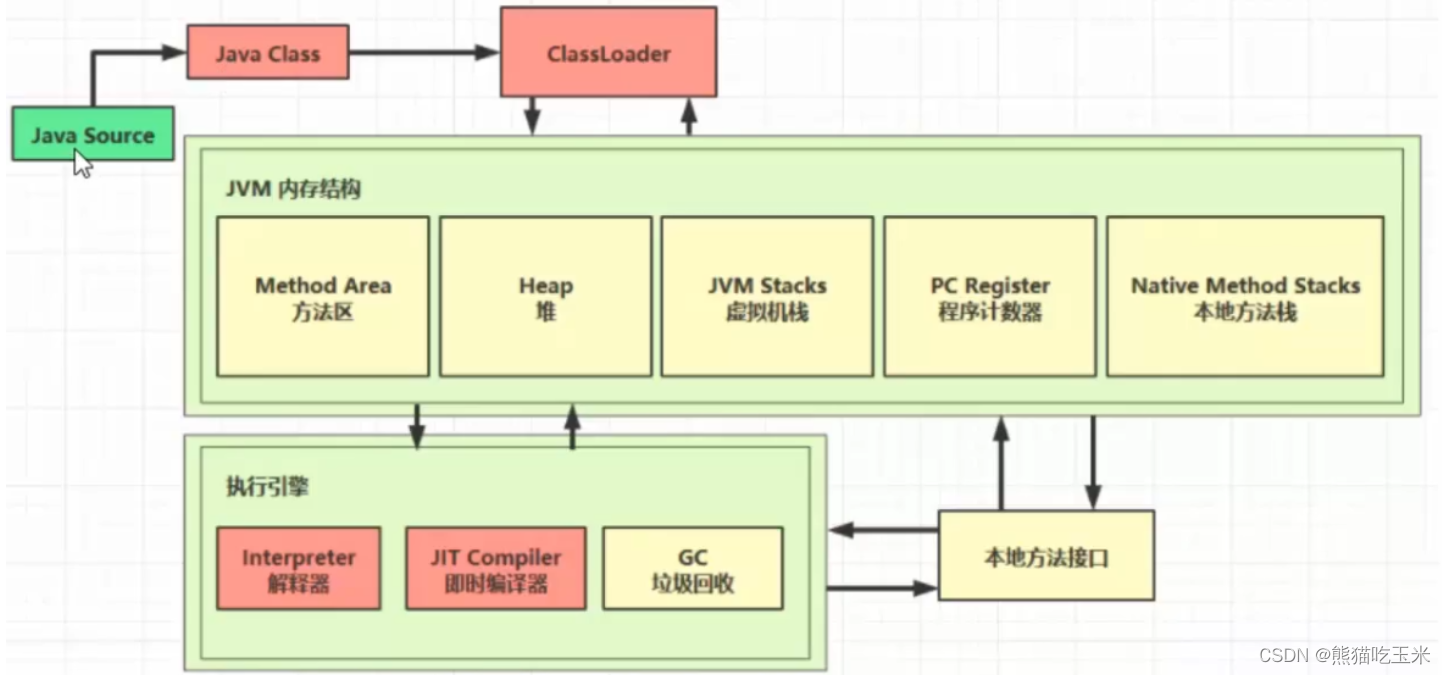
基于LSTM的CDN网络流量预测
本案例是基于英特尔CDN以及英特尔 OpenAPI Intel® Extension for TensorFlow* Intel@ oneAPIDPC++ Library 的网络流量预测,CDN是构建在现有网络基础之上的智能虚拟网络,目的是将源站内容分发至最接近用户的节点,使用户可就近取得所需内容,提高用户访问的响应速度和成功率。CDN智能调度中的流量分配算法、95调度算法与错峰调度等算法的有效性高度依赖域名流量的趋势,若能较为准确的预测域名流量的趋势,则可以提升调度算法的效果。与此类似的还有零售预测、供需预测等相关场景。
时间序列预测按数据及场景类别主要可分为单元时序预测(单变量)、多元时序预测、单步预测(预测)、多步预测几类。时间序列预测算法有基于统计的、基于机器学习的和基于深度学习的等等。
本文根据实际场景(单元多步时序预测),针对多线路预测问题,从数据分析到模型预测,采用LSTM,端到端实现CDN网络流量预测模型。
实验步骤
1.代码和数据集
本案例使用的数据集是来自于脱敏过的CDN网络流量预测项目数据集,因此数据及模型精度较真实效果有点偏差,打开压缩包后使用代码和数据集
2 查看数据
构建任何模型之前,都需要先对数据集进行分析,了解数据集的规模、属性名、属性值等情况。因为我们要先了解数据,才能用好数据
2.1 读取csv文件
pandas是常用的python数据分析模块,我们先用它来加载数据集中的csv文件。以time_series_1.csv为例,我们先加载该文件来分析数据的情况
import pandas as pd
df_data = pd.read_csv("./network_traffic_forecast/data/time_series_1.csv")
2.2 查看单个csv文件数据的规模
print('单个csv文件数据的规模,行数:%d, 列数:%d' % (df_data.shape[0], df_data.shape[1]))
单个csv文件数据的规模,行数:68601, 列数:4
2.3 查看前20行数据
使用pandas加载csv后,得到的是一个DataFrame对象,可以理解为一个表格,调用该对象的head()函数,我们查看一下该表格的头20行数据
df_data.head(20)
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
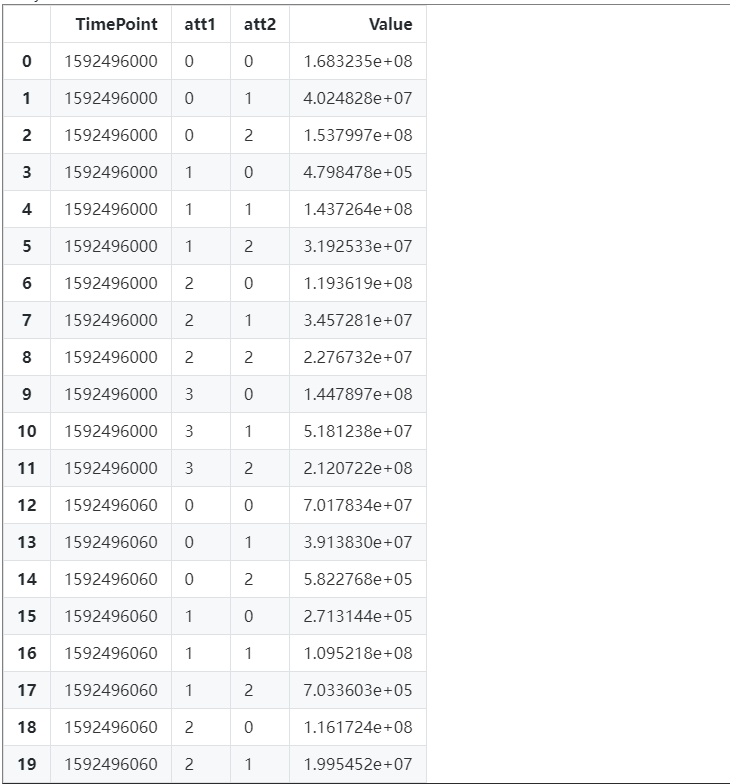
如上所示是表格的头20行数据,表头是属性名,属性名下面是属性值,各属性含义如下:
属性名 属性含义
2.3.1 查看单条线路数据情况
df_data[(df_data['att1'] == 0) & (df_data['att2'] ==0)]
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
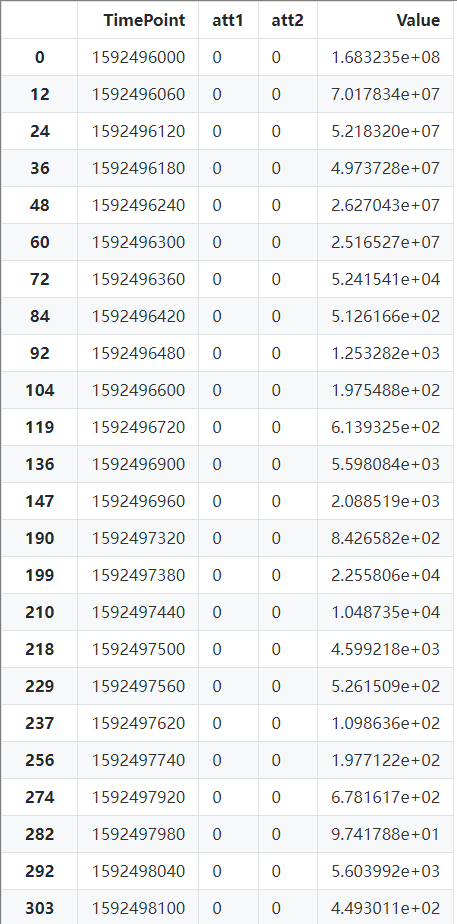
… … … … …
5717 rows × 4 columns
如上所示,以att1=0,att2=0 查看单条线路{区域,运营商}数据情况,可以看到数据是1min采样一次,共4天。
2.3.2 查看数据时序性情况
画出每条线路数据曲线图,根据曲线图判断数据时序性
import time
import matplotlib.pyplot as plt
from intel_tensorflow import IETensor
# 使用 Intel 的工具包 tensorflow
# 假设 df_data 包含 'att1', 'att2', 'TimePoint', 'Value' 列
# 如果列名不同,请修改下面的代码以匹配实际的列名
# 将时间戳转换为可读的时间格式
df_data["TimePoint"] = df_data["TimePoint"].apply(lambda x: time.strftime("%Y-%m-%d %H:%M:%S", time.localtime(x)))
# 将数据按 'att1' 和 'att2' 分组,并绘制曲线图
fig, ax = plt.subplots(figsize=(20, 10))
for name, group in df_data.groupby(["att1", "att2"]):
# 使用 Intel 工具包进行加速或优化操作,例如 IETensor 类
x = IETensor(group['TimePoint'].values)
y = IETensor(group['Value'].values)
ax.plot(x, y, label=name)
plt.title('每条线路数据曲线图 (使用 Intel 工具包)')
plt.xlabel('时间')
plt.ylabel('数值')
plt.legend()
plt.show()
df_data.groupby(["att1","att2"]).describe()
print(df_data['Value'].min())
print(df_data['Value'].max())
INFO:matplotlib.font_manager:font search path ['/home/ma-user/anaconda3/envs/Pytorch-1.0.0/lib/python3.6/site-packages/matplotlib/mpl-data/fonts/ttf', '/home/ma-user/anaconda3/envs/Pytorch-1.0.0/lib/python3.6/site-packages/matplotlib/mpl-data/fonts/afm', '/home/ma-user/anaconda3/envs/Pytorch-1.0.0/lib/python3.6/site-packages/matplotlib/mpl-data/fonts/pdfcorefonts']
INFO:matplotlib.font_manager:generated new fontManager
att1 att2
0 0 AxesSubplot(0.125,0.125;0.775x0.755)
1 AxesSubplot(0.125,0.125;0.775x0.755)
2 AxesSubplot(0.125,0.125;0.775x0.755)
1 0 AxesSubplot(0.125,0.125;0.775x0.755)
1 AxesSubplot(0.125,0.125;0.775x0.755)
2 AxesSubplot(0.125,0.125;0.775x0.755)
2 0 AxesSubplot(0.125,0.125;0.775x0.755)
1 AxesSubplot(0.125,0.125;0.775x0.755)
2 AxesSubplot(0.125,0.125;0.775x0.755)
3 0 AxesSubplot(0.125,0.125;0.775x0.755)
1 AxesSubplot(0.125,0.125;0.775x0.755)
2 AxesSubplot(0.125,0.125;0.775x0.755)
Name: Value, dtype: object
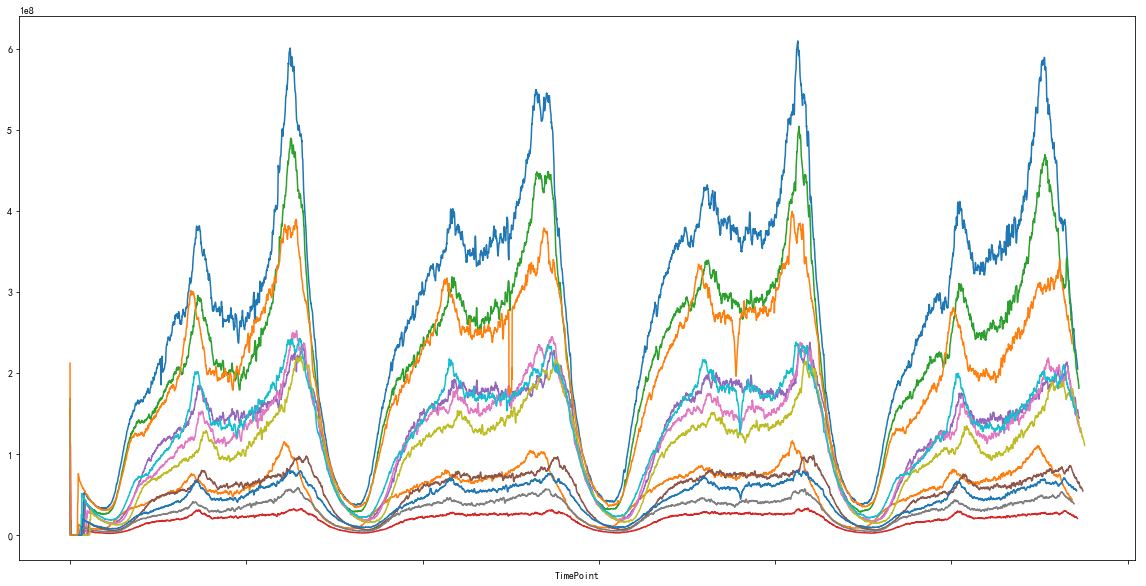
时间序列数据构成要素:长期趋势,季节变动,循环变动,不规则变动。
- 长期趋势(T)现象在较长时期内受某种根本性因素作用而形成的总的变动趋势。
- 季节变动(S)现象在一年内随着季节的变化而发生的有规律的周期性变动。
- 循环变动(C)现象以若干年为周期所呈现出的波浪起伏形态的有规律的变动。
- 不规则变动(I)是一种无规律可循的变动,包括严格的随机变动和不规则的突发性影响很大的变动两种类型。
分析:
如上图所示,是将数据按照(att1,att2)分组后,每条线路的曲线示意图,图上每条曲线则对应不同的线路,横轴为时间,纵轴为单条线路对应的Value值。根据图中曲线及以上时间序列数据特点,可得出以下结论:
- 数据存在周期性 每天一个周期,同一线路各周期间数据范围大致相同,不存在趋势性,季节性由于数据较少,暂看不出来,
- 共31个区域,每个{区域,运营商}]对应一条具体的线路,即共31*3条线路 每条线路大致趋势相同,但是量级不一样 需要进行归一化
数据峰值处波动较大,其余部分较平缓 - 整体数据质量较好,不需要进行数据平滑等使得数据变平稳的操作,后续建模预测未来10min,将主要依赖待预测点前一段时序数据进行预测。
- 数据中无明显脱离整体趋势范围的异常值。
2.4 数据分析
查看数据的统计值及空值情况
df_data.groupby(["att1","att2"]).describe()
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead tr th {
text-align: left;
}
.dataframe thead tr:last-of-type th {
text-align: right;
}
| att1 | att2 | count | mean | std | min | 25% | 50% | 75% | max |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 5717 | 2.756998e+08 | 1.471390e+08 | 85.107962 | 1.608420e+08 | 2.940786e+08 | 3.754438e+08 | 6.095700e+08 |
| 1 | 0 | 5686 | 5.480488e+07 | 2.756697e+07 | 51.327340 | 3.322805e+07 | 5.950805e+07 | 7.381292e+07 | 1.162919e+08 |
| 2 | 0 | 5724 | 2.188223e+08 | 1.181942e+08 | 65.711383 | 1.333125e+08 | 2.329354e+08 | 2.915056e+08 | 5.042825e+08 |
| 1 | 1 | 5715 | 1.861563e+07 | 9.069485e+06 | 38.332234 | 1.034681e+07 | 2.209178e+07 | 2.592819e+07 | 3.338421e+07 |
| 1 | 2 | 5725 | 1.258266e+08 | 6.321933e+07 | 4.381480 | 6.769589e+07 | 1.459575e+08 | 1.770747e+08 | 2.377960e+08 |
| 2 | 2 | 5746 | 5.218107e+07 | 2.650715e+07 | 4.772777 | 2.804430e+07 | 6.088992e+07 | 7.308530e+07 | 9.835380e+07 |
| 2 | 0 | 5732 | 1.179337e+08 | 6.204479e+07 | 36.191396 | 6.684485e+07 | 1.292305e+08 | 1.580988e+08 | 2.522959e+08 |
| 1 | 1 | 5696 | 3.024132e+07 | 1.488895e+07 | 49.353860 | 1.792033e+07 | 3.356871e+07 | 4.138216e+07 | 5.848370e+07 |
| 2 | 2 | 5756 | 1.024740e+08 | 5.487324e+07 | 146.927647 | 5.985492e+07 | 1.095121e+08 | 1.376453e+08 | 2.203716e+08 |
| 3 | 0 | 5708 | 1.271339e+08 | 6.343431e+07 | 109.510294 | 7.234194e+07 | 1.381774e+08 | 1.783945e+08 | 2.426037e+08 |
| 1 | 1 | 5711 | 4.340486e+07 | 2.045753e+07 | 6.857371 | 2.588623e+07 | 4.660798e+07 | 6.067043e+07 | 7.981218e+07 |
| 2 | 2 | 5685 | 1.991225e+08 | 9.818788e+07 | 1.169489 | 1.234276e+08 | 2.079243e+08 | 2.744293e+08 | 3.993022e+08 |
数据在时间列采样上存在缺失值,需要进行缺失值填充
对于count列,不同的att1与att2组合(不同线路)对应的count长度不同,正常情况下,数据有4天,应该是1440*4 = 5760个点,说明数据在时间列采样上存在缺失值,需要进行缺失值填充
查看Value列的最大最小值
由于以上分析中,value的max和min显示并不直观,因此这里再做具体分析
print(df_data['Value'].min())
print(df_data['Value'].max())
1.1694885305466325
609569980.8860668
可以看到最小值是1.1694885305466325,最大值为609569980.8860668,无小于等于0的异常值;