1 配置执行器
在任务调度中心,点击进入”执行器管理”界面, 如下图:

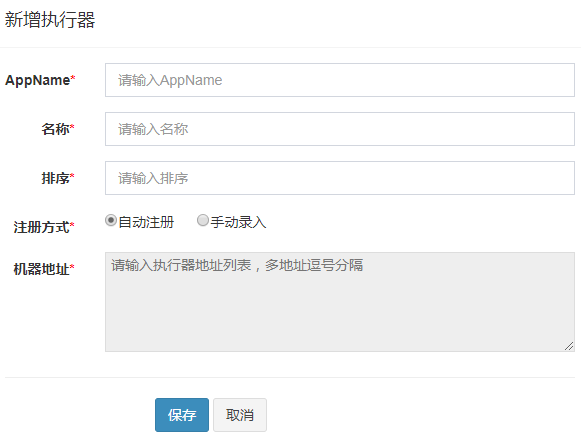
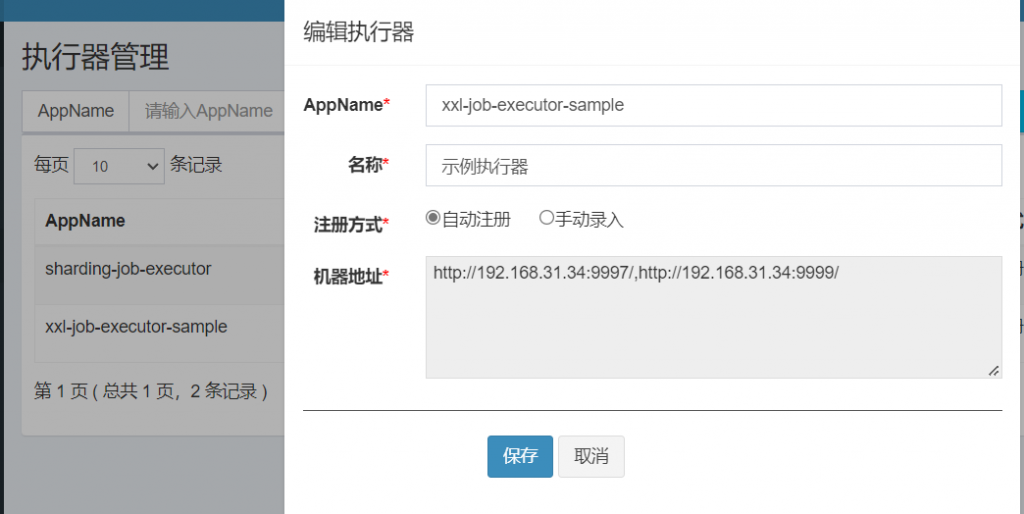
1、此处的AppName,会在创建任务时被选择,每个任务必然要选择一个执行器。 2、”执行器列表” 中显示在线的执行器列表, 支持编辑删除。
以下是执行器的属性说明:
| 属性名称 | 说明 |
|---|---|
| AppName | 是每个执行器集群的唯一标示AppName, 执行器会周期性以AppName为对象进行自动注册。可通过该配置自动发现注册成功的执行器, 供任务调度时使用; |
| 名称 | 执行器的名称, 因为AppName限制字母数字等组成,可读性不强, 名称为了提高执行器的可读性; |
| 排序 | 执行器的排序, 系统中需要执行器的地方,如任务新增, 将会按照该排序读取可用的执行器列表; |
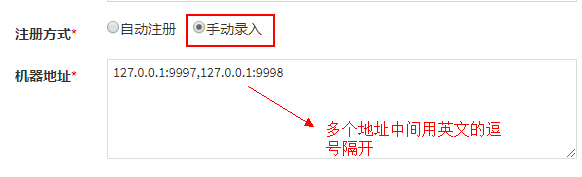
| 注册方式 | 调度中心获取执行器地址的方式; |
| 机器地址 | 注册方式为”手动录入”时有效,支持人工维护执行器的地址信息; |
具体操作:
(1)新增执行器:
(2)自动注册和手动注册的区别和配置(我们使用自动即可,特别是在docker中,不能写localhost,这样是访问不到的!!!)
2.2.2 在调度中心新建任务
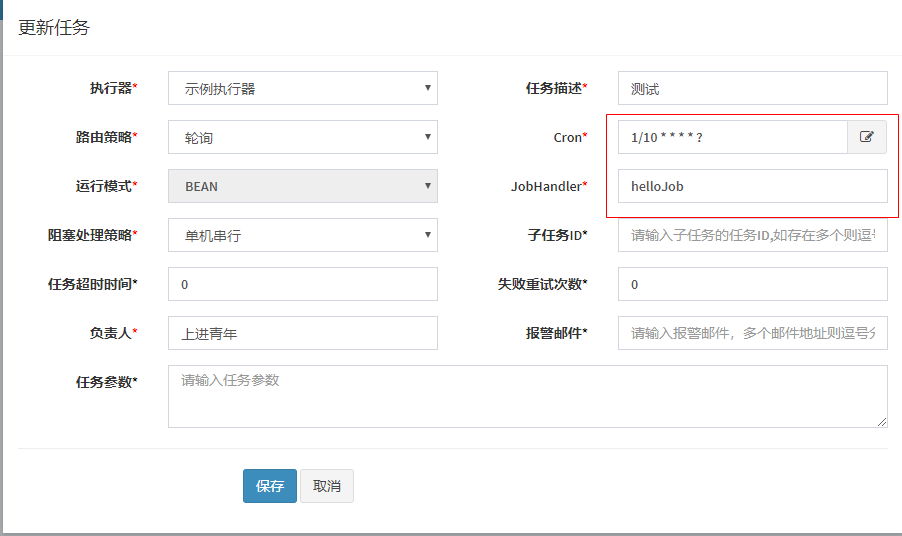
在任务管理->新建,填写以下内容
6.任务详解
- 执行器:任务的绑定的执行器,任务触发调度时将会自动发现注册成功的执行器, 实现任务自动发现功能; 另一方面也可以方便的进行任务分组。每个任务必须绑定一个执行器, 可在 “执行器管理” 进行设置
- 任务描述:任务的描述信息,便于任务管理路由策略:当执行器集群部署时,提供丰富的路由策略,包括
- FIRST(第一个):固定选择第一个机器;
- LAST(最后一个):固定选择最后一个机器;
- ROUND(轮询):
- RANDOM(随机):随机选择在线的机器;
- CONSISTENT_HASH(一致性HASH):每个任务按照Hash算法固定选择某一台机器,且所有任务均匀散列在不同机器上。
- LEAST_FREQUENTLY_USED(最不经常使用):使用频率最低的机器优先被选举;
- LEAST_RECENTLY_USED(最近最久未使用):最久为使用的机器优先被选举;
- FAILOVER(故障转移):按照顺序依次进行心跳检测,第一个心跳检测成功的机器选定为目标执行器并发起调度;
- BUSYOVER(忙碌转移):按照顺序依次进行空闲检测,第一个空闲检测成功的机器选定为目标执行器并发起调度;
- SHARDING_BROADCAST(分片广播):广播触发对应集群中所有机器执行一次任务,同时系统自动传递分片参数;可根据分片参数开发分片任务;
- Cron:触发任务执行的Cron表达式;
- 运行模式:
- BEAN模式:任务以JobHandler方式维护在执行器端;需要结合 “JobHandler” 属性匹配执行器中任务;
- GLUE模式(Java):任务以源码方式维护在调度中心;该模式的任务实际上是一段继承自IJobHandler的Java类代码并 “groovy” 源码方式维护,它在执行器项目中运行,可使用@Resource/@Autowire注入执行器里中的其他服务;
- GLUE模式(Shell):任务以源码方式维护在调度中心;该模式的任务实际上是一段 “shell” 脚本;
- GLUE模式(Python):任务以源码方式维护在调度中心;该模式的任务实际上是一段 “python” 脚本;
- GLUE模式(PHP):任务以源码方式维护在调度中心;该模式的任务实际上是一段 “php” 脚本;
- GLUE模式(NodeJS):任务以源码方式维护在调度中心;该模式的任务实际上是一段 “nodejs” 脚本;
- GLUE模式(PowerShell):任务以源码方式维护在调度中心;该模式的任务实际上是一段 “PowerShell” 脚本;
- JobHandler:运行模式为 “BEAN模式” 时生效,对应执行器中新开发的JobHandler类“@JobHandler”注解自定义的value值;
- 阻塞处理策略:调度过于密集执行器来不及处理时的处理策略;
- 单机串行(默认):调度请求进入单机执行器后,调度请求进入FIFO队列并以串行方式运行;
- 丢弃后续调度:调度请求进入单机执行器后,发现执行器存在运行的调度任务,本次请求将会被丢弃并标记为失败;
- 覆盖之前调度:调度请求进入单机执行器后,发现执行器存在运行的调度任务,将会终止运行中的调度任务并清空队列,然后运行本地调度任务;
- 子任务:每个任务都拥有一个唯一的任务ID(任务ID可以从任务列表获取),当本任务执行结束并且执行成功时,将会触发子任务ID所对应的任务的一次主动调度。
- 任务超时时间:支持自定义任务超时时间,任务运行超时将会主动中断任务;
- 失败重试次数;支持自定义任务失败重试次数,当任务失败时将会按照预设的失败重试次数主动进行重试;
- 报警邮件:任务调度失败时邮件通知的邮箱地址,支持配置多邮箱地址,配置多个邮箱地址时用逗号分隔;
- 负责人:任务的负责人;
- 执行参数:任务执行所需的参数;
二、在项目中配置
新建项目:xxl-job-demo
(1)pom文件
<groupId>com.itheima</groupId>
<artifactId>xxl-job-demo</artifactId>
<version>1.0-SNAPSHOT</version>
<!-- 继承Spring boot工程 -->
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!-- xxl-job -->
<dependency>
<groupId>com.xuxueli</groupId>
<artifactId>xxl-job-core</artifactId>
<version>2.2.0-SNAPSHOT</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>(2)配置有两个,一个是application.properties,另外一个是日志配置:logback.xml
application.properties
server:
port: 8881
xxl:
job:
admin:
addresses: http://192.168.200.130:8888/xxl-job-admin
executor:
appname: xxl-job-sharding-sample
port: 9999讲解:这里的appname对应调度中心执行器的appname,address是我们服务在docker中的地址
logback.xml
<?xml version="1.0" encoding="UTF-8"?>
<configuration debug="false" scan="true" scanPeriod="1 seconds">
<contextName>logback</contextName>
<property name="log.path" value="/data/applogs/xxl-job/xxl-job-executor-sample-springboot.log"/>
<appender name="console" class="ch.qos.logback.core.ConsoleAppender">
<encoder>
<pattern>%d{HH:mm:ss.SSS} %contextName [%thread] %-5level %logger{36} - %msg%n</pattern>
</encoder>
</appender>
<appender name="file" class="ch.qos.logback.core.rolling.RollingFileAppender">
<file>${log.path}</file>
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<fileNamePattern>${log.path}.%d{yyyy-MM-dd}.zip</fileNamePattern>
</rollingPolicy>
<encoder>
<pattern>%date %level [%thread] %logger{36} [%file : %line] %msg%n
</pattern>
</encoder>
</appender>
<root level="info">
<appender-ref ref="console"/>
<appender-ref ref="file"/>
</root>
</configuration>(3)引导类:
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication
public class XxlJobApplication {
public static void main(String[] args) {
SpringApplication.run(XxlJobApplication.class,args);
}
}2.2.4 添加xxl-job配置
添加配置类:
这个类主要是创建了任务执行器,参考官方案例编写,无须改动(yaml文件中没有的部分是可以删掉的)
package com.itheima.xxljob.config;
import com.xxl.job.core.executor.impl.XxlJobSpringExecutor;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class XxlJobConfig {
private Logger logger = LoggerFactory.getLogger(XxlJobConfig.class);
@Value("${xxl.job.admin.addresses}")
private String adminAddresses;
@Value("${xxl.job.accessToken}")
private String accessToken;
@Value("${xxl.job.executor.appname}")
private String appName;
@Value("${xxl.job.executor.address}")
private String address;
@Value("${xxl.job.executor.ip}")
private String ip;
@Value("${xxl.job.executor.port}")
private int port;
@Value("${xxl.job.executor.logpath}")
private String logPath;
@Value("${xxl.job.executor.logretentiondays}")
private int logRetentionDays;
@Bean
public XxlJobSpringExecutor xxlJobExecutor() {
logger.info(">>>>>>>>>>> xxl-job config init.");
XxlJobSpringExecutor xxlJobSpringExecutor = new XxlJobSpringExecutor();
xxlJobSpringExecutor.setAdminAddresses(adminAddresses);
xxlJobSpringExecutor.setAppName(appName);
xxlJobSpringExecutor.setAddress(address);
xxlJobSpringExecutor.setIp(ip);
xxlJobSpringExecutor.setPort(port);
xxlJobSpringExecutor.setAccessToken(accessToken);
xxlJobSpringExecutor.setLogPath(logPath);
xxlJobSpringExecutor.setLogRetentionDays(logRetentionDays);
return xxlJobSpringExecutor;
}
/**
* 针对多网卡、容器内部署等情况,可借助 "spring-cloud-commons" 提供的 "InetUtils" 组件灵活定制注册IP;
*
* 1、引入依赖:
* <dependency>
* <groupId>org.springframework.cloud</groupId>
* <artifactId>spring-cloud-commons</artifactId>
* <version>${version}</version>
* </dependency>
*
* 2、配置文件,或者容器启动变量
* spring.cloud.inetutils.preferred-networks: 'xxx.xxx.xxx.'
*
* 3、获取IP
* String ip_ = inetUtils.findFirstNonLoopbackHostInfo().getIpAddress();
*/
}2.2.5 创建任务
import com.xxl.job.core.biz.model.ReturnT;
import com.xxl.job.core.handler.annotation.XxlJob;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.stereotype.Component;
import java.time.LocalDateTime;
@Component
public class HelloJob {
@Value("${server.port}")
private String appPort;
@XxlJob("helloJob")
public ReturnT<String> hello(String param) throws Exception {
System.out.println("helloJob:"+ LocalDateTime.now()+",端口号"+appPort);
return ReturnT.SUCCESS;
}
}


![[Unity数据管理]自定义菜单创建Unity内部数据表(ScriptableObject)](https://img-blog.csdnimg.cn/direct/bb90345311cf497b931b7005d751c5af.png)