acwing-Linux课上的笔记
acwing-Linux网址
文章目录
- 1.1常用文件管理命令
- homework作业测评命令
- 2.1 简单的介绍tmux与vim
- vim
- homework
- tmux教程
- vim教程
- homework中的一些操作
- 3 shell语法
- 概论
- 注释
- 变量
- 默认变量
- 数组
- expr命令
- read命令
- echo命令
- printf命令
- test命令与判断符号[]
- 逻辑运算符&&和||
- test命令
- 文件类型判断
- 文件权限判断
- 整数间的比较
- 字符串比较
- 多重条件判定
- 判断符号[]
- 判断语句
- 循环语句
- 函数
- exit命令
- 文件重定向
- 引入外部脚本
- 4.1 ssh登录
- 基本用法
- 配置文件
- 密钥登录
- 执行命令
- 关于ssh远程执行命令中单引号与双引号的问题
- ssh远程执行命令
- shell命令变量中的空格问题(用ssh执行)
- 4.2scp传文件
- 基本用法
- 一次复制多个文件:
- 复制文件夹:
- 指定服务器的端口号:
- 使用`scp`配置其他服务器的`vim`和`tmux`
- 5.1 git
- 1.git教程
- 1.1. git基本概念
- 1.2 git常用命令
- 2.创建作业 & 测试作业的正确性
- 3.git命令分类整理
- 全局设置
- 常用命令
- 查看命令
- 删除命令
- 代码回滚
- 远程仓库
- 分支命令
- stash暂存
- 一些问题
- 关于 git restore
- 关于 git rm
- 6. thrift-rpc框架
- 匹配系统项目实现
- 接口实现
- 实现match_server
- 客户端实现
- server端实现
- 实现数据存储功能
- 升级匹配系统
- 看一下为什么Calculator修改为Match/Save
- 知识补充
- c++ mutex锁
- c++ 条件变量
- c++ 多线程
- 7. 管道、环境变量与常用命令
- 管道
- 概念
- 要点
- 与文件重定向的区别
- 举例
- 环境变量
- 概念
- 查看
- 修改
- 常见环境变量
- 常用命令
- 系统状况
- 文件权限
- 文件检索
- 查看文件内容
- 用户相关
- 工具
- 安装软件
- 补充
- 8. 租云服务器及配docker环境
- 概述
- 租云服务器及安装docker
- 阿里云
- 腾讯云
- 华为云
- docker教程
1.1常用文件管理命令
homework作业测评命令
homework num(作业号) show/create/test
homework 1 create #创建第一节课的作业 生成lesson_1文件夹
homework 1 test #测试第一节课的作业是不是对的
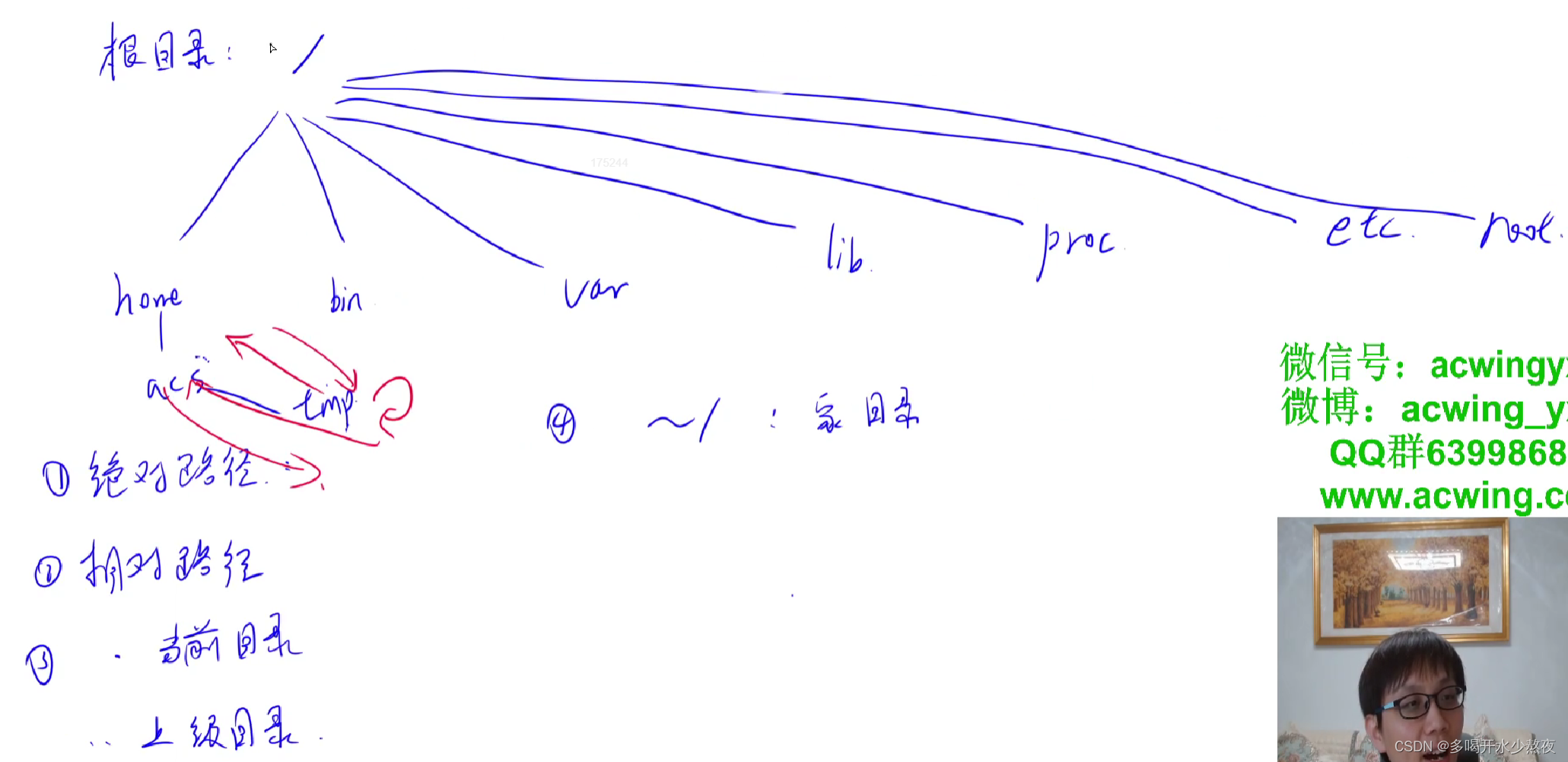
home下面的用户文件目录是家目录
-
常用命令介绍
(1) ctrl c: 取消命令,并且换行
(2) ctrl u: 清空本行命令
(3) tab键:可以补全命令和文件名,如果补全不了快速按两下tab键,可以显示备选选项
(4) ls: 列出当前目录下所有文件,蓝色的是文件夹,白色的是普通文件,绿色的是可执行文件 ls -l==详细信息 ls -lh文件大小可以转成kb ls -a展示隐藏文件(以.开头的文件)
(5) pwd: 显示当前路径
(6) cd XXX: 进入XXX目录下, cd … 返回上层目录 cd -返回上一个呆过的目录
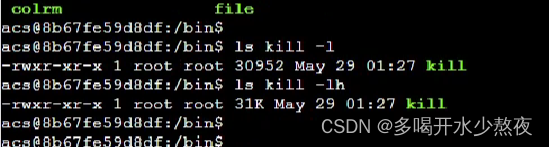
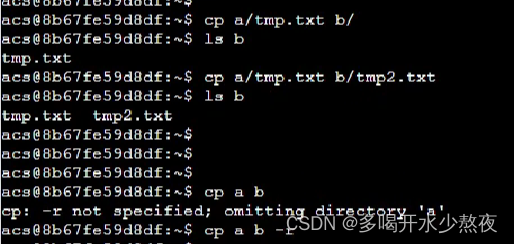
(7) cp XXX YYY: 将XXX文件复制成YYY,XXX和YYY可以是一个路径,比如…/dir_c/a.txt,表示上层目录下的dir_c文件夹下的文件a.txt cp=复制+粘贴+重命名 cp tmp/a.txt b/a1.txt 复制文件夹需要在命令后加-r
(8) mkdir XXX: 创建目录XXX
(9) rm XXX: 删除普通文件; rm XXX -r: 删除文件夹
(10) mv XXX YYY: 将XXX文件移动到YYY,和cp命令一样,XXX和YYY可以是一个路径;重命名也是用这个命令
(11) touch XXX: 创建一个文件
(12) cat XXX: 展示文件XXX中的内容(15)删除本目录下所有文件: rm -f * 删除某类型的文件 rm *.txt *和文件类型之间没有空格
(13) 复制文本
windows/Linux下:Ctrl + insert,Mac下:command + c
(14) 粘贴文本
windows/Linux下:Shift + insert,Mac下:command + v
2.1 简单的介绍tmux与vim
简单的介绍tmux与vim
开发项目时的两个编辑环境,此为开发项目时所必备
tmux
作用
1.分屏:可以在一个开发框里分屏
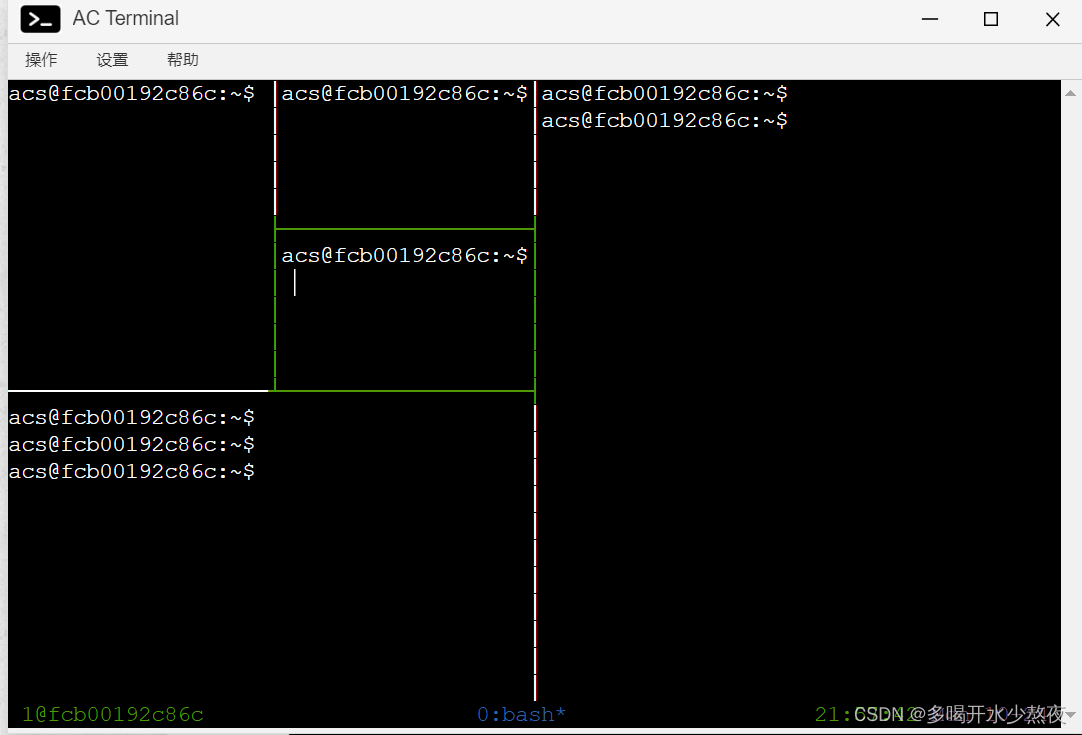
2.允许terminal在连接断开之后可以继续运行,让进程不会因为断开连接而中断
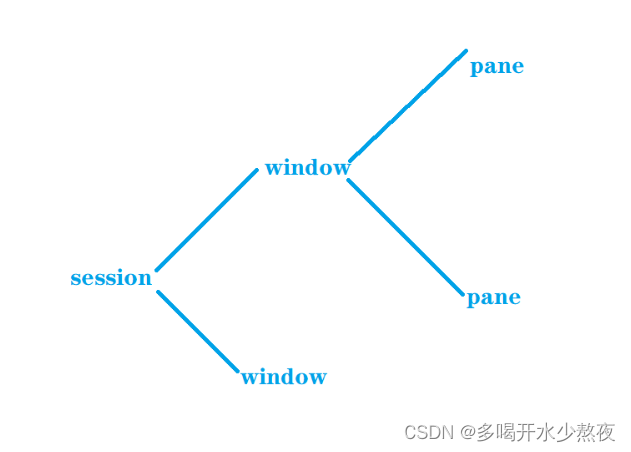
结构
一个tmux可以有一堆session
每个sesion可开很多的window
每个window可以开很多pane
每个pane可以打开一个shell交互
如图所示:
常规操作
前言:tmux创建一个session,session中包含一个window,一个界面就是一个window
1).切分:
竖直切分:先按ctrl+A松开,输入%,也就是按下shift+5
当按下ctrl+d,可以关闭tmux
水平切分:先按ctrl+A,再按”,即 shift+’
同样的按下ctrl+d取消
对于切分来说,每一块都可以继续切分
2).退出:
ctrl+d 退出
当window没有pane时,自动退出
当session没有window时,自动退出
故一直ctrl+d下去会直接退出
3).选择pane:鼠标点击即可或输入ctrl+a,然后按方向键选择相邻的pane
4).调整分割线:选中并拖动即可或者ctrl+a同时(同时也不松开)按方向键
5).全屏与取消全屏:某个窗口全屏:选中并按下ctrl+A再按z
同样取消按ctrl+A再按z
6).挂起窗口:ctrl+a然后按d,此为从session中退出
输入tmux a 或tmux attach,再开启session窗口
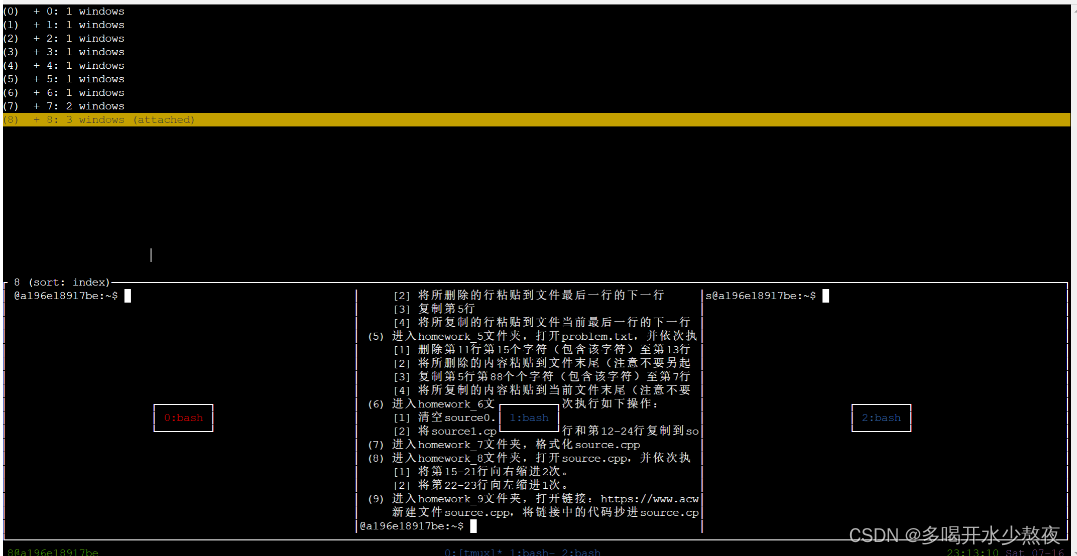
7).选择其他的session:先进入tmux,然后在tmux里输入ctrl+a再按s
再session里的方向键操作:
→展开,→再按一次是展开所有pane ←按下是合上所有pane
←合上
↑↓选择session
如下所示:一共9个session,点开展开是一系列window,再展开window是pane
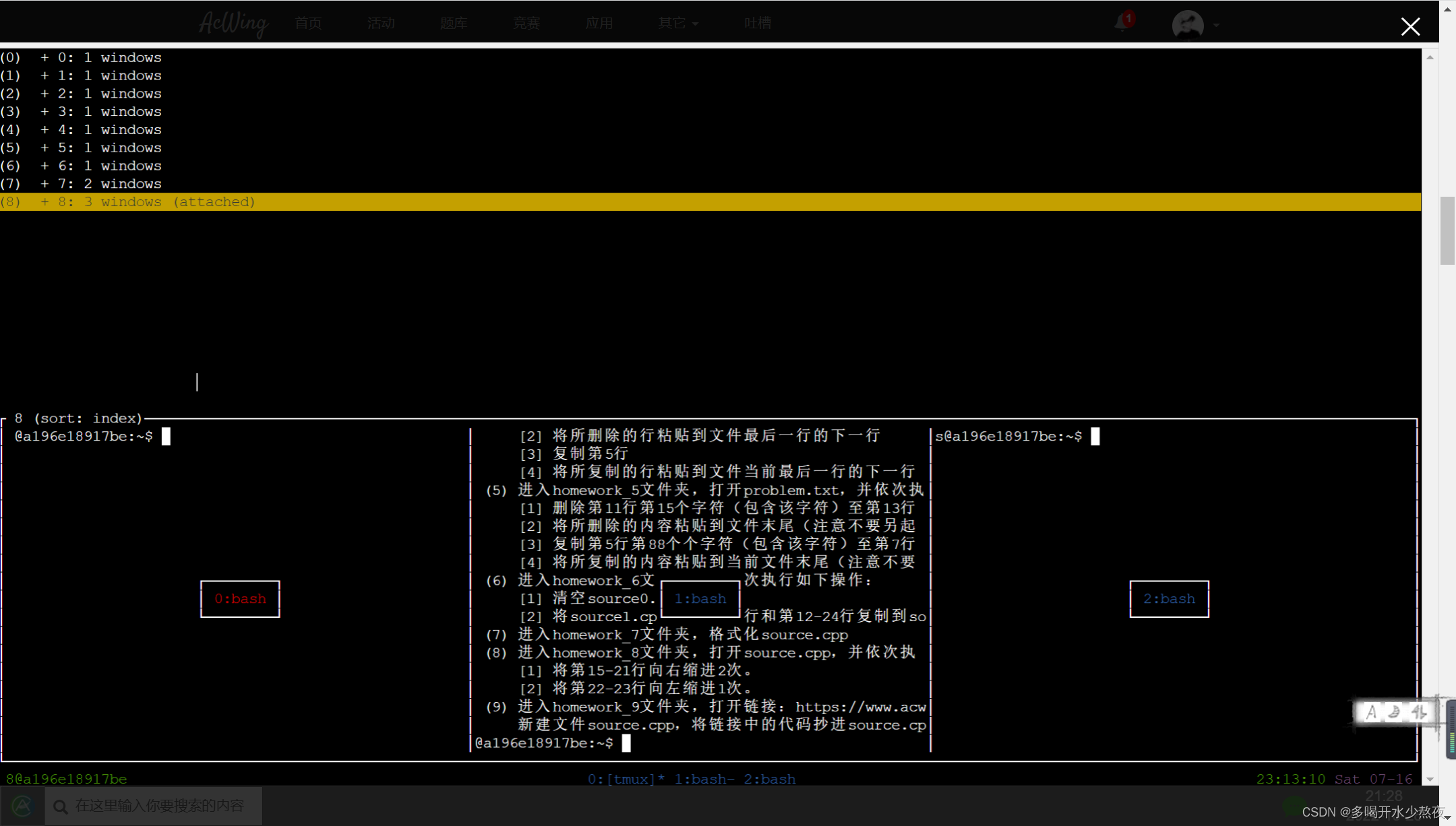
8).session中创建window与选择window:ctrl+a再按c:创建window
ctrl+a再按w:选择其他window也可以展开合上每个window
注:ctrl+a+s与ctrl+a+w的区别:前者打开只展开session一级,展示session级中所有的window如图一,后者打开默认是w一级,展开window级中所有的pane,如图二
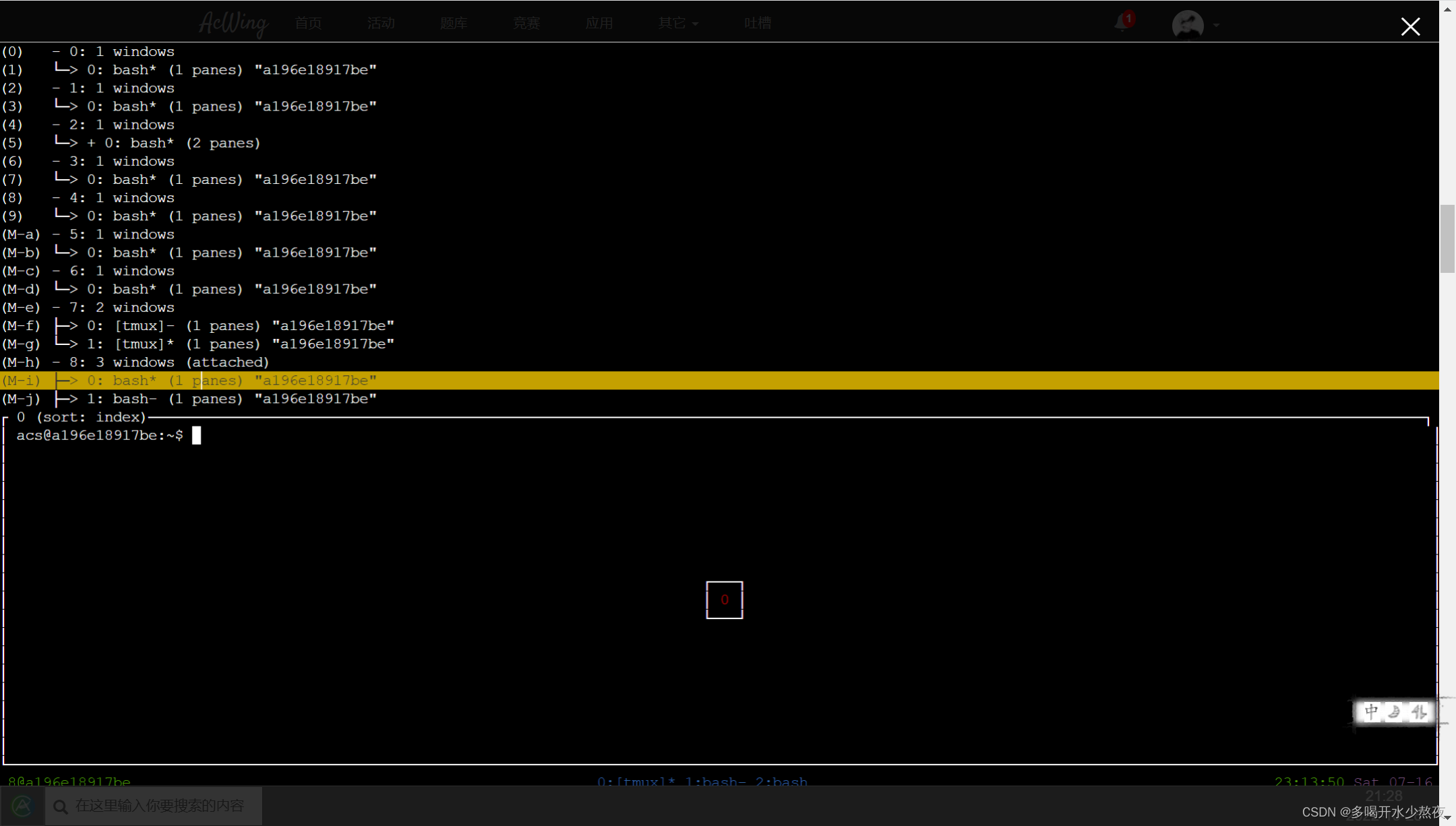
9).翻阅内容:↑滚轮向上
如果没有鼠标:ctrl+a再按Pageup向上翻,按PageUp向下翻
按PageUp也可以唤醒
10).从tmux中复制文本:
按住shift键选择文本
ctrl+insert复制
shift+insert粘贴
mac电脑:command+c复制
command+v粘贴
1、先列出所有的session及每个窗口的个数:
tmux ls
2、找到自己的session并删除不响应的窗口:
tmux kill-window -t 2
关闭当前tmux的第2个窗口
vim
功能
1.命令行模式下的文本编辑器
2.根据扩展名判别编程语言,实现代码缩进、代码高亮
使用
vim filename
如果有该文件则打开
没有则打开一个新的文件,命名为filename
模式
1.一般命令模式/默认模式:无法编写,输入命令,每一个命令对应一个字母,支持复制粘贴删除文本
2.编辑模式:在默认模式下按i,进入编辑模式,按esc退出
3.命令行模式:默认模式下按:/?三个中任意一个进入命令行模式,命令行在最下面(个人建议用:)支持查找、替换、保存、退出、配置编辑器等
输入:wq,保存并退出
操作
1.i:进入编辑模式
2.esc:进入一般命令模式
3.小键盘可以操作前后左右
注:在命令模式下:vim会卡在最后一个字符前面,编辑模式会卡在最后一个字符,不像win,移动到最后会直接换行
同样的,无论是什么模式,往左移动到开头就会停下
4.光标的移动操作:n n是数字,光标会自动右移n个字符
一般命令模式下:0/home 将光标移动到本行开头
$/End 将光标移动到本行结尾
G:光标移动到最后一行
5.具体到哪一行的操作:
1).n/nG:表示想去具体到哪一行(n是到某一行的下面,nG是直达)
2).gg:到达第一行
3).n 向下跳n行
6.查找与修改字符串的操作:
1)./word:在命令行模式下,光标之下寻找第一个值为word的字符串
2).?word:在光标之上第一个值为word的字符串
3).n:重复前一个查找操作 数字+n重复前一个查找动作n次
4).N:反向查找,也就是说前一个命令向前找,此命令下向后找
5).:n1,n2s/word1/word2/g:n1,n2为数字,在第n1与n2之间找word1,并替换为word2
:1,
s
/
w
o
r
d
1
/
w
o
r
d
2
/
g
:
将全文的
w
o
r
d
1
换成
w
o
r
d
2
:
1
,
s/word1/word2/g: 将全文的word1换成word2 :1,
s/word1/word2/g:将全文的word1换成word2:1,s/word1/word2/gc:在每一次替换的时候都会让用户进行确认
7.:noh 关闭所查找的关键词的高亮
8.选中与删除
v:选中文本,按两下esc取消
d:删除选中文本(其实有剪切的特性)
dd:删除整行
9.复制与粘贴:
y:复制(文本)
p:在光标所处位置的下一行或下一个位置(通常当光标在两边时)粘贴
yy:复制当前行
10.撤销:u:撤销
ctrl+r:取消撤销
注:在windows里,ctrl+z撤销,ctrl+shift+z取消撤销
11.> 将选中的文本整体向右移动
< 将选中的文本整体向左移动
12.保存与退出:
:w保存
:w! 强制保存
一般命令模式下:按下ESC,按q退出
:q! 强制退出(不保存)
:wq 保存并退出
:wq! 强制保存退出
13.行号的显示与隐藏:
:set nonu 隐藏行号
:set nu 显示行号
14.paste模式:
为什么:当要粘贴过来的代码很长时,命令可能会失效,占用很大带宽,导致出现多重缩进
:set paste取消代码缩进,设置成粘贴模式
:set nopaste开启代码缩进
要粘贴代码的时候先 :set paste
15.其他与gg有关的
gg+d+5G
gg+d+G 删除全部内容
gg=G 将全文格式化
16.vim的卡死处理
ctrl+q:当vim卡死时,可取消当前正在执行的命令
17.异常处理:当前进程出现冲突时,会出现异常
解决方法:1).找到正在多个打开的文件程序,并关掉,保证同一个进程只有同一个文件能打开
2).问题:当一个进程不小心被其他进程杀掉,当再打开main.cpp时,此时如果出现一个.swp缓存文件时会报错
解决:在没有任何一个进程打开该文件时,将.swp文件删掉即可
作业
homework(0).
cd homework/lesson_2/homework_0/
touch names.txt
vim names.txt
输入i进入编辑模式
AcWing
yxc
Bob
张强
李明
Alice
按Esc
进入一般命令模式
:wq
保存并退出
homework
homework(1).
1).
cd …/homework_1
vim problem.txt
G // 进入最后一行
101 //进入编辑模式
i进入编辑模式
2).
3G //进入编辑模式
8 //第8个字符
i进入编辑模式
3).
gg //进入第一行
30 //找到第30个字符
i //进入编辑模式
4).
:16//进入第16行
55 //找到第55个字符
i //进入编辑模式
5).
:9//进入第9行
80 //找到第80个字符
i//进入编辑模式
:wq//保存并退出
homework(2).
cd homework/lesson_2/homework_2
vim problem.txt
gg//先到第1行
然后输入 /two,回车
i进入编辑模式
1).在第一个two后面输入 “abc”
2).在第二个two前面输入def
3).在第三个two,删除12个字符
4).定位到第四个two,退出编辑模式输入dd,删除该行
homework(3).
cd …/homework_3
vim problem.txt
1).:5,15/of/OF/g //将在5行和第15行之间的of全部换成OF
2).:1,
s
/
t
h
e
/
T
H
E
/
g
/
/
将所有的
t
h
e
换成
T
H
E
3
)
:
1
,
s/the/THE/g //将所有的the换成THE 3):1,
s/the/THE/g//将所有的the换成THE3):1,s/is/IS/gc 然后ny交替按即可//将所有偶数个is换成IS
homework(4).
cd …/homework_4
1).11G dd//删除第11行
2).Gp //先到最后一行,然后按p粘贴
3).5Gyy//将第5行复制
4).Gp//先到最后一行,然后按p粘贴
:wq //保存并退出
homework(5).
cd …/homework_5
1).11G14//跳到第11行第14个单词
v//选中文本
13G5//到第13行第5个单词
d//删除选中文本
2).G
/
/
到达最后一行的最后一个位置
p
/
/
粘贴文本
3
)
.
5
G
87
<
S
p
a
c
e
>
/
/
跳到第
5
行第
87
个单词(因为第
88
个单词要保留)
v
/
/
选中文本
7
G
6
<
S
p
a
c
e
>
/
/
跳到第
7
行第
6
个单词(因为第
7
个要保留)
y
/
/
复制文本
4
)
.
G
//到达最后一行的最后一个位置 p//粘贴文本 3).5G87<Space>//跳到第5行第87个单词(因为第88个单词要保留) v//选中文本 7G6<Space>//跳到第7行第6个单词(因为第7个要保留) y//复制文本 4).G
//到达最后一行的最后一个位置p//粘贴文本3).5G87<Space>//跳到第5行第87个单词(因为第88个单词要保留)v//选中文本7G6<Space>//跳到第7行第6个单词(因为第7个要保留)y//复制文本4).Gp
:wq //保存并退出
homework(6).
此题的难点在于复制内容与粘贴内容到第二个文件
cd …/homework_6
1).gg+d+G//删除全部文本
2).ctrl+a shift+" //打开一个新的pane
vim source1.cpp
:set nonu //隐藏行号
shift //选中前3行
ctrl+insert //复制选中内容
在source0.cpp中
:set paste //进入粘贴模式
i进入编辑模式
shift+insert //进行粘贴
同理操作12-24行
source0.cpp :wq//保存并退出
source1.cpp :q//退出
复制后可能会一定概率有一些小空格,需要把多余空格删掉
注意,在复制粘贴时,被复制的文件最好在左边或下边,且周围没有新的pane影响,如下图所示

homework(7).
cd …/homework_7
vim source.cpp
gg=G //将全部内容格式化
:wq //保存并退出
homework(8).
cd …/homework_8
vim source.cpp
下面两行操作重复两次
15Gv21G //选中15-21行
//向右缩进
22Gv23G //选中22-23行
< //向左缩进1次
:wq
homework(9)
格局小了hh
vim source.cpp
#include
using namespace std;
int main(){
int a, b;
cin >> a >> b;
cout << a + b < <endl;
return 0;
}
//输入以上代码即可
最终结果
│homework_0 is Right!
│homework_1 is Right!
│homework_2 is Right!
│homework_3 is Right!
│homework_4 is Right!
│homework_5 is Right!
│homework_6 is Right!
│homework_7 is Right!
│homework_8 is Right!
│homework_9 is Right!
score: 100/100
tmux教程
功能:
(1) 分屏。
(2) 允许断开Terminal连接后,继续运行进程。
结构:
一个tmux可以包含多个session,一个session可以包含多个window,一个window可以包含多个pane。
实例:
tmux:
session 0:
window 0:
pane 0
pane 1
pane 2
…
window 1
window 2
…
session 1
session 2
…
操作:
(1) tmux:新建一个session,其中包含一个window,window中包含一个pane,pane里打开了一个shell对话框。
(2) 按下Ctrl + a后手指松开,然后按%:将当前pane左右平分成两个pane。
(3) 按下Ctrl + a后手指松开,然后按"(注意是双引号"):将当前pane上下平分成两个pane。
(4) Ctrl + d:关闭当前pane;如果当前window的所有pane均已关闭,则自动关闭window;如果当前session的所有window均已关闭,则自动关闭session。
(5) 鼠标点击可以选pane。
(6) 按下ctrl + a后手指松开,然后按方向键:选择相邻的pane。
(7) 鼠标拖动pane之间的分割线,可以调整分割线的位置。
(8) 按住ctrl + a的同时按方向键,可以调整pane之间分割线的位置。
(9) 按下ctrl + a后手指松开,然后按z:将当前pane全屏/取消全屏。
(10) 按下ctrl + a后手指松开,然后按d:挂起当前session。
(11) tmux a:打开之前挂起的session。
(12) 按下ctrl + a后手指松开,然后按s:选择其它session。
方向键 —— 上:选择上一项 session/window/pane
方向键 —— 下:选择下一项 session/window/pane
方向键 —— 右:展开当前项 session/window
方向键 —— 左:闭合当前项 session/window
(13) 按下Ctrl + a后手指松开,然后按c:在当前session中创建一个新的window。
(14) 按下Ctrl + a后手指松开,然后按w:选择其他window,操作方法与(12)完全相同。
(15) 按下Ctrl + a后手指松开,然后按PageUp:翻阅当前pane内的内容。
(16) 鼠标滚轮:翻阅当前pane内的内容。
(17) 在tmux中选中文本时,需要按住shift键。(仅支持Windows和Linux,不支持Mac,不过该操作并不是必须的,因此影响不大)
(18) tmux中复制/粘贴文本的通用方式:
(1) 按下Ctrl + a后松开手指,然后按[
(2) 用鼠标选中文本,被选中的文本会被自动复制到tmux的剪贴板
(3) 按下Ctrl + a后松开手指,然后按],会将剪贴板中的内容粘贴到光标处
vim教程
功能:
(1) 命令行模式下的文本编辑器。
(2) 根据文件扩展名自动判别编程语言。支持代码缩进、代码高亮等功能。
(3) 使用方式:vim filename
如果已有该文件,则打开它。
如果没有该文件,则打开个一个新的文件,并命名为filename
模式:
(1) 一般命令模式
默认模式。命令输入方式:类似于打游戏放技能,按不同字符,即可进行不同操作。可以复制、粘贴、删除文本等。
(2) 编辑模式
在一般命令模式里按下i,会进入编辑模式。
按下ESC会退出编辑模式,返回到一般命令模式。
(3) 命令行模式
在一般命令模式里按下:/?三个字母中的任意一个,会进入命令行模式。命令行在最下面。
可以查找、替换、保存、退出、配置编辑器等。
操作:
(1) i:进入编辑模式
(2) ESC:进入一般命令模式
(3) h 或 左箭头键:光标向左移动一个字符
(4) j 或 向下箭头:光标向下移动一个字符
(5) k 或 向上箭头:光标向上移动一个字符
(6) l 或 向右箭头:光标向右移动一个字符
(7) n:n表示数字,按下数字后再按空格,光标会向右移动这一行的n个字符
(8) 0 或 功能键[Home]:光标移动到本行开头
(9) $ 或 功能键[End]:光标移动到本行末尾
(10) G:光标移动到最后一行
(11) :n 或 nG:n为数字,光标移动到第n行
(12) gg:光标移动到第一行,相当于1G
(13) n:n为数字,光标向下移动n行
(14) /word:向光标之下寻找第一个值为word的字符串。
(15) ?word:向光标之上寻找第一个值为word的字符串。
(16) n:重复前一个查找操作
(17) N:反向重复前一个查找操作
(18) :n1,n2s/word1/word2/g:n1与n2为数字,在第n1行与n2行之间寻找word1这个字符串,并将该字符串替换为word2
(19) :1,
s
/
w
o
r
d
1
/
w
o
r
d
2
/
g
:将全文的
w
o
r
d
1
替换为
w
o
r
d
2
(
20
)
:
1
,
s/word1/word2/g:将全文的word1替换为word2 (20) :1,
s/word1/word2/g:将全文的word1替换为word2(20):1,s/word1/word2/gc:将全文的word1替换为word2,且在替换前要求用户确认。
(21) v:选中文本
(22) d:删除选中的文本
(23) dd: 删除当前行
(24) y:复制选中的文本
(25) yy: 复制当前行
(26) p: 将复制的数据在光标的下一行/下一个位置粘贴
(27) u:撤销
(28) Ctrl + r:取消撤销
(29) 大于号 >:将选中的文本整体向右缩进一次
(30) 小于号 <:将选中的文本整体向左缩进一次
(31) :w 保存
(32) :w! 强制保存
(33) :q 退出
(34) :q! 强制退出
(35) :wq 保存并退出
(36) :set paste 设置成粘贴模式,取消代码自动缩进(粘贴大量代码的时候要用到)
(37) :set nopaste 取消粘贴模式,开启代码自动缩进
(38) :set nu 显示行号
(39) :set nonu 隐藏行号
(40) gg=G:将全文代码格式化
(41) :noh 关闭查找关键词高亮
(42) Ctrl + q:当vim卡死时,可以取消当前正在执行的命令
异常处理:
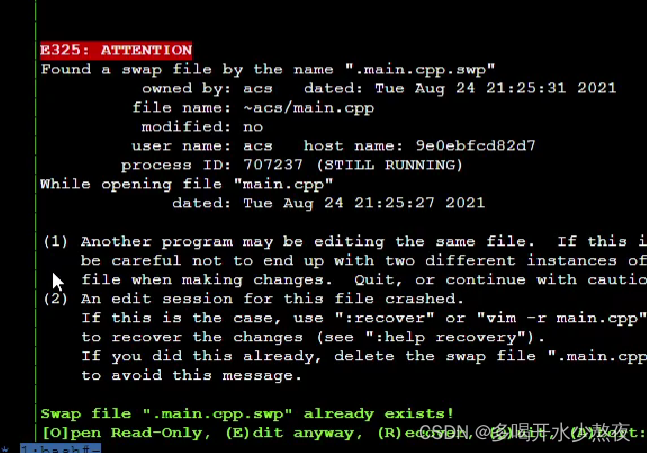
每次用vim编辑文件时,会自动创建一个.filename.swp的临时文件。
如果打开某个文件时,该文件的swp文件已存在,则会报错。此时解决办法有两种:
(1) 找到正在打开该文件的程序,并退出
(2) 直接删掉该swp文件即可

homework中的一些操作
/word 通过光标查看某个单词在全文中所有位置 ,按显示光标之下第一个值为word的字符串,按往下查找
在esc模式下按是向后删除 在编辑模式下是向前删除
dd: 删除当前行
:n1,n2s/word1/word2/g:n1与n2为数字,在第n1行与n2行之间寻找word1这个字符串,并将该字符串替换为word2
:1,
s
/
w
o
r
d
1
/
w
o
r
d
2
/
g
:将全文的
w
o
r
d
1
替换为
w
o
r
d
2
:
1
,
s/word1/word2/g:将全文的word1替换为word2 :1,
s/word1/word2/g:将全文的word1替换为word2:1,s/word1/word2/gc:将全文的word1替换为word2,且在替换前要求用户确认。
dd后按p可将删除的行复制回来
v:选中文本
$ 或 功能键[End]:光标移动到本行末尾
y:复制选中的文本
yy: 复制当前行
p: 将复制的数据在光标的下一行/下一个位置粘贴
gg=G:将全文代码格式化
大于号 >:将选中的文本整体向右缩进一次
小于号 <:将选中的文本整体向左缩进一次
3 shell语法
概论
shell是我们通过命令行与操作系统沟通的语言。
shell脚本可以直接在命令行中执行,也可以将一套逻辑组织成一个文件,方便复用。
AC Terminal中的命令行可以看成是一个“shell脚本在逐行执行”。
Linux中常见的shell脚本有很多种,常见的有:
-
Bourne Shell(
/usr/bin/sh或/bin/sh) -
Bourne Again Shell(
/bin/bash) -
C Shell(
/usr/bin/csh) -
K Shell(
/usr/bin/ksh) -
zsh
-
…
Linux系统中一般默认使用bash,所以接下来讲解bash中的语法。
文件开头需要写#! /bin/bash,指明bash为脚本解释器。
学习技巧
不要死记硬背,遇到含糊不清的地方,可以在AC Terminal里实际运行一遍。
脚本示例
新建一个test.sh文件,内容如下:
#! /bin/bash
echo "Hello World!"
运行方式
作为可执行文件
acs@9e0ebfcd82d7:~$ chmod +x test.sh # 使脚本具有可执行权限
acs@9e0ebfcd82d7:~$ ./test.sh # 当前路径下执行
Hello World! # 脚本输出
acs@9e0ebfcd82d7:~$ /home/acs/test.sh # 绝对路径下执行
Hello World! # 脚本输出
acs@9e0ebfcd82d7:~$ ~/test.sh # 家目录路径下执行
Hello World! # 脚本输出
用解释器执行
acs@9e0ebfcd82d7:~$ bash test.sh
Hello World! # 脚本输出
注释
单行注释
每行中#之后的内容均是注释。
# 这是一行注释
echo 'Hello World' # 这也是注释
多行注释
格式:
:<<EOF
第一行注释
第二行注释
第三行注释
EOF
其中 EOF 可以换成其它任意字符串。例如:
:<<abc
第一行注释
第二行注释
第三行注释
abc
:<<!
第一行注释
第二行注释
第三行注释
!
变量
1、定义变量时,等号两边不能有空格
2、定义变量的时候变量都是字符串,但当变量需要是整数时,会自动把变量转换成整数
3、type+命令可以解释该命令的来源(内嵌命令。第三方命令等)
如type readonly #readonly is a shell builtin(shell内部命令)
type ls # ls is aliased to ‘ls –color+auto’
4、被声明为只读的变量无法被unset删除
5、bash可以用来开一个新的进程,exit或Ctrl+d退出新的bash
6、字符串中,不加引号和双引号效果相同
7、如果一个变量不存在的话,他的值是空字符串
定义变量
定义变量,不需要加$符号,例如:
name1='yxc' # 单引号定义字符串
name2="yxc" # 双引号定义字符串
name3=yxc # 也可以不加引号,同样表示字符串
使用变量
使用变量,需要加上$符号,或者${}符号。花括号是可选的,主要为了帮助解释器识别变量边界。
name=yxc
echo $name # 输出yxc
echo ${name} # 输出yxc
echo ${name}acwing # 输出yxcacwing
只读变量
使用 readonly或者declare可以将变量变为只读。
name=yxc
readonly name
declare -r name # 两种写法均可
name=abc # 会报错,因为此时name只读
删除变量
unset可以删除变量。
name=yxc
unset name
echo $name # 输出空行
变量类型
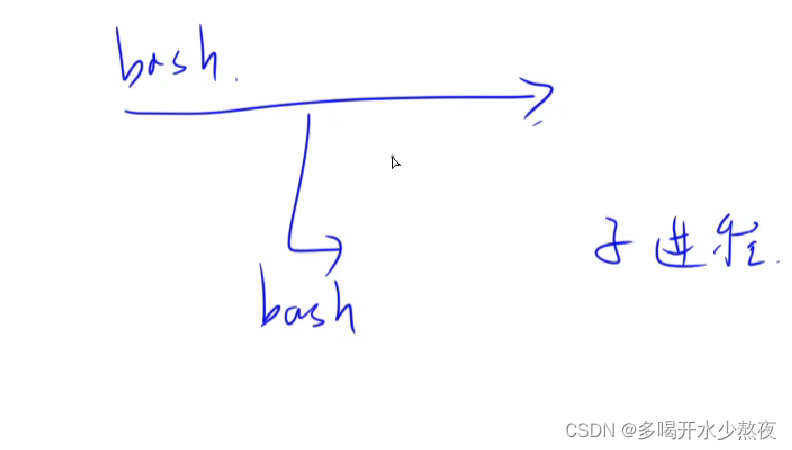
输入bash后相当于开了一个新的子进程 exit相当于退出该子进程
-
自定义变量(局部变量)
-
子进程不能访问的变量
环境变量(全局变量)
-
子进程可以访问的变量
自定义变量改成环境变量:
acs@9e0ebfcd82d7:~$ name=yxc # 定义变量 acs@9e0ebfcd82d7:~$ export name # 第一种方法 acs@9e0ebfcd82d7:~$ declare -x name # 第二种方法环境变量改为自定义变量:
acs@9e0ebfcd82d7:~$ export name=yxc # 定义环境变量 acs@9e0ebfcd82d7:~$ declare +x name # 改为自定义变量字符串
字符串可以用单引号,也可以用双引号,也可以不用引号。
单引号与双引号的区别:
-
单引号中的内容会原样输出,不会执行、不会取变量;
-
双引号中的内容可以执行、可以取变量;
name=yxc # 不用引号 echo 'hello, $name \"hh\"' # 单引号字符串,输出 hello, $name \"hh\" echo "hello, $name \"hh\"" # 双引号字符串,输出 hello, yxc "hh"获取字符串长度
name="yxc"
echo ${#name} # 输出3
提取子串
name="hello, yxc"
echo ${name:0:5} # 提取从0开始的5个字符
默认变量
文件参数变量
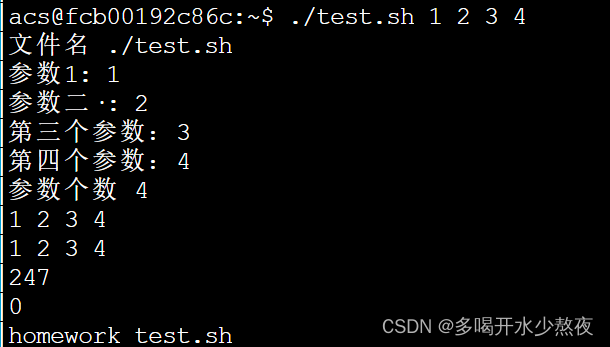
在执行shell脚本时,可以向脚本传递参数。$1是第一个参数,$2是第二个参数,以此类推。特殊的,$0是文件名(包含路径)。例如:
创建文件test.sh:
#! /bin/bash
echo "文件名:"$0
echo "第一个参数:"$1
echo "第二个参数:"$2
echo "第三个参数:"$3
echo "第四个参数:"$4
然后执行该脚本:
acs@9e0ebfcd82d7:~$ chmod +x test.sh
acs@9e0ebfcd82d7:~$ ./test.sh 1 2 3 4
文件名:./test.sh
第一个参数:1
第二个参数:2
第三个参数:3
第四个参数:4
其它参数相关变量
| 参数 | 说明 |
|---|---|
| $# | 代表文件传入的参数个数,如上例中值为4 |
| $* | 由所有参数构成的用空格隔开的字符串,如上例中值为"$1 $2 $3 $4" |
| $@ | 每个参数分别用双引号括起来的字符串,如上例中值为"$1" “$2” “$3” “$4” |
| $$ | 脚本当前运行的进程ID |
| $? | 上一条命令的退出状态(注意不是stdout,而是exit code)。0表示正常退出,其他值表示错误 |
| $(command) | 返回command这条命令的stdout(可嵌套) |
command | 返回command这条命令的stdout(不可嵌套) |
最后两个的例子

数组
数组中可以存放多个不同类型的值,只支持一维数组,初始化时不需要指明数组大小。
数组下标从0开始。
定义
数组用小括号表示,元素之间用空格隔开。例如:
array=(1 abc "def" yxc)
也可以直接定义数组中某个元素的值:
array[0]=1
array[1]=abc
array[2]="def"
array[3]=yxc
读取数组中某个元素的值
格式:
${array[index]}
例如:
array=(1 abc "def" yxc)
echo ${array[0]}
echo ${array[1]}
echo ${array[2]}
echo ${array[3]}
读取整个数组
格式:
${array[@]} # 第一种写法
${array[*]} # 第二种写法
例如:
array=(1 abc "def" yxc)
echo ${array[@]} # 第一种写法
echo ${array[*]} # 第二种写法
数组长度
类似于字符串
${#array[@]} # 第一种写法
${#array[*]} # 第二种写法
例如:
array=(1 abc "def" yxc)
echo ${#array[@]} # 第一种写法
echo ${#array[*]} # 第二种写法
expr命令
expr命令用于求表达式的值,格式为:
expr 表达式
表达式说明:
-
用空格隔开每一项
-
用反斜杠放在shell特定的字符前面(发现表达式运行错误时,可以试试转义)
-
对包含空格和其他特殊字符的字符串要用引号括起来
-
expr会在stdout中输出结果也就是需要通过`` 或$()进行输出结果。如果为逻辑关系表达式,则结果为真,stdout为1,否则为0。
-
expr的exit code:如果为逻辑关系表达式,则结果为真,exit code为0,否则为1。
字符串表达式
length STRING
返回STRING的长度index STRING CHARSET
CHARSET中任意单个字符在STRING中最前面的字符位置,下标从1开始。如果在STRING中完全不存在CHARSET中的字符,则返回0。substr STRING POSITION LENGTH
返回STRING字符串中从POSITION开始,长度最大为LENGTH的子串。如果POSITION或LENGTH为负数,0或非数值,则返回空字符串。
示例:
str="Hello World!"
echo `expr length "$str"` # ``不是单引号,表示执行该命令,输出12
echo `expr index "$str" aWd` # 输出7,下标从1开始
echo `expr substr "$str" 2 3` # 输出 ell
整数表达式
expr支持普通的算术操作,算术表达式优先级低于字符串表达式,高于逻辑关系表达式。
+ -
加减运算。两端参数会转换为整数,如果转换失败则报错。
* / %
乘,除,取模运算。两端参数会转换为整数,如果转换失败则报错。()可以改变优先级,但需要用反斜杠转义
示例:
a=3
b=4
echo `expr $a + $b` # 输出7
echo `expr $a - $b` # 输出-1
echo `expr $a \* $b` # 输出12,*需要转义
echo `expr $a / $b` # 输出0,整除
echo `expr $a % $b` # 输出3
echo `expr \( $a + 1 \) \* \( $b + 1 \)` # 输出20,值为(a + 1) * (b + 1)
逻辑关系表达式
|
如果第一个参数非空且非0,则返回第一个参数的值,否则返回第二个参数的值,但要求第二个参数的值也是非空或非0,否则返回0。如果第一个参数是非空或非0时,不会计算第二个参数。&
如果两个参数都非空且非0,则返回第一个参数,否则返回0。如果第一个参为0或为空,则不会计算第二个参数。< <= = == != >= >
比较两端的参数,如果为true,则返回1,否则返回0。”==”是”=”的同义词。”expr”首先尝试将两端参数转换为整数,并做算术比较,如果转换失败,则按字符集排序规则做字符比较。()可以改变优先级,但需要用反斜杠转义
示例:
a=3
b=4
echo `expr $a \> $b` # 输出0,>需要转义
echo `expr $a '<' $b` # 输出1,也可以将特殊字符用引号引起来
echo `expr $a '>=' $b` # 输出0
echo `expr $a \<\= $b` # 输出1
c=0
d=5
echo `expr $c \& $d` # 输出0
echo `expr $a \& $b` # 输出3
echo `expr $c \| $d` # 输出5
echo `expr $a \| $b` # 输出3
乘法运算的 * 的使用除转义外,还有直接加单引号这种方式也可以,如
echo `expr $a '*' $b`
这几个运算之间不管需不需要转义都可以直接加上’',这个作用应该是告诉解释器我和你们之前定义的不一样吧,原来是什么意思就按什么意思来。那些需要转义的应该是解释器赋予了他们新的功能,一旦我们加上",就意味着不是按解释器赋予的新的意思执行。回归到最原始的意义.
read命令
read命令用于从标准输入中读取单行数据。当读到文件结束符时,exit code为1,否则为0。
参数说明
-
-p: 后面可以接提示信息 -
-t:后面跟秒数,定义输入字符的等待时间,超过等待时间后会自动忽略此命令实例:
acs@9e0ebfcd82d7:~$ read name # 读入name的值
acwing yxc # 标准输入
acs@9e0ebfcd82d7:~$ echo $name # 输出name的值
acwing yxc #标准输出
acs@9e0ebfcd82d7:~$ read -p "Please input your name: " -t 30 name # 读入name的值,等待时间30秒
Please input your name: acwing yxc # 标准输入
acs@9e0ebfcd82d7:~$ echo $name # 输出name的值
acwing yxc # 标准输出
echo命令
echo用于输出字符串。命令格式:
echo STRING
显示普通字符串
echo "Hello AC Terminal"
echo Hello AC Terminal # 引号可以省略
显示转义字符
echo "\"Hello AC Terminal\"" # 注意只能使用双引号,如果使用单引号,则不转义
echo \"Hello AC Terminal\" # 也可以省略双引号
显示变量
name=yxc
echo "My name is $name" # 输出 My name is yxc
显示换行
echo -e "Hi\n" # -e 开启转义
echo "acwing"
输出结果:
Hi
acwing
显示不换行
echo -e "Hi \c" # -e 开启转义 \c 不换行
echo "acwing"
输出结果:
Hi acwing
显示结果定向至文件
echo "Hello World" > output.txt # 将内容以覆盖的方式输出到output.txt中
原样输出字符串,不进行转义或取变量(用单引号)
name=acwing
echo '$name\"'
输出结果
$name\"
显示命令的执行结果
echo `date`
输出结果:
Wed Sep 1 11:45:33 CST 2021
\\ \a \b \c \d \e \f \n \r \t \v 这些是要在有 - e 的时候才能起作用, 其他时候的转义是不用- e也能转义的。
help echo
printf命令
printf命令用于格式化输出,类似于C/C++中的printf函数。
默认不会在字符串末尾添加换行符。
命令格式:
printf format-string [arguments...]
用法示例
脚本内容:
printf "%10d.\n" 123 # 占10位,右对齐
printf "%-10.2f.\n" 123.123321 # 占10位,保留2位小数,左对齐
printf "My name is %s\n" "yxc" # 格式化输出字符串
printf "%d * %d = %d\n" 2 3 `expr 2 \* 3` # 表达式的值作为参数
输出结果:
123.
123.12 .
My name is yxc
2 * 3 = 6
test命令与判断符号[]
逻辑运算符&&和||
-
&& 表示与,|| 表示或
-
二者具有短路原则:
expr1 && expr2:当expr1为假时,直接忽略expr2
expr1 || expr2:当expr1为真时,直接忽略expr2 -
表达式的exit code为0,表示真;为非零,表示假。(与C/C++中的定义相反)
test命令
在命令行中输入
help test,可以查看test命令的用法。
test命令用于判断文件类型,以及对变量做比较。
test命令用exit code返回结果,而不是使用stdout。0表示真,非0表示假。

例如:
test 2 -lt 3 # 为真,返回值为0
echo $? # 输出上个命令的返回值,输出0
acs@9e0ebfcd82d7:~$ ls # 列出当前目录下的所有文件
homework output.txt test.sh tmp
acs@9e0ebfcd82d7:~$ test -e test.sh && echo "exist" || echo "Not exist"
exist # test.sh 文件存在
acs@9e0ebfcd82d7:~$ test -e test2.sh && echo "exist" || echo "Not exist"
Not exist # testh2.sh 文件不存在
文件类型判断
命令格式:
test -e filename # 判断文件是否存在
| 测试参数 | 代表意义 |
|---|---|
| -e | 文件是否存在 |
| -f | 是否为文件 |
| -d | 是否为目录 |
文件权限判断
命令格式:
test -r filename # 判断文件是否可读
| 测试参数 | 代表意义 |
|---|---|
| -r | 文件是否可读 |
| -w | 文件是否可写 |
| -x | 文件是否可执行 |
| -s | 是否为非空文件 |
整数间的比较
命令格式:
test $a -eq $b # a是否等于b
| 测试参数 | 代表意义 |
|---|---|
| -eq | a是否等于b |
| -ne | a是否不等于b |
| -gt | a是否大于b |
| -lt | a是否小于b |
| -ge | a是否大于等于b |
| -le | a是否小于等于b |
字符串比较
| 测试参数 | 代表意义 |
|---|---|
| test -z STRING | 判断STRING是否为空,如果为空,则返回true |
| test -n STRING | 判断STRING是否非空,如果非空,则返回true(-n可以省略) |
| test str1 == str2 | 判断str1是否等于str2 |
| test str1 != str2 | 判断str1是否不等于str2 |
多重条件判定
命令格式:
test -r filename -a -x filename
and or
| 测试参数 | 代表意义 |
|---|---|
| -a | 两条件是否同时成立 |
| -o | 两条件是否至少一个成立 |
| ! | 取反。如 test ! -x file,当file不可执行时,返回true |
判断符号[]
[]与test用法几乎一模一样,更常用于if语句中。另外[[]]是[]的加强版,支持的特性更多。
例如:
[ 2 -lt 3 ] # 为真,返回值为0
echo $? # 输出上个命令的返回值,输出0
acs@9e0ebfcd82d7:~$ ls # 列出当前目录下的所有文件
homework output.txt test.sh tmp
acs@9e0ebfcd82d7:~$ [ -e test.sh ] && echo "exist" || echo "Not exist"
exist # test.sh 文件存在
acs@9e0ebfcd82d7:~$ [ -e test2.sh ] && echo "exist" || echo "Not exist"
Not exist # testh2.sh 文件不存在
注意:
- []内的每一项都要用空格隔开
- 中括号内的变量,最好用双引号括起来
- 中括号内的常数,最好用单或双引号括起来
例如:
name="acwing yxc"
[ $name == "acwing yxc" ] # 错误,等价于 [ acwing yxc == "acwing yxc" ],参数太多
[ "$name" == "acwing yxc" ] # 正确
判断语句
if…then形式
类似于C/C++中的if-else语句。
单层if
命令格式:
if condition
then
语句1
语句2
...
fi
示例:
a=3
b=4
if [ "$a" -lt "$b" ] && [ "$a" -gt 2 ]
then
echo ${a}在范围内
fi
输出结果:
3在范围内


单层if-else
命令格式
if condition
then
语句1
语句2
...
else
语句1
语句2
...
fi
示例:
a=3
b=4
if ! [ "$a" -lt "$b" ]
then
echo ${a}不小于${b}
else
echo ${a}小于${b}
fi
输出结果:
3小于4
多层if-elif-elif-else
命令格式
if condition
then
语句1
语句2
...
elif condition
then
语句1
语句2
...
elif condition
then
语句1
语句2
else
语句1
语句2
...
fi
示例:
a=4
if [ $a -eq 1 ]
then
echo ${a}等于1
elif [ $a -eq 2 ]
then
echo ${a}等于2
elif [ $a -eq 3 ]
then
echo ${a}等于3
else
echo 其他
fi
输出结果:
其他
case…esac形式
类似于C/C++中的switch语句。
命令格式
case $变量名称 in
值1)
语句1
语句2
...
;; # 类似于C/C++中的break
值2)
语句1
语句2
...
;;
*) # 类似于C/C++中的default
语句1
语句2
...
;;
esac
示例:
a=4
case $a in
1)
echo ${a}等于1
;;
2)
echo ${a}等于2
;;
3)
echo ${a}等于3
;;
*)
echo 其他
;;
esac
输出结果:
其他
循环语句
for…in…do…done
命令格式:
for var in val1 val2 val3
do
语句1
语句2
...
done
示例1,输出a 2 cc,每个元素一行:
for i in a 2 cc
do
echo $i
done
示例2,输出当前路径下的所有文件名,每个文件名一行:
for file in `ls`
do
echo $file
done
示例3,输出1-10
for i in $(seq 1 10)
do
echo $i
done
示例4,使用{1…10} 或者 {a…z}
for i in {a..z}
do
echo $i
done
for ((…;…;…)) do…done
命令格式:
for ((expression; condition; expression))
do
语句1
语句2
done
示例,输出1-10,每个数占一行:
for ((i=1; i<=10; i++))
do
echo $i
done
while…do…done循环
命令格式:
while condition
do
语句1
语句2
...
done
示例,文件结束符为Ctrl+d,输入文件结束符后read指令返回false。
while read name
do
echo $name
done
until…do…done循环
当条件为真时结束。
命令格式:
until condition
do
语句1
语句2
...
done
示例,当用户输入yes或者YES时结束,否则一直等待读入。
until [ "${word}" == "yes" ] || [ "${word}" == "YES" ]
do
read -p "Please input yes/YES to stop this program: " word
done
break命令
跳出当前一层循环,注意与C/C++不同的是:break不能跳出case语句。
示例
while read name
do
for ((i=1;i<=10;i++))
do
case $i in
8)
break
;;
*)
echo $i
;;
esac
done
done
该示例每读入非EOF的字符串,会输出一遍1-7。
该程序可以输入Ctrl+d文件结束符来结束,也可以直接用Ctrl+c杀掉该进程。
continue命令
跳出当前循环。
示例:
for ((i=1;i<=10;i++))
do
if [ `expr $i % 2` -eq 0 ]
then
continue
fi
echo $i
done
该程序输出1-10中的所有奇数。
死循环的处理方式
如果AC Terminal可以打开该程序,则输入Ctrl+c即可。
否则可以直接关闭进程:
-
使用
top命令找到进程的PID -
输入
kill -9 PID即可关掉此进程
函数
bash中的函数类似于C/C++中的函数,但return的返回值与C/C++不同,返回的是exit code,取值为0-255,0表示正常结束。
如果想获取函数的输出结果,可以通过echo输出到stdout中,然后通过$(function_name)来获取stdout中的结果。
函数的return值可以通过$?来获取。
命令格式:
[function] func_name() { # function关键字可以省略
语句1
语句2
...
}
不获取 return值和stdout值
示例
func() {
name=yxc
echo "Hello $name"
}
func
输出结果:
Hello yxc
获取 return值和stdout值
不写return时,默认return 0。
示例
func() {
name=yxc
echo "Hello $name"
return 123
}
output=$(func)
ret=$?
echo "output = $output"
echo "return = $ret"
输出结果:
output = Hello yxc
return = 123
函数的输入参数
在函数内,$1表示第一个输入参数,$2表示第二个输入参数,依此类推。
注意:函数内的$0仍然是文件名,而不是函数名。
示例:
func() { # 递归计算 $1 + ($1 - 1) + ($1 - 2) + ... + 0
word=""
while [ "${word}" != 'y' ] && [ "${word}" != 'n' ]
do
read -p "要进入func($1)函数吗?请输入y/n:" word
done
if [ "$word" == 'n' ]
then
echo 0
return 0
fi
if [ $1 -le 0 ]
then
echo 0
return 0
fi
sum=$(func $(expr $1 - 1))
echo $(expr $sum + $1)
}
echo $(func 10)
输出结果:
55
函数内的局部变量
可以在函数内定义局部变量,作用范围仅在当前函数内。
可以在递归函数中定义局部变量。
命令格式:
local 变量名=变量值
例如:
#! /bin/bash
func() {
local name=yxc
echo $name
}
func
echo $name
输出结果:
yxc
第一行为函数内的name变量,第二行为函数外调用name变量,会发现此时该变量不存在。
exit命令
exit命令用来退出当前shell进程,并返回一个退出状态;使用$?可以接收这个退出状态。
exit命令可以接受一个整数值作为参数,代表退出状态。如果不指定,默认状态值是 0。
exit退出状态只能是一个介于 0~255 之间的整数,其中只有 0 表示成功,其它值都表示失败。
示例:
创建脚本test.sh,内容如下:
#! /bin/bash
if [ $# -ne 1 ] # 如果传入参数个数等于1,则正常退出;否则非正常退出。
then
echo "arguments not valid"
exit 1
else
echo "arguments valid"
exit 0
fi
执行该脚本:
acs@9e0ebfcd82d7:~$ chmod +x test.sh
acs@9e0ebfcd82d7:~$ ./test.sh acwing
arguments valid
acs@9e0ebfcd82d7:~$ echo $? # 传入一个参数,则正常退出,exit code为0
0
acs@9e0ebfcd82d7:~$ ./test.sh
arguments not valid
acs@9e0ebfcd82d7:~$ echo $? # 传入参数个数不是1,则非正常退出,exit code为1
1
文件重定向
每个进程默认打开3个文件描述符:
stdin标准输入,从命令行读取数据,文件描述符为0stdout标准输出,向命令行输出数据,文件描述符为1stderr标准错误输出,向命令行输出数据,文件描述符为2
可以用文件重定向将这三个文件重定向到其他文件中。
重定向命令列表
| 命令 | 说明 |
|---|---|
| command > file | 将stdout重定向到file中 |
| command < file | 将stdin重定向到file中 |
| command >> file | 将stdout以追加方式重定向到file中 |
| command n> file | 将文件描述符n重定向到file中 |
| command n>> file | 将文件描述符n以追加方式重定向到file中 |
输入和输出重定向
echo -e "Hello \c" > output.txt # 将stdout重定向到output.txt中
echo "World" >> output.txt # 将字符串追加到output.txt中
read str < output.txt # 从output.txt中读取字符串
echo $str # 输出结果:Hello World
同时重定向stdin和stdout
创建bash脚本:
#! /bin/bash
read a
read b
echo $(expr "$a" + "$b")
创建input.txt,里面的内容为:
3
4
执行命令:
acs@9e0ebfcd82d7:~$ chmod +x test.sh # 添加可执行权限
acs@9e0ebfcd82d7:~$ ./test.sh < input.txt > output.txt # 从input.txt中读取内容,将输出写入output.txt中
acs@9e0ebfcd82d7:~$ cat output.txt # 查看output.txt中的内容
7
引入外部脚本
类似于C/C++中的include操作,bash也可以引入其他文件中的代码。
语法格式:
. filename # 注意点和文件名之间有一个空格
或
source filename
示例
创建test1.sh,内容为:
#! /bin/bash
name=yxc # 定义变量name
然后创建test2.sh,内容为:
#! /bin/bash
source test1.sh # 或 . test1.sh
echo My name is: $name # 可以使用test1.sh中的变量
执行命令:
acs@9e0ebfcd82d7:~$ chmod +x test2.sh
acs@9e0ebfcd82d7:~$ ./test2.sh
My name is: yxc
4.1 ssh登录
获取ssh教程配套的远程服务器账号的信息:
homework 4 getinfo
基本用法
远程登录服务器:
ssh user@hostname
user: 用户名hostname: IP地址或域名
第一次登录时会提示:
The authenticity of host '123.57.47.211 (123.57.47.211)' can't be established.
ECDSA key fingerprint is SHA256:iy237yysfCe013/l+kpDGfEG9xxHxm0dnxnAbJTPpG8.
Are you sure you want to continue connecting (yes/no/[fingerprint])?
输入yes,然后回车即可。
这样会将该服务器的信息记录在~/.ssh/known_hosts文件中。
然后输入密码即可登录到远程服务器中。
默认登录端口号为22。如果想登录某一特定端口:
ssh user@hostname -p 22
配置文件
创建文件 ~/.ssh/config。
然后在文件中输入:
Host myserver1
HostName IP地址或域名
User 用户名
Host myserver2
HostName IP地址或域名
User 用户名
之后再使用服务器时,可以直接使用别名myserver1、myserver2。
密钥登录
创建密钥:
ssh-keygen
然后一直回车即可。
执行结束后,~/.ssh/目录下会多两个文件:
id_rsa:私钥id_rsa.pub:公钥
之后想免密码登录哪个服务器,就将公钥传给哪个服务器即可。
例如,想免密登录myserver服务器。则将公钥中的内容,复制到myserver中的~/.ssh/authorized_keys文件里即可。
也可以使用如下命令一键添加公钥:
ssh-copy-id myserver
执行命令
命令格式:
ssh user@hostname command
例如:
ssh user@hostname ls -a
或者
# 单引号中的$i可以求值
ssh myserver 'for ((i = 0; i < 10; i ++ )) do echo $i; done'
或者
# 双引号中的$i不可以求值
ssh myserver "for ((i = 0; i < 10; i ++ )) do echo $i; done"
单引号是原生字符串,双引号在本地服务器直接解析
关于ssh远程执行命令中单引号与双引号的问题
远程执行脚本:脚本中的内容可视为是双引号包含起来的。
远程执行命令:例如:ssh user@remote_host "COMMOND":
- 使用单引号的时候,COMMAND中定义的命令字符都会在本地被去掉特殊意义,只是一串完全没有解析引用的字符串传过去远程主机;
- 如果是使用双引号时,COMMAND中定义的特殊命令字符都会在本地被解析引用,比如:COMMAND中的反引号、引号、EXTRACT_DIR变量、i变量。如果此时要在COMMAND中的特殊命令字符前加上转义符号“\”,这样就会去掉在本地的解析引用;但是如果COMMAND中变量有一个BAK_TIME变量引用前是不用加转义符的,因为这个变量就是希望在本地引用的。(其中的变量名都是举个例子)
总结: ssh远程执行的命令中使用单引号时,所有变量、特殊字符都不会在本地解析引用,会原封不动地传过去远程主机;如果在命令中有变量或特殊字符在本地进行解析引用的,命令就得使用双引号括起来,此时命令中不需要在本地解析引用的变量或特殊字符就需要在其前面加上转义符\。
ssh远程执行命令
ssh server "cd homework ; ls"
基本能完成常用的对于远程节点的管理了,几个注意的点:
-
如果不加双引号,第二个ls命令在本地执行
-
分号,两个命令之间用分号隔开
整条ssh命令用引号包围
a=1
ssh myserver echo $a # 正确
ssh myserver "echo $a" # 正确
ssh myserver 'echo $a' # 错误
双引号在本地进行解析,所以传过去命令不是echo $a,而是echo 1
单引号在服务器进行解析,传过去的是echo $a,服务器不知道$a的值,解析为空
ssh myserver "for ((i = 0; i < 10; i ++ )) do echo $i; done" # 错误
ssh myserver 'for ((i = 0; i < 10; i ++ )) do echo $i; done' # 正确
双引号在本地进行解析,本地不知道$i的值,解析为空
单引号在服务器进行解析,$i的值在服务器随循环变化
shell命令变量中的空格问题(用ssh执行)
ssh ser mkdir homework/lesson_4/homework_4/\"$1\" # 正确
ssh ser mkdir homework/lesson_4/homework_4/"'$1'" # 正确
ssh ser mkdir homework/lesson_4/homework_4/'"$1"' # 错误
-
如果shell命令(用ssh执行)中有空格,变量用双引号引起来
-
最外层是双引号,内嵌单引号,$等特殊符号依旧可以识别
-
最外层是单引号,内嵌双引号,$等特殊符号无法识别
-
mkdir “my dir” -> mkdir my dir ->创建my和dir文件夹 -
mkdir"'my dir'" ->mkdir 'my dir'->创建my dir文件夹
4.2scp传文件
服务器和服务器之间传数据,可以:服务器->本地->服务器,免去服务器和服务器之间的授权过程
基本用法
命令格式:
scp source destination
将source路径下的文件复制到destination中
一次复制多个文件:
scp source1 source2 destination
复制文件夹:
scp -r ~/tmp myserver:/home/acs/
将本地家目录中的tmp文件夹复制到myserver服务器中的/home/acs/目录下。
scp -r ~/tmp myserver:homework/
将本地家目录中的tmp文件夹复制到myserver服务器中的~/homework/目录下。
scp -r myserver:homework .
将myserver服务器中的~/homework/文件夹复制到本地的当前路径下。
指定服务器的端口号:
scp -P 22 source1 source2 destination
注意: scp的-r -P等参数尽量加在source和destination之前。
使用scp配置其他服务器的vim和tmux
scp ~/.vimrc ~/.tmux.conf myserver:
.vimrc配置文件
" An example for a vimrc file.
"
" To use it, copy it to
" for Unix and OS/2: ~/.vimrc
" for Amiga: s:.vimrc
" for MS-DOS and Win32: $VIM\_vimrc
" for OpenVMS: sys$login:.vimrc
" When started as "evim", evim.vim will already have done these settings.
if v:progname =~? "evim"
finish
endif
" Use Vim settings, rather then Vi settings (much better!).
" This must be first, because it changes other options as a side effect.
set nocompatible
" allow backspacing over everything in insert mode
set backspace=indent,eol,start
if has("vms")
set nobackup " do not keep a backup file, use versions instead
else
set backup " keep a backup file
endif
set history=50 " keep 50 lines of command line history
set ruler " show the cursor position all the time
set showcmd " display incomplete commands
set incsearch " do incremental searching
"==========================================================================
"My Setting-sunshanlu
"==========================================================================
vmap <leader>y :w! /tmp/vitmp<CR>
nmap <leader>p :r! cat /tmp/vitmp<CR>
"语法高亮
syntax enable
syntax on
"显示行号
set nu
"修改默认注释颜色
"hi Comment ctermfg=DarkCyan
"允许退格键删除
"set backspace=2
"启用鼠标
set mouse=a
set selection=exclusive
set selectmode=mouse,key
"按C语言格式缩进
set cindent
set autoindent
set smartindent
set shiftwidth=4
" 允许在有未保存的修改时切换缓冲区
"set hidden
" 设置无备份文件
set writebackup
set nobackup
"显示括号匹配
set showmatch
"括号匹配显示时间为1(单位是十分之一秒)
set matchtime=5
"显示当前的行号列号:
set ruler
"在状态栏显示正在输入的命令
set showcmd
set foldmethod=syntax
"默认情况下不折叠
set foldlevel=100
" 开启状态栏信息
set laststatus=2
" 命令行的高度,默认为1,这里设为2
set cmdheight=2
" 显示Tab符,使用一高亮竖线代替
set list
"set listchars=tab:\|\ ,
set listchars=tab:>-,trail:-
"侦测文件类型
filetype on
"载入文件类型插件
filetype plugin on
"为特定文件类型载入相关缩进文件
filetype indent on
" 启用自动补全
filetype plugin indent on
"设置编码自动识别, 中文引号显示
filetype on "打开文件类型检测
"set fileencodings=euc-cn,ucs-bom,utf-8,cp936,gb2312,gb18030,gbk,big5,euc-jp,euc-kr,latin1
set fileencodings=utf-8,gb2312,gbk,gb18030
"这个用能很给劲,不管encoding是什么编码,都能将文本显示汉字
"set termencoding=gb2312
set termencoding=utf-8
"新建文件使用的编码
set fileencoding=utf-8
"set fileencoding=gb2312
"用于显示的编码,仅仅是显示
set encoding=utf-8
"set encoding=utf-8
"set encoding=euc-cn
"set encoding=gbk
"set encoding=gb2312
"set ambiwidth=double
set fileformat=unix
"设置高亮搜索
set hlsearch
"在搜索时,输入的词句的逐字符高亮
set incsearch
" 着色模式
set t_Co=256
"colorscheme wombat256mod
"colorscheme gardener
"colorscheme elflord
colorscheme desert
"colorscheme evening
"colorscheme darkblue
"colorscheme torte
"colorscheme default
" 字体 && 字号
set guifont=Monaco:h10
"set guifont=Consolas:h10
" :LoadTemplate 根据文件后缀自动加载模板
"let g:template_path='/home/ruchee/.vim/template/'
" :AuthorInfoDetect 自动添加作者、时间等信息,本质是NERD_commenter && authorinfo的结合
""let g:vimrc_author='sunshanlu'
""let g:vimrc_email='sunshanlu@baidu.com'
""let g:vimrc_homepage='http://www.sunshanlu.com'
"
"
" Ctrl + E 一步加载语法模板和作者、时间信息
""map <c-e> <ESC>:AuthorInfoDetect<CR><ESC>Gi
""imap <c-e> <ESC>:AuthorInfoDetect<CR><ESC>Gi
""vmap <c-e> <ESC>:AuthorInfoDetect<CR><ESC>Gi
" ======= 引号 && 括号自动匹配 ======= "
"
":inoremap ( ()<ESC>i
":inoremap ) <c-r>=ClosePair(')')<CR>
"
":inoremap { {}<ESC>i
"
":inoremap } <c-r>=ClosePair('}')<CR>
"
":inoremap [ []<ESC>i
"
":inoremap ] <c-r>=ClosePair(']')<CR>
"
":inoremap < <><ESC>i
"
":inoremap > <c-r>=ClosePair('>')<CR>
"
"":inoremap " ""<ESC>i
"
":inoremap ' ''<ESC>i
"
":inoremap ` ``<ESC>i
"
":inoremap * **<ESC>i
" 每行超过80个的字符用下划线标示
""au BufRead,BufNewFile *.s,*.asm,*.h,*.c,*.cpp,*.java,*.cs,*.lisp,*.el,*.erl,*.tex,*.sh,*.lua,*.pl,*.php,*.tpl,*.py,*.rb,*.erb,*.vim,*.js,*.jade,*.coffee,*.css,*.xml,*.html,*.shtml,*.xhtml Underlined /.\%81v/
"
"
" For Win32 GUI: remove 't' flag from 'guioptions': no tearoff menu entries
" let &guioptions = substitute(&guioptions, "t", "", "g")
" Don't use Ex mode, use Q for formatting
map Q gq
" This is an alternative that also works in block mode, but the deleted
" text is lost and it only works for putting the current register.
"vnoremap p "_dp
" Switch syntax highlighting on, when the terminal has colors
" Also switch on highlighting the last used search pattern.
if &t_Co > 2 || has("gui_running")
syntax on
set hlsearch
endif
" Only do this part when compiled with support for autocommands.
if has("autocmd")
" Enable file type detection.
" Use the default filetype settings, so that mail gets 'tw' set to 72,
" 'cindent' is on in C files, etc.
" Also load indent files, to automatically do language-dependent indenting.
filetype plugin indent on
" Put these in an autocmd group, so that we can delete them easily.
augroup vimrcEx
au!
" For all text files set 'textwidth' to 80 characters.
autocmd FileType text setlocal textwidth=80
" When editing a file, always jump to the last known cursor position.
" Don't do it when the position is invalid or when inside an event handler
" (happens when dropping a file on gvim).
autocmd BufReadPost *
\ if line("'\"") > 0 && line("'\"") <= line("$") |
\ exe "normal g`\"" |
\ endif
augroup END
else
set autoindent " always set autoindenting on
endif " has("autocmd")
" 增加标行高亮
set cursorline
hi CursorLine cterm=NONE ctermbg=darkred ctermfg=white
" 设置tab是四个空格
set ts=4
set expandtab
" 主要给Tlist使用
let Tlist_Exit_OnlyWindow = 1
let Tlist_Auto_Open = 1
.tmux.config配置文件:
set-option -g status-keys vi
setw -g mode-keys vi
setw -g monitor-activity on
# setw -g c0-change-trigger 10
# setw -g c0-change-interval 100
# setw -g c0-change-interval 50
# setw -g c0-change-trigger 75
set-window-option -g automatic-rename on
set-option -g set-titles on
set -g history-limit 100000
#set-window-option -g utf8 on
# set command prefix
set-option -g prefix C-a
unbind-key C-b
bind-key C-a send-prefix
bind h select-pane -L
bind j select-pane -D
bind k select-pane -U
bind l select-pane -R
bind -n M-Left select-pane -L
bind -n M-Right select-pane -R
bind -n M-Up select-pane -U
bind -n M-Down select-pane -D
bind < resize-pane -L 7
bind > resize-pane -R 7
bind - resize-pane -D 7
bind + resize-pane -U 7
bind-key -n M-l next-window
bind-key -n M-h previous-window
set -g status-interval 1
# status bar
set -g status-bg black
set -g status-fg blue
#set -g status-utf8 on
set -g status-justify centre
set -g status-bg default
set -g status-left " #[fg=green]#S@#H #[default]"
set -g status-left-length 20
# mouse support
# for tmux 2.1
# set -g mouse-utf8 on
set -g mouse on
#
# for previous version
#set -g mode-mouse on
#set -g mouse-resize-pane on
#set -g mouse-select-pane on
#set -g mouse-select-window on
#set -g status-right-length 25
set -g status-right "#[fg=green]%H:%M:%S #[fg=magenta]%a %m-%d #[default]"
# fix for tmux 1.9
bind '"' split-window -vc "#{pane_current_path}"
bind '%' split-window -hc "#{pane_current_path}"
bind 'c' new-window -c "#{pane_current_path}"
# run-shell "powerline-daemon -q"
# vim: ft=conf
5.1 git
1.git教程
代码托管平台:git.acwing.com

暂存区的内容放到新的节点里面,HEAD后移一位
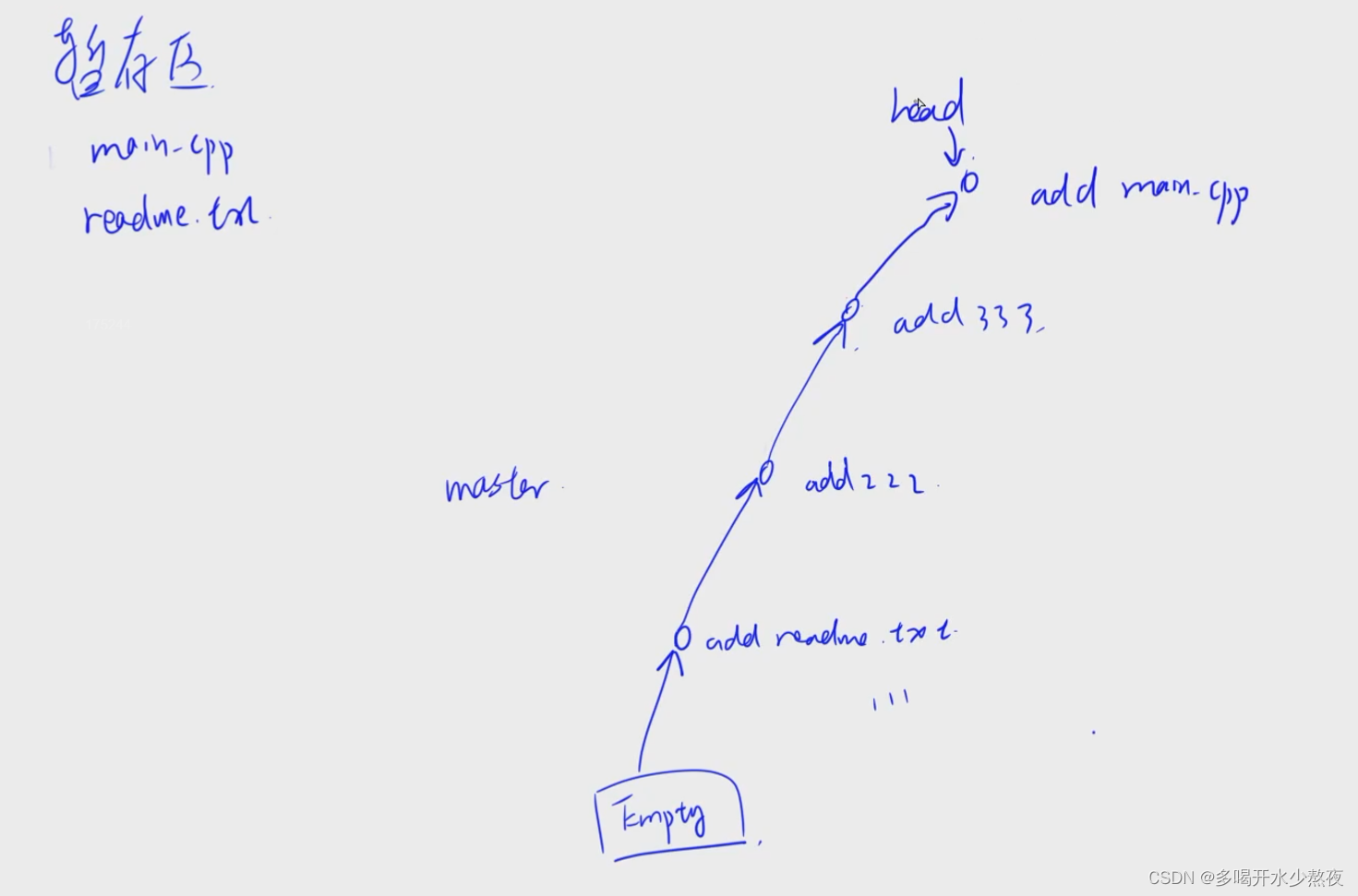

当在其他分支修改后,回到master分支,修改文件并创建新的节点(commit),执行merge命令会有冲突(如git merge dev2),此时vim 修改的文件,会有两次修改的记录,按自己需求修改后,git add. -> git commit -m "xxxx",会在master新创建一个节点,并把修改后的内容和HEAD移到当前节点,再删掉分支(git branch -d dev2)
将云端的分支拉下来,先创建和云端同名的分支(git checkout -b dev4),然后执行命令:git branch --set-upstream-to=origin/dev4 dev4,将本地分支和云端分支对应起,再执行git pull,将远程仓库的当前分支与本地仓库的当前分支合并
然后可以git checkout master ,将dev4合并到master,git merge dev4 ,删掉本地和云端的dev4git branch -d dev4 ,git push -d origin dev4,再用git push同步到云端
暂存区有修改内容,本地工作区也有修改内容,如果服务器挂了,我们需要去修改,但是不想将当前的内容提交到日志(版本库)里面,可以用git stash ,将当前的修改存到一个栈里
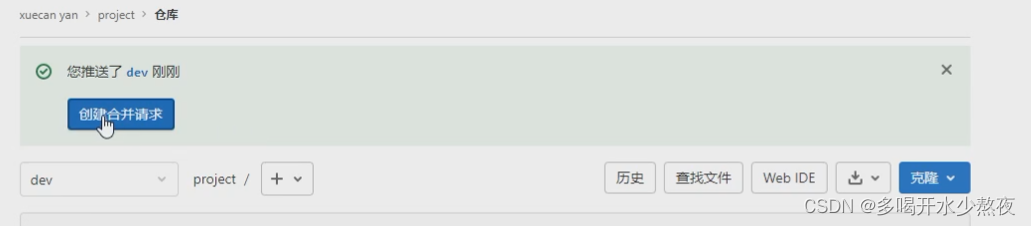
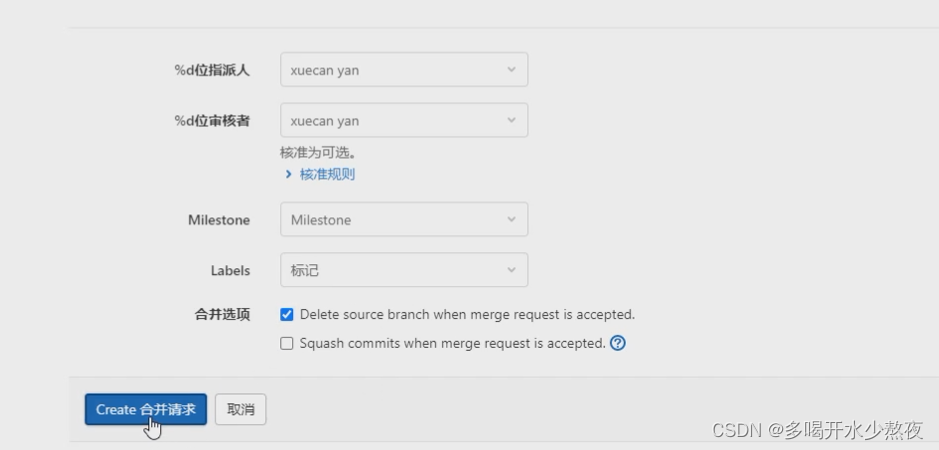
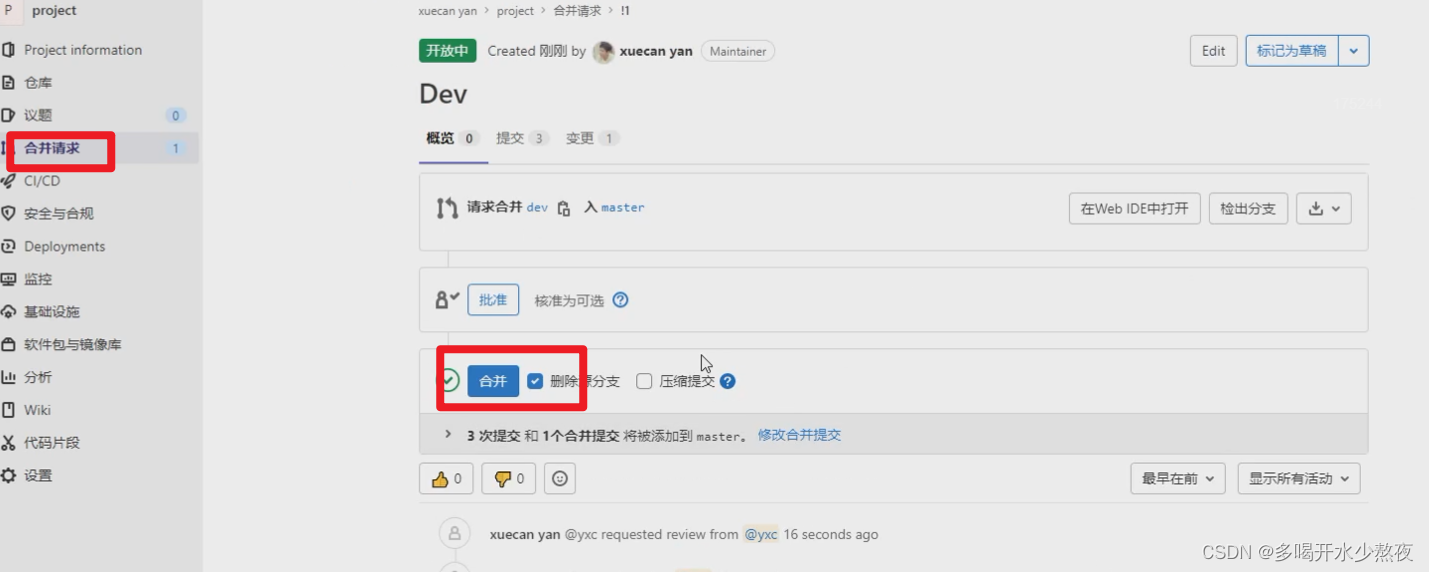
分支:云端合并到云端:在分支中点击“创建合并请求”,审核人改成leader,title去掉Draft,点击“create 合并请求”,在“合并请求”里面点击合并,则当前分支会合并到master
1.1. git基本概念
-
工作区:仓库的目录。工作区是独立于各个分支的。
-
暂存区:数据暂时存放的区域,类似于工作区写入版本库前的缓存区。暂存区是独立于各
个分支的。
-
版本库:存放所有已经提交到本地仓库的代码版本
-
版本结构:树结构,树中每个节点代表一个代码版本。
git add:工作区代码放到暂存区里,git commit -m "xxx"最后提交到版本库里
1.2 git常用命令
-
git config --global user.name xxx:设置全局用户名,信息记录在~/.gitconfig文件中 -
git config --global user.email xxx@xxx.com:设置全局邮箱地址,信息记录在~/.gitconfig文件中 -
git init:将当前目录配置成git仓库,信息记录在隐藏的.git文件夹中 -
git remote add origin git@git.acwing.com:xxx/XXX.git:第一次连接远程git仓库 -
git remote set-url origin git@git.acwing.com:xxx/XXX.git:更换git仓库 -
git add XX:将XX文件添加到暂存区- git add .`:将所有待加入暂存区的文件加入暂存区
-
git rm --cached XX:将文件从仓库索引目录中删掉( 删除暂存区中的某个文件) -
git commit -m "给自己看的备注信息":将暂存区的内容提交到当前分支 -
git status:查看仓库状态 -
git diff XX:查看XX文件相对于暂存区修改了哪些内容git diff:当工作区有改动,临时区为空,diff的对比是“工作区与最后一次commit提交的仓库的共同文件”;当工作区有改动,临时区不为空,diff对比的是“工作区与暂存区的共同文件”。
-
git log:查看当前分支的所有版本(按q退出)git log --pretty=oneline:放在一行显示
-
git reflog:查看HEAD指针的移动历史(包括被回滚的版本) -
git reset --hard HEAD^或git reset --hard HEAD~:将代码库回滚到上一个版本-
git reset --hard HEAD^^:往上回滚两次,以此类推 -
git reset --hard HEAD~100:往上回滚100个版本 -
git reset --hard 版本号:回滚到某一特定版本 -
git reset .: 撤销上一次提交暂存区的操作 -
git reset: 保留工作目录,并清空暂存区。也就是说,工作目录的修改、暂存区的内容以及由 reset 所导致的新的文件差异,都会被放进工作目录。简而言之,就是「把所有差异都混合(mixed)放在工作目录中」
-
-
git checkout — XX或git restore XX:将XX文件尚未加入暂存区的修改全部撤销 -
git remote add origin git@git.acwing.com:xxx/XXX.git:将本地仓库关联到远程仓库 -
git push -u (第一次需要-u以后不需要):将当前分支推送到远程仓库(-u 参数相当于是让你本地的仓库和远程仓库进行了关联,加了参数-u后,以后即可直接用git push 代替git push origin master)git push origin branch_name:将本地的某个分支推送到远程仓库
-
git clone git@git.acwing.com:xxx/XXX.git:将远程仓库XXX下载到当前目录下 -
git checkout -- .:撤销本地全部没有git add过的修改 -
git checkout -b branch_name:创建并切换到branch_name这个分支 -
git branch:查看所有分支和当前所处分支 -
git checkout branch_name:切换到branch_name这个分支 -
git merge branch_name:将分支branch_name合并到当前分支上 -
git branch -d branch_name:删除本地仓库的branch_name分支 -
git branch branch_name:创建新分支 -
git push --set-upstream origin branch_name:设置本地的branch_name分支对应远程仓库的branch_name分支 -
git push -d origin branch_name:删除远程仓库的branch_name分支 -
git pull:将远程仓库的当前分支与本地仓库的当前分支合并git pull origin branch_name:将远程仓库的branch_name分支与本地仓库的当前分支合并
-
git branch --set-upstream-to=origin/branch_name1 branch_name2:将远程的branch_name1分支与本地的branch_name2分支对应 -
git checkout -t origin/branch_name将远程的branch_name分支拉取到本地 -
git stash:将工作区和暂存区中尚未提交的修改存入栈中 -
git stash apply:将栈顶存储的修改恢复到当前分支,但不删除栈顶元素 -
git stash drop:删除栈顶存储的修改 -
git stash pop:将栈顶存储的修改恢复到当前分支,同时删除栈顶元素 -
git stash list:查看栈中所有元素
2.创建作业 & 测试作业的正确性
homework 5 create # 可以重新创建所有lesson_5的作业
homework 5 test # 可以评测lesson_5的所有作业
3.git命令分类整理
全局设置
- git config --global user.name xxx:设置全局用户名,信息记录在~/.gitconfig文件中
- git config --global user.email xxx@xxx.com:设置全局邮箱地址,信息记录在~/.gitconfig文件中
- git init:将当前目录配置成git仓库,信息记录在隐藏的.git文件夹中
常用命令
- git add XX :将XX文件添加到暂存区
- git commit -m “给自己看的备注信息”:将暂存区的内容提交到当前分支
- git status:查看仓库状态
- git log:查看当前分支的所有版本
- git push -u (第一次需要-u以后不需要) :将当前分支推送到远程仓库
- git clone git@git.acwing.com:xxx/XXX.git:将远程仓库XXX下载到当前目录下
- git branch:查看所有分支和当前所处分支
查看命令
- git diff XX:查看XX文件相对于暂存区修改了哪些内容
- git status:查看仓库状态
- git log:查看当前分支的所有版本
- git log --pretty=oneline:用一行来显示
- git reflog:查看HEAD指针的移动历史(包括被回滚的版本)
- git branch:查看所有分支和当前所处分支
- git pull :将远程仓库的当前分支与本地仓库的当前分支合并
删除命令
- git rm --cached XX:将文件从仓库索引目录中删掉,不希望管理这个文件
- git restore --staged xx:将xx从暂存区里移除
- git checkout — XX或git restore XX:将XX文件尚未加入暂存区的修改全部撤销
代码回滚
- git reset --hard HEAD^ 或git reset --hard HEAD~ :将代码库回滚到上一个版本
- git reset --hard HEAD^^:往上回滚两次,以此类推
- git reset --hard HEAD~100:往上回滚100个版本
- git reset --hard 版本号:回滚到某一特定版本
远程仓库
-
git remote add origin git@git.acwing.com:xxx/XXX.git:将本地仓库关联到远程仓库
-
git push -u (第一次需要-u以后不需要) :将当前分支推送到远程仓库
-
git push origin branch_name:将本地的某个分支推送到远程仓库
-
git clone git@git.acwing.com:xxx/XXX.git:将远程仓库XXX下载到当前目录下
-
git push --set-upstream origin branch_name:设置本地的branch_name分支对应远程仓库的branch_name分支
-
git push -d origin branch_name:删除远程仓库的branch_name分支
-
git checkout -t origin/branch_name 将远程的branch_name分支拉取到本地
-
git pull :将远程仓库的当前分支与本地仓库的当前分支合并
-
git pull origin branch_name:将远程仓库的branch_name分支与本地仓库的当前分支合并
-
git branch --set-upstream-to=origin/branch_name1 branch_name2:将远程的branch_name1分支与本地的branch_name2分支对应
分支命令
-
git branch branch_name:创建新分支
-
git branch:查看所有分支和当前所处分支
-
git checkout -b branch_name:创建并切换到branch_name这个分支
-
git checkout branch_name:切换到branch_name这个分支
-
git merge branch_name:将分支branch_name合并到当前分支上
-
git branch -d branch_name:删除本地仓库的branch_name分支
-
git push --set-upstream origin branch_name:设置本地的branch_name分支对应远程仓库的branch_name分支
-
git push -d origin branch_name:删除远程仓库的branch_name分支
-
git checkout -t origin/branch_name 将远程的branch_name分支拉取到本地
-
git pull :将远程仓库的当前分支与本地仓库的当前分支合并
-
git pull origin branch_name:将远程仓库的branch_name分支与本地仓库的当前分支合并
-
git branch --set-upstream-to=origin/branch_name1 branch_name2:将远程的branch_name1分支与本地的branch_name2分支对应
stash暂存
- git stash:将工作区和暂存区中尚未提交的修改存入栈中
- git stash apply:将栈顶存储的修改恢复到当前分支,但不删除栈顶元素
- git stash drop:删除栈顶存储的修改
- git stash pop:将栈顶存储的修改恢复到当前分支,同时删除栈顶元素
- git stash list:查看栈中所有元素
一些问题
解决git push -u origin master后的:
The authenticity of host 'git.acwing.com (47.93.222.173)' can't be established.
ECDSA key fingerprint is SHA256:OxENYBI4n6Nd8yOqmEdMazWuvBldKlP6ZJnOAAbCaeM.
Are you sure you want to continue connecting (yes/no/[fingerprint])?
输入yes,将git.acwing.com永久加入到已知主机列表中
Warning: Permanently added 'git.acwing.com,47.93.222.173' (ECDSA) to the list of known hosts.
Enumerating objects: 10, done.
Counting objects: 100% (10/10), done.
Compressing objects: 100% (5/5), done.
Writing objects: 100% (10/10), 850 bytes | 850.00 KiB/s, done.
Total 10 (delta 0), reused 0 (delta 0)
To git.acwing.com:DrinkWater/project.git
* [new branch] master -> master
Branch 'master' set up to track remote branch 'master' from 'origin'.
刷新git.acwing.com的项目可出现历史文件与数据
git remote add origin git@git.acwing.com:xxx时出现fatal:remote origin already exist 解决方案:删除现有origin仓库: git remote remove origin,然后再输入上面的命令,输入git push -u origin master,push本地内容到云端
报错:git错误 ! [rejected] master -> master (non-fast-forward)
解决:git pull --rebase origin master
关于 git restore
git restore 命令用于恢复,恢复有两种:从暂存区恢复到工作区(即暂存区内容copy还原工作区)、从HEAD所指版本库恢复到暂存区(版本库内容copy还原暂存区)
1. git restore -- filename # git restore指令使得在工作空间但是不在暂存区的文件撤销更改(内容恢复到没修改之前的状态) -- 可以不加
2. git restore --staged filename # 是将暂存区的文件从暂存区撤出,但不会更改文件的内容。
另外,git checkout -- filename 作用与git restore -- filename一致,都是将文件从暂存区恢复到工作区。
版本恢复中, git reset --hard HEAD^ 是将上个版本的内容copy到工作区以及暂存区,效果应该等同于顺序执行上述的 2、1 命令(即版本库先copy到暂存区,然后暂存区copy到工作区)。
关于 git rm
git rm filename 用于删除,如果工作区和暂存区都有名字为 filename 的文件,那么会给出提示是否要强制删除该文件(同一执行后工作区和暂存区该文件都会消失),如果工作区中该文件已经删除但暂存区还有,那么该命令直接执行,将从暂存区中删除该文件(此时效果等同于直接 git add .,将工作区更改应用于暂存区)。
另一方面,git rm --cached filename 仅仅是在暂存区中将该文件删除,取消跟踪(类似于工作区中刚创建该文件还没有add到暂存区),工作区没有任何变化。
综上,git restore 用于恢复,数据有两种流向;git rm 用于删除,主要是使用 –cached 参数来删除暂存区的内容。假如目前HEAD所指版本中没有该文件,而 工作区和暂存区都有,那么 git restore --staged 将和git rm --cached效果相同。
6. thrift-rpc框架
一个节点上的服务器进程想调用另一个服务器上的进程可以用thrift
不同的进程可以用不同的语言来实现
thrift三步
1.定义接口
2.server
3.client
匹配系统项目实现
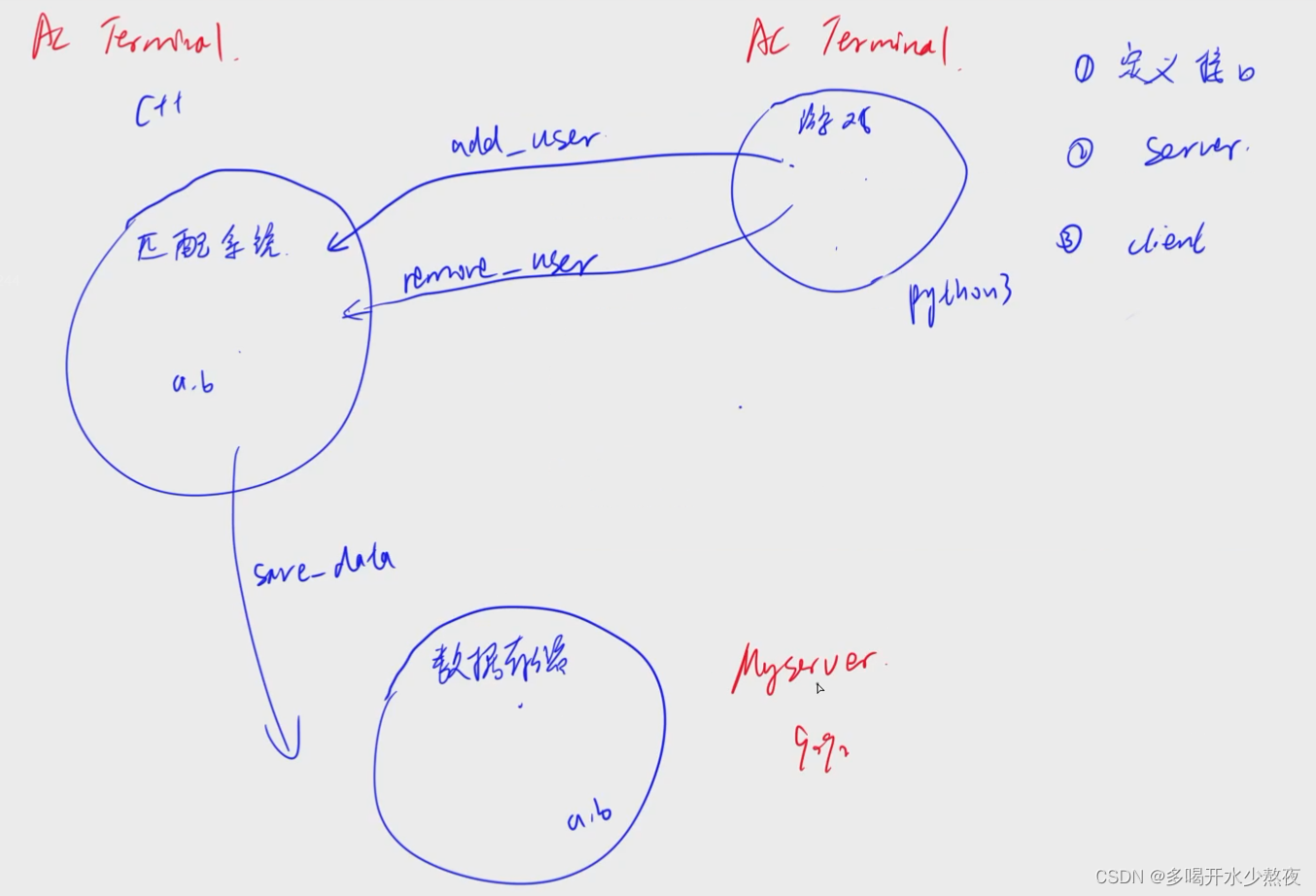
游戏节点需要实现match_client端,匹配系统需要实现match_server和save_client端
#最终项目的结构树
|-- game
| `-- src
| |-- client.py
| `-- match_client
| |-- __init__.py
| |-- __pycache__
| | `-- __init__.cpython-38.pyc
| `-- match
| |-- Match.py
| |-- __init__.py
| |-- __pycache__
| | |-- Match.cpython-38.pyc
| | |-- __init__.cpython-38.pyc
| | `-- ttypes.cpython-38.pyc
| |-- constants.py
| `-- ttypes.py
|-- match_system
| `-- src
| |-- Match.o
| |-- Save.o
| |-- main
| |-- main.cpp
| |-- main.o
| |-- maintmp.cpp
| |-- match_server
| | |-- Match.cpp
| | |-- Match.h
| | |-- match_types.cpp
| | `-- match_types.h
| |-- match_types.o
| `-- save_client
| |-- Save.cpp
| |-- Save.h
| `-- save_types.h
|-- readme.md
`-- thrift
|-- match.thrift
`-- save.thrift
//main.cpp 的所有头文件
#include "match_server/Match.h"
#include "save_client/Save.h"
#include <thrift/concurrency/ThreadManager.h>
#include <thrift/concurrency/ThreadFactory.h>
#include <thrift/protocol/TBinaryProtocol.h>
#include <thrift/server/TSimpleServer.h>
#include <thrift/server/TThreadPoolServer.h>
#include <thrift/server/TThreadedServer.h>
#include <thrift/transport/TServerSocket.h>
#include <thrift/transport/TBufferTransports.h>
#include <thrift/transport/TTransportUtils.h>
#include <thrift/transport/TSocket.h>
#include <thrift/TToString.h>
#include <iostream>
#include <thread>
#include <mutex>
#include <condition_variable>
#include <queue>
#include <vector>
#include <unistd.h>
接口实现
创建相关文件夹,编写接口:/thrift/match.thrift
namespace cpp match_service
struct User {
1: i32 id,
2: string name,
3: i32 score
}
service Match {
i32 add_user(1: User user, 2: string info),
i32 remove_user(1: User user, 2: string info),
}
实现match_server
通过thrift -r --gen cpp ../../thrift/match.thrift ,生成一个C++的服务器,里面包括了一个gen-cpp文件夹,所有的基础c++代码都通过上层命令自动生成,(类似gRPC的作用),实现接口的函数在Match_server.skeleton.cpp文件中。
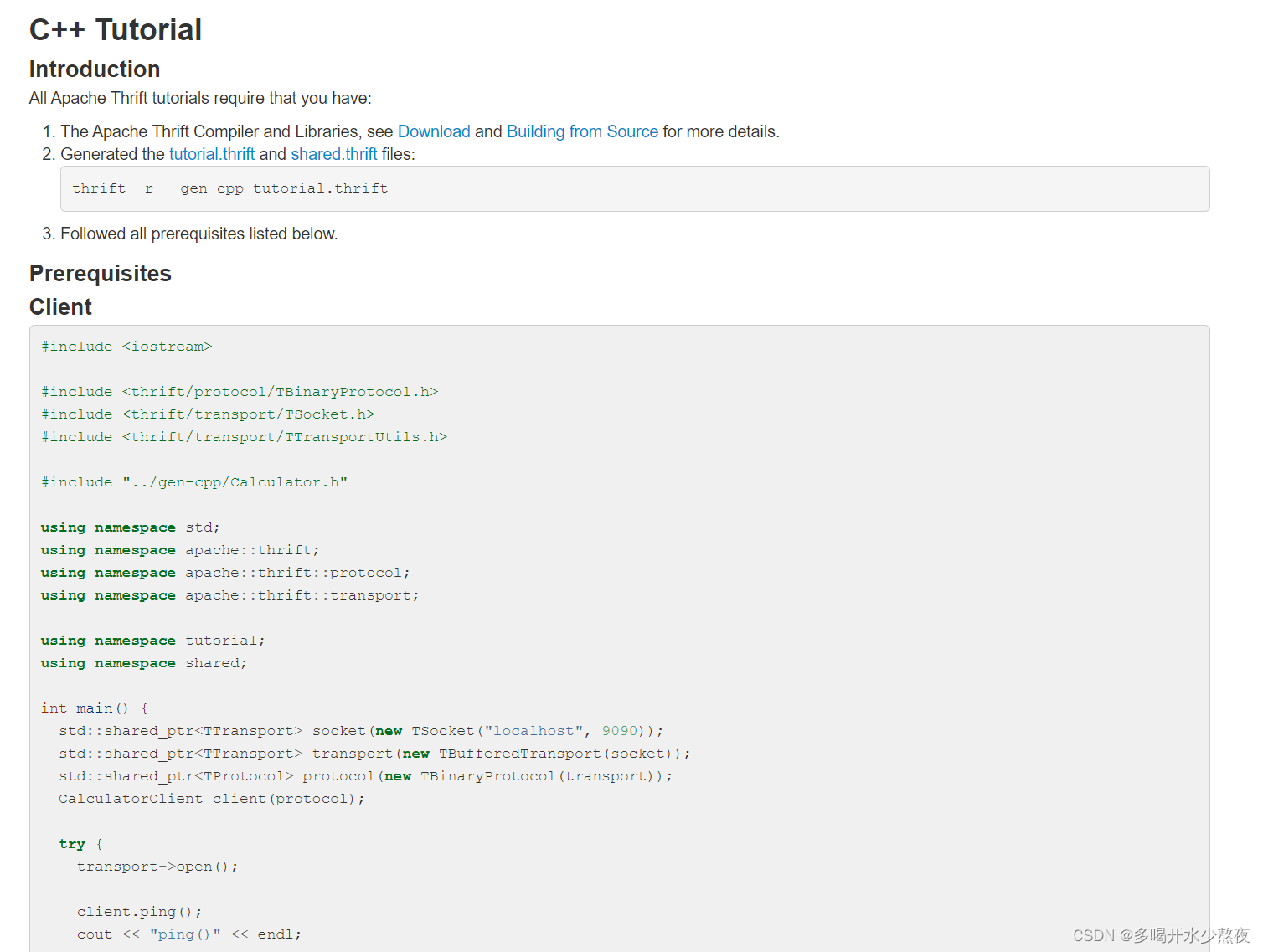
mv match_server/Match_server.skeleton.cpp main.cpp ,在main.cpp里修改Match.h头文件的路径:#include "match_server/Match.h"然后输入: g++ -c main.cpp match_server/*.cpp(表示用match_server里面的.cpp文件来编译main.cpp),然后用g++ *.o -o main -lthrift进行链接后就可以用./main进行起来了。每次修改c++文件后用g++ -c main.cpp重新编译,链接g++ *.o -o main -lthrift,然后执行./main就能运行了。(Ctrl+c停止运行)
记得删除skeleton.cpp函数再编译链接
每完成一个文件或者阶段记得git add .,commit,push,保存记录,一般来说.o可执行文件和编译后的文件不上传到云端,git add . 后记得用git restore --stage *.o,git restore --stage main把这些文件移出暂存区
良好习惯:每次进入相关文件夹记得mkdir src,在该目录下生成代码
客户端实现
进入到/game里面写python代码:
进入src/,输入thrift -r --gen py ../../thrift/match.thrift,重命名为match_client,在match_client/match/下有可执行文件 Match-remote,该文件是用来写Python服务器端的,本项目只需要在这里实现客户端,所以删掉这个文件。
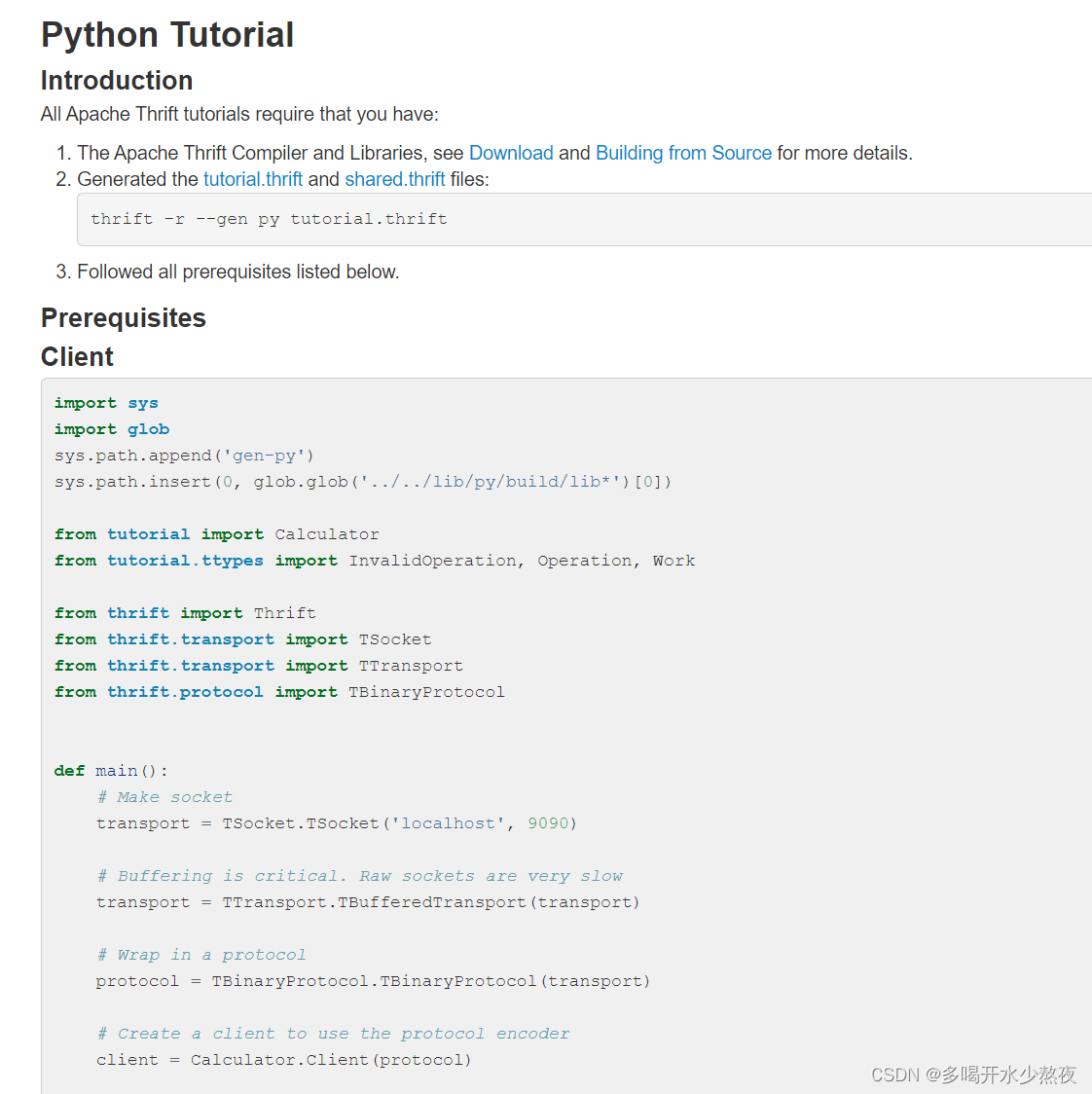
直接把上图的client端的例子的代码复制下来,进行修改,vim client.py,前四行代码删掉,引入正确路径from match_client.match import Match from match_client.match.ttypes import User
#client.py
from match_client.match import Match
from match_client.match.ttypes import User
from thrift import Thrift
from thrift.transport import TSocket
from thrift.transport import TTransport
from thrift.protocol import TBinaryProtocol
def main():
# Make socket
transport = TSocket.TSocket('127.0.0.1', 9090)
# Buffering is critical. Raw sockets are very slow
transport = TTransport.TBufferedTransport(transport)
# Wrap in a protocol
protocol = TBinaryProtocol.TBinaryProtocol(transport)
# Create a client to use the protocol encoder
client = Match.Client(protocol)
# Connect!
transport.open()
user = User(1,'zyt',1500)
client.add_user(user,"")
# Close!
transport.close()
if __name__ == "__main__":
main()
将服务器开启./main然后在客户端的src/下,运行.py文件,python3 client.py,可以看到服务器输出了一个add_user,成功用python调用了一个c++的进程的函数
在src/目录下保存一下git add . ,.pyc文件不要上传到云端,git restore --stage *.pyc,git restore --stage *.swp ,git commit -m "add match client",git push
修改client.py为从命令行读入用户信息的形式:
from match_client.match import Match
from match_client.match.ttypes import User
from thrift import Thrift
from thrift.transport import TSocket
from thrift.transport import TTransport
from thrift.protocol import TBinaryProtocol
from sys import stdin
def operate(op, user_id, username, score):
# Make socket
transport = TSocket.TSocket('127.0.0.1', 9090)
# Buffering is critical. Raw sockets are very slow
transport = TTransport.TBufferedTransport(transport)
# Wrap in a protocol
protocol = TBinaryProtocol.TBinaryProtocol(transport)
# Create a client to use the protocol encoder
client = Match.Client(protocol)
# Connect!
transport.open()
user = User(user_id, username, score)
if op == "add":
client.add_user(user,"")
elif op == "remove":
client.remove_user(user,"")
# Close!
transport.close()
def main():
for line in stdin:
op, user_id, username, score = line.split(' ')
operate(op, int(user_id), username, int(score))
if __name__ == "__main__":
main()
记得user_id和score为int类型
client端代码完成,如上所示,记得git add client.py 然后commit,push
server端实现
(修改main.cpp代码)
因为用户的添加和用户之间的匹配是并行的,所以给匹配单独开一个线程,
生产者-消费者模型:要想实现生产者和消费者之间的通信可以使用消息队列,需要用到mutex锁,PV操作,实现互斥共享操作,实现的数据结构如下所示:
struct Task
{
User user;
string type;
};
struct MessageQueue
{
queue<Task> q;
mutex m;
condition_variable cv;
}message_queue;
开一个线程thread matching_thread(consume_task)
消息队列每次加入用户以及操作前都要锁住,保证所有和队列相关操作同一时间只有一个线程在操作它unique_lock<mutex> lck(message_queue.m);,该做法能让当该变量被注销时不需要显示解锁,它会自动解锁。
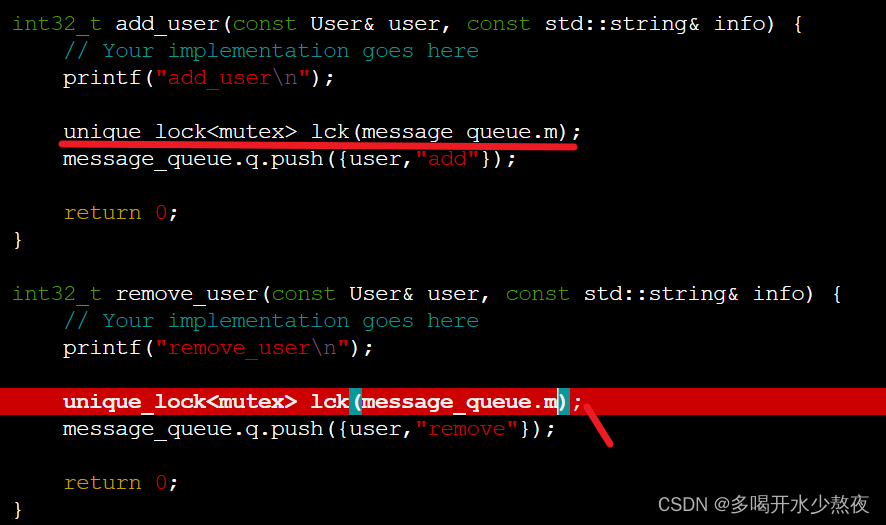
这里表示每次只能有一个线程拿到锁,另一个线程会停下来,直到前一个拿到锁的线程执行完它的函数,此时才能释放锁,执行该线程拿到锁。
如果一个线程中消息队列为空,那么应该阻塞住线程,否则会一直消费者死循环下去浪费CPU资源,直到有新的玩家加入线程。阻塞线程:message_queue.cv.wait(lck);,唤醒线程:message_queue.cv.notify_all();,通知所有被cv卡住的线程,随机执行其中一个,因为这里只有一个线程,所以也可以用message_queue.cv.notify_one();
将所有用户放到一个玩家池里面,相关数据结构如下:记得池里的for操作要break
class Pool
{
public:
void save_result(int a, int b)
{
//如果这里不加\n会导致在add 第三个用户的时候同时输出前两个的id和add user字符串,不知道原因,可能是不加\n会被阻塞?
printf("Match Result: %d %d\n", a, b);
}
void match()
{
while(users.size()>1){
auto a = users[0],b = users[1];
users.erase(users.begin());
users.erase(users.begin());
save_result(a.id, b.id);
}
}
void add(User user)
{
users.push_back(user);
}
void remove(User user)
{
for(uint32_t i = 0; i < users.size(); i++ ){
if(users[i].id == user.id){
users.erase(users.begin() + i);
}
}
}
private:
vector<User> users;
}pool;
每次执行任务的时候,根据类型选择匹配池的操作,并进行匹配操作pool.match()
void consume_task(){
while(true){
unique_lock<mutex> lck(message_queue.m);
if(message_queue.q.empty()){
message_queue.cv.wait(lck);
}-
else{
auto task = message_queue.q.front();
message_queue.q.pop();
lck.unlock();//remember to unlock
//do task
if(task.type == "add") pool.add(task.user);
else if(task.type == "remove")pool.remove(task.user);
pool.match();
}
}
}
完成所有代码后进行编译,链接,因为此时用到了线程,所以链接的时候的命令为:g++ *.o -o main -lthrift -pthread
记得git add main.cpp 然后commit ,git push
实现数据存储功能
记得要加头文件#include "save_client/Save.h"命名空间:save_service
求一个字符串md5值:在命令行写入md5sum 按回车键,输入字符串,按ctrl+d就能出来它的md5值。
namespace cpp save_service
service Save {
/**
* username: myserver的名称
* password: myserver的密码的md5sum的前8位
* 用户名密码验证成功会返回0,验证失败会返回1
* 验证成功后,结果会被保存到myserver:homework/lesson_6/result.txt中
*/
i32 save_data(1: string username, 2: string password, 3: i32 player1_id, 4: i32 player2_id)
}
在y总的git项目中把save.thrift的代码粘贴下来,写入thrift/目录,在match_system/src下使用thrift -r --gen cpp ../../thrift/save.thrift 生成相关实现接口的C++文件,重命名mv gen-cpp/ save_client,因为我们只需要实现客户端,所以删除服务器端生成的文件rm Save_server.skeleton.cpp
编写客户端的代码:在C++ Tutorial把代码对着main.cpp改,没有的头文件要加上,将save_client里面的头文件导入进去#include "save_client/Save.h" ,因为save.thrift里面使用了命名空间,因此也要加入main.cpp中using namespace ::save_service;,把样例文件中的main函数部分都复制下来,粘贴到save_result()函数中,进行修改:
void save_result(int a, int b)
{
printf("Match Result: %d %d\n", a, b);
std::shared_ptr<TTransport> socket(new TSocket("123.57.47.211", 9090));
std::shared_ptr<TTransport> transport(new TBufferedTransport(socket));
std::shared_ptr<TProtocol> protocol(new TBinaryProtocol(transport));
SaveClient client(protocol);
try {
transport->open();
client.save_data("myserver的用户名","md5密码前8位",a,b);
transport->close();
} catch (TException& tx) {
cout << "ERROR: " << tx.what() << endl;
}
}
进行编译链接:g++ -c save_client/*.cpp ,g++ -c main.cpp,g++ *.o -o main -lthrift -pthread
因为一直在服务器中看不到存储的result.txt文件,反复检查,发现是密码的md5前八位写错了,第一次生成的应该是因为多加了回车键,所以生成的md5是错误的,修改后就能看到保存的数据文件了。
记得git add 以下文件, git commit -m "implements save-client",git push

升级匹配系统
1.按分差来匹配,每一秒钟匹配一次
if(message_queue.q.empty()){
// message_queue.cv.wait(lck);
lck.unlock();
pool.match();
sleep(1);
}
void match()
{
while (users.size() > 1){
sort(users.begin(),users.end(),[&](User& a, User b){
return a.score < b.score;
});
bool flag = true;
for (uint32_t i=1; i < users.size(); i++){
auto a = users[i-1],b = users[i];
if(b.score-a.score<=50){
users.erase(users.begin()+i-1,users.begin()+i+1);
save_result(a.id,b.id);
flag = false;
break;
}
}
if(flag) break;
}
}
记得git add main.cpp ,git commit -m "match-server:3.0",git push
2.使用多线程服务器(2:02:16)
在该网页的Server代码样例中,粘贴需要的头文件和代码,并进行修改。
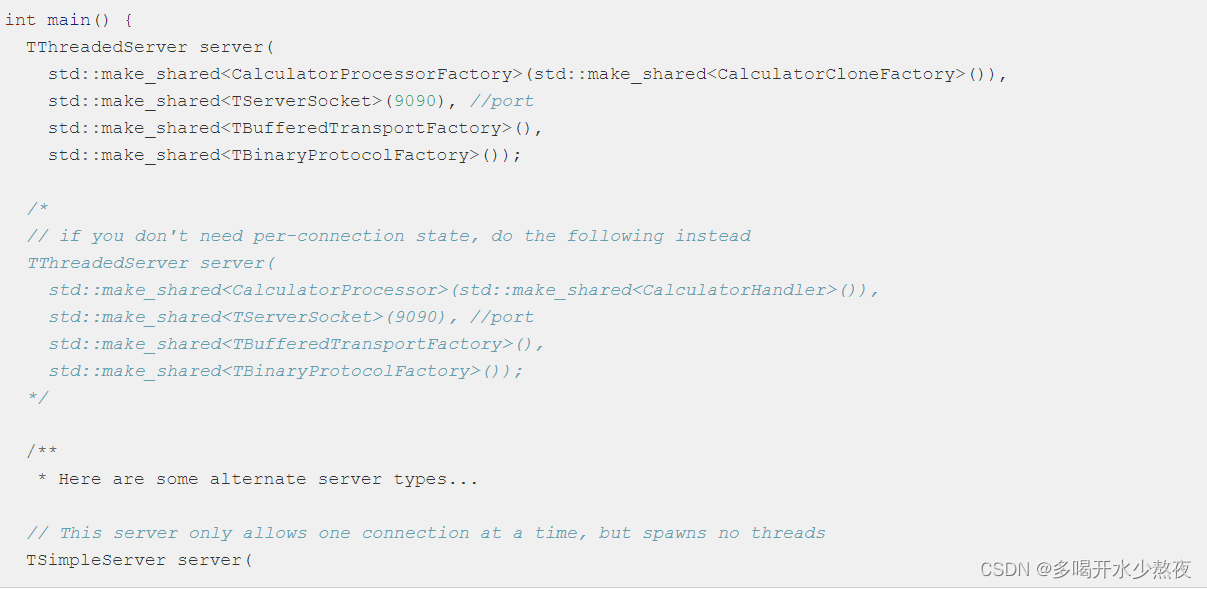
int main(int argc, char **argv) {
TThreadedServer server(
std::make_shared<MatchProcessorFactory>(std::make_shared<MatchCloneFactory>()),
std::make_shared<TServerSocket>(9090), //port
std::make_shared<TBufferedTransportFactory>(),
std::make_shared<TBinaryProtocolFactory>());---
cout << "Start Match Server" << endl;
thread matching_thread(consume_task);
server.serve();
return 0;
}
粘贴CloneFactory函数,:1,$s/Calculator/Match/g,替换所有Calculator的字,
class MatchCloneFactory : virtual public MatchIfFactory {
public:
~MatchCloneFactory() override = default;
MatchIf* getHandler(const ::apache::thrift::TConnectionInfo& connInfo) override
{
std::shared_ptr<TSocket> sock = std::dynamic_pointer_cast<TSocket>(connInfo.transport);
/*cout << "Incoming connection\n";
cout << "\tSocketInfo: " << sock->getSocketInfo() << "\n";
cout << "\tPeerHost: " << sock->getPeerHost() << "\n";
cout << "\tPeerAddress: " << sock->getPeerAddress() << "\n";
cout << "\tPeerPort: " << sock->getPeerPort() << "\n";*/
return new MatchHandler;
}
void releaseHandler(MatchIf* handler) override {
delete handler;
}
};
记得push上去 git add main.cpp,git commit -m "match-server:4.0,git push
3.每隔1s增加搜索分数的范围,比如以50倍每秒增加:
bool check_match(uint32_t i, uint32_t j)
{
auto a = users[i],b = users[j];
int dt = abs(a.score - b.score);
int a_max_dif = wt[i] * 50;
int b_max_dif = wt[j] * 50;
return dt<=a_max_dif && dt<=b_max_dif;
}
void match()
{
for(uint32_t i=0; i < wt.size(); i++) wt[i]++;
while (users.size() > 1){
bool flag = true;
for(uint32_t i=0; i < users.size(); i++){
for(uint32_t j=i+1; j < users.size(); j++){
if(check_match(i,j)){
auto a = users[i],b = users[j];
//先删除排序在后的,不然erase会乱掉
users.erase(users.begin() + j);
users.erase(users.begin() + i);
wt.erase(wt.begin() + j);
wt.erase(wt.begin() + i);
save_result(a.id, b.id);
flag = false;
break;
}
}
if(!flag) break;
}
if(flag) break;
}
}
void consume_task(){
while(true){
unique_lock<mutex> lck(message_queue.m);
if(message_queue.q.empty()){
// message_queue.cv.wait(lck);
lck.unlock();
pool.match();
sleep(1);
}-
else{
auto task = message_queue.q.front();
message_queue.q.pop();
lck.unlock();//remember to unlock
//do task
if(task.type == "add") pool.add(task.user);
else if(task.type == "remove")pool.remove(task.user);
}
}
}
记得提交git add main.cpp,git commit -m "match-server:5.0",git push
class Pool
{
public:
void save_result(int a,int b){
printf("Match Result: %d %d\n", a, b);
}
bool check_match(uint32_t i, uint32_t j){
auto a= users[i], b = users[j];
int dt = abs(a.score-b.score);
int a_max_dif = wt[i] * 50;
int b_max_dif = wt[j] * 50;
return dt <= a_max_dif && dt <= b_max_dif;
}
void match(){
for(uint32_t i=0; i < wt.size(); i++) wt[i]++;
while(users.size() > 1){
bool flag = true;
for(uint32_t i=0; i < users.size(); i++){
for(uint32_t j=i+1; j < users.size();j++){
if(check_match(i,j){
auto a = users[i],b = users[j];
users.erase(users.begin() + j);
users.erase(users.begin() + i);
wt.erase(wt.begin() + j);
wt.erase(wt.begin() + i);
save_result(a.id, b.id);
flag=false;
break;
}
}
if(!flag)break;
}
if(flag)break;
}
}
void add(User user){
users.push_back(user);
wt.push_back(0);
}
void remove(User user){
for(uint32_t i=0; i < users.size(); i++){
if(users[i].id == user.id){
users.erase(users.begin() + i);
wt.erase(wt.begin() + i);
}
}
}
private:
vector<User> users;
vector<int> wt;
}pool;
重做一遍的时候发现大部分的错误都是因为在编译的时候忘了先要用/match_server下和/save-client下的c++文件进行编译,其他逻辑上的问题还好,不过对生产者-消费者模型及其对应实现还有锁和多线程等都不太熟练,目前主要是靠背。
看一下为什么Calculator修改为Match/Save
首先判断当前函数是用来做什么功能的,client/server?对应的方法在哪个thrift生成的头文件下,官网中示例的Calculator改成相应的xxx.h中的xxx
例如#include "save_client/Save.h" 在save_result的时候对应的Calculator就要改成Save
#include "match_server/Match.h"其他大部分都是针对match_server的,相应改成Match
void releaseHandler(::shared::SharedServiceIf *handler) override {
delete handler;
}
改成:
void releaseHandler(MatchIf *handler) override {
delete handler;
}
在Match.cpp文件中查到

所以在释放handler这里类型应该为Match。
在Match.h头文件中也看到和Handler相关的操作都是MatchIf类型的
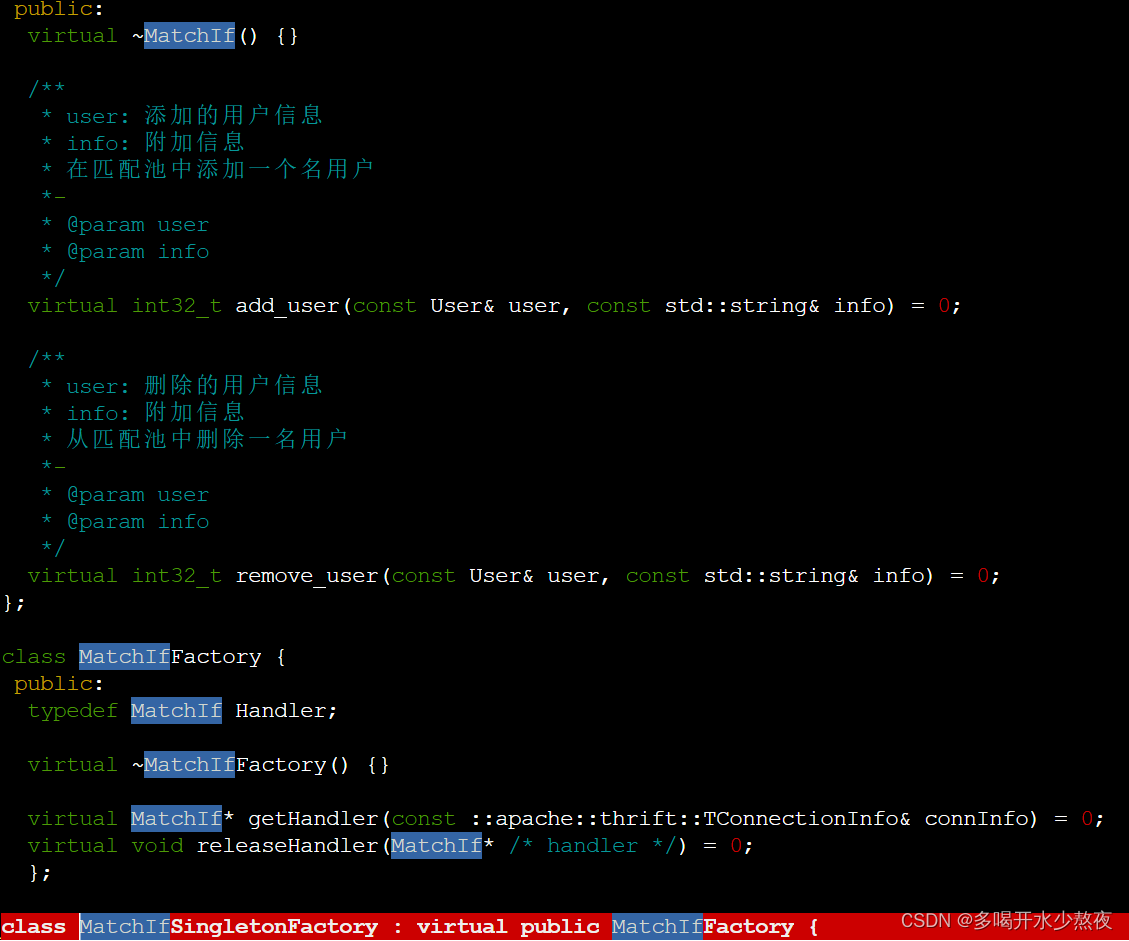
知识补充
c++ mutex锁
参考文档1
锁是由信号量来实现的,mutex->互斥量,信号量=1。
多个线程共享一个变量的时候会产生读写冲突,需要上锁。锁进一步引入了条件变量这一概念。
在编程中,引入了对象互斥锁的概念,来保证共享数据操作的完整性。每个对象都对应于一个可称为" 互斥锁" 的标记,这个标记用来保证在任一时刻,只能有一个线程访问该对象。
锁有两个操作。一个P操作(上锁),一个V操作(解锁)。 定义互斥锁:mutex m; 锁一般使用信号量来实现的,mutex其实就是一个信号量(它特殊也叫互斥量)。互斥量就是同一时间能够分给一个人,即S=1。 信号量S:S=10表示可以将信号量分给10个人来用。
unique_lock<mutex> lck(message_queue.m)定义互斥锁,并完成“加锁”过程
message_queue.cv.notify_all()通知条件变量,所有被条件变量睡眠的线程通知一下,锁已经释放掉了,可以继续执行了。
解锁:lck.unlock()对消息队列要进行某种操作前要解锁
阻塞:message_queue.cv.wait(lck)相当于V操作,将锁释放掉,同时卡死这句话,知道其他程序唤醒(notify)它为止

上图中没有lck.unlock()是因为lck有一个析构函数,在这个函数执行完的时候会自动解锁。
类的析构函数是类的一种特殊的成员函数,它会在每次删除所创建的对象时执行。
析构函数的名称与类的名称是完全相同的,只是在前面加了个波浪号(~)作为前缀,它不会返回任何值,也不能带有任何参数。析构函数有助于在跳出程序(比如关闭文件、释放内存等)前释放资源。
P操作的主要动作是: ①S减1; ②若S减1后仍大于或等于0,则进程继续执行;
③若S减1后小于0,则该进程被阻塞后放入等待该信号量的等待队列中,然后转进程调度。
V操作的主要动作是: ①S加1; ②若相加后结果大于0,则进程继续执行; ③若相加后结果小于或等于0,则从该信号的等待队列中释放一个等待进程,然后再返回原进程继续执行或转进程调度。
对于P和V都是原子操作,就是在执行P和V操作时,不会被插队。从而实现对共享变量操作的原子性。 特殊:S=1表示互斥量,表示同一时间,信号量只能分配给一个线程。
std::unique_lock:方便线程对互斥量上锁,但提供了更好的上锁和解锁控制。
c++ 条件变量
参考文档1
参考文档2
条件变量是利用线程间共享的全局变量进行同步的一种机制,主要包括两个动作:一个线程等待
条件变量的条件成立而挂起;另一个线程使条件成立(给出条件成立信号)。为了防止竞争,条件变量的使用总是和一个互斥量结合在一起。
条件变量是一个对象,能够在通知恢复之前阻止调用线程。它使用在调用其等待函数之一时锁定线程。线程将保持阻塞状态,直到被另一个调用同一对象上的通知函数的线程唤醒。
c++ 多线程
开启一个线程:thread 线程名(线程函数)
参考文档1
参考文档2
- 多线程并发
多线程并发指的是在同一个进程中执行多个线程。
优点:有操作系统相关知识的应该知道,线程是轻量级的进程,每个线程可以独立的运行不同的指令序列,但是线程不独立的拥有资源,依赖于创建它的进程而存在。也就是说,同一进程中的多个线程共享相同的地址空间,可以访问进程中的大部分数据,指针和引用可以在线程间进行传递。这样,同一进程内的多个线程能够很方便的进行数据共享以及通信,也就比进程更适用于并发操作。
缺点:由于缺少操作系统提供的保护机制,在多线程共享数据及通信时,就需要程序员做更多的工作以保证对共享数据段的操作是以预想的操作顺序进行的,并且要极力的避免死锁(deadlock)。
-
thrift教程
-
thrift官网
-
上课代码地址
-
可用的thrift tutorial地址
-
创建作业 & 测试作业的正确性
homework 6 create # 可以重新创建所有lesson_6的作业
homework 6 test # 可以评测lesson_6的所有作业
- 作业
本次作业为复现课上最后一个版本的内容,课程视频地址:https://www.acwing.com/video/3479/
注意:本次作业的2个题目采用整体评测,即如果两个作业同时正确,则得100分;否则如果至少有一个作业错误,则得0分。
创建好作业后,先进入文件夹/home/acs/homework/lesson_6/,当前目录的文件结构如下:
`-- thrift_lesson
|-- game
| `-- src
|-- match_system
| `-- src
|-- readme.md
`-- thrift
|-- match.thrift
`-- save.thrift
- (0) 进入
thrift_lesson/match_system/src/目录,用cpp实现课上的match-server和save-client逻辑。
接口文件在thrift_lesson/thrift/中。
实现后启动server,监听端口9090。 - (1) 进入
thrift_lesson/game/src/目录,用python3实现课上的match-client逻辑。
文件名和输入格式与课上内容相同。
7. 管道、环境变量与常用命令
管道
概念
管道类似于文件重定向,可以将前一个命令的stdout重定向到下一个命令的stdin。
要点
- 管道命令仅处理
stdout,会忽略stderr。 - 管道右边的命令必须能接受
stdin。 - 多个管道命令可以串联。
与文件重定向的区别
- 文件重定向左边为命令,右边为文件。
- 管道左右两边均为命令,左边有
stdout,右边有stdin。
命令 | 命令
举例
统计当前目录下所有python文件的总行数,其中find、xargs、wc等命令可以参考常用命令这一节内容。
find . -name '*.py' | xargs cat | wc -l
环境变量
概念
Linux系统中会用很多环境变量来记录配置信息。
环境变量类似于全局变量,可以被各个进程访问到。我们可以通过修改环境变量来方便地修改系统配置。
查看
列出当前环境下的所有环境变量:
env # 显示当前用户的变量
set # 显示当前shell的变量,包括当前用户的变量;
export # 显示当前导出成用户变量的shell变量
输出某个环境变量的值:
echo $PATH
修改
环境变量的定义、修改、删除操作可以参考3. shell语法——变量这一节的内容。
例如:
export HOME=/home/acs/homework #修改HOME环境变量地址
为了将对环境变量的修改应用到未来所有环境下,可以将修改命令放到~/.bashrc文件中(最后一行)。
修改完~/.bashrc文件后,记得执行source ~/.bashrc,来将修改应用到当前的bash环境下。
为何将修改命令放到~/.bashrc,就可以确保修改会影响未来所有的环境呢?
- 每次启动
bash,都会先执行~/.bashrc。 - 每次
ssh登陆远程服务器,都会启动一个bash命令行给我们。 - 每次
tmux新开一个pane,都会启动一个bash命令行给我们。 - 所以未来所有新开的环境都会加载我们修改的内容。
常见环境变量
-
HOME:用户的家目录。 -
PATH:可执行文件(命令)的存储路径。路径与路径之间用:分隔。当某个可执行文件同时出现在多个路径中时,会选择从左到右数第一个路径中的执行。下列所有存储路径的环境变量,均采用从左到右的优先顺序。
输入该路径下的可执行文件名,就可以在任意路径中启用该可执行文件,也就是变成了一个自定义的命令。
-
LD_LIBRARY_PATH:用于指定动态链接库(.so文件)的路径,其内容是以冒号分隔的路径列表。 -
C_INCLUDE_PATH:C语言的头文件路径,内容是以冒号分隔的路径列表。 -
CPLUS_INCLUDE_PATH:CPP的头文件路径,内容是以冒号分隔的路径列表。 -
PYTHONPATH:Python导入包的路径,内容是以冒号分隔的路径列表。 -
JAVA_HOME:jdk的安装目录。 -
CLASSPATH:存放Java导入类的路径,内容是以冒号分隔的路径列表。
常用命令
Linux命令非常多,本节讲解几个常用命令。其他命令依赖于大家根据实际操作环境,边用边查。
系统状况
-
top:查看所有进程的信息(Linux的任务管理器)- 打开后,输入M:按使用内存排序
- 打开后,输入P:按使用CPU排序
- 打开后,输入q:退出
-
df -h:查看硬盘使用情况 -
free -h:查看内存使用情况 -
du -sh:查看当前目录占用的硬盘空间 -
ps aux:查看所有进程可以用来查找某个进程:
ps aux | grep match-server(进程名)
-
kill -9 pid:杀死编号为pid的进程- 传递某个具体的信号:
kill -s SIGTERM pid - kill -9是立即关掉进程,kill -15是完成善后工作再关掉,有时延
- 传递某个具体的信号:
-
netstat -nt:查看所有网络连接 -
w:列出当前登陆的用户 -
ping www.baidu.com:检查是否连网
文件权限
文件权限有十位
第一位d文件夹 l链接文件 -代表没权限
剩下的每三位一组,表示可读可写可执行
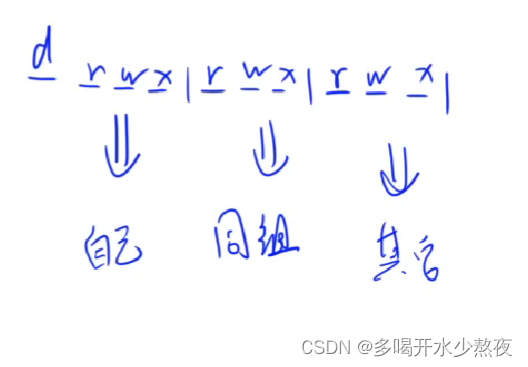
chmod:修改文件权限chmod +x xxx:给xxx添加可执行权限chmod -x xxx:去掉xxx的可执行权限chmod 777 xxx:将xxx的权限改成777- 上面数字是0-7内也就是三位二进制,从前往后表示自己,同组,其他的权限,0表示有1表示没有,777=111 111 111 表示所有权限都开启
chmod 777 xxx -R:递归修改整个文件夹的权限
文件检索
-
find /path/to/directory/ -name '*.py':搜索某个文件路径下的所有*.py文件
-
grep xxx:从stdin中读入若干行数据,如果某行中包含xxx,则输出该行;否则忽略该行。
查找该文件夹下的某内容

-
wc:统计行数、单词数、字节数
既可以从stdin中直接读入内容;也可以在命令行参数中传入文件名列表;
某个文件行数:

wc /文件夹/* 输出该文件夹下所有文件的行数、单词数、字节数
wc -l:统计行数wc -w:统计单词数wc -c:统计字节数
-
tree:展示当前目录的文件结构tree /path/to/directory/:展示某个目录的文件结构tree -a:展示隐藏文件
-
ag xxx:搜索当前目录下的所有文件,检索xxx字符串 -
cut:分割一行内容- 从
stdin中读入多行数据 echo $PATH | cut -d ':' -f 3,5:输出PATH用:分割后第3、5列数据echo $PATH | cut -d ':' -f 3-5:输出PATH用:分割后第3-5列数据echo $PATH | cut -c 3,5:输出PATH的第3、5个字符echo $PATH | cut -c 3-5:输出PATH的第3-5个字符
- 从
-
sort:将每行内容按字典序排序- 可以从
stdin中读取多行数据 - 可以从命令行参数中读取文件名列表
- 可以从
-
xargs:将stdin中的数据用空格或回车分割成命令行参数find . -name '*.py' | xargs cat | wc -l:统计当前目录下所有python文件的总行数
查看文件内容
-
more:浏览文件内容- 回车:下一行
- 空格:下一页
b:上一页q:退出
-
less:与more类似,功能更全- 回车:下一行
y:上一行Page Down:下一页Page Up:上一页q:退出
-
head -3 xxx:展示xxx文件的前3行内容- 同时支持从
stdin读入内容
- 同时支持从
-
tail -3 xxx:展示xxx末尾3行内容-
同时支持从
stdin读入内容
-
用户相关
history:展示当前用户的历史操作。内容存放在~/.bash_history中
工具
md5sum:计算md5哈希值- 可以从
stdin读入内容,ctrl+d退出 - 也可以在命令行参数中传入文件名列表;
- 可以从
time command:统计command命令的执行时间ipython3:交互式python3环境。可以当做计算器,或者批量管理文件。! echo "Hello World":!表示执行shell脚本
watch -n 0.1 command:每0.1秒执行一次command命令tar:压缩文件tar -zcvf xxx.tar.gz /path/to/file/*:压缩tar -zxvf xxx.tar.gz:解压缩
diff xxx yyy:查找文件xxx与yyy的不同点
安装软件
sudo command:以root身份执行command命令apt-get install xxx:安装软件pip install xxx --user --upgrade:安装python包
补充
tar 解压比较常用的写法,tar -zxvf xxx.tar.gz -C yyy:可以将 xxx.tar.gz 解压到指定目录 yyy 中,x - extract。
tail -n 5 文件 :查看文件尾部5行内容 (常用于日志)
tail -f 文件 :实时追踪该文档的所有更新 (常用于 flum 采集数据)
updatadb:更新locate命令所使用的数据库
locate xxx :按索引查询比find快,支持模糊查询
ps -aux :查看进程的CPU占用率和内存占用率
ps -ef:查看进程的父进程ID
netstat -nlp | grep 22:查看22端口号是否被占用
rpm -qa | grep rpm:查看自己安装的压缩包
sudo netstat -nltp:检测TCP/IP网络连接的监听端口(网络端口监听)
xargs将stdin的内容用空行隔开,作为cat的命令行参数,传给cat
cat a.txt b.txt
stdin变成文件参数
find . -name “*.py | cat:获取为.py结尾的文件名
find . -name “*.py | xargs cat:获取.py文件的内容
linux关于bashrc与profile的区别(转)
Linux命令查找
8. 租云服务器及配docker环境
概述

租到的服务器是毛坯,未来主要工作在docker上,方便迁移
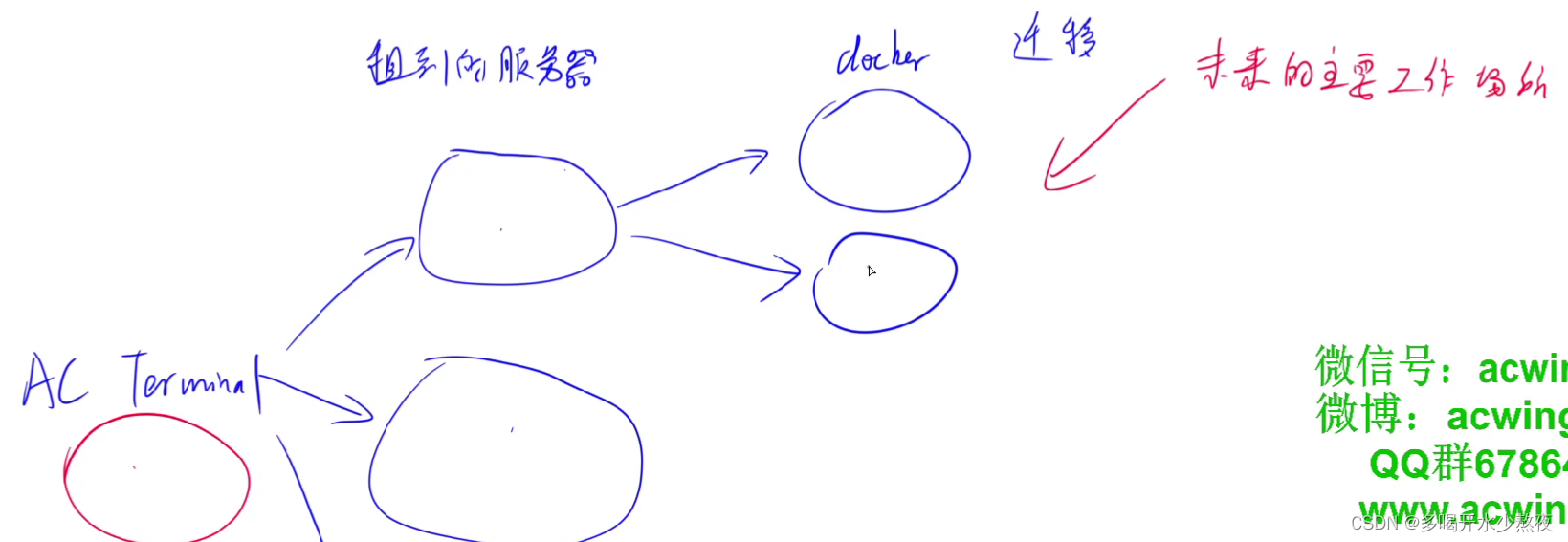
云平台的作用:
- 存放我们的docker容器,让计算跑在云端。
- 获得公网IP地址,让每个人可以访问到我们的服务。
任选一个云平台即可,推荐配置:
- 1核 2GB(后期可以动态扩容,前期配置低一些没关系)
- 网络带宽采用按量付费,最大带宽拉满即可(费用取决于用量,与最大带宽无关)
- 系统版本:ubuntu 20.04 LTS(推荐用统一版本,避免后期出现配置不兼容的问题)
docker安装教程地址:https://docs.docker.com/engine/install/ubuntu/
租云服务器及安装docker
阿里云
阿里云地址:https://www.aliyun.com/
创建工作用户acs并赋予sudo权限
登录到新服务器。打开AC Terminal,然后:
ssh root@xxx.xxx.xxx.xxx # xxx.xxx.xxx.xxx替换成新服务器的公网IP 密码
免费七个月云服务器
创建user1用户:(非根用户,分配sudo权限)
adduser user1 # 创建用户user1 密码
usermod -aG sudo user1 # 给用户user1分配sudo权限
配置免密登录方式
退回AC Terminal,然后配置user1用户的别名和免密登录,可以参考4. ssh——ssh登录。
配置新服务器的工作环境
将AC Terminal的配置传到新服务器上:
scp .bashrc .vimrc .tmux.conf server_name: # server_name需要换成自己配置的别名
安装tmux和docker
登录自己的服务器,然后安装tmux:
sudo apt-get update
sudo apt-get install tmux
打开tmux。(养成好习惯,所有工作都在tmux里进行,防止意外关闭终端后,工作进度丢失)
然后在tmux中根据docker安装教程安装docker即可。
腾讯云
腾讯云地址:https://cloud.tencent.com/
创建工作用户acs并赋予sudo权限
登录到新服务器。打开AC Terminal,然后:
ssh ubuntu@xxx.xxx.xxx.xxx # 注意腾讯云登录的用户不是root,而是ubuntu
创建acs用户:
adduser acs # 创建用户acs
usermod -aG sudo acs # 给用户acs分配sudo权限
配置免密登录方式
退回AC Terminal,然后配置acs用户的别名和免密登录,可以参考4. ssh——ssh登录。
配置新服务器的工作环境
将AC Terminal的配置传到新服务器上:
scp .bashrc .vimrc .tmux.conf server_name: # server_name需要换成自己配置的别名
安装tmux和docker
登录自己的服务器,然后安装tmux:
sudo apt-get update
sudo apt-get install tmux
打开tmux。(养成好习惯,所有工作都在tmux里进行,防止意外关闭终端后,工作进度丢失)
然后在tmux中根据docker安装教程安装docker即可。
华为云
华为云地址:https://www.huaweicloud.com/
创建工作用户user1并赋予sudo权限
登录到新服务器。打开AC Terminal,然后:
ssh root@xxx.xxx.xxx.xxx # xxx.xxx.xxx.xxx替换成新服务器的公网IP
创建acs用户:
adduser acs # 创建用户acs
usermod -aG sudo acs # 给用户acs分配sudo权限
配置免密登录方式
退回AC Terminal,然后配置acs用户的别名和免密登录,可以参考4. ssh——ssh登录。
配置新服务器的工作环境
将AC Terminal的配置传到新服务器上:
scp .bashrc .vimrc .tmux.conf server_name: # server_name需要换成自己配置的别名
安装tmux和docker
登录自己的服务器,然后安装tmux:
sudo apt-get update
sudo apt-get install tmux
打开tmux。(养成好习惯,所有工作都在tmux里进行,防止意外关闭终端后,工作进度丢失)
然后在tmux中根据docker安装教程安装docker即可。
docker教程
将当前用户添加到docker用户组
为了避免每次使用docker命令都需要加上sudo权限,可以将当前用户加入安装中自动创建的docker用户组(可以参考官方文档):添加完后及的执行newgrp docker 更新用户组
sudo usermod -aG docker $USER
执行完此操作后,需要退出服务器,再重新登录回来,才可以省去sudo权限。
镜像和容器就像是印章和图案
镜像(images)
docker pull ubuntu:20.04:拉取一个镜像docker images:列出本地所有镜像docker image rm ubuntu:20.04或docker rmi ubuntu:20.04:删除镜像ubuntu:20.04docker [container] commit CONTAINER IMAGE_NAME:TAG:创建某个container的镜像docker save -o ubuntu_20_04.tar ubuntu:20.04:将镜像ubuntu:20.04导出到本地文件ubuntu_20_04.tar中,chmod +r ubuntu_20_04.tar这个文件只有自己是可读的所以设置一下权限。docker load -i ubuntu_20_04.tar:将镜像ubuntu:20.04从本地文件ubuntu_20_04.tar中加载出来
在不同云服务器之间传镜像:先打包成tar文件,然后利用scp命令下载到本地,再把本地的tar镜像传到需要的云服务器上。
容器(container)
docker [container] create -it ubuntu:20.04:利用镜像ubuntu:20.04创建一个容器。docker ps -a:查看本地的所有容器,docker ps查看所有启动的容器docker [container] start CONTAINER:启动容器,CONTAINER可以是id或者namedocker [container] stop CONTAINER:停止容器docker [container] restart CONTAINER:重启容器docker [contaienr] run -itd ubuntu:20.04:创建并启动一个容器docker [container] attach CONTAINER:进入容器- 先按
Ctrl-p,再按Ctrl-q可以挂起容器 Ctrl-d退出容器 - 不建议
- 先按
docker [container] exec CONTAINER COMMAND:在容器中执行命令docker [container] rm CONTAINER:删除容器,删除停止的容器docker container prune:删除所有已停止的容器docker export -o xxx.tar CONTAINER:将容器CONTAINER导出到本地文件xxx.tar中docker import xxx.tar image_name:tag:将本地文件xxx.tar导入成镜像,并将镜像命名为image_name:tagdocker export/import与docker save/load的区别:export/import会丢弃历史记录和元数据信息,仅保存容器当时的快照状态save/load会保存完整记录,体积更大
docker top CONTAINER:查看某个容器内的所有进程docker stats:查看所有容器的统计信息,包括CPU、内存、存储、网络等信息docker cp xxx CONTAINER:xxx或docker cp CONTAINER:xxx xxx:在本地和容器间复制文件,docker cp文件夹不用加-rdocker rename CONTAINER1 CONTAINER2:重命名容器docker update CONTAINER --memory 500MB:修改容器限制
实战–实现在云服务器上搭建一个和AC Terminal一样环境的云服务器
进入AC Terminal,然后:
scp /var/lib/acwing/docker/images/docker_lesson_1_0.tar server_name: # 将镜像上传到自己租的云端服务器
ssh server_name # 登录自己的云端服务器
docker load -i docker_lesson_1_0.tar # 将镜像加载到本地
docker run -p 20000:22 --name my_docker_server -itd docker_lesson:1.0 # 创建并运行docker_lesson:1.0镜像 -p修改端口映射:将容器内22端口映射到本地20000端口,名称为my_docker_server
docker attach my_docker_server # 进入创建的docker容器
passwd # 设置root密码
云平台上修改root密码:在实例中重置实例密码,自己创建的服务中设置root密码输入:passwd
去云平台控制台中修改安全组配置,放行端口20000。
返回AC Terminal,即可通过ssh登录自己的docker容器:
ssh root@xxx.xxx.xxx.xxx -p 20000 # 将xxx.xxx.xxx.xxx替换成自己租的服务器的IP地址
然后,可以仿照上节课内容,创建工作账户user1。
最后,可以参考4. ssh——ssh登录配置docker容器的别名和免密登录。装tmux前先sudo apt-get update 再sudo apt-get install tmux
小Tips
如果apt-get下载软件速度较慢,可以参考清华大学开源软件镜像站中的内容,修改软件源。
将当前用户加入安装中自动创建的docker用户组后,仍然提示Got permission denied , 可以运行 newgrp docker #更新用户组
acs is not in the sudoers file. This incident will be reported.
输入acs的密码后出现上述内容,解决方案:重新登录root用户,创建另一个用户,重新设置免密登录以及以后的内容