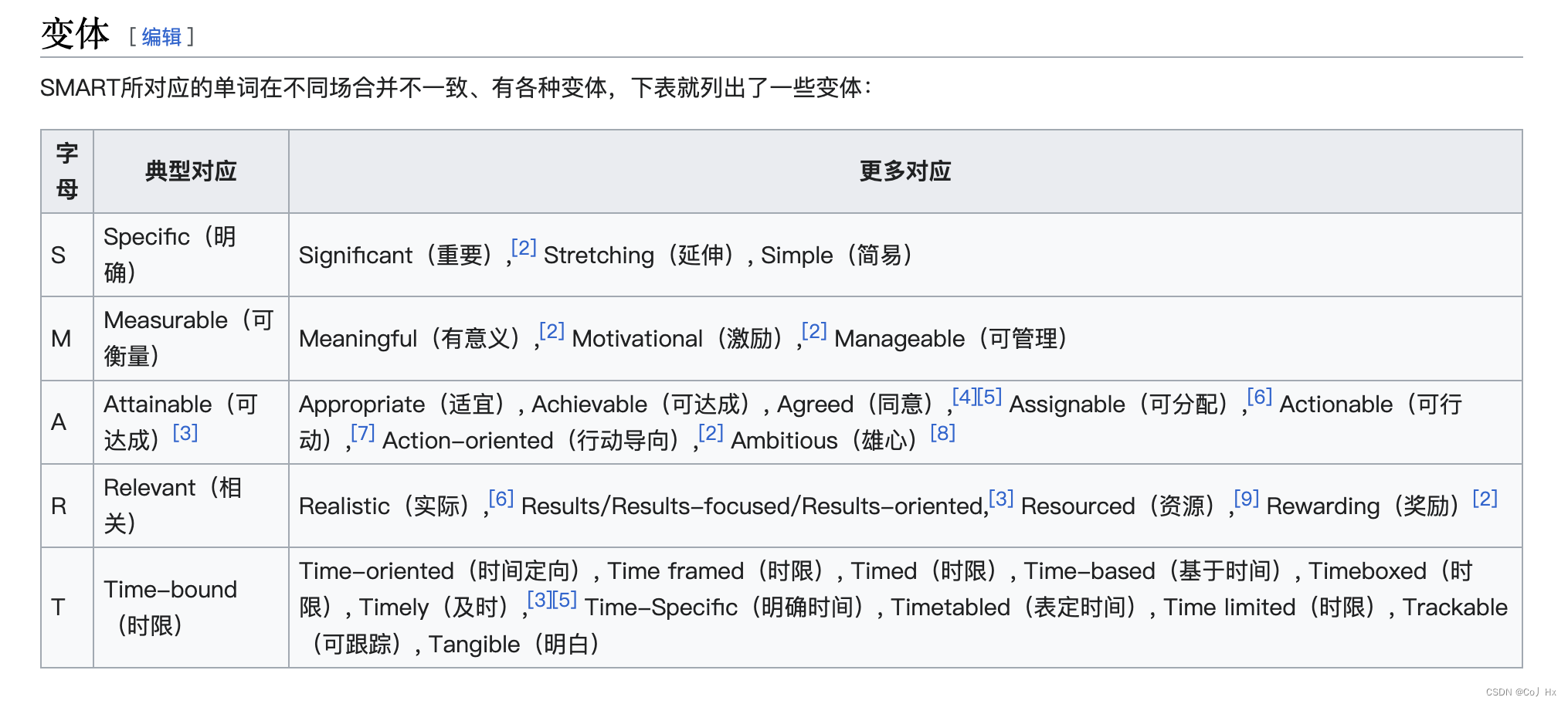
目录
一、简单介绍
二、安装与简单使用
三、常见用法
3.1 显示格式
3.2 写入文件
3.3 json日志
3.4 日志绕接
3.5 并发安全
四、高级用法
4.1 接管标准日志logging
4.2 输出日志到网络服务器
4.2.1 自定义日志服务器
4.2.2 第三方库日志服务器
4.3 与pytest结合
一、简单介绍
python中的日志库logging使用起来有点像log4j,但配置通常比较复杂,构建日志服务器时也不是方便。标准库logging的替代品是loguru,loguru使用起来就简单的多。
loguru默认的输出格式是:时间、级别、模块、行号以及日志内容。loguru不需要手动创建 logger,开箱即用,比logging使用方便得多;另外,日志输出内置了彩色功能,颜色和非颜色控制很方便,更加友好。
二、安装与简单使用
- 使用 pip 安装即可,Python 3 版本的安装如下:
pip3 install loguru- 简单使用
- 我们直接通过导入loguru 封装好的logger 类的实例化对象,不需要手动创建 logger,直接进行调用不同级别的日志输出方法。
from loguru import logger
logger.debug('This is debug information')
logger.info('This is info information')
logger.warning('This is warn information')
logger.error('This is error information')上述代码输出:
 日志打印到文件的用法也很简单,代码如下:
日志打印到文件的用法也很简单,代码如下:
from loguru import logger
logger.add('myloguru.log')
logger.debug('hello, this debug loguru')
logger.info('hello, this is info loguru')
logger.warning('hello, this is warning loguru')
logger.error('hello, this is error loguru')
logger.critical('hello, this is critical loguru')
上述代码运行时,可以打印到console,也可以打印到文件中去。
 三、常见用法
三、常见用法
3.1 显示格式
loguru默认格式是时间、级别、名称+模块和日志内容,其中名称+模块是写死的,是当前文件的__name__变量,此变量最好不要修改。
工程比较复杂的情况下,自定义模块名称,是非常有用的,容易定界定位,避免陷入细节中。我们可以通过logger.configure手工指定模块名称。如下:
import sys
from loguru import logger
logger.configure(handlers=[
{
"sink": sys.stderr,
"format": "{time:YYYY-MM-DD HH:mm:ss.SSS} |<lvl>{level:8}</>| {name} : {module}:{line:4} | <cyan>mymodule</> | - <lvl>{message}</>",
"colorize": True
},
])
logger.debug('this is debug')
logger.info('this is info')
logger.warning('this is warning')
logger.error('this is error')
logger.critical('this is critical')
handlers:表示日志输出句柄或者目的地,sys.stderr表示输出到命令行终端。
"sink": sys.stderr,表示输出到终端
"format":表示日志格式化。<lvl>{level:8}</>表示按照日志级别显示颜色。8表示输出宽度为8个字符。
"colorize": True**:表示显示颜色。
上述代码的输出为:
 这里写死了模块名称,每个日志都这样设置也是比较繁琐。下面会介绍指定不同模块名称的方法。
这里写死了模块名称,每个日志都这样设置也是比较繁琐。下面会介绍指定不同模块名称的方法。
3.2 写入文件
loguru默认格式是时间、级别、名称+模块和日志内容,其中名称+模块是写死的,是当前文件的__name__变量,此变量最好不要修改。
工程比较复杂的情况下,自定义模块名称,是非常有用的,容易定界定位,避免陷入细节中。我们可以通过logger.configure手工指定模块名称。如下:
import sys
from loguru import logger
logger.configure(handlers=[
{
"sink": sys.stderr,
"format": "{time:YYYY-MM-DD HH:mm:ss.SSS} |<lvl>{level:8}</>| {name} : {module}:{line:4} | <cyan>mymodule</> | - <lvl>{message}</>",
"colorize": True
},
{
"sink": 'first.log',
"format": "{time:YYYY-MM-DD HH:mm:ss.SSS} |{level:8}| {name} : {module}:{line:4} | mymodule | - {message}",
"colorize": False
},
])
logger.debug('this is debug')
logger.info('this is info')
logger.warning('this is warning')
logger.error('this is error')
logger.critical('this is critical')
与3.1.唯一不同的地方,
logger.configure新增了一个handler,写入到日志文件中去。用法很简单。
上述只是通过logger.configure设置日志格式,但是模块名不是可变的,实际项目开发中,不同模块写日志,需要指定不同的模块名称。因此,模块名称需要参数化,这样实用性更强。样例代码如下:
import sys
from loguru import logger
logger.configure(handlers=[
{
"sink": sys.stderr,
"format": "{time:YYYY-MM-DD HH:mm:ss.SSS} |<lvl>{level:8}</>| {name} : {module}:{line:4} | <cyan>{extra[module_name]}</> | - <lvl>{message}</>",
"colorize": True
},
{
"sink": 'first.log',
"format": "{time:YYYY-MM-DD HH:mm:ss.SSS} |{level:8}| {name} : {module}:{line:4} | {extra[module_name]} | - {message}",
"colorize": False
},
])
log = logger.bind(module_name='my-loguru')
log.debug("this is hello, module is my-loguru")
log2 = logger.bind(module_name='my-loguru2')
log2.info("this is hello, module is my-loguru2")
logger.bind(module_name='my-loguru')通过bind方法,实现module_name的参数化。bind返回一个日志对象,可以通过此对象进行日志输出,这样就可以实现不同模块的日志格式。
loguru中自定义模块名称的功能比标准日志库有点不同。通过bind方法,可以轻松实现标准日志logging的功能。而且,可以通过bind和logger.configure,轻松实现结构化日志。
上述代码的输出如下:

3.3 json日志
loguru保存成结构化json格式非常简单,只需要设置serialize=True参数即可。代码如下:
from loguru import logger
logger.add('json.log', serialize=True, encoding='utf-8')
logger.debug('this is debug message')
logger.info('this is info message')
logger.error('this is error message')
输出内容如下:

3.4 日志绕接
loguru日志文件支持三种设置:循环、保留、压缩。设置也比较简单。尤其是压缩格式,支持非常丰富,常见的压缩格式都支持,比如:"gz", "bz2", "xz", "lzma", "tar", "tar.gz", "tar.bz2", "tar.xz", "zip"。样例代码如下:
from loguru import logger
logger.add("file_1.log", rotation="500 MB") # 自动循环过大的文件
logger.add("file_2.log", rotation="12:00") # 每天中午创建新文件
logger.add("file_3.log", rotation="1 week") # 一旦文件太旧进行循环
logger.add("file_X.log", retention="10 days") # 定期清理
logger.add("file_Y.log", compression="zip") # 压缩节省空间
3.5 并发安全
loguru默认是线程安全的,但不是多进程安全的,如果使用了多进程安全,需要添加参数enqueue=True,样例代码如下:
logger.add("somefile.log", enqueue=True)
四、高级用法
4.1 接管标准日志logging
更换日志系统或者设计一套日志系统,比较难的是兼容现有的代码,尤其是第三方库,因为不能因为日志系统的切换,而要去修改这些库的代码,也没有必要。好在loguru可以方便的接管标准的日志系统。
样例代码如下:
import logging
import logging.handlers
import sys
from loguru import logger
handler = logging.handlers.SysLogHandler(address=('localhost', 514))
logger.add(handler)
class LoguruHandler(logging.Handler):
def emit(self, record):
try:
level = logger.level(record.levelname).name
except ValueError:
level = record.levelno
frame, depth = logging.currentframe(), 2
while frame.f_code.co_filename == logging.__file__:
frame = frame.f_back
depth += 1
logger.opt(depth=depth, exception=record.exc_info).log(level, record.getMessage())
logging.basicConfig(handlers=[LoguruHandler()], level=0, format='%(asctime)s %(filename)s %(levelname)s %(message)s',
datefmt='%Y-%M-%D %H:%M:%S')
logger.configure(handlers=[
{
"sink": sys.stderr,
"format": "{time:YYYY-MM-DD HH:mm:ss.SSS} |<lvl>{level:8}</>| {name} : {module}:{line:4} | [ModuleA] | - <lvl>{message}</>",
"colorize": True
},
])
log = logging.getLogger('root')
# 使用标注日志系统输出
log.info('hello wrold, that is from logging')
log.debug('debug hello world, that is from logging')
log.error('error hello world, that is from logging')
log.warning('warning hello world, that is from logging')
# 使用loguru系统输出
logger.info('hello world, that is from loguru')
输出为:
 4.2 输出日志到网络服务器
4.2 输出日志到网络服务器
如果有需要,不同进程的日志,可以输出到同一个日志服务器上,便于日志的统一管理。我们可以利用自定义或者第三方库进行日志服务器和客户端的设置。下面介绍两种日志服务器的用法。
4.2.1 自定义日志服务器
日志客户端段代码如下:
# client.py
import pickle
import socket
import struct
import time
from loguru import logger
class SocketHandler:
def __init__(self, host, port):
self.sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
self.sock.connect((host, port))
def write(self, message):
record = message.record
data = pickle.dumps(record)
slen = struct.pack(">L", len(data))
self.sock.send(slen + data)
logger.configure(handlers=[{"sink": SocketHandler('localhost', 9999)}])
while True:
time.sleep(1)
logger.info("Sending info message from the client")
logger.debug("Sending debug message from the client")
logger.error("Sending error message from the client")
日志服务器代码如下:
# server.py
import pickle
import socketserver
import struct
from loguru import logger
class LoggingStreamHandler(socketserver.StreamRequestHandler):
def handle(self):
while True:
chunk = self.connection.recv(4)
if len(chunk) < 4:
break
slen = struct.unpack('>L', chunk)[0]
chunk = self.connection.recv(slen)
while len(chunk) < slen:
chunk = chunk + self.connection.recv(slen - len(chunk))
record = pickle.loads(chunk)
level, message = record["level"].no, record["message"]
logger.patch(lambda record: record.update(record)).log(level, message)
server = socketserver.TCPServer(('localhost', 9999), LoggingStreamHandler)
server.serve_forever()
运行结果如下:
 4.2.2 第三方库日志服务器
4.2.2 第三方库日志服务器
日志客户端代码如下:
# client.py
import zmq
from zmq.log.handlers import PUBHandler
from loguru import logger
socket = zmq.Context().socket(zmq.PUB)
socket.connect("tcp://127.0.0.1:12345")
handler = PUBHandler(socket)logger.add(handler)
logger.info("Logging from client")
日志服务器代码如下:
# server.py
import sys
import zmq
from loguru import logger
socket = zmq.Context().socket(zmq.SUB)
socket.bind("tcp://127.0.0.1:12345")
socket.subscribe("")
logger.configure(handlers=[{"sink": sys.stderr, "format": "{message}"}])
while True:
_, message = socket.recv_multipart()
logger.info(message.decode("utf8").strip())
4.3 与pytest结合
官方帮助中有一个讲解loguru与pytest结合的例子,讲得有点含糊不是很清楚。简单的来说,pytest有个fixture,可以捕捉被测方法中的logging日志打印,从而验证打印是否触发。
下面就详细讲述如何使用loguru与pytest结合的代码,如下:
import pytest
from _pytest.logging import LogCaptureFixture
from loguru import logger
def some_func(i, j):
logger.info('Oh no!')
logger.info('haha')
return i + j
@pytest.fixture
def caplog(caplog: LogCaptureFixture):
handler_id = logger.add(caplog.handler, format="{message}")
yield caplog
logger.remove(handler_id)
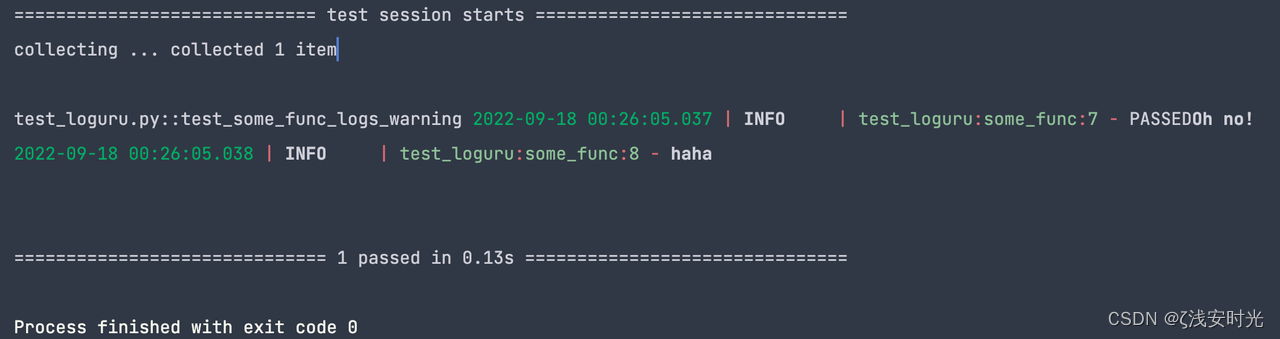
def test_some_func_logs_warning(caplog):
assert some_func(-1, 3) == 2
assert "Oh no!" in caplog.text
测试输出如下:


![[ Linux Audio 篇 ] 音频开发入门基础知识](https://img-blog.csdnimg.cn/direct/0a204f57c264419cad8326a3698ba572.png#pic_center)