其实我早就很想写这篇文章了,RPC是一切现代计算机应用中非常重要的思想。也是微服务和分布式的总体设计思想。只能说是非常中要,远的不说,就说进的这个是面试必问的。不管用的上不,但是就是非常重要。
文章目录
- RPC的原理
- 本地调用
- RPC调用
- server服务
- 客户端来请求上述HTTP服务
- `RPC原理`
- 如何做到透明化(封装)远程服务调用
- 对消息进行编码和解码
- 序列化
RPC的原理
RPC(Remote Procedure Call Protocol)远程过程调用协议。一个通俗的描述是:客户端在不知道调用细节的情况下,调用存在于远程计算机上的某个对象,就像调用本地应用程序中的对象一样。
一种通过网络从远程计算机程序上请求服务,而不需要了解底层网络技术的协议。
(这里我做一个解释:是不是有人会将这个与TCP等传输协议放在一起比较,而我想说这么比较是对的。这里献上一篇文章–tcp、http、rpc和grpc总结,但是要注意,这其中的区别)
不过这里我做一个强调,这篇文章必须将这些协议弄清楚了,才能看,他不是雪中送碳,而是锦上添花。
RPC是一种服务器-客户端(Client/Server)模式,经典实现是一个通过发送请求-接受回应进行信息交互的系统。
首先与RPC(远程调用)相对应的是本地调用。
本地调用
先看一个go文件
package main
import "fmt"
func add(x, y int)int{
return x + y
}
func main(){
// 调用本地函数add
a := 10
b := 20
ret := add(a, x)
fmt.Println(ret)
}
在程序中本地调用add函数的执行流程,可以理解为以下四个步骤。
- 将变量
a和b的值分别压入堆栈上 - 执行
add函数,从堆栈中获取a和b的值,并将它们分配给x和y - 计算
x + y的值并将其保存到堆栈中 - 退出
add函数并将x + y的值赋给ret
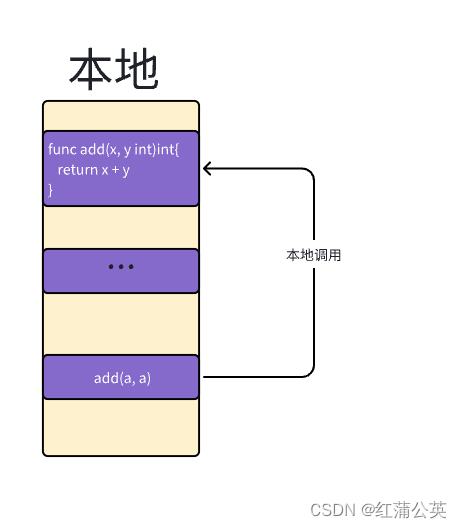
定义add函数的代码和调用add函数的代码共享同一个内存空间,所以调用能够正常执行
但是我们无法直接在另一个程序——中调用add函数,因为它们是两个程序——内存空间是相互隔离的。(两个进程不共享内存)
(两个程序可能在一个主机上,也可能在不同的主机上)
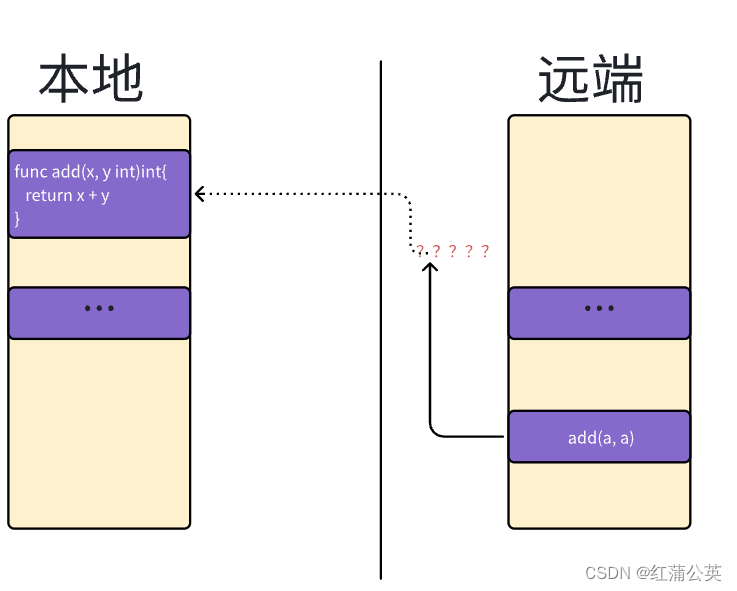
所以RPC就诞生了
RPC就是为了解决类似远程、跨内存空间、的函数或者方法调用的
RPC调用
为什么要用RPC ?
如果我们开发简单的单一应用,逻辑简单、用户不多、流量不大,那我们用不着。
当我们的系统访问量增大、业务增多时,我们会发现一台单机运行此系统已经无法承受。此时,我们可以将业务拆分成几个互不关联的应用,分别部署在各自机器上,以划清逻辑并减小压力。
此时,我们也可以不需要RPC,因为应用之间是互不关联的。
当我们的业务越来越多、应用也越来越多时,自然的,我们会发现有些功能已经不能简单划分开来或者划分不出来。
此时,可以将公共业务逻辑抽离出来,将之组成独立的服务Service应用 。而原有的、新增的应用都可以与那些独立的Service应用 交互,以此来完成完整的业务功能。
所以此时,我们急需一种高效的应用程序之间的通讯手段来完成这种需求.
描述的场景也是服务化 、微服务和分布式系统架构的基础场景。
要实现RPC就需要解决以下三个问题:
-
如何确定要执行的函数?
- 在本地调用中,函数主体通过函数指针函数指定,然后调用 add 函数,编译器通过
函数指针函数自动确定add 函数在内存中的位置。 - 在
RPC中,调用不能通过函数指针完成,因为它们的内存地址可能完全不同。因此,调用方和被调用方都需要维护一个{ function <-> ID }映射表,以确保调用正确的函数
- 在本地调用中,函数主体通过函数指针函数指定,然后调用 add 函数,编译器通过
-
如何表达参数?
- 本地过程调用中传递的参数是
通过堆栈内存结构实现的,但RPC不能直接使用内存传递参数,因此参数或返回值需要在传输期间序列化并转换成字节流,反之亦然。
- 本地过程调用中传递的参数是
-
如何进行网络传输?
- 函数的调用方和被调用方通常是通过网络连接的,也就是说,
function ID和序列化字节流需要通过网络传输,因此,只要能够完成传输,调用方和被调用方就不受某个网络协议的限制。. - 例如,一些
RPC框架使用TCP协议,一些使用HTTP
- 函数的调用方和被调用方通常是通过网络连接的,也就是说,
以往实现跨服务调用的时候,我们会采用RESTful API的方式,被调用方会对外提供一个HTTP接口,调用方按要求发起HTTP请求并接收API接口返回的响应数据。
server服务
// server/main.go
package main
import (
"encoding/json"
"io/ioutil"
"log"
"net/http"
)
type addParam struct {
X int `json:"x"`
Y int `json:"y"`
}
type addResult struct {
Code int `json:"code"`
Data int `json:"data"`
}
func add(x, y int) int {
return x + y
}
func addHandler(w http.ResponseWriter, r *http.Request) {
// 解析参数
b, _ := ioutil.ReadAll(r.Body)
var param addParam
json.Unmarshal(b, ¶m)
// 业务逻辑
ret := add(param.X, param.Y)
// 返回响应
respBytes , _ := json.Marshal(addResult{Code: 0, Data: ret})
w.Write(respBytes)
}
func main() {
http.HandleFunc("/add", addHandler)
log.Fatal(http.ListenAndServe(":9090", nil))
}
客户端来请求上述HTTP服务
// client/main.go
package main
import (
"bytes"
"encoding/json"
"fmt"
"io/ioutil"
"net/http"
)
type addParam struct {
X int `json:"x"`
Y int `json:"y"`
}
type addResult struct {
Code int `json:"code"`
Data int `json:"data"`
}
func main() {
// 通过HTTP请求调用其他服务器上的add服务
url := "http://127.0.0.1:9090/add"
param := addParam{
X: 10,
Y: 20,
}
paramBytes, _ := json.Marshal(param)
resp, _ := http.Post(url, "application/json", bytes.NewReader(paramBytes))
defer resp.Body.Close()
respBytes, _ := ioutil.ReadAll(resp.Body)
var respData addResult
json.Unmarshal(respBytes, &respData)
fmt.Println(respData.Data) // 30
}
这中交互模式,应该是非常常见了。
这种模式是我们目前比较常见的跨服务或跨语言之间基于RESTful API的服务调用模式。
既然使用API调用也能实现类似远程调用的目的,为什么还要用RPC呢?
使用 RPC 的目的是让我们调用远程方法像调用本地方法一样无差别
并且基于RESTful API通常是基于HTTP协议,传输数据采用JSON等文本协议,相较于RPC 直接使用TCP协议,传输数据多采用二进制协议来说,RPC通常相比RESTful API性能会更好。(在我的rabbitMQ文章中有体现)
RESTful API多用于前后端之间的数据传输,而目前微服务架构下各个微服务之间多采用RPC调用
使用场景
- 服务化/微服务
- 分布式系统架构
- 服务可重用
- 系统间交互调用
总结一下:
内部子系统较多:- 众多的内部子系统是驱动采用RPC架构的原因之一,订单系统,支付系统,商品系统,用户系统…, 每个可独立单独布署。 RPC主要使用在大型企业内部子系统之间的调用。
- 基于HTTP协议的接口,包括Webservice等主要作为对外接口服务。
接口访问量巨大:- 要求满足支持 “负载均衡”,“熔断降级” 一类面向服务的高级特性
接口非常多:- 服务发现
RPC原理
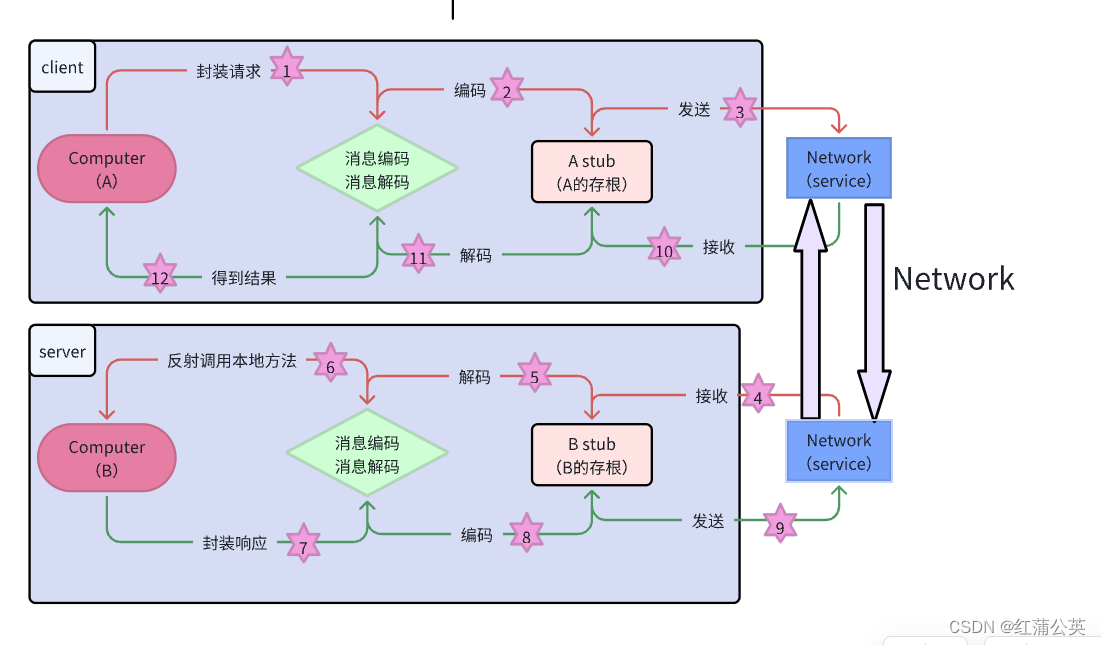
服务调用方(client)以本地调用方式调用服务client stub接收到调用后负责将方法、参数等组装成能够进行网络传输的消息体,client stub找到服务地址,并将消息发送到服务端server端接收到消息server stub收到消息后进行解码server stub根据解码结果调用本地的服务- 本地服务执行并将结果返回给
server stub server stub将返回结果打包成能够进行网络传输的消息体- 按地址将消息发送至调用方
client端接收到消息client stub收到消息并进行解码- 调用方得到最终结果
使用RPC框架的目标是只需要关心第1步和第12步,中间的其他步骤统统封装起来,让使用者无需关心。
例如社区中各式RPC框架(grpc、thrift等)就是为了让RPC调用更方便。
RPC的目标就是要2~8这些步骤都封装起来,让用户对这些细节透明。
如何做到透明化(封装)远程服务调用
怎么封装通信细节才能让用户像以本地调用方式调用远程服务呢?
这部分有点像我用java实现的MQ一样。
就是定义一个结构体。
如果我们需要从A调用B的方法,那么意味着B需要A传来的参数和方法名等,然后通过反射来解析。
所以我们就可以这么做。
能看到这里的人相信对如何设置数据结构已经了熟与心了,所以就不写代码了。(用web实现数据结构的肯定没少做这个事)
如果还是不知道。可以看我的这篇文章,并找到创建请求和响应协议参数这一节,当然看完也可。
对消息进行编码和解码
客户端的请求消息结构一般需要包括以下内容:
接口名称:在我们的例子里接口名是“HelloWorldService”,如果不传,服务端就不知道调用哪个接口了;方法名:一个接口内可能有很多方法,如果不传方法名服务端也就不知道调用哪个方法;参数类型和参数值:参数类型有很多,比如有 bool、int、long、double、string、map、list,甚至如struct等,以及相应的参数值;超时时间 + requestID(标识唯一请求id)
服务端返回的消息结构一般包括以下内容:
状态code返回值requestID
一旦确定了消息的数据结构后,下一步就是要考虑序列化与反序列化了。
序列化
什么是序列化?
- 序列化就是将数据结构或对象转换成二进制串的过程,也就是编码的过程。
什么是反序列化?
- 将在序列化过程中所生成的二进制串转换成数据结构或者对象的过程。
为什么需要序列化?
- 转换为二进制串后才好进行网络传输(快)
为什么需要反序列化?
- 将二进制转换为对象才好进行后续处理(方便)
现如今序列化的方案越来越多,每种序列化方案都有优点和缺点,它们在设计之初有自己独特的应用场景,那到底选择哪种呢?
从RPC的角度上看,主要看三点:
通用性:比如是否能支持Map等复杂的数据结构;性能:包括时间复杂度和空间复杂度,由于RPC框架将会被公司几乎所有服务使用,如果序列化上能节约一点时间,对整个公司的收益都将非常可观,同理如果序列化上能节约一点内存,网络带宽也能省下不少可扩展性:对互联网公司而言,业务变化飞快,如果序列化协议具有良好的可扩展性,支持自动增加新的业务字段,而不影响老的服务,这将大大提供系统的灵活度。
目前互联网公司广泛使用Protobuf、Thrift、Avro等成熟的序列化解决方案来搭建RPC框架,这些都是久经考验的解决方案。
这里就不介绍了。
如果想要知道如何创建,搭建一个框架的,个人建议可以去这里,极客兔兔的文章。
下一章介绍如何使用go中的RPC的包