概述
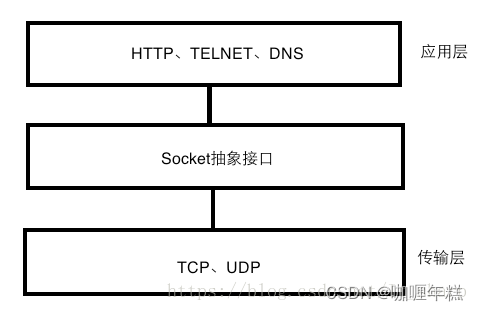
ZooKeeper是一种分布式协调服务,用于管理大型主机集。在分布式环境中协调和管理服务是一个复杂的过程。ZooKeeper通过其简单的架构和API解决了这个问题。ZooKeeper允许开发人员专注于核心应用程序逻辑,而不必担心应用程序的分布式性质。
Zookeeper工作机制
Zookeeper从设计角度来理解,就是一个观察者模式设计的分布式服务管理框架,它负责存储和管理核心数据,接受观察者的注册,一旦数据状态发生变化,Zookeeper负责通知在Zookeeper上注册的观察者。
特点

数据结构
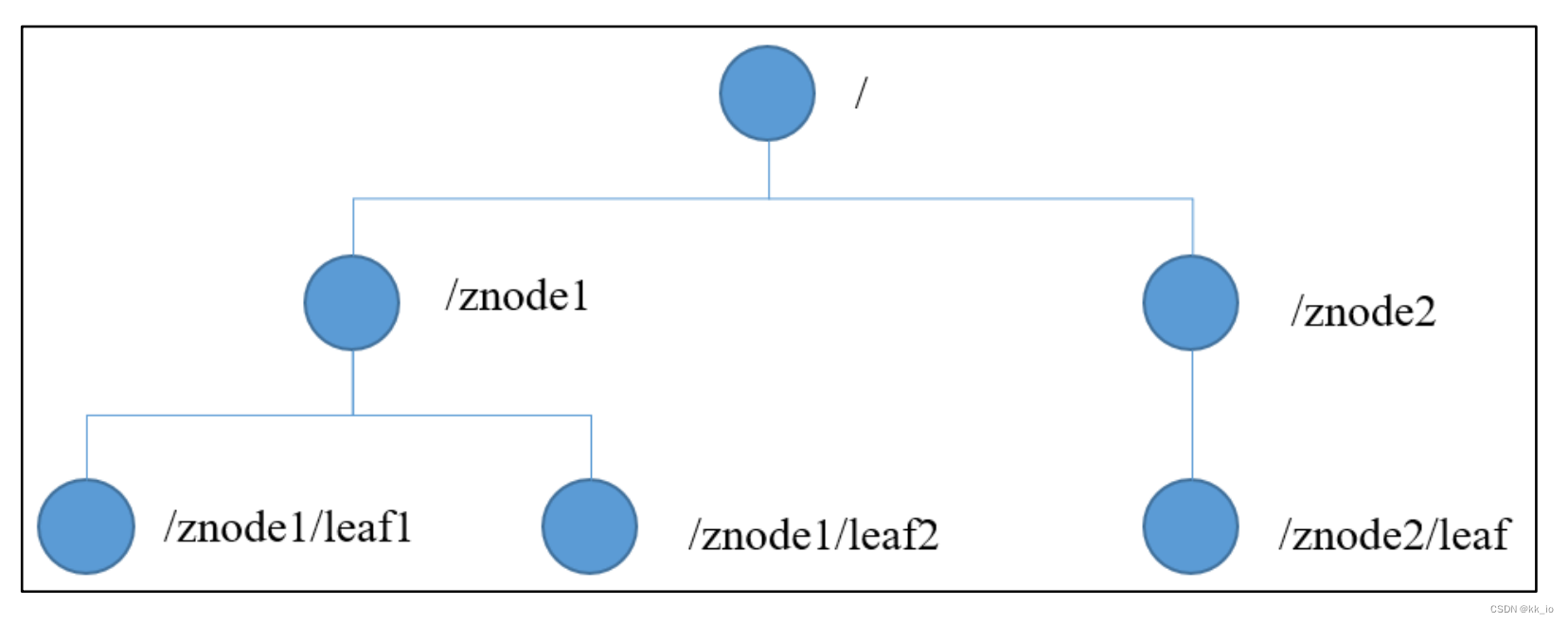
Zookeeper数据模型的结构与Unix 文件系统类似,整体可以看做为一颗树,每个节点可称做 ZNode。每个 ZNode 默认存储 1MB的数据,每个 ZNode可以通过其路径唯一标识。
应用场景
提供的服务包括:同意命名服务、统一配置管理、统一集群管理、服务器节点动态上下线、软负载均衡等。这里重点讲统一集群管理和服务器节点动态上下线。
统一集群管理
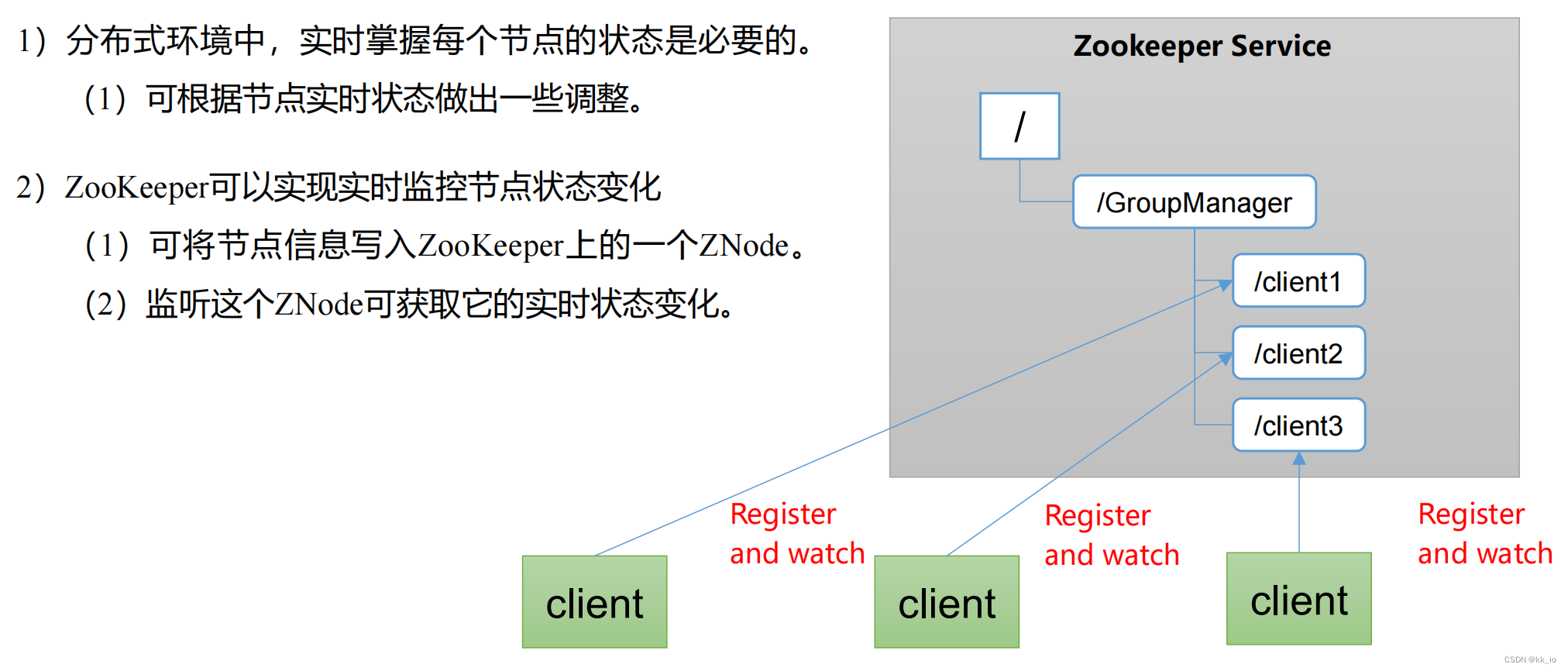
服务器节点动态上下线
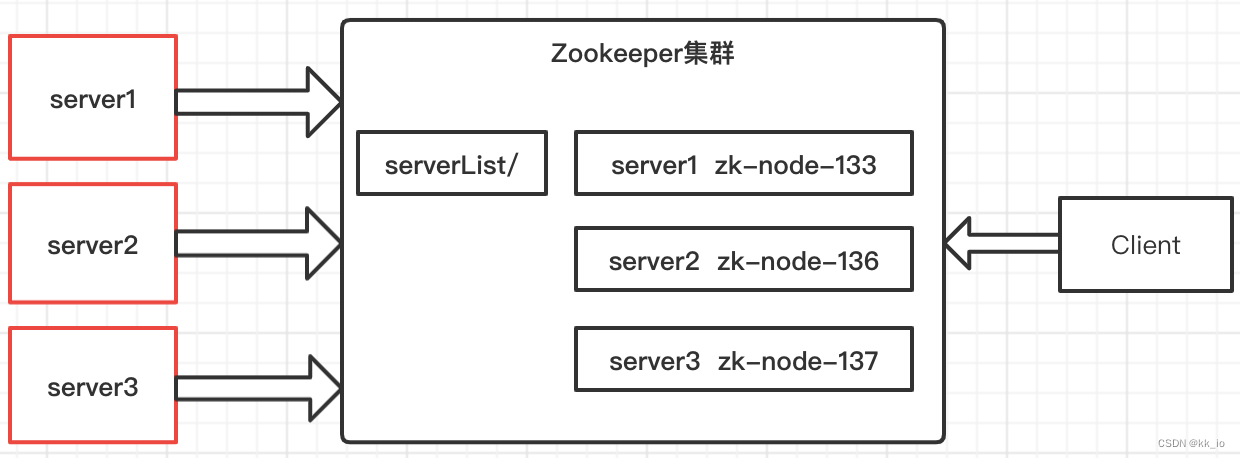
客户端能实时洞察到服务器上下线的变化
zookeeper 安装
- 集群规划:在hadoop101、hadoop102 和hadoop103 三个节点上部署 Hadoop
- 下载地址: https://archive.apache.org/dist/zookeeper/zookeeper-3.5.7/
- 解压安装:
[logan@hadoop101 software]$ tar -zxvf apache-zookeeper-3.5.7-bin.tar.gz -C /opt/module/
[logan@hadoop101 software]$ cd /opt/module
[logan@hadoop101 module]$ ln -snf apache-zookeeper-3.5.7-bin/ zookeeper
- 配置服务器编号
- 在/opt/module/zookeeper 目录下创建zkData
[logan@hadoop101 zookeeper]$ mkdir zkData- 在zkData 目录下创建myid文件,并写入编号 1,然后
:wq退出。注意使用 vi编辑器写入,尽量不要拷贝或者用其他服务写入
[logan@hadoop101 zkData]$ vim myid 1 - 配置zoo.cfg文件
- 复制一份zoo.cfg 文件
[logan@hadoop101 zkData]$ cd /opt/module/zookeeper/conf/ [logan@hadoop101 conf]$ cp zoo_sample.cfg zoo.cfg- 在zoo.cfg修改数据存储路径配置
[logan@hadoop101 conf]$ vim zoo.cfg dataDir=/opt/module/zookeeper/zkData- 在zoo.cfg中增加如下配置
#######################cluster########################## server.1=hadoop101:2888:3888 server.2=hadoop102:2888:3888 server.3=hadoop103:2888:3888 - 同步/opt/module/apache-zookeeper-3.5.7-bin目录到hadoop102和 hadoop103,注意 xsync 是hadoop 安装时候配置的脚本,可以同步到其他服务器上去
[logan@hadoop101 bin]$ xsync /opt/module/apache-zookeeper-3.5.7-bin/
- 修改hadoop102 和 hadoop103上的 myid 文件为 2 和 3
- 分别在hadoop101、hadoop102和hadoop103 上启动 zookeeper。
/opt/module/zookeeper/bin/zkServer.sh start
- 使用zkCli 进行测试
[logan@hadoop101 zookeeper]$ bin/zkCli.sh
[zk: localhost:2181(CONNECTED) 3] ls /
[zookeeper]
[zk: localhost:2181(CONNECTED) 4] create /test
Created /test
[zk: localhost:2181(CONNECTED) 6] ls /
[test, zookeeper]