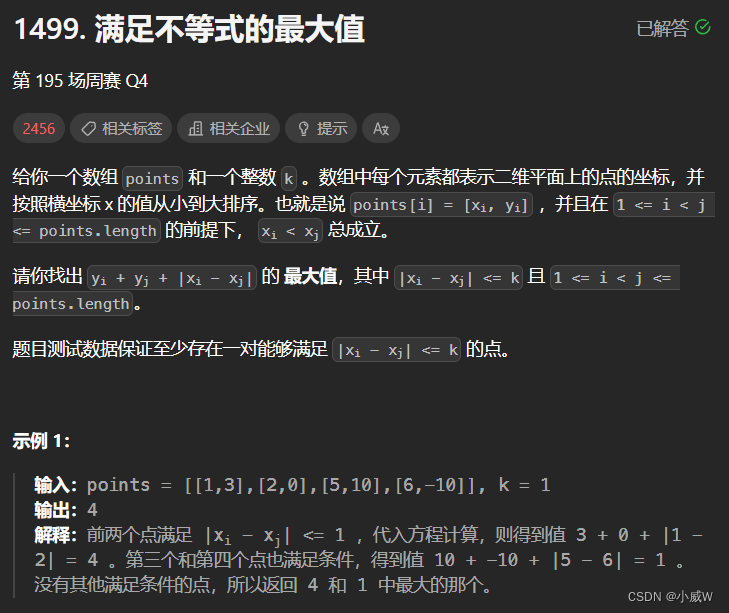
文章目录
- Flume 概述
- Flume 安装部署
- 官方网址
- 下载安装
- 配置文件
- 启动 Flume 进程
- 启动报错
- 输出文件乱码问题
Flume 概述
Flume(Apache Flume)是一个开源的分布式日志收集、聚合和传输系统,属于 Apache 软件基金会的项目之一。其主要目标是简化大规模数据处理中日志数据的采集、移动和处理过程。Flume 的设计灵感来自于 Google 的 Chubby 论文和 Facebook 的 Scribe 系统。
以下是 Flume 的主要概述:
- 架构模型: Flume 采用了分布式、可扩展的架构。它的基本架构包括多个组件,其中关键组件包括代理(Agent)、通道(Channel)和收集器(Collector)等。
- 代理(Agent): 代理是 Flume 中的基本工作单元,负责从数据源采集数据,并将数据传输到目的地。代理可以部署在数据源和目的地之间,负责数据的传输和整理。
- 通道(Channel): 通道是代理之间的缓冲区,用于存储传输的数据。通道允许代理之间异步、可靠地传输数据,确保即使在某个环节发生故障时,数据也不会丢失。
- 收集器(Collector): 收集器是 Flume 的目的地组件,负责接收代理传递的数据,并将数据存储到指定的存储系统中,如 Hadoop HDFS、HBase 等。
- 事件(Event): Flume 中的基本数据单元被称为事件,代表被传输的数据。事件由代理采集,并通过通道传递到收集器。
- 拓扑结构: Flume 支持多种拓扑结构,包括单一代理、多代理、多通道等,使其适用于不同规模和需求的数据处理场景。
- 可插拔性: Flume 具有良好的可插拔性,允许用户根据需要选择适当的组件,如数据源、通道、拦截器等,以定制数据采集和传输过程。
- 监控和管理: Flume 提供了监控和管理工具,使用户能够实时跟踪数据的流动和性能指标,以及对代理进行配置和管理。
总体而言,Flume 被设计用于解决大规模数据采集和传输的问题,使得数据工程师能够更轻松地搭建可靠的数据流水线,将数据从源头传递到目的地,以支持各种数据分析和处理需求。
Flume 安装部署
官方网址
- Flume 官网地址:Welcome to Apache Flume — Apache Flume
- 文档查看地址:Flume 1.9.0 User Guide — Apache Flume
- 下载地址:Index of /dist/flume (apache.org)
下载安装
将 apache-flume-1.9.0-bin.tar.gz 上传到 hadoop102 的 /root/software 目录下
tar -zxvf apache-flume-1.9.0-bin.tar.gz -C /opt/
将 apache-flume-1.9.0-bin 改名为 flume-1.9.0
cd /opt/
mv apache-flume-1.9.0-bin flume-1.9.0
配置文件
将 flume-1.9.0/conf 下的 flume-env.sh.template 文件修改为 flume-env.sh,并配置 flume-env.sh 文件
mv flume-env.sh.template flume-env.sh
vim flume-env.sh
在末尾添加:
export JAVA_HOME=/usr/java/default
在 flume-1.9.0/conf 中添加文件 file-flume-log.conf,该文件是一个 Flume 作业的核心文件
vim file-flume-log.conf
文件添加内容如下:
# 定义组件名称
a1.sources = r1
a1.sinks = k1
a1.channels = c1
############ source 部分 ############
a1.sources.r1.type = spooldir
# 配置读取文件的目录(本地目录)
a1.sources.r1.spoolDir = /opt/flume-1.9.0/logs
############ channel 部分 ############
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 1000
############ sink 部分 ############
a1.sinks.k1.type = hdfs
# 使用本地时间戳
a1.sinks.k1.hdfs.useLocalTimeStamp = true
# 配置输出到 HDFS 的路径,根据日期格式分开存储文件
a1.sinks.k1.hdfs.path = hdfs://hadoop102:9000/flume/%Y-%m-%d/%H%M
# 上传文件的前缀
a1.sinks.k1.hdfs.filePrefix = log
# 多少时间单位创建一个新的文件夹
a1.sinks.k1.hdfs.roundValue = 1
# 重新定义时间单位
a1.sinks.k1.hdfs.roundUnit = minute
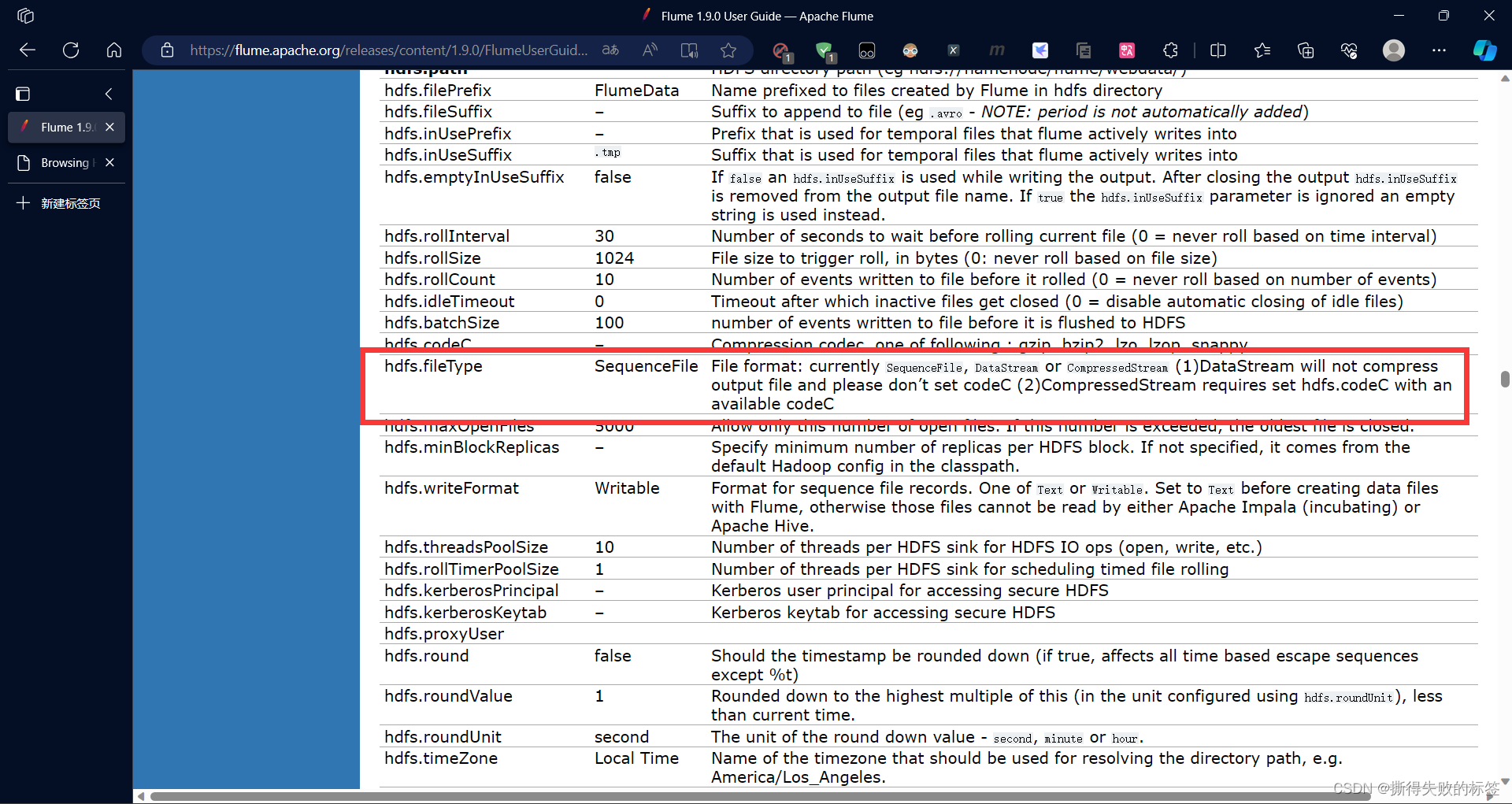
# 设置文件格式 DataStream 不会压缩输出文件,默认为 SequenceFile
a1.sinks.k1.hdfs.fileType = DataStream
# 把 source 和 sink 绑定到 channel 中
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
启动 Flume 进程
在 Flume 目录下输入命令:
bin/flume-ng agent -c /opt/flume-1.9.0/conf/ -n a1 -f /opt/flume-1.9.0/conf/file-flume-log.conf -Dflume.root.logger=info,console
令开一个窗口,随便传个文件到 /opt/flume-1.9.0/logs 目录下,蓝色说明 Flume 控制台在滚动打印
可以进入 HDFS Web 页面查看生成的文件

启动报错
如果出现下述报错内容
flume.sink.hdfs.HDFSEventSink.process(HDFSEventSink.java:459)] process failed
java.lang.NoSuchMethodError: com.google.common.base.Preconditions.checkArgument(ZLjava/lang/String;Ljava/lang/Object;)V
at org.apache.hadoop.conf.Configuration.set(Configuration.java:1357)
at org.apache.hadoop.conf.Configuration.set(Configuration.java:1338)
at org.apache.hadoop.conf.Configuration.setBoolean(Configuration.java:1679)
at org.apache.flume.sink.hdfs.BucketWriter.open(BucketWriter.java:221)
at org.apache.flume.sink.hdfs.BucketWriter.append(BucketWriter.java:572)
at org.apache.flume.sink.hdfs.HDFSEventSink.process(HDFSEventSink.java:412)
at org.apache.flume.sink.DefaultSinkProcessor.process(DefaultSinkProcessor.java:67)
at org.apache.flume.SinkRunner$PollingRunner.run(SinkRunner.java:145)
at java.lang.Thread.run(Thread.java:748)
原因是 Hadoop 3.3.1 中的 guava 包版本和 Flume 1.9.0 中的版本不一致
用 Hadoop 中高版本的 guava 包覆盖 Flume 中低版本的 guava 包
cp $HADOOP_HOME/share/hadoop/common/lib/guava-27.0-jre.jar /opt/flume-1.9.0/lib/guava-11.0.2.jar
输出文件乱码问题
在 sink 部分添加下述配置
# 设置文件格式 DataStream 不会压缩输出文件,默认为 SequenceFile
a1.sinks.k1.hdfs.fileType = DataStream
查看官方文档 Flume 1.9.0 User Guide — Apache Flume 在 hdfs-sink 部分的配置中写到文件类型默认为 SequenceFile,数据以二进制格式编码,并且将数据压缩了,数据下载下来是二进制格式,不能直接查看,无法可视化。如果想要直接查看输出文件,使用 DataStream,其不会压缩输出文件。