编者按:近年来,人工智能技术飞速发展,尤其是大型语言模型的问世,让 AI 写作、聊天等能力有了质的飞跃。如何更好地理解和利用这些生成式 AI,成为许多开发者和用户关心的问题。
今天,我们推出的这篇文章有助于读者深入了解大语言模型的工作原理。作者指出,大语言模型的核心在于将文本转化为数字表征,这就需要介绍 tokenizer 的概念。通过 tokenizer ,文本被分词并映射为 token id,这为模型理解文本提供了坚实的基础。作者还比较了基于统计学的文本自动补全和大语言模型的不同之处,说明了上下文窗口大小的重要性。最后,作者建议读者在使用 OpenAI 等平台时观察定价规则与 token 数量的关系,并思考为什么是这种定价规则。
本文通俗易懂地介绍了 tokenizer 在语言模型中的关键作用,让我们更好理解这类模型的工作方式,对使用生成式AI有很好的启发作用。人工智能技术的发展日新月异,理解其基础原理尤为重要。我们将持续关注该领域新进展,为读者呈现有价值的技术分析。
以下是译文,enjoy!
🚢🚢🚢欢迎小伙伴们加入AI技术软件及技术交流群,追踪前沿热点,共探技术难题~
作者 | SCORPIL
编译 | 岳扬

最近,生成式人工智能(Generative AI)领域的最新进展深刻改变了AI辅助应用(AI-assisted applications)中所采用的开发模式。就在五年前,将人工智能集成到应用程序中,除了需要基础技术外,很可能还需要一支计算机科学家团队来设计神经网络架构、训练和精心微调模型。总的来说,要做很多外行人难以理解的工作。但自从不到一年前 ChatGPT 发布以来,语言模型已经变得足够智能,以至于人们只需通过礼貌地询问,就能修改它们的行为(也不一定需要礼貌地询问)。
局限性。其中大部分都或多或少地依赖于应用 LLM 来控制 LLM 的想法(在本系列的后续部分中,我们将更深入地探讨这种情况)。这类工作感觉与传统的软件工程非常不同,有部分原因是它的 empirical nature (译者注:empirical nature应当意思为此类工作方式或方法是基于实际经验和实证数据的,而不是完全基于理论或假设。),部分原因是因为这个领域还十分年轻。
如今,使用人工智能并不一定要求对神经网络、机器学习和自然语言处理等领域有深入的了解,就像从事Web开发并不需要掌握编译器和汇编语言一样。不过,在这两种情况下,对于技术底层运作的了解对我们大有裨益,并且往往是优秀工程师与卓越工程师之间的区别。
目录
01 人工智能模型的本质是一种应用程序
02 文本自动补全系统设计
03 关于单词的定义和处理方式
01 人工智能模型的本质是一种应用程序
很多软件工程师第一次接触生成式人工智能时可能会感到困惑。多年的专业经验使他们对机器的能力有着一定的预期,并且可能会让他们怀疑其中是否存在一些虚假的表象。不管这种情况是好是坏,事实并非如此:每个人工智能模型只不过是一个应用程序(或者,如果你更愿意严格定义的话,是一个应用程序的核心部分)。模型的训练方式与大多数应用程序从零开始设计的方式不同,但它们仍然只是具有输入和输出的一种应用程序。
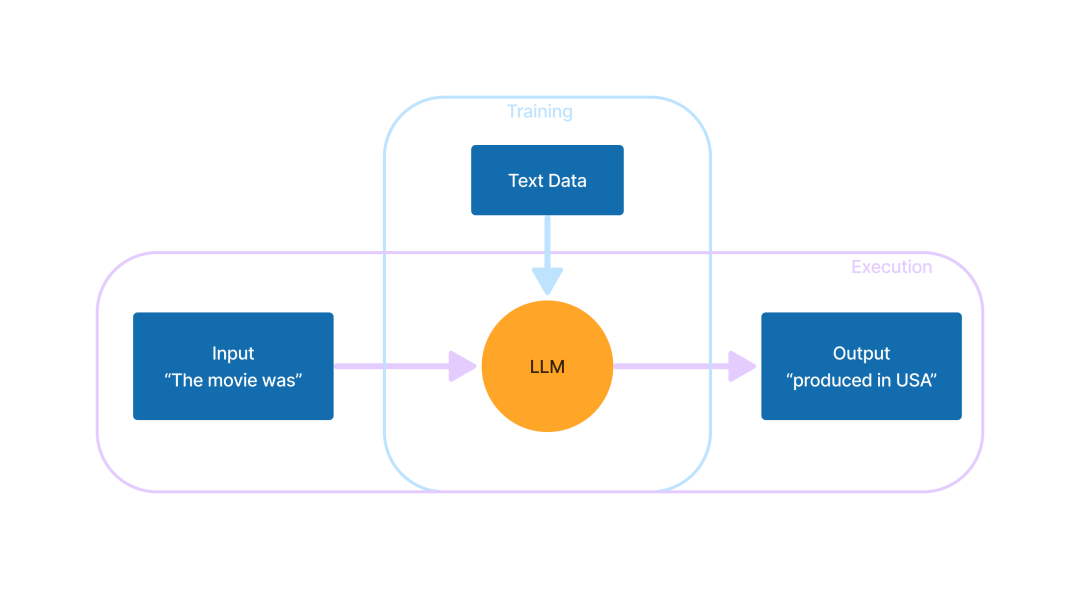
该应用程序的设计目标是,在输入一段文本后,以一种类似于人类编写的方式扩展输入的文本。这就是目前所有的 LLM 所做的。大模型是否能够“理解”输入的内容,这是一个备受争议的哲学话题。然而,大多数专家都同意,目前的 LLM 在创建文本时,并没有像人类那样真正理解输入文本。当然,没有人真正知道“像人类那样理解事物”是什么意思。谁知道呢,也许我们也只是一种非常先进的数据理解机器呢?
不过,我们还是不要被哲学问题所束缚。那么,我们要如何设计(哪怕只是在理论上)这种文本补全应用程序呢?
02 文本自动补全系统设计
文本自动补全系统(Autocomplete systems)已经存在几十年了,但直到手机流行起来后,才出现了对其最有用的应用。在手机上打字确实并不是很方便,因此能够猜测用户意图并给出输入建议这种能力就成了备受追捧的功能。
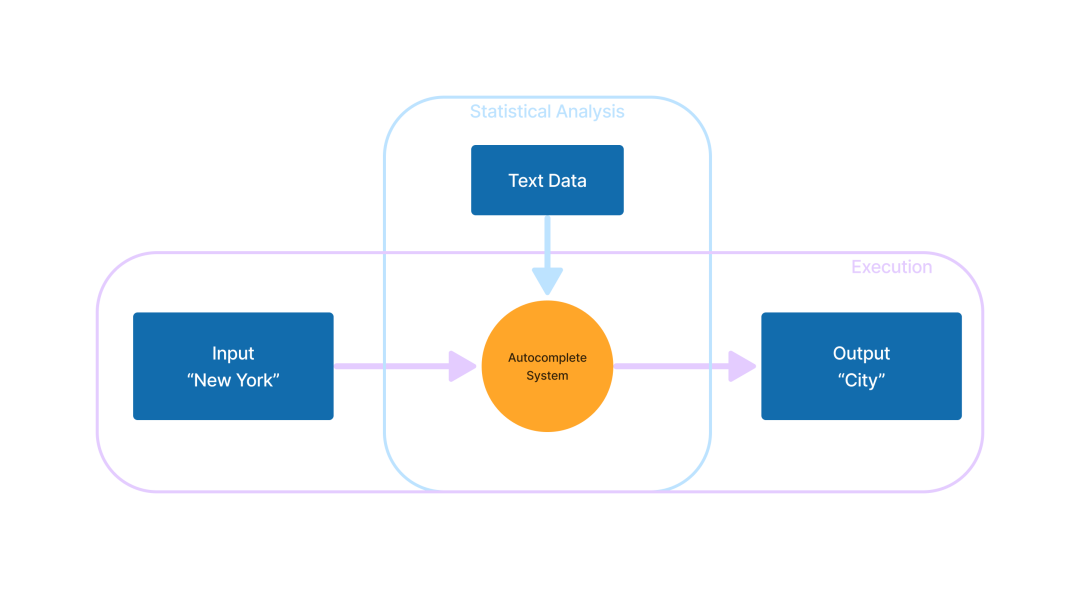
如果输入“New York”,文本自动补全系统很可能会预测下一个词是“City”。创建这种系统的一种相对直接的方法是使用简单的统计方法:在一个大型文本数据集中,记录下“New York”出现的所有文本样例(以及其他所有词对的样例),并记录在这些词对(如“New York”)后面出现的是什么单词,以此来学习文本的模式。
在设计这样的系统时,一个明显的需要权衡的因素是上下文的大小,即文本自动补全系统可以在输入中一起评估的单词数量:
- 接受更长的输入可能助于提升预测的准确度。
- 然而,输入量越大,统计数据存储所需的内存就会呈指数级增长。由于任何特定语言中可能出现的单词组合数量都是天文数字,因此即使使用最强大的硬件,收集和使用连续几个以上单词的精确频率数据也极其困难。
一个只有很小上下文窗口的文本自动补全系统,很快就会忘了他们刚刚在说什么。尽管有明显的局限性,但这样的系统与成熟的 LLM 相比还是有优势的:运行起来更轻便,而且可以说更适合文本信息辅助(text message assistance)。现代智能手机上的“预测文本”和“自动更正”功能更接近文本自动补全(autocomplete),而不是LLM(至少在撰写本文时是如此。它们可能很快就会被成熟的生成式人工智能所取代)。你可以亲自体验一下——在移动设备上进入本文的评论区,输入几个词(如果你想不出来,可以用“In future AI will(未来人工智能将会)”),然后不断选择设备给出的第一个输入建议。我以“The movie was(这部电影是)”开始,最后得到了下面这句话:
这部电影是一部好电影,但我认为它不足以成为一部好电影,因为它是一部好电影
The movie was a good one, but I don’t think it was good enough for the movie to be a good one because it was a good one
这个句子中的每一个词都是由前一个词自然衔接起来的。如果仅从这段文字中抓取一小段,单独读起来还可以:“这部电影是一部好电影”、“但我认为它不足以成为一部好电影”、“因为它是一部好电影”。然而,整段文本却是毫无意义的。 没有任何意义的线索将它们联系在一起。
为了便于比较,以下是由 GPT-3 根据 “The movie was” 补全的文本。
这部电影于2015年11月18日在美国上映。由布拉德·伯德执导,乔治·克鲁尼、休·劳瑞和布里特·罗伯逊主演。该片由迪士尼出品,票房大获成功,全球总票房超过 2.09 亿美元。
The movie was released in the United States on November 18, 2015. It was directed by Brad Bird, and stars George Clooney, Hugh Laurie, and Britt Robertson. It was produced by Disney and was a box office success, grossing over $209 million worldwide.
从这个简单的线索开始,GPT-3似乎就离题了,开始谈论了一部名为《明日世界(Tomorrowland)》的电影。令人印象深刻,但坦率地说,这可能不是我们希望从手机的文本自动补全功能中希望得到的结果。
这个例子表明,LLM可以根据更多的信息和语境来进行预测和生成文本,而不仅仅是依靠少数词语。 毕竟,要在第二句中正确说出“Disney”,必须考虑前面的整句文本。
但回到文本自动补全功能。为了让这种简单的统计方法发挥作用,我们必须首先获取统计数据。为此,我们可以编写一个程序,计算用户输入中提供的词组频率,并将统计数据存储在某个数据库中,以便以后在文本自动补全应用程序中使用。最终,输入的文本数据越多,文本自动补全程序的输出就应该变得更准确。
这种两阶段的方法反映了人工智能(以及机器学习一般)的工作方式。(译者注:此处的两阶段指的应当是首先需要收集并处理数据(训练模型),然后才能应用这些数据来进行预测或生成结果(运行模型))在这个类比中,这些统计数据是模型,计算这些数据是训练,文本自动补全是运行模型。开发者没有直接编写代码来定义应用程序的行为,而是创建了一个类似大型语言模型的中间过程,通过这个过程来指定应用程序的行为方式。
03 关于单词的定义和处理方式
我们理论上的文本自动补全程序(autocomplete program)隐含地将单词作为语言的原子部分进行操作。这是一个显而易见的选择,但并非最佳选择,原因有以下几点:
- 单词并非如其表面看起来那样被清晰地定义;“I’m”算一个词还是两个词?像“um”这样的插入语算不算一个词?像GPT这样的首字母缩略词算不算单词?这是一个单词吗:“🌸”?“bbbbbbbb”呢?
- “Apple”和“apples”是同一个单词的两种形式还是两个不同的单词?
- 如果只关注单词,我们就会忽略标点符号提供的有价值的线索。例如,“Cats like eating…”可能会有“fish”作为有效的补全内容,而“Cats like eating, …”(注意逗号)更可能会补全“sleeping, and playing”之类的内容。
为了解决这些挑战,LLM的输入被分割成“token”而不是单词。 在LLM中,token本质上是“在文本中的常见字符序列”,不受严格规则或语言语义的约束。相反,统计分析过程会根据输入文本确定什么是token,什么不是token。因此,这种方法允许对任何语言(不受其语法的限制)自动分词(automatic tokenization)。此外,token可以包括任何符号,而不仅仅是字母。分词器会将文本中的每个字符都分配给一个token,包括标点符号、数字、空白字符,甚至是表情符号。
需要注意的是,上述方法是对 LLM 的输入进行分词的最常见方式,但并非唯一的方式。“分词(tokenization)”这个术语可能在其他语境下指代自然语言处理中使用的其他更高级程序。
LLM 分词器需要保持一种微妙的平衡:
- 过于激进地将文本分割成 token 会使平均 token 长度变短,增加给定文本的上下文大小,并使 LLM 的运行成本更高。
- 另一方面,如果分词过程过于保守,token过长,可能会限制模型捕捉长程依赖关系(long-range dependencies)的能力,导致文本中细微信号的丢失,并可能导致计算复杂性增加。
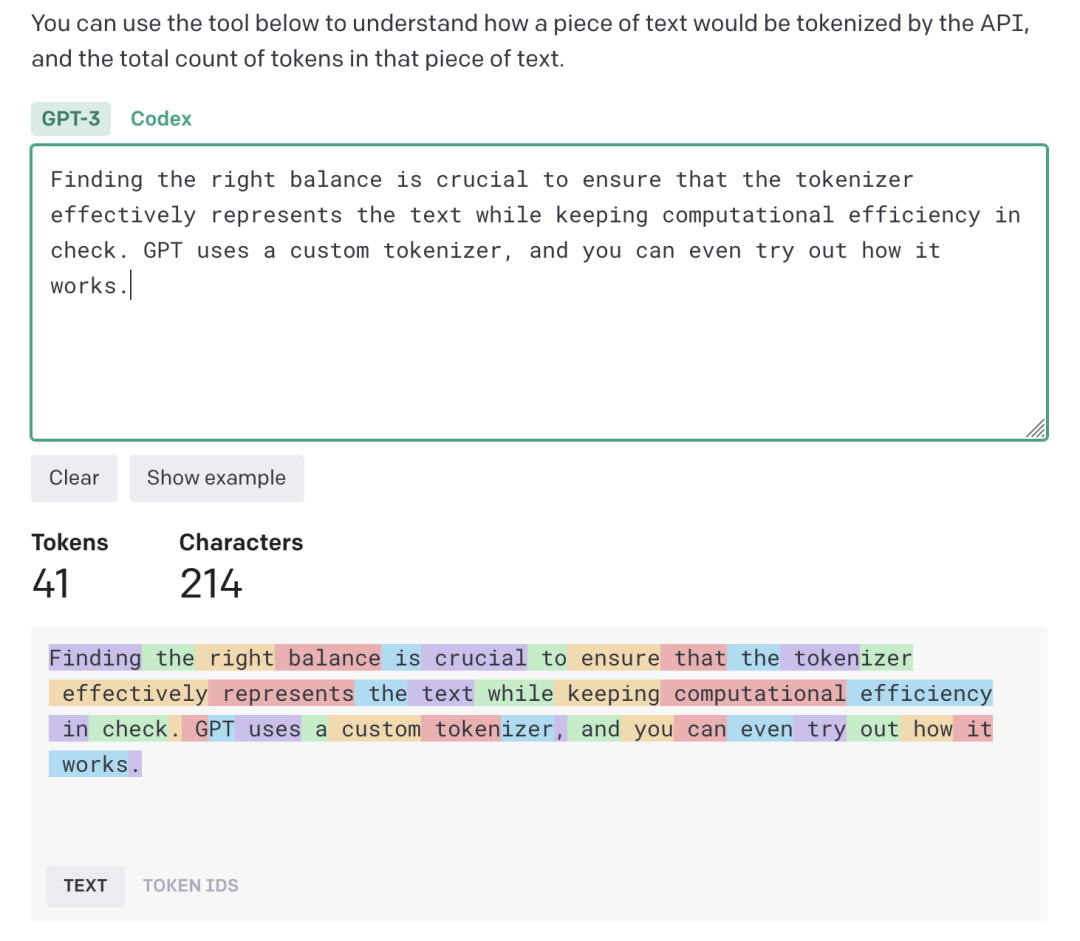
找到合适的一个平衡点对于确保分词器有效地表示文本,并保持计算效率至关重要。 GPT使用的是一种自定义分词器,你可以尝试理解它的工作方式[1]。请注意,该分词器将前导空格作为下一个单词token的一部分:”GPT“由两个token组成,与单词“tokenizer”相同。
由于分词器定义了一个庞大但也有限的 token 集合,因此可以对其进行枚举,并使用它们的索引作为数字类型的文本表征(digital text representation)。这种格式就是目前 LLM(大语言模型)所使用的。token 文本,即使是以二进制形式,长度也是可变的,这使得处理起来很困难,但token ID 只是数字。从 LLM 的角度来看,不存在所谓“文本字符(text character)”这样的东西。有趣的是,一些研究表明,人类感知文本的方式与此类似[2],更多地是根据单词块而不是单个符号。
至此,我相信您已经对创建 LLM 中训练步骤的重要性,上下文窗口大小的重要性,以及分词如何在将文本转换为与神经网络兼容的格式时发挥关键作用有了扎实的了解。是时候将我们新学习的知识应用到现实世界中了。我鼓励大家在浏览 OpenAI 的 LLM 定价页面[3]时牢记这些关键要点:
- 模型使用成本,包括与训练、输入和输出相关的费用 ,是按每 1000 个token 计算的 。 通过 LLM 的 token 数量直接影响了运行它所产生的成本。
- 上下文窗口大小对于 LLM 来说是一个关键参数。较大的窗口可以提高性能,但也会增加成本。
通过理解使用基于 token 的定价规则的目的,我们可以在实际场景中更明智地使用 LLM。
END
参考资料
[1]https://platform.openai.com/tokenizer
[2]https://library.ucsd.edu/dc/collection/bb95920960
[3]https://openai.com/pricing#language-models
本文经原作者授权,由Baihai IDP编译。如需转载译文,请联系获取授权。
原文链接:
https://scorpil.com/post/understanding-generative-ai-part-one-tokenizer/