outPath, true);
}
// 启用跨平台,将应用程序从Windows客户端提交到Linux / Unix服务器
conf.set("mapreduce.app-submission.cross-platform","true");
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
for(int i = 0; i < otherArgs.length - 1; ++i) {
FileInputFormat.addInputPath(job, new Path(otherArgs[i]));
}
FileOutputFormat.setOutputPath(job, new Path(otherArgs[otherArgs.length - 1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
2)将 core-site.xml、hdfs-site.xml、log4.properties 三个文件下载放到 src 目录下

3)右击 java 文件 ➡ Run As ➡ Run Configurations

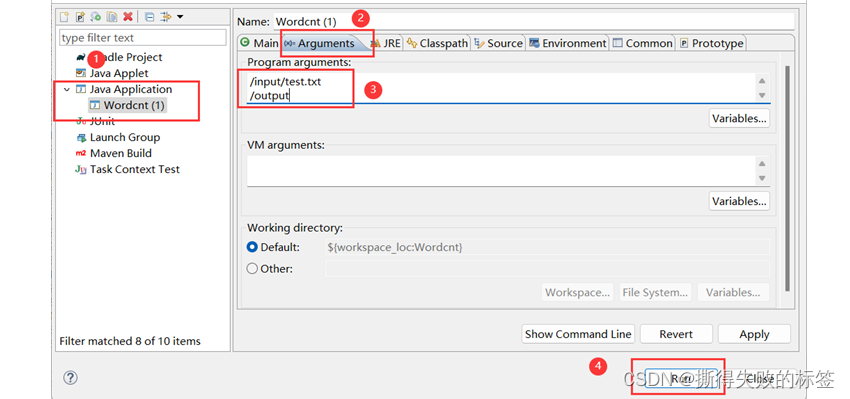
4)创建一个Java Application(双击就可以了) ➡ Arguments ➡ 第一个路径为 hadoop 上测试文件路径,第二个为输出文件路径(第二个路径用 jar 包中是不可以存在的,测试代码以更改可以存在)
5)查看运行提示信息与结果,与 Linux 中结果一致

注意事项
1)这里的 user 需要改成自己所用的用户名
// 使用 hadoop 的用户
System.setProperty("HADOOP_USER_NAME", "user");
2)同系统中不需要这行代码(这里加上是因为我的 Hadoop 是部署在 Linux 系统上,代码是在 Windows 系统上运行的)
// 启用跨平台,将应用程序从Windows客户端提交到Linux / Unix服务器
conf.set("mapreduce.app-submission.cross-platform","true");
这个参数在 mapred-default.xml 文件里写到如果启用,用户可以跨平台提交应用程序,即从 Windows 客户端提交应用程序到 Linux/Unix 服务器,反之亦然。默认情况下是关闭的。


请注意,由于在 Windows 上使用 Eclipse 编写 MapReduce 程序,但实际运行是在 Linux 虚拟机上的 Hadoop 集群,所以需要 确保主机名和 IP 地址的映射 在虚拟机和 Windows 主机的 hosts 文件中都是正确的。
常见报错
1)报错内容如下:
Could not locate executable winutils.exe in the Hadoop binaries
这是因为 Hadoop 都是运行在 Linux 系统下的,在 Windows 下 Eclipse 中运行 Mapreduce 程序需要支持插件
下载 hadoop-common-2.2.0-bin-master 把其中的 winutils.exe 和 hadoop.dll 放到 windows 安装的 hadoop 的 bin 目录下,或者直接放到 C:\Windows\System32 目录下就可以了(版本最好对应)
2)报错内容如下:
INFO mapreduce.JobSubmitter: Cleaning up the staging area /tmp/hadoop-yarn/staging/root/.staging/job_1510302622448_0003
出错原因:单机读取的是本地的文件,分布式环境下需要从hdfs 上读取文件。
解决方案:将本地的文件上传到 hdfs 上,然后再运行可以成功执行。
报错内容:
Output directory xxx already exists
出错原因:输出目录已存在
解决方案:修改输出目录,输出目录需要为空目录,所以在后面随便加上一个目录名,则会在 /output 目录下创建目录,如果是多次计算每次都需要指定不同的目录用于存储结果。
Hadoop文件系统命令参考:FileSystem Shell
下面给出几个常用命令
# 1 新建文件夹
hadoop dfs -mkdir [-p] <paths>
# 2 上传本地文件
hadoop fs -put localfile /hadoopdir
# 3 查看 hadoop 文件
hadoop fs -ls /hadoopfile
hadoop fs -ls -e /hadoopdir
# 4 修改文件夹权限
hadoop fs -chown [-R] [OWNER][:[GROUP]] URI [URI ]
# 5 删除文件夹
hadoop fs -rm -r /hadoopdir