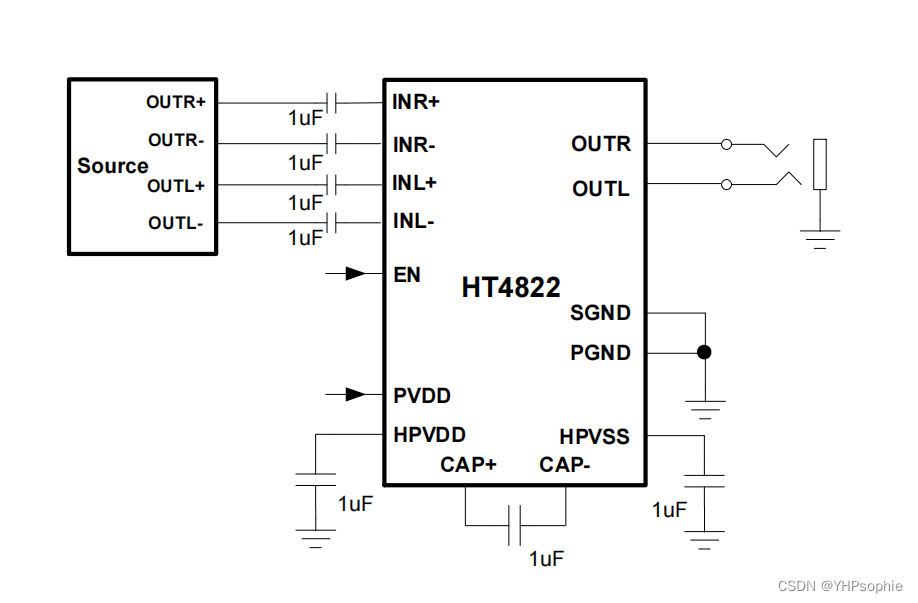
简介:NLTK(Natural Language Toolkit)是一个强大的Python库,用于处理和分析人类语言数据,是一个开源的项目,包含:Python模块,数据集和教程,用于NLP的研究和开发,由Steven Bird和Edward Loper在宾夕法尼亚大学计算机和信息科学系开发。NLTK包括图形演示和示例数据。其提供的教程解释了工具包支持的语言处理任务背后的基本概念。
历史攻略:
Python:使用pycorrector处理错字、纠正
Python:字符转语音
Python:2行代码实现文字转语音
语音识别:利用百度智能进行语音识别
安装:
pip install nltk
参数解析:
函数和模块 - NLTK包含多种函数和模块,例如 nltk.tokenize(用于分词),nltk.tag(用于词性标注)等。
常用参数:对于分词(word_tokenize)等函数,主要参数是要处理的文本字符串。对于词性标注等,参数可能包括分词后的词列表。
案例:
# -*- coding: utf-8 -*-
# time: 2023/11/22 10:18
# file: nltk_demo.py
# 公众号: 玩转测试开发
import nltk
import random
from nltk.util import ngrams
from nltk.tag import pos_tag
from collections import Counter
from nltk.probability import FreqDist
from nltk.corpus import movie_reviews
from nltk.tokenize import word_tokenize
from nltk.classify.util import accuracy
from nltk.classify import NaiveBayesClassifier
# demo - 01: 基本使用
text = "NLTK is a leading platform for building Python programs to work with human language data."
tokens = word_tokenize(text)
# 首次运行,如果环境没配置好,会报错,具体解决步骤参考,注意事项
print(tokens)
# demo - 02:文本分析
# a: 词频分布分析: 展示了如何使用NLTK来分析文本中词汇的频率分布。
nltk.download('punkt')
with open(r"D:\codes\tom2023\IHaveADream.txt")as f:
text = f.read()
tokens = word_tokenize(text)
fdist = FreqDist(tokens)
# b: 输出最常见的10个词
for word, frequency in fdist.most_common(10):
print(f"最常见的词 - {word}")
# c: 词性标注: 展示了如何使用NLTK进行词性标注。
nltk.download('averaged_perceptron_tagger')
text = "NLTK is a leading platform for building Python programs."
tokens = word_tokenize(text)
tags = pos_tag(tokens)
print(f"tags:{tags}")
# 简单的情感分类:展示了如何使用NLTK的分类工具进行简单的情感分析。
nltk.download('movie_reviews')
def extract_features(words):
return dict([(word, True) for word in words])
# 构建训练和测试数据
fileids_pos = movie_reviews.fileids('pos')
fileids_neg = movie_reviews.fileids('neg')
features_pos = [(extract_features(movie_reviews.words(fileids=[f])), 'Positive') for f in fileids_pos]
features_neg = [(extract_features(movie_reviews.words(fileids=[f])), 'Negative') for f in fileids_neg]
threshold = 0.8
num_pos = int(threshold * len(features_pos))
num_neg = int(threshold * len(features_neg))
features_train = features_pos[:num_pos] + features_neg[:num_neg]
features_test = features_pos[num_pos:] + features_neg[num_neg:]
# 训练分类器
classifier = NaiveBayesClassifier.train(features_train)
# 测试分类器
print("Accuracy: ", accuracy(classifier, features_test))
# 语言模型:展示了如何使用NLTK构建一个简单的n-gram语言模型。
nltk.download('reuters')
from nltk.corpus import reuters
text = reuters.raw(reuters.fileids()[0])
tokens = word_tokenize(text.lower())
bigrams = ngrams(tokens, 2)
bigram_freq = Counter(bigrams)
# 输出最常见的5个bigram
print(bigram_freq.most_common(5))
运行结果:
注意事项:
性能问题:对于大规模数据集,NLTK可能不是最高效的选择。
语言支持:NLTK主要支持英语,对于其他语言可能需要额外的处理。
版本兼容性:确保使用的Python版本与NLTK兼容。
首次运行报错,需要手动导入下载,操作如下图
手动执行Python,然后导入,下载相应包
python >> import nltk >> nltk.download(“punkt”)

总结:NLTK是Python中用于自然语言处理的重要库之一。它提供了丰富的工具和数据集,适用于文本处理、分析和建模等多种任务。虽然NLTK在处理大型数据集时可能不是最高效的,但它的易用性和强大功能使其成为学习和实践自然语言处理的优秀工具。




![vue-cli创建项目运行报错this[kHandle] = new _Hash(algorithm, xofLen);(完美解决)](https://img-blog.csdnimg.cn/direct/b7a09b703f9e4a8980dcdf63d063c436.png)