面试 Java 基础八股文十问十答第四期
作者:程序员小白条,个人博客
相信看了本文后,对你的面试是有一定帮助的!
⭐点赞⭐收藏⭐不迷路!⭐
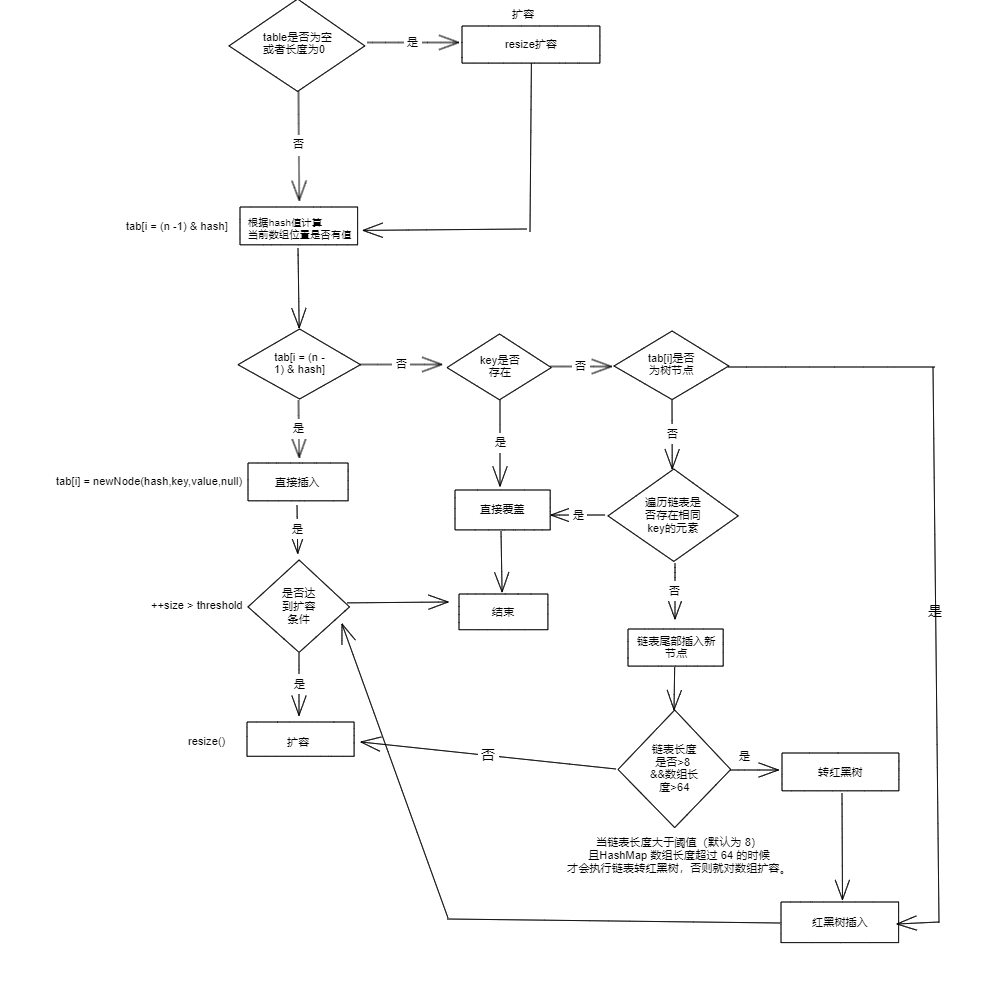
31.HashMap的put 方法执行过程
HashMap 只提供了 put 用于添加元素,putVal 方法只是给 put 方法调用的一个方法,并没有提供给用户使用。
对 putVal 方法添加元素的分析如下:
- 如果定位到的数组位置没有元素 就直接插入。
- 如果定位到的数组位置有元素就和要插入的 key 比较,如果 key 相同就直接覆盖,如果 key 不相同,就判断 p 是否是一个树节点,如果是就调用e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value)将元素添加进入。如果不是就遍历链表插入(插入的是链表尾部)。
32.ConcurrentHashMap的put方法
- 根据 key 计算出 hashcode 。
- 判断是否需要进行初始化。
- 即为当前 key 定位出的 Node,如果为空表示当前位置可以写入数据,利用 CAS 尝试写入,失败则自旋保证成功。
- 如果当前位置的 hashcode == MOVED == -1,则需要进行扩容。
- 如果都不满足,则利用 synchronized 锁写入数据。
- 如果数量大于 TREEIFY_THRESHOLD 则要执行树化方法,在 treeifyBin 中会首先判断当前数组长度 ≥64 时才会将链表转换为红黑树。
public V put(K key, V value) {
return putVal(key, value, false);
}
/** Implementation for put and putIfAbsent */
final V putVal(K key, V value, boolean onlyIfAbsent) {
// key 和 value 不能为空
if (key == null || value == null) throw new NullPointerException();
int hash = spread(key.hashCode());
int binCount = 0;
for (Node<K,V>[] tab = table;;) {
// f = 目标位置元素
Node<K,V> f; int n, i, fh;// fh 后面存放目标位置的元素 hash 值
if (tab == null || (n = tab.length) == 0)
// 数组桶为空,初始化数组桶(自旋+CAS)
tab = initTable();
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
// 桶内为空,CAS 放入,不加锁,成功了就直接 break 跳出
if (casTabAt(tab, i, null,new Node<K,V>(hash, key, value, null)))
break; // no lock when adding to empty bin
}
else if ((fh = f.hash) == MOVED)
tab = helpTransfer(tab, f);
else {
V oldVal = null;
// 使用 synchronized 加锁加入节点
synchronized (f) {
if (tabAt(tab, i) == f) {
// 说明是链表
if (fh >= 0) {
binCount = 1;
// 循环加入新的或者覆盖节点
for (Node<K,V> e = f;; ++binCount) {
K ek;
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
Node<K,V> pred = e;
if ((e = e.next) == null) {
pred.next = new Node<K,V>(hash, key,
value, null);
break;
}
}
}
else if (f instanceof TreeBin) {
// 红黑树
Node<K,V> p;
binCount = 2;
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
}
}
if (binCount != 0) {
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
}
addCount(1L, binCount);
return null;
}
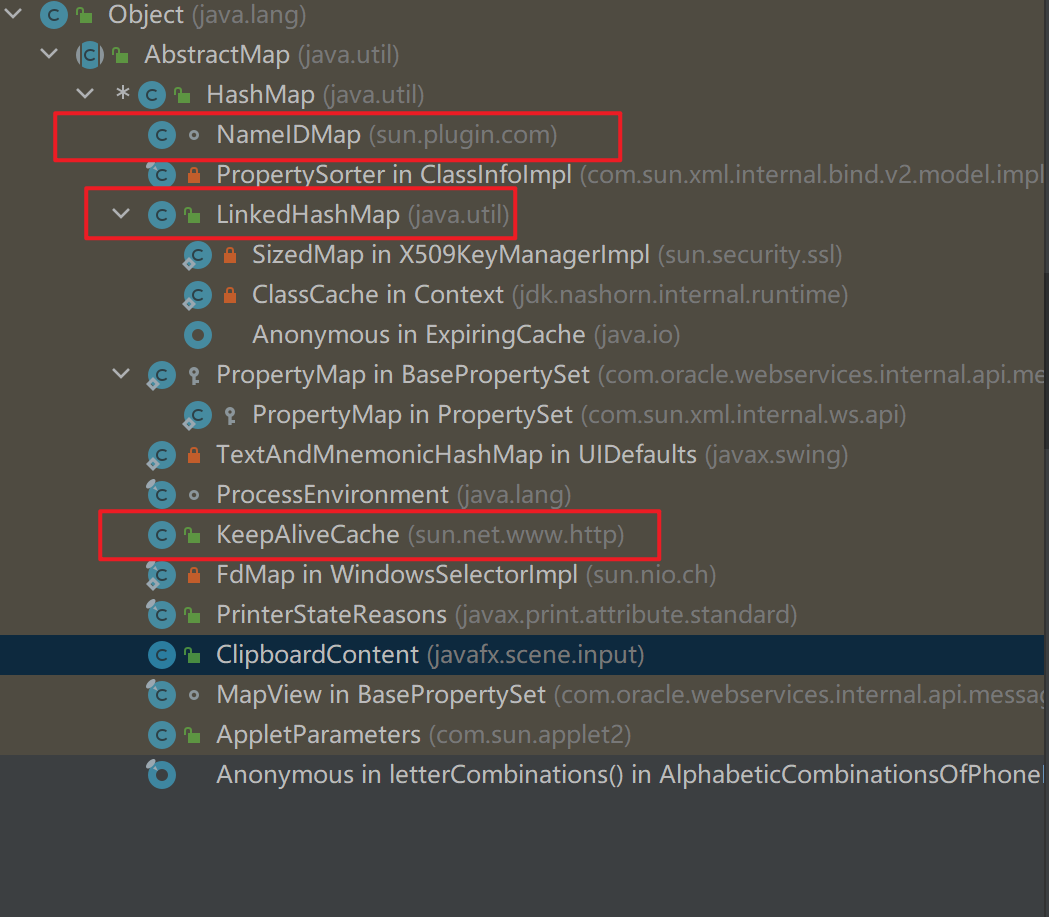
33.hashmap子类知道多少?
34.对于多态的理解是什么?
1.父类的引用指向子类的对象
子类重写父类的方法:子类可以继承父类的方法,并对其进行重写。当通过父类的引用调用这个方法时,实际执行的是子类重写后的方法。
比如Person person = new Student Person是父类 Student ,都有一个工作的方法,student重写工作方法,比如上学。
2.接口的引用指向实现类的对象
- List list = new ArrayList(); 2) ArrayList list= new ArrayList()
在第一种情况下,无法使用ArrayList特有的方法,因为声明的是一个List类型的变量,只能使用List接口中定义的方法。而在第二种情况下,声明了一个ArrayList类型的变量,可以使用ArrayList特有的方法。
3.方法的重载
方法的重载:方法重载指的是在同一个类中定义多个同名但参数列表不同的方法。在调用这个方法时,编译器会根据参数的类型和数量来确定具体调用哪个方法。
4.方法重写
4.1子类中的方法必须与父类中的方法具有相同的名称。
4.2子类中的方法必须具有相同的参数列表(参数的类型、顺序和数量)。
4.3子类中的方法的返回类型可以是父类方法返回类型的子类型(也称为协变返回类型)。
4.4子类中的方法不能缩小父类方法的访问权限(即不能将父类方法的访问权限由public改为private),不能更加严格,但是可以扩大访问权限。
5.向上转型和向下转型
5.1向上转型(Upcasting):将一个子类对象转换为父类类型。这是一个隐式的转型过程,不需要显式地进行类型转换。
5.2向下转型(Downcasting):将一个父类对象转换为子类类型。这是一个显式的转型过程,需要使用强制类型转换符进行类型转换。需要注意进行类型检查,避免类型转换异常。
35.对于static变量的理解?static变量分配内存的时候发生在哪个环节?
static变量是一种静态变量,它在程序执行期间保持不变。它被所有类的对象所共享,这意味着无论创建多少个类的对象,静态变量只有一个副本。
静态变量在类定义时被声明,而不是在对象创建时分配内存。内存分配发生在程序加载时,在程序的生命周期内只会分配一次。
静态变量是在类加载阶段的第二阶段连接(第二阶段准备阶段)从方法区取出内存,进行静态变量的默认初始化,真正被赋值的时候是第三阶段初始化。
36.JDK1.8对于方法区的实现是?(元空间)元空间还会存放什么东西?
- 为什么永久代(HotSpot虚拟机)要改成方法区(元数据区)?
因为永久代的垃圾回收条件苛刻,所以容易导致内存不足,而转为元空间,使用本地内存,极大减少了 OOM 异常,毕竟,现在电脑的内存足以支持 Java 的允许。
- 只有 Hotspot 才有永久代。BEA JRockit、IBMJ9 等来说,是不存在永久代的概念的。
- 必要性:1.为永久代设置空间大小是很难确定的 2.对永久代进行调优是很困难的。
元数据区(MetaSpace)存放:1.运行时常量池和静态常量池(字符串常量池放在堆中) 2.类元信息(类的二进制字节码文件,类的名称,父类,接口,成员变量,方法,静态变量,常量,常量池的符号引用和指向其他类的引用) 3.方法元信息(方法访问修饰符,返回类型,参数类型,异常类型)
37.为什么String要设计成Final类?
只有当字符串是不可变的,字符串池才有可能实现
字符串池的实现可以在运行时节约很多heap空间,因为不同的字符串变量都指向池中的同一个字符串。但如果字符串是可变的,那么String interning将不能实现(注:String interning是指对不同的字符串仅仅只保存一个,即不会保存多个相同的字符串。),因为这样的话,如果变量改变了它的值,那么其它指向这个值的变量的值也会一起改变。
如果字符串是可变的,那么会引起很严重的安全问题
譬如,数据库的用户名、密码都是以字符串的形式传入来获得数据库的连接,或者在socket编程中,主机名和端口都是以字符串的形式传入。因为字符串是不可变的,所以它的值是不可改变的,否则黑客们可以钻到空子,改变字符串指向的对象的值,造成安全漏洞。
因为字符串是不可变的,所以是多线程安全的
同一个字符串实例可以被多个线程共享。这样便不用因为线程安全问题而使用同步。字符串自己便是线程安全的。
类加载器要用到字符串,不可变性提供了安全性,以便正确的类被加载
譬如你想加载java.sql.Connection类,而这个值被改成了myhacked.Connection,那么会对你的数据库造成不可知的破坏。
作为Map的key,提高了访问效率
因为字符串是不可变的,所以在它创建的时候hashcode就被缓存了,不需要重新计算。这就使得字符串很适合作为Map中的键,字符串的处理速度要快过其它的键对象。这就是HashMap中的键往往都使用字符串。因为Map使用得也是非常之多,所以一举两得
38.什么情况下会导致元数据区溢出?
1.加载的类的数量过多(比如CGLIB不断生成代理类)
2.类的大小过大,包含大量静态属性或常量
3.元数据区的参数设置不当,内存给的太小
堆在什么时候会内存溢出?
堆内存存在大量对象,且对象都有被引用,创建对象不合理。
栈在什么时候会溢出?
递归调用没有写好结束条件,导致栈溢出。
频繁FullGC的几种原因?
拓展:新生代占比堆的三分之一,而老年代占比堆的三分之二。1:2
新生代占比:Eden8,S0,S1 各占1份,8:1:1
① 系统承载高并发请求,或者处理数据量过大,导致YoungGC很频繁,而且每次YoungGC过后存活对象太多,内存分配不合理,Survivor区域过小,导致对象频繁进入老年代,频繁触发FullGC
② 系统一次性加载过多数据进内存,搞出来很多大对象,导致频繁有大对象进入老年代,然后频繁触发FullGC
③ 系统发生了内存泄漏,创建大量的对象,始终无法回收,一直占用在老年代里,必然频繁触发FullGC
④ Metaspace 因为加载类过多触发FullGC
⑤ 误调用 System.gc() 触发 FullGC
39.Java的常量优化机制
数值常量优化机制
1、给一个变量赋值,如果“=”号右边是常量的表达式没有一个变量,那么就会在编译阶段计算该表达式的结果。
2、然后判断该表达式的结果是否在左边类型所表示范围内。
3、如果在,那么就赋值成功,如果不在,那么就赋值失败。
byte b1 = 1 + 2;
System.out.println(b1);
// 输出结果 3
这个就是典型的常量优化机制,1 和 2 都是常量,编译时可以明显确定常量结果,所以直接把 1 和 2 的结果赋值给 b1 了。(和直接赋值 3 是一个意思)
编译器对 String 的常量也有优化机制
String s1 = "abc";
String s2 = "a"+"b"+"c";
System.out.println(s1 == s2); // true
String a = "a1";
String b = "a" + 1; // 常量+基础数据类型
System.out.println((a == b)); //result = true
String a = "atrue";
String b = "a" + true;
System.out.println((a == b)); //result = true
String a = "a3.4";
String b = "a" + 3.4;
System.out.println((a == b)); //result = true
String s1 = "ab";
String s2 = "abc";
String s3 = s1 + "c"; // 变量+常量
System.out.println(s3 == s2); // false
final String s1 = "ab";
String s2 = "abc";
String s3 = s1 + "c"; //变量相加
System.out.println(s2 == s3); // true
40.Comparable和Comparator接口区别和对比使用场景
1、Comparable 接口简介
Comparable接口:位于java.lang包下,需要重写public int compareTo(T o);
Comparable 是排序接口。若一个类实现了Comparable接口,就意味着“该类支持排序”。
“实现Comparable接口的类的对象”可以用作“有序映射(如TreeMap)”中的键或“有序集合(TreeSet)”中的元素,而不需要指定比较器。
它强行将实现它的每一个类的对象进行整体排序-----称为该类的自然排序,实现此接口的对象列表和数组可以用Collections.sort(),和Arrays.sort()进行自动排序;
接口中通过compareTo(T o)来比较x和y的大小。若返回负数,意味着x比y小;返回零,意味着x等于y;返回正数,意味着x大于y。
2、Comparator 接口简介
Comparator接口:位于java.util包下,需要重写int compare(T o1, T o2);
Comparator 是比较器接口。我们若需要控制某个类的次序,而该类本身不支持排序(即没有实现Comparable接口);
它是针对一些本身没有比较能力的对象(数组)为它们实现比较的功能,所以它叫做比较器,是一个外部的东西,通过它定义比较的方式,再传到Collection.sort()和Arrays.sort()中对目标排序,而且通过自身的方法compare()定义比较的内容和结果的升降序;
int compare(T o1, T o2) 和上面的x.compareTo(y)类似,定义排序规则后返回正数,零和负数分别代表大于,等于和小于。
总结:
1.只要涉及对象大小的比较,就可以实现这两个接口的任意一个。
Comparable接口:通过对象调用重写后的compareTo()
Comparator接口:通过对象调用重写后的compare()
2.如果要调用sort进行排序
Comparable接口:自然排序
Comparator接口:定制排序–>属于临时性的排序规则
3.compare和compareTo方法的对比
compareTo:是拿调这个方法的对象和形参比大小
compare:直接让两个形参比大小