一、介绍
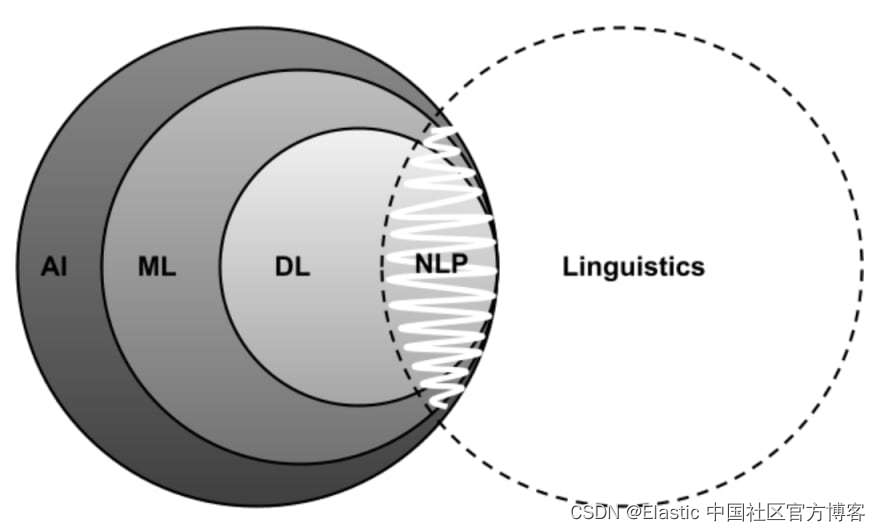
自然语言处理 (NLP) 中的组合语义分析是一个引人入胜且复杂的话题。为了充分理解它,将这个概念分解成它的基本组成部分是至关重要的:组合语义及其在NLP中的应用。组合语义学是植根于语言哲学和语言学的原则,主要归功于哲学家弗雷格。它假设复杂表达式的含义由其结构及其组成部分的含义决定。从本质上讲,这意味着可以从句子各个部分(单词)的含义以及它们在句法上的组合方式来理解句子的含义。

逐字解码意义:NLP数字时代的组合语义艺术。
二、NLP中的组合语义
在 NLP 中,组合语义是一个关键概念,因为它指导理解计算机如何解释、处理和生成人类语言。NLP的挑战在于对语言的这种组合性质进行建模,以便机器能够理解和生成类似人类的文本。
NLP中的关键组件:
- 语法和语义集成:NLP模型需要将句法结构与语义含义集成。语法决定了单词在句子中的排列方式,而语义则处理含义。有效的 NLP 模型结合这些来理解完整的上下文。
- 词嵌入:这些是词的向量表示,捕获语义含义。像 Word2Vec 或 GloVe 这样的工具为这些嵌入提供了基础。然而,这些模型有时会在构图方面遇到困难,因为它们孤立地表示单词。
- 句子嵌入:句子嵌入超越了单个单词,代表了句子的语义内容。像 BERT 和 GPT(由 OpenAI 开发)这样的模型旨在更好地捕捉较长文本字符串的组成方面。
- 处理歧义:语言本质上是模棱两可的。NLP中的组合语义分析必须处理这种歧义,根据上下文确定正确的含义。
三、挑战与解决方案
- 上下文变化:根据上下文,单词可以具有不同的含义。像变形金刚(BERT、GPT)这样的高级模型旨在通过查看整个句子或段落来处理这个问题,而不仅仅是单个单词。
- 成语和固定表达:这些不遵循标准的组成规则。处理它们需要更高级的语言建模,有时还需要针对特定领域的训练。
- 依赖关系解析:了解句子中的单词如何相互依赖和关联对于准确的语义分析至关重要。
未来方向
NLP中组合语义分析的未来在于增强对上下文和人类语言微妙之处的理解。这包括更好的讽刺、幽默和情感底色模型。它还涉及为真正的全球 NLP 应用程序集成跨语言语义。
四、代码
在 Python 中为组合语义分析创建完整的代码示例,以及合成数据集和绘图,涉及几个步骤。我将指导您完成整个过程,其中包括创建合成数据集,应用基本的 NLP 模型进行语义分析,然后可视化结果。
第 1 步:安装必要的库
首先,您需要安装一些 Python 库。主要的是numpy ,matplotlib用于绘图nltk、spacy用于 NLP 任务。您可以通过 pip 安装它们:
pip install numpy matplotlib nltk spacy步骤 2:创建合成数据集
让我们创建一个简单的合成数据集。用于语义分析的合成数据集可能由具有不同结构和含义的句子组成。
import numpy as np
# Example synthetic dataset
sentences = [
"The cat sat on the mat.",
"A dog barked loudly outside.",
"The sun shines brightly.",
"An apple falls from the tree.",
"She read the book quietly."
]
# Simple binary labels for some property (e.g., positive or negative sentiment)
labels = np.array([1, 0, 1, 0, 1]) # 1 for positive, 0 for negative第 3 步:组合语义分析
为简单起见,让我们使用 NLTK 来标记和分析句子。我们将创建一个基本模型来表示句子的语义内容。
import nltk
from nltk.tokenize import word_tokenize
nltk.download('punkt')
# Tokenize sentences
tokenized_sentences = [word_tokenize(sentence) for sentence in sentences]
# Basic semantic analysis (counting word length as a proxy for this example)
semantic_values = [len(sentence) for sentence in tokenized_sentences]第 4 步:可视化结果
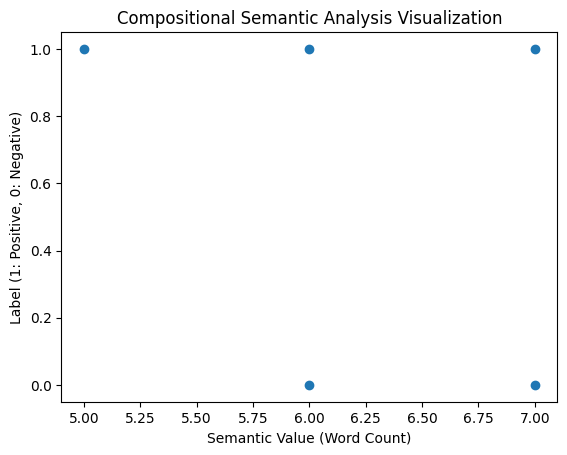
现在,让我们根据标签绘制语义值。
import matplotlib.pyplot as plt
plt.scatter(semantic_values, labels)
plt.xlabel('Semantic Value (Word Count)')
plt.ylabel('Label (1: Positive, 0: Negative)')
plt.title('Compositional Semantic Analysis Visualization')
plt.show()关于实际应用的注意事项
在实际场景中,组合语义分析要复杂得多。它通常涉及使用高级 NLP 模型,如 BERT 或 GPT,它们可以根据上下文和单词组成来理解句子的语义。这些模型需要更复杂的设置,包括对大型数据集的微调和更复杂的特征提取方法。
此示例高度简化,用于教育目的。真正的语义分析涉及理解上下文、惯用语和语言的细微差别,而这个简单的模型无法捕捉到这些。您可以在 Python 环境中运行此代码,以了解如何可视化组合语义分析的基本思想。但是,为了进行更深入、更准确的分析,请考虑探索 Hugging Face 的 Transformer 等库,这些库为高级 NLP 任务提供预训练模型。
五、结论
组合语义分析是使机器有效地理解和使用人类语言的核心。NLP 模型的进步,尤其是深度学习和神经网络的进步,极大地推动了这一领域的发展。然而,人类语言的复杂性和细微差别确保了这仍然是 NLP 中一个充满活力和挑战性的研究领域。