目录
前言
一、从官网拿到源码,然后配置自己缺少的环境。
针对可能遇到的错误:
二、数据集获取与处理
2.1 数据集下载
2.2 数据集处理
三、下载预训练权重
四、修改部分参数配置
4.1 修改config.py
4.2 修改build.py
4.3 修改units.py
4.4 修改main.py
4.5 修改其他的地方
4.6 将最后结果以折线图的形式呈现出来
五、其他可修改的地方
六、运行代码
前言
关于Swin Transformer的讲解和实战,实际上网络上已经有很多了。不过有一些代码跑起来可能有一些问题(有一些确实有点问题,或者没头没尾的)。
最初的时候,我通过一些调研,参照网上的一些教程,跑的时候也遇到了一些问题,但是最后确实是成功了。下面我就详细地来讲述应该怎么做。
关于Swin Transformer的基础知识就不再赘述了。相信想到用Swin Transformer来实战的同学肯定已经多多少少对其有一定了解了。
在此,我说一下我的实战的思路:
从官网拿到代码,然后改改,换成自己的数据集,加载它的预训练权重,然后让代码跑起来。
如果你的coding能力确实比较强,那么你完全可以从官网上找到部分Swin Transformer的Model部分核心代码,然后数据处理部分、跑模型的部分都自己来写,这样做也完全OK。但是对能力要求较高,并且对模型的理解要求也比较高。比如,参考某B站Up主的视频,它的代码就是这样子的(在别人的文章里应该都能看的到,我就不重复了)。
而我们在这里就介绍傻瓜式的操作。
我的环境:
- Win 10
- Python 3.8
- Pytorch/torchvision 1.13.1+cu116
- NVIDIA GeForce RTX 3060(CUDA 11.7.102)
- Pycharm Community;
OK,开始。
一、从官网拿到源码,然后配置自己缺少的环境。
论文: https://arxiv.org/abs/2103.14030
代码: https://github.com/microsoft/Swin-Transformer
注意下,这里的fused window process、还有apex等不安装也是可以跑通的。它们的安装不影响代码的运行。如果你最后对性能有很高的要求,那你再去下载,我们这里主要是学习,然后让它先跑起来。
你要最起码确保在data文件夹下、models文件夹下和最外层的所有py文件都没有依赖报错(就是导入包的报错)

就是如上图那些的一些包,你给它都下载好不报错就行了。或者你新搞个虚拟环境,然后重新装一下就行,怎么搞虚拟环境可以参考这篇文章【正在更新中...】。
针对可能遇到的错误:
注意,这个错误只是可能遇到,不是一定会遇到。它和你下载的Pytorch的版本有关系。并且你的分类数如果大于5,应该是不会报错的。
那我们需要做什么呢?就是你可能需要改一下你的accuracy函数。
说一下这个函数的入口在哪找,因为这个函数并不是Swin-transformer的函数,它是Pytorch内置的文件函数,所以它原本是只读的(只是有写保护,并非不可更改)。那么我们从哪里找呢?
找到main.py->函数validate,有一行
acc1, acc5 = accuracy(output, target, topk=(1, 5))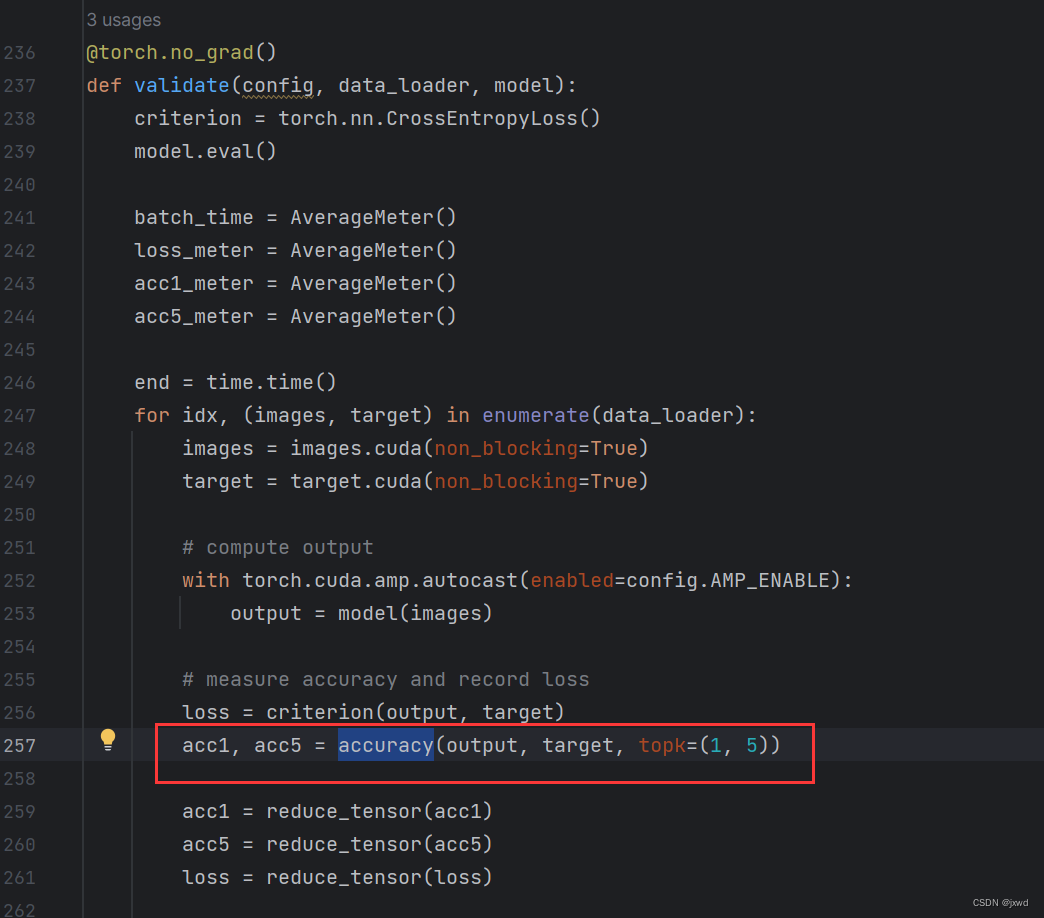
鼠标点击accuracy函数,然后按ctrl B就可以了(转到定义)
然后在metrics.py(这是个只读文件)里的这个函数accuracy,它应该是这个样子的(如下图):

但有些小伙伴该函数的第一行是这个样子的:
maxk = max(topk)然后就导致如果你训练过程中,如果分类数比较少(比如二分类),那它就会报类似于“索引k超出范围”这样的错误。你把它这一行给改成上面截图的那个样子就行:
maxk = min(max(topk), output.size()[1]) //应该是这个样子的,否则二分类会报错OK了家人们,现在我们环境配置就这样说完了。拿到项目和配置环境相信都是最基本的,没有什么好说的了哈。
二、数据集获取与处理
注意,我们是要用预训练权重去跑我们自己是数据集,所以不要傻乎乎的去下载ImgNet 1K,更不要傻乎乎地去下载ImgNet 22K哈哈哈,这些都是官方在一开始训练swin transformer的时候所用到的数据集,如果我们用预训练权重来去训练自己的训练集的话,是不需要下载这些东西的了。
我们这里,就以猫狗数据集为例来为大家说下数据集怎么整。
我们就以Kaggle猫狗大战数据集为例。
2.1 数据集下载
传送门:Dogs vs. Cats Redux: Kernels Edition | Kaggle
具体怎么下载,可以参考这篇文章:【正在更新中】
或者也可以用百度网盘分享的链接下载:【正在更新中】
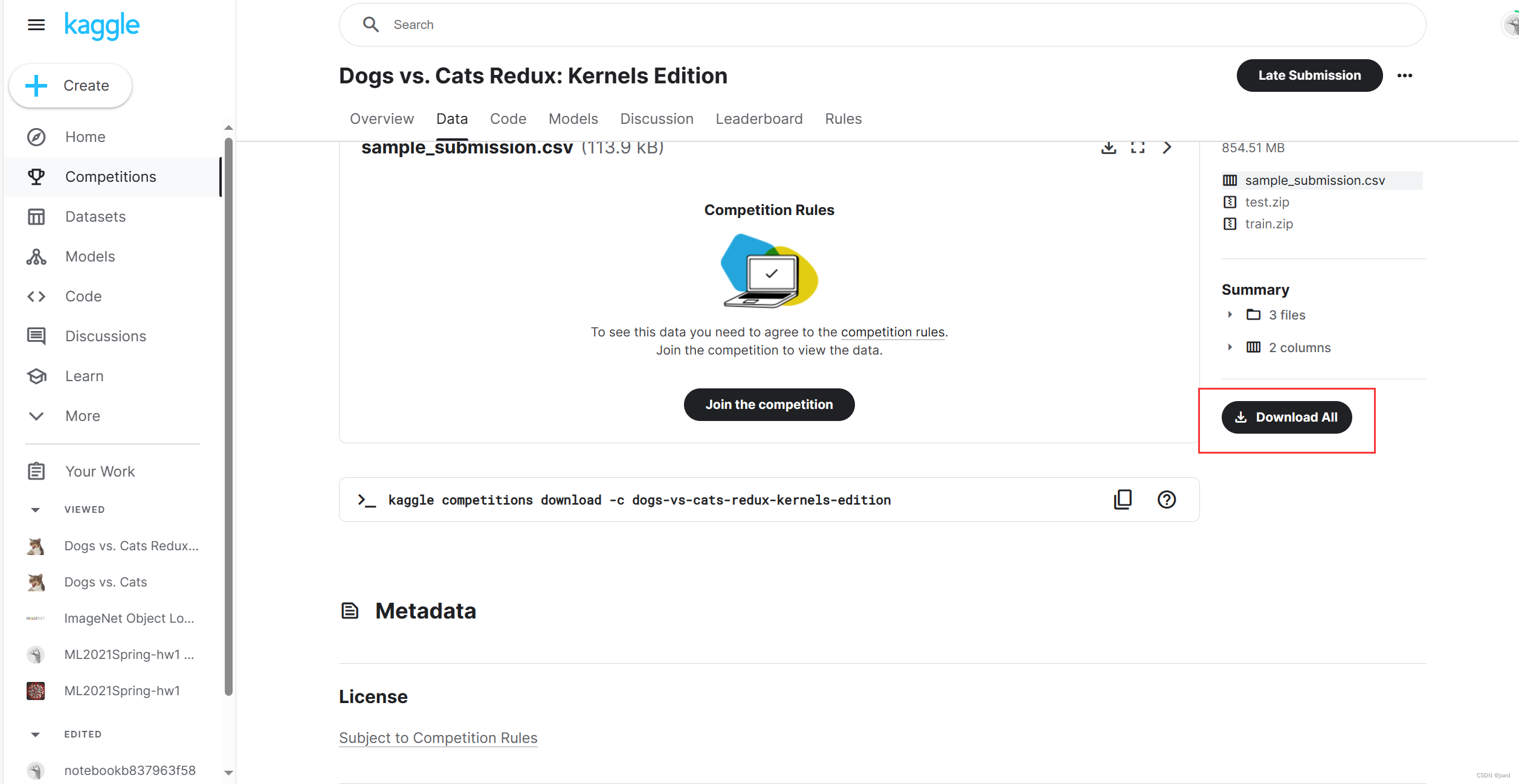
简单来说,就是你需要先登录,同意它比赛的Rules,然后点击那个Download就可以下载了。数据集不是很大,所以直接从浏览器上下载感觉问题也不大。
2.2 数据集处理
OK,那么数据集下载完毕之后,我们要对数据集进行处理分类。
那个csv表格没有用的,它是给你提交的样例。我们需要拿的是test数据集合train数据集,解压缩。
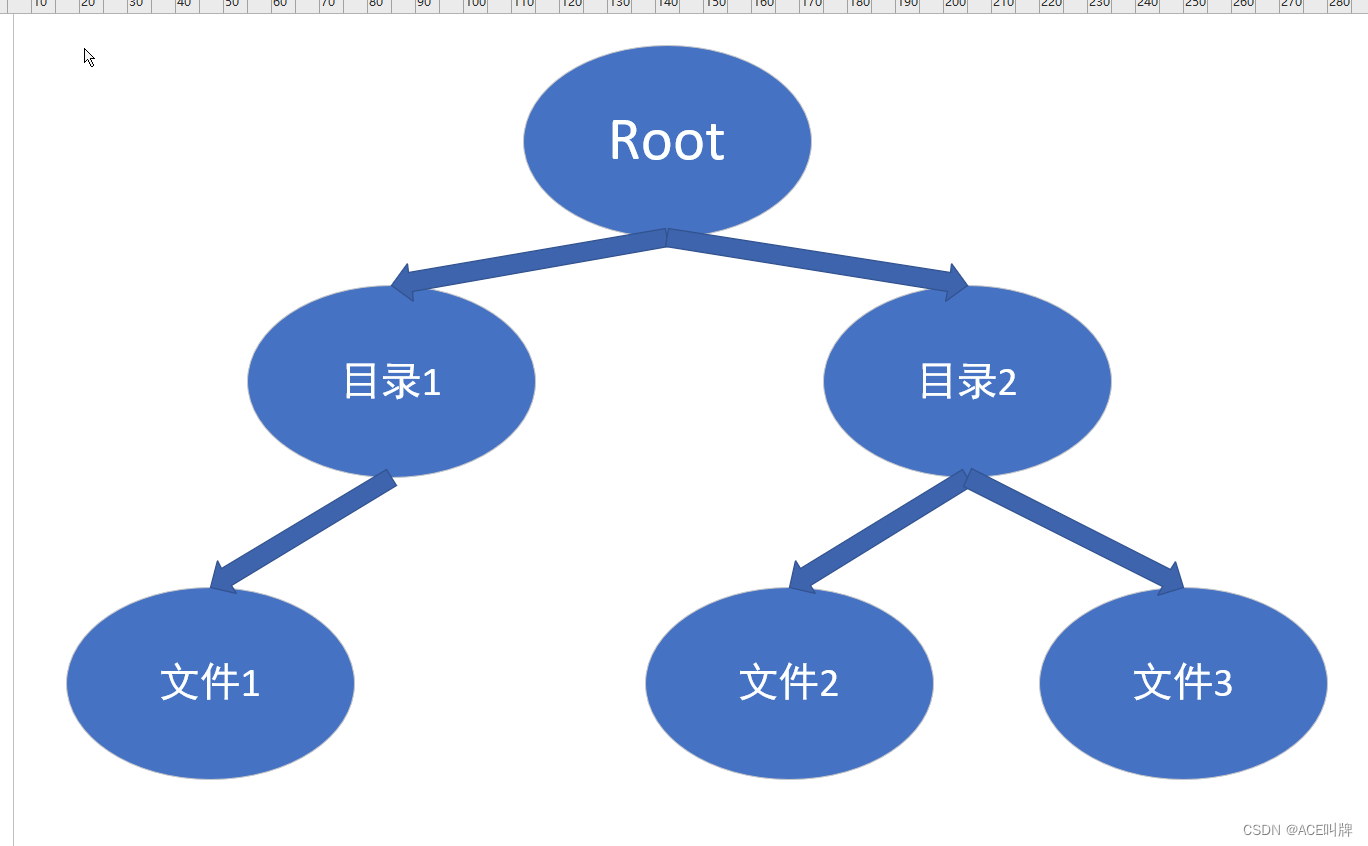
我们的目标,就是把它整成这样的形式:

图①
简单来说,也就是把下载拿到的训练集分成训练集(train)和验证集(val),然后猫的目录下都存猫,狗的目录下都存狗。
怎么整呢?我的做法是,首先新建一个文件夹,命名为dataset,然后把从网上下载的train和test的压缩包都解压到该目录下。再新建一个main.py文件用于执行划分训练集和验证集的代码。那么,解压后的文件结构就是:
|——dataset
|——test
|—— 0.png
|—— 1.png
|—— 2.png
|—— ...
|——train
|——cat //这个是自己提前建好的空目录
|——dog //这个也是提前建好的空目录
|——cat.1.png
|——cat.2.png
|——cat.3.png
|——...
|——dog.1.png
|——dog.2.png
|——dog.3.png
|——...
|——val
|——cat //这个是自己提前建好的空目录
|——dog //这个也是提前建好的空目录
|——main.py然后在main.py中执行以下代码:
import os
import shutil
dir_train = '.\\train'
dir_val = '.\\val'
for file in os.listdir(dir_train):
if file.startswith('cat') and file.endswith(".jpg"):
num = int(file.split('.')[1])
if num <= 9999:
shutil.move(os.path.join(dir_train, file), os.path.join(dir_train, 'cat', file))
else:
shutil.move(os.path.join(dir_train, file), os.path.join(dir_val, 'cat', file))
elif file.startswith('dog') and file.endswith(".jpg"):
num = int(file.split('.')[1])
if num <= 9999:
shutil.move(os.path.join(dir_train, file), os.path.join(dir_train, 'dog', file))
else:
shutil.move(os.path.join(dir_train, file), os.path.join(dir_val, 'dog', file))解释下这个代码是做什么的。这个代码就是把train目录文件下的编号是0-9999的猫和狗作为训练集(就是放到train目录下),然后把10000-12500的猫和狗放到val文件下。这样,我们在训练集,就总共有20000张图片,然后我们放了5000张图片留作验证使用。(当然你要是觉得这个比例不够好,可以自己再去调,该上面的两个9999就可以)
运行这段代码后,得到的文件夹结构就是像图①所示的那样了。
三、下载预训练权重
接下来,下载预训练配置权重。
从modelhub.md文件中,下载预训练权重。下载哪个都行,当然了,有些模型需要配置额外的环境。
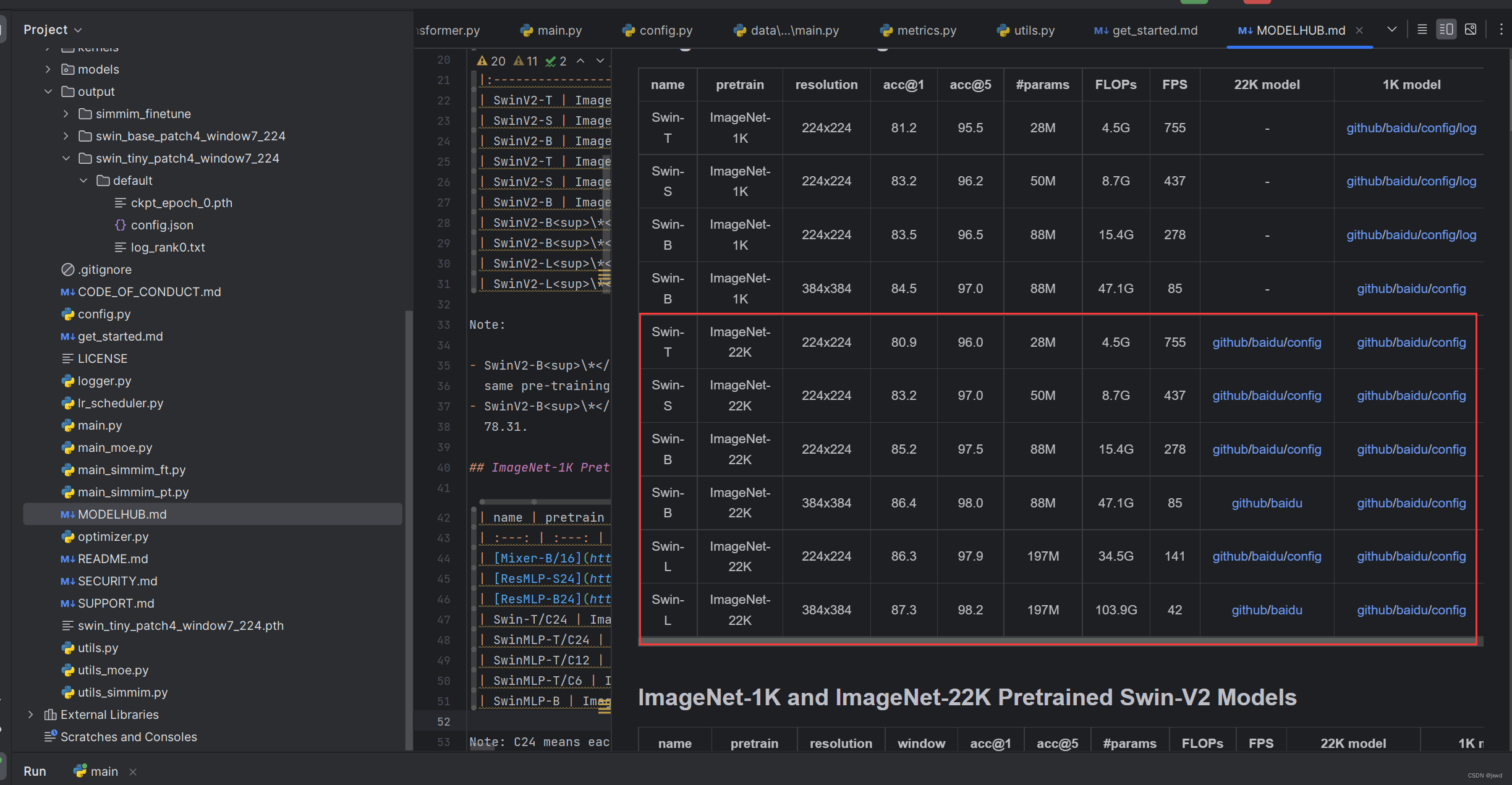
我们这里就以最简单的Swin-T为例,我们下载的也是Image 1K的model的预训练权重。那么,下载下来的预训练权重的名称就是swin_tiny_patch4_window7_224.pth。
OK,不管哪个,下载下来,然后放到swin-Transformer的根路径中,就像这样:

四、修改部分参数配置
由于我们是Windows操作系统,并且按照我们上面数据集来看,我们是二分类,所以我们需要修改一些参数配置。
4.1 修改config.py
_C.DATA.DATA_PATH = 'dataset'
# Dataset name
_C.DATA.DATASET = 'imagenet'
# Model name
_C.MODEL.NAME = 'swin_tiny_patch4_window7_224'
# Checkpoint to resume, could be overwritten by command line argument
_C.MODEL.RESUME ='swin_tiny_patch4_window7_224.pth'
# Number of classes, overwritten in data preparation
_C.MODEL.NUM_CLASSES = 2
上面这些参数是必然要改的。相信大家也能看懂这些参数是什么意思哈。
稍微解释下这个 (了解下即可)
_C.DATA.DATASET = 'imagenet' 这个的意思,我的理解就是采用什么数据集来去训练的,它有俩选择,要么是“imagenet”,要么是"imagenet22K",对应下面build.py的截图中的if和elsif。
4.2 修改build.py
build.py文件在data文件夹里。
修改这个地方:
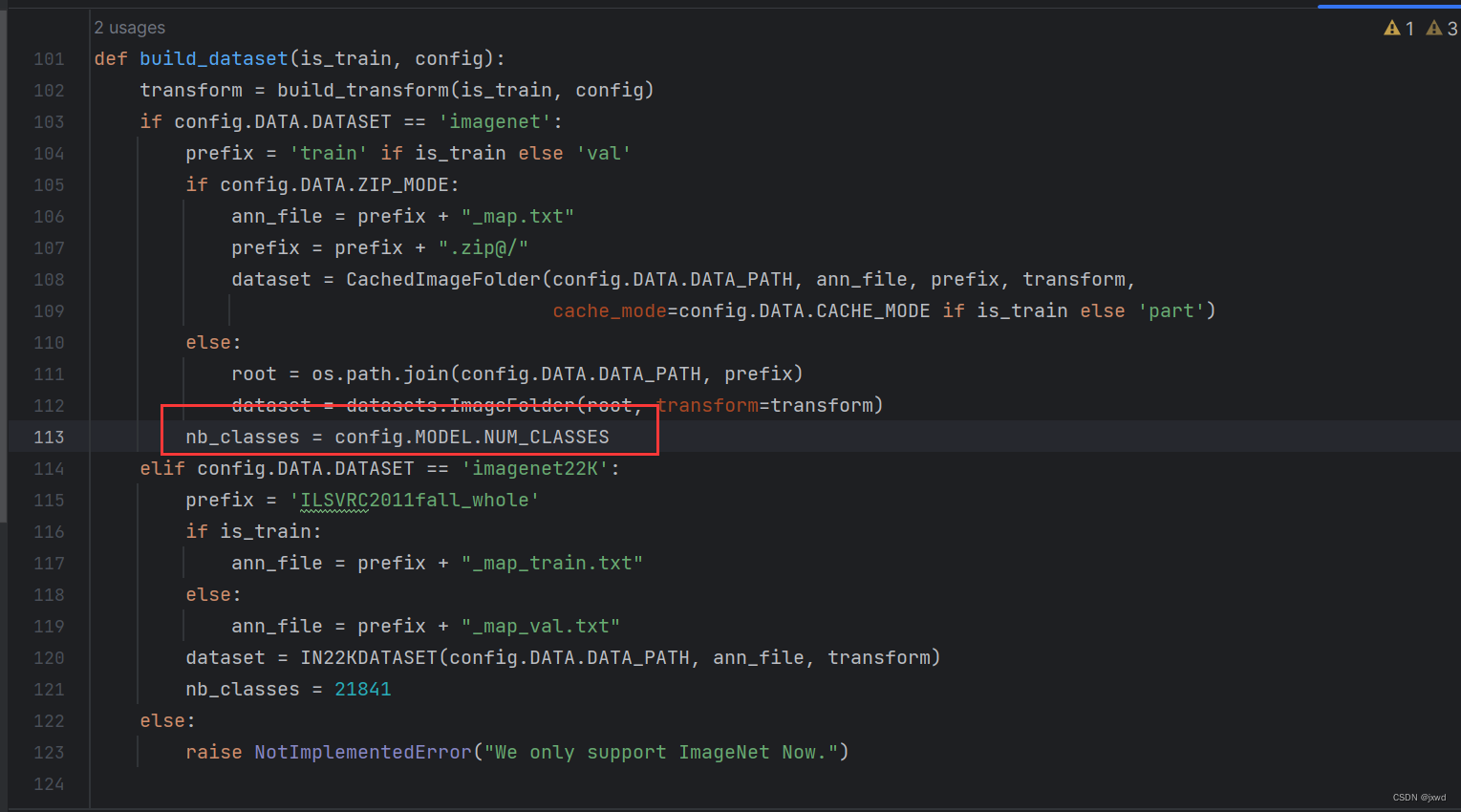
把原来的1000改成上图所示,或者直接改成2都行。
4.3 修改units.py
因为我们的预训练权重中最后是对1000类别进行分类的,而我们是二分类,所以我们需要在load_checkpoint这个函数中,把输出头的类别数给修改了。具体如下:
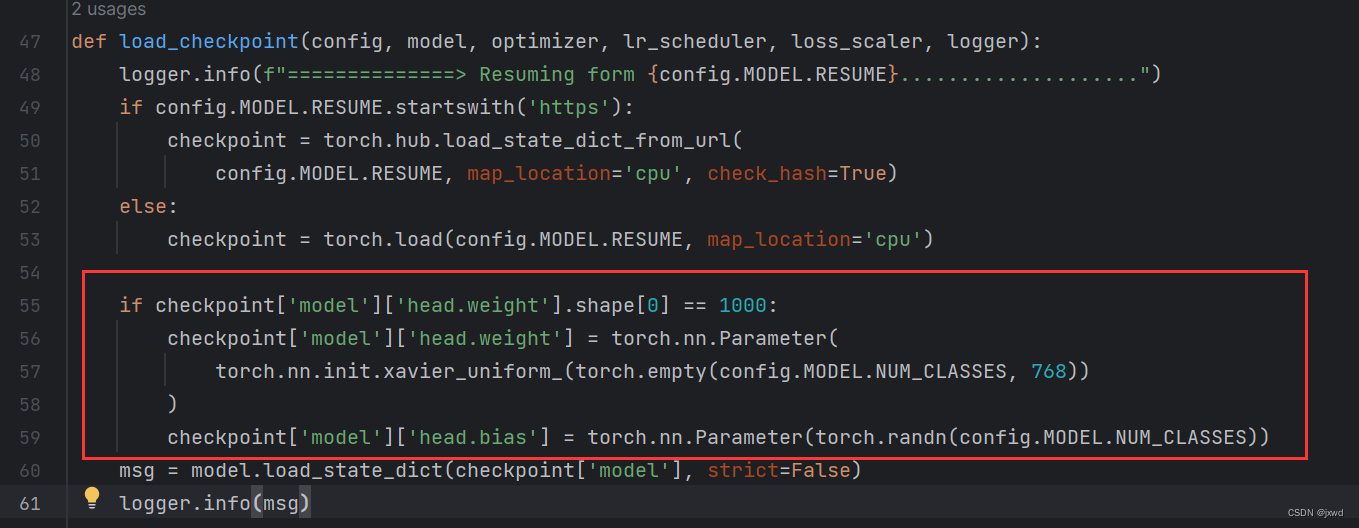
在上图的位置添加以下代码:
if checkpoint['model']['head.weight'].shape[0] == 1000:
checkpoint['model']['head.weight'] = torch.nn.Parameter(
torch.nn.init.xavier_uniform_(torch.empty(config.MODEL.NUM_CLASSES, 768))
)
checkpoint['model']['head.bias'] = torch.nn.Parameter(torch.randn(config.MODEL.NUM_CLASSES))4.4 修改main.py

将init_process_group函数修改如下:
torch.distributed.init_process_group(backend='gloo', init_method='env://', world_size=1, rank=0)想要在windows环境下跑通代码,那么前面的backend得换成“gloo”。然后后面的init_method我的用'env://'是可以跑通的,有的小伙伴可能跑不通,我看网上也有用‘file://tmp/somefile’的(对我来说行不通),大家如果最终是因为这行代码而导致代码跑不起来,可以专门去网上看看解决方案。反正上述代码我的是跑起来了。
4.5 修改其他的地方
还有些其他奇奇怪怪的情况,在这里就不一一列举,上网一查都可以查到。比如
from torch._six import inf已经不再用,而是直接从torch里导入,即
from torch import inf即可。
但是这些问题不是每个人都会遇到,就比如我自己配置的时候并没有遇到这些问题,我给别人配置的时候就遇到了这些问题。大家自己如果遇到了再去查就行。
4.6 将最后结果以折线图的形式呈现出来
先说一下我们最后画出来的图是什么样子的。就是横坐标是迭代次数,纵坐标左边是每次Train的avg_loss(平均的loss)大小,右边是Test时每次的avg_acc@1(平均准确率)。
修改五个地方。
在util.py文件中修改一处:
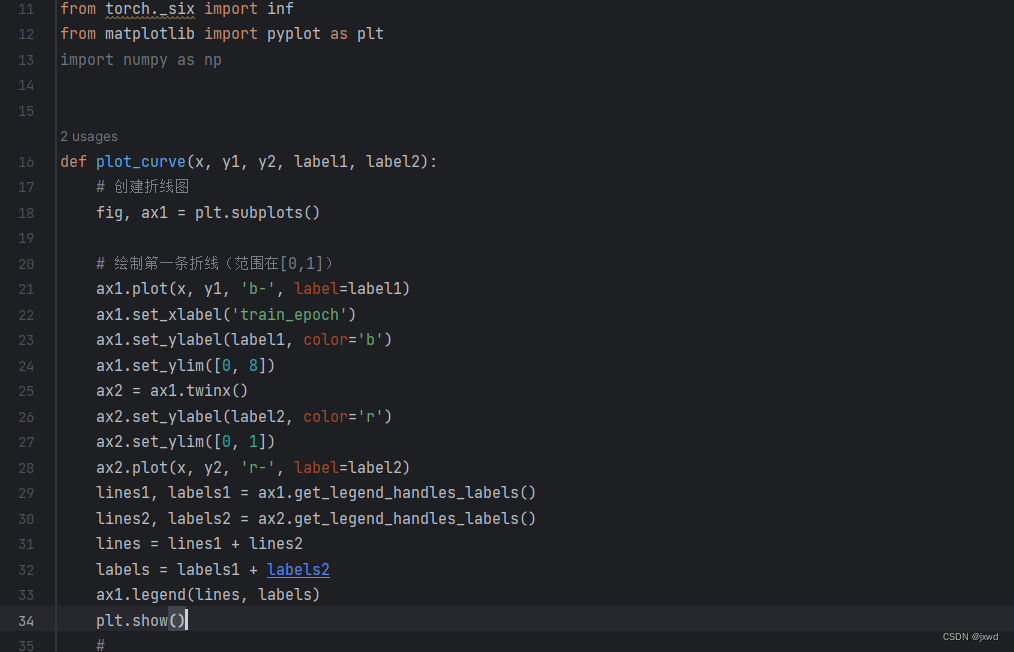
也就是添加以下代码,就是新添加一个函数。
from matplotlib import pyplot as plt
def plot_curve(x, y1, y2, label1, label2):
# 创建折线图
fig, ax1 = plt.subplots()
# 绘制第一条折线(范围在[0,1])
ax1.plot(x, y1, 'b-', label=label1)
ax1.set_xlabel('train_epoch')
ax1.set_ylabel(label1, color='b')
ax1.set_ylim([0, 8])
ax2 = ax1.twinx()
ax2.set_ylabel(label2, color='r')
ax2.set_ylim([0, 1])
ax2.plot(x, y2, 'r-', label=label2)
lines1, labels1 = ax1.get_legend_handles_labels()
lines2, labels2 = ax2.get_legend_handles_labels()
lines = lines1 + lines2
labels = labels1 + labels2
ax1.legend(lines, labels)
plt.show()然后在main.py中修改四处:
第一处:

可以在一开始的地方加上两个list用于存储每个epoch的avg_loss和avg_acc@1.
第二处:
在train_one_epoch函数的最后增加一行:
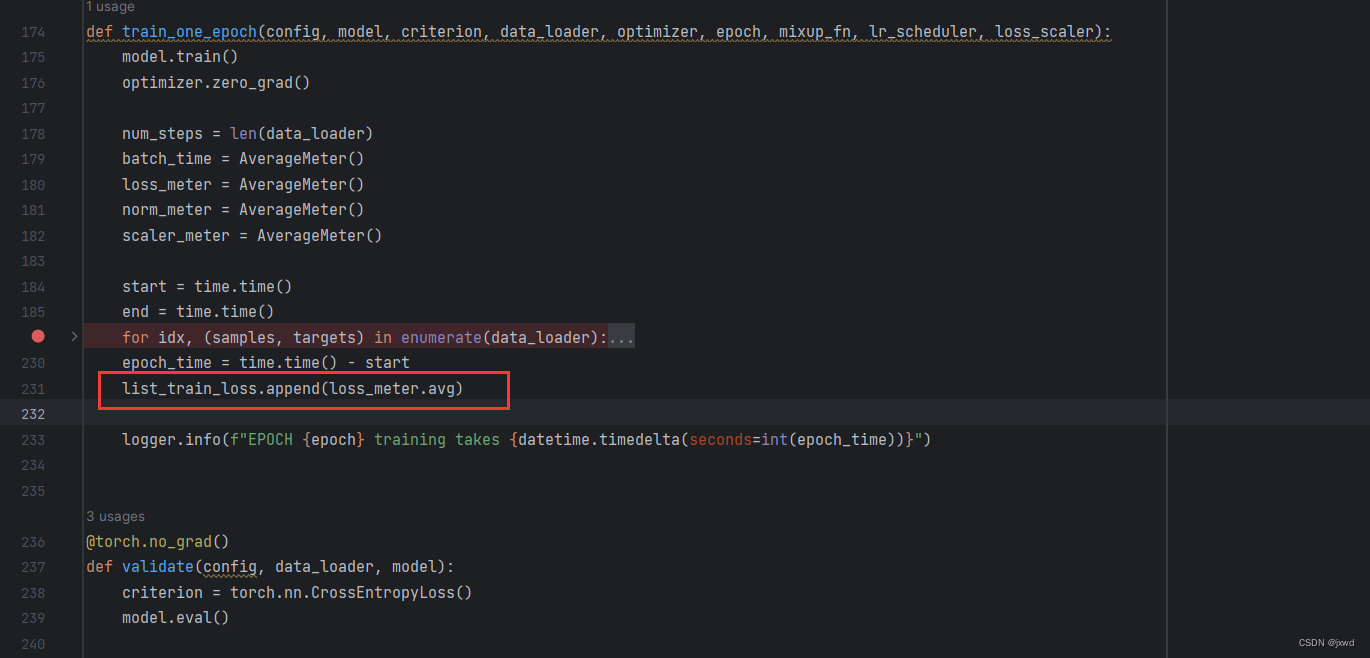
list_train_loss.append(loss_meter.avg)就是说每次训练完都把avg_loss存储进去。
第三处:
同理,在validate函数中也添加一行代码:
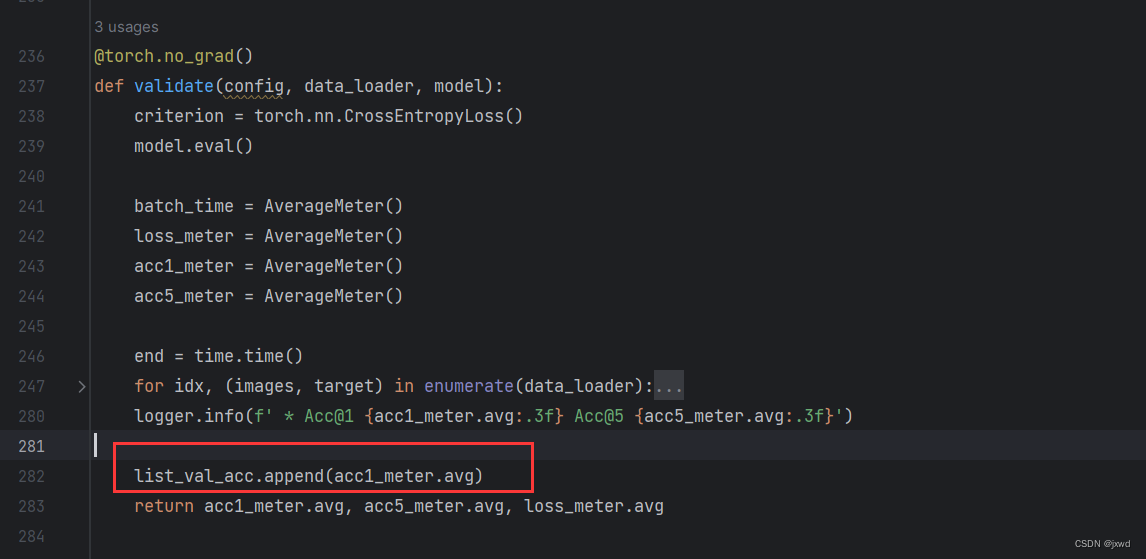
list_val_acc.append(acc1_meter.avg)作用和上面同理。
第四处:
在main函数的最后,加上这两行:
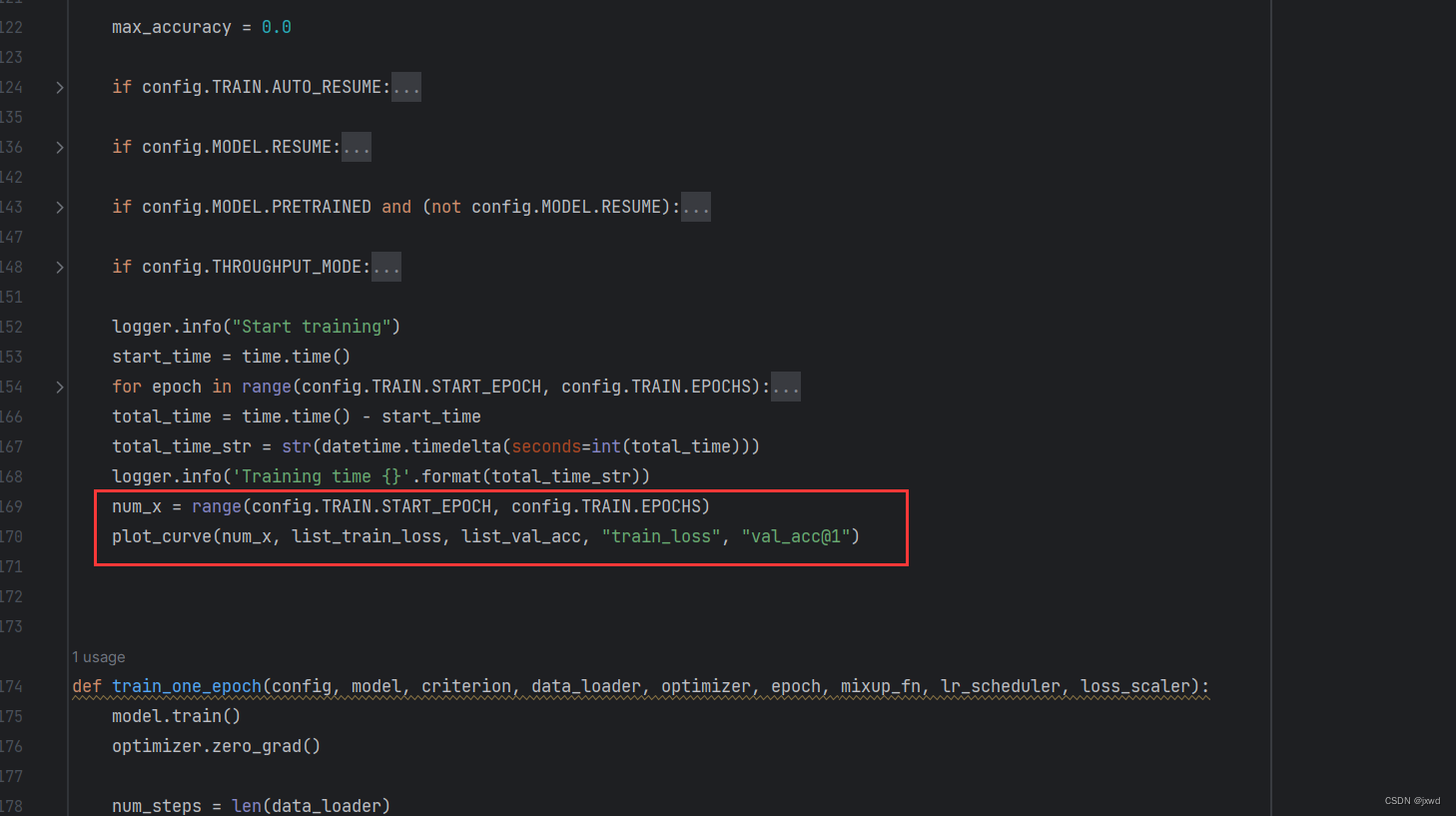
num_x = range(config.TRAIN.START_EPOCH, config.TRAIN.EPOCHS)
plot_curve(num_x, list_train_loss, list_val_acc, "train_loss", "val_acc@1")它的作用是最后显示出图示来。
但需要注意下哈,我在这里画出来的图,默认只能够画出来你从断点开始到最后结束的那一段。就是你checkpoint之前的是画不出来的,所以尽量一次性训练完就好。
五、其他可修改的地方
再说说其他可以修改的地方:
如果你觉得它打印的频次太多了,你可以修改参数:
# Frequency to logging info
_C.PRINT_FREQ = 10同样如果你觉得你训练次数过多或者过少,你可以修改参数:
_C.TRAIN.EPOCHS = 100如果你不想把你自身训练的每一轮模型都保存,你可以修改参数:
# Frequency to save checkpoint
_C.SAVE_FREQ = 1为什么修改这些参数大家可以从源码中去找哈。
六、运行代码
差不多都搞完了,我们将我们的代码跑起来:
如果不想用命令行,可以点击右上角的编辑配置:
然后在参数这一栏:
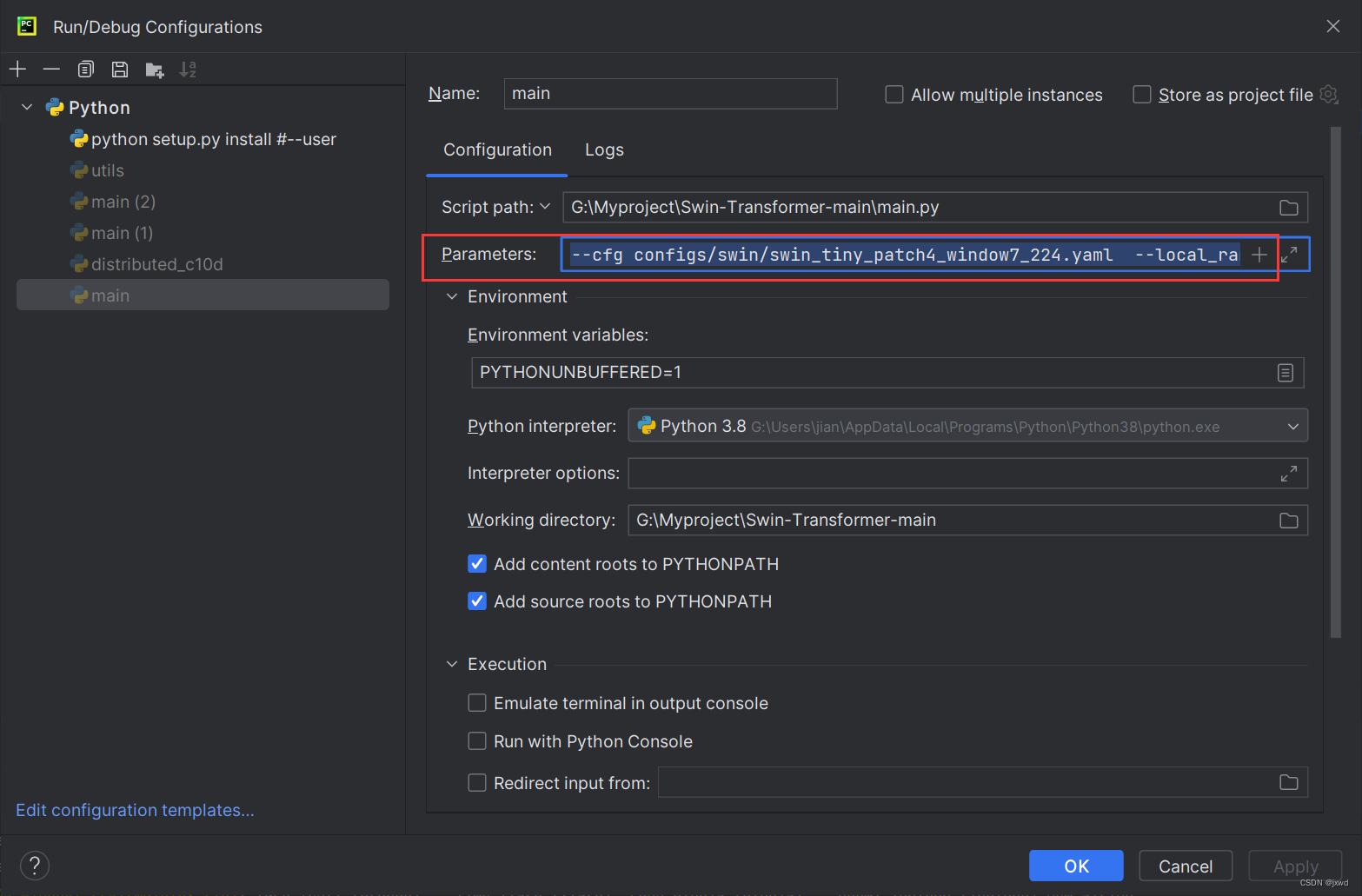
添加以下参数:
--cfg configs/swin/swin_tiny_patch4_window7_224.yaml --local_rank 0 --batch-size=64 --data-path=data/dataset解释下什么意思。
- --cfg是参数配置文件,它在configs文件夹里,你添加的这个配置的文件名需要和你的预训练权重的名字是一样的。
- --local_rank设置成0就行。
- --data-path后面需要添加你数据文件的路径。我就把它放到了data/dataset文件下。
- --batch-size看你GPU有多大了,如果不大,可以设置成16,如果比较大,也可以设置成64、128等。
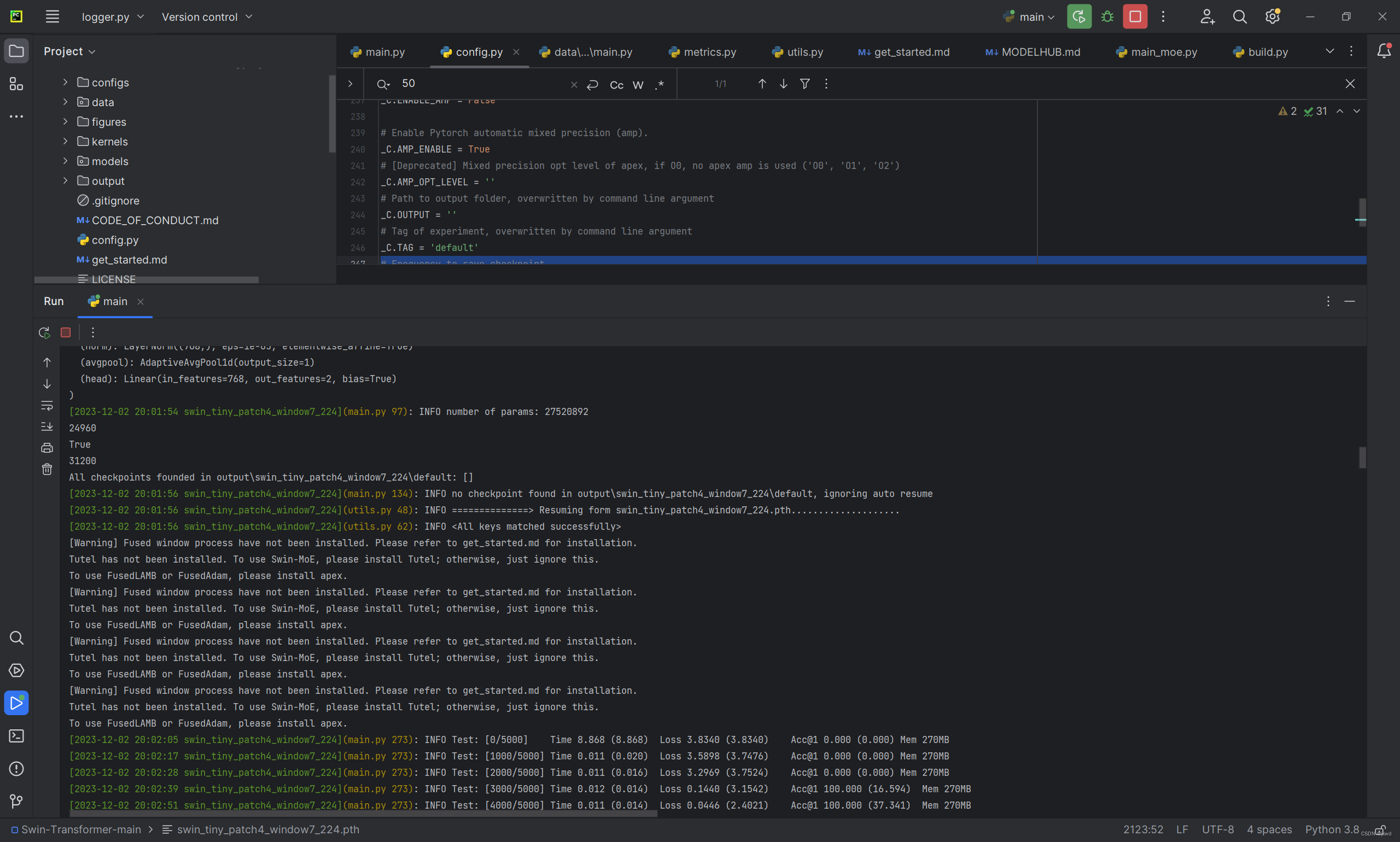
然后就,跑起来了。
好啦,如果有什么问题,欢迎留言。同时,如果觉得我写的文章对你有帮助,那就点个收藏,或者赞和关注吧,我将会持续带来优质的分享。