介绍
文本分析,是将全文本转换为一系列单词的过程,也叫分词。analysis是通过analyzer(分词器)来实现的,可以使用Elasticearch内置的分词器,也可以自己去定制一些分词器。除了在数据写入时将词条进行转换,那么在查询的时候也需要使用相同的分析器对语句进行分析。
| 分词器名称 | 处理过程 |
| Standard Analyzer | 默认的分词器,按词切分,小写处理 |
| Simple Analyzer | 按照非字母切分(符号被过滤),小写处理 |
| Stop Analyzer | 小写处理,停用词过滤(the, a, this) |
| Whitespace Analyzer | 按照空格切分,不转小写 |
| Keyword Analyzer | 不分词,直接将输入当做输出 |
| Pattern Analyzer | 正则表达式,默认是\W+(非字符串分隔) |
实战
1、空格分词器展示
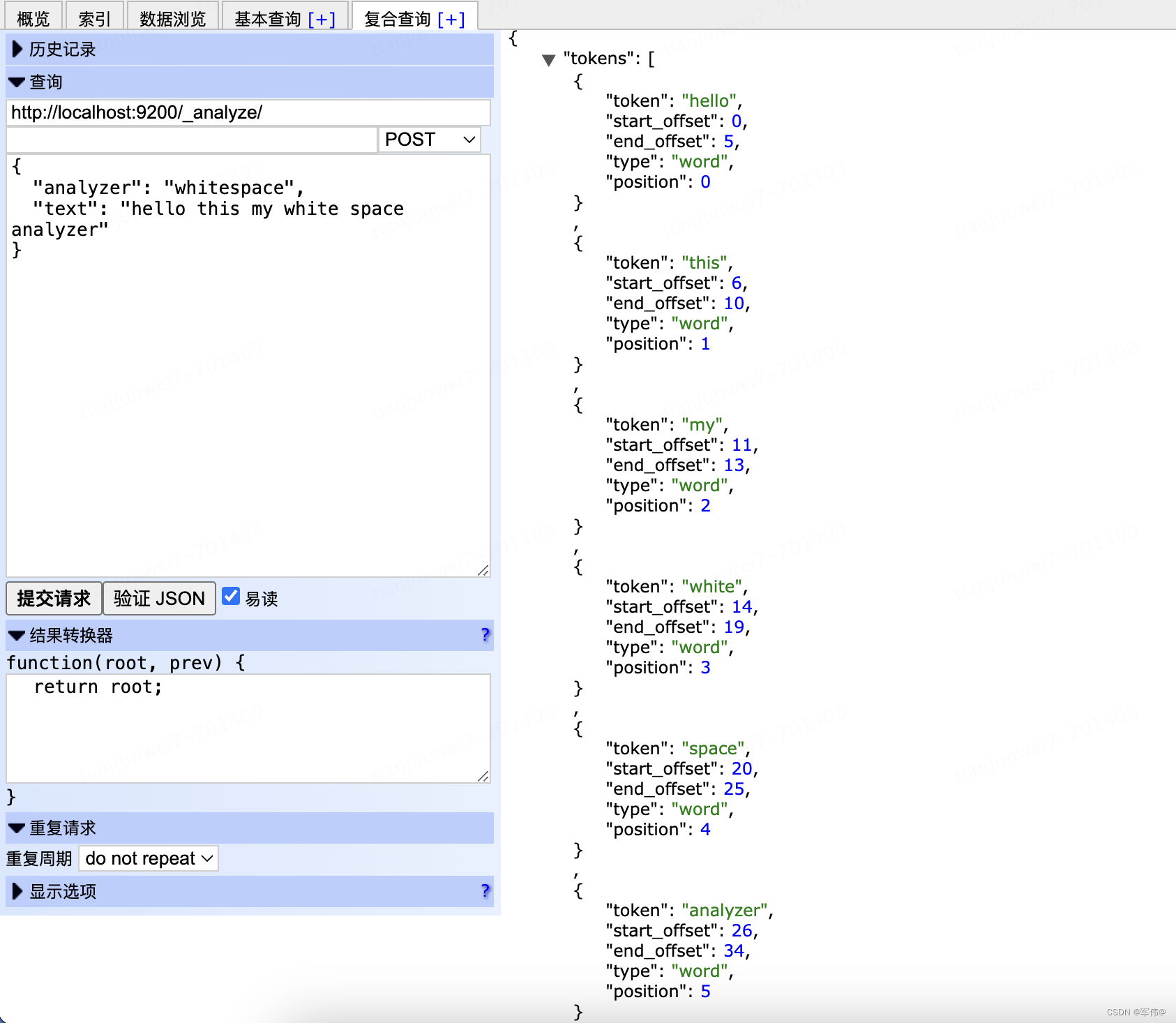
POST:http://localhost:9200/_analyze/
{
"analyzer": "whitespace",
"text": "hello this my white space analyzer"
}结果:按照空格进行分词处理
{
"tokens":[
{
"token":"hello",
"start_offset":0,
"end_offset":5,
"type":"word",
"position":0
},
{
"token":"this",
"start_offset":6,
"end_offset":10,
"type":"word",
"position":1
},
{
"token":"my",
"start_offset":11,
"end_offset":13,
"type":"word",
"position":2
},
{
"token":"white",
"start_offset":14,
"end_offset":19,
"type":"word",
"position":3
},
{
"token":"space",
"start_offset":20,
"end_offset":25,
"type":"word",
"position":4
},
{
"token":"analyzer",
"start_offset":26,
"end_offset":34,
"type":"word",
"position":5
}
]
}
2、空格分词器创建与查询
目前我们有一些应用场景需要根据空格分词之后的内容进行精准查询,这样空格分词器就满足我们的需求了。
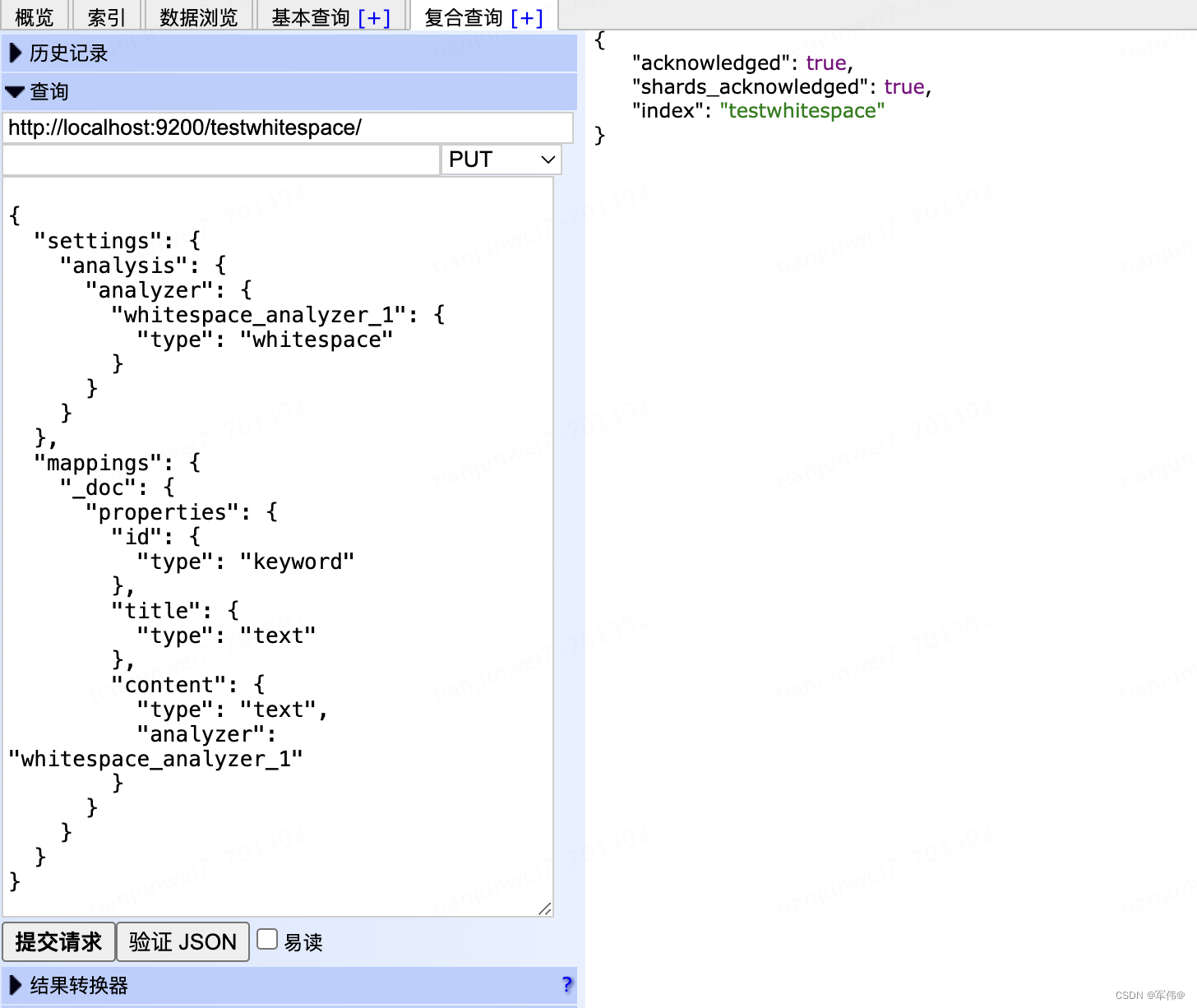
(1)创建索引,针对想要分词的字段指定空格分词器
whitespace_analyzer_1:指定为whitespace
content:指定为空格分词器
{
"settings": {
"analysis": {
"analyzer": {
"whitespace_analyzer_1": {
"type": "whitespace"
}
}
}
},
"mappings": {
"_doc": {
"properties": {
"id": {
"type": "keyword"
},
"title": {
"type": "text"
},
"content": {
"type": "text",
"analyzer": "whitespace_analyzer_1"
}
}
}
}
}
(2)索引查询
保存一条数据:
{
"id": "002",
"title": "科目2",
"content": "this is whitespace"
}根据分词查询:
{
"query": {
"match": {
"desc": "this"
}
}
}
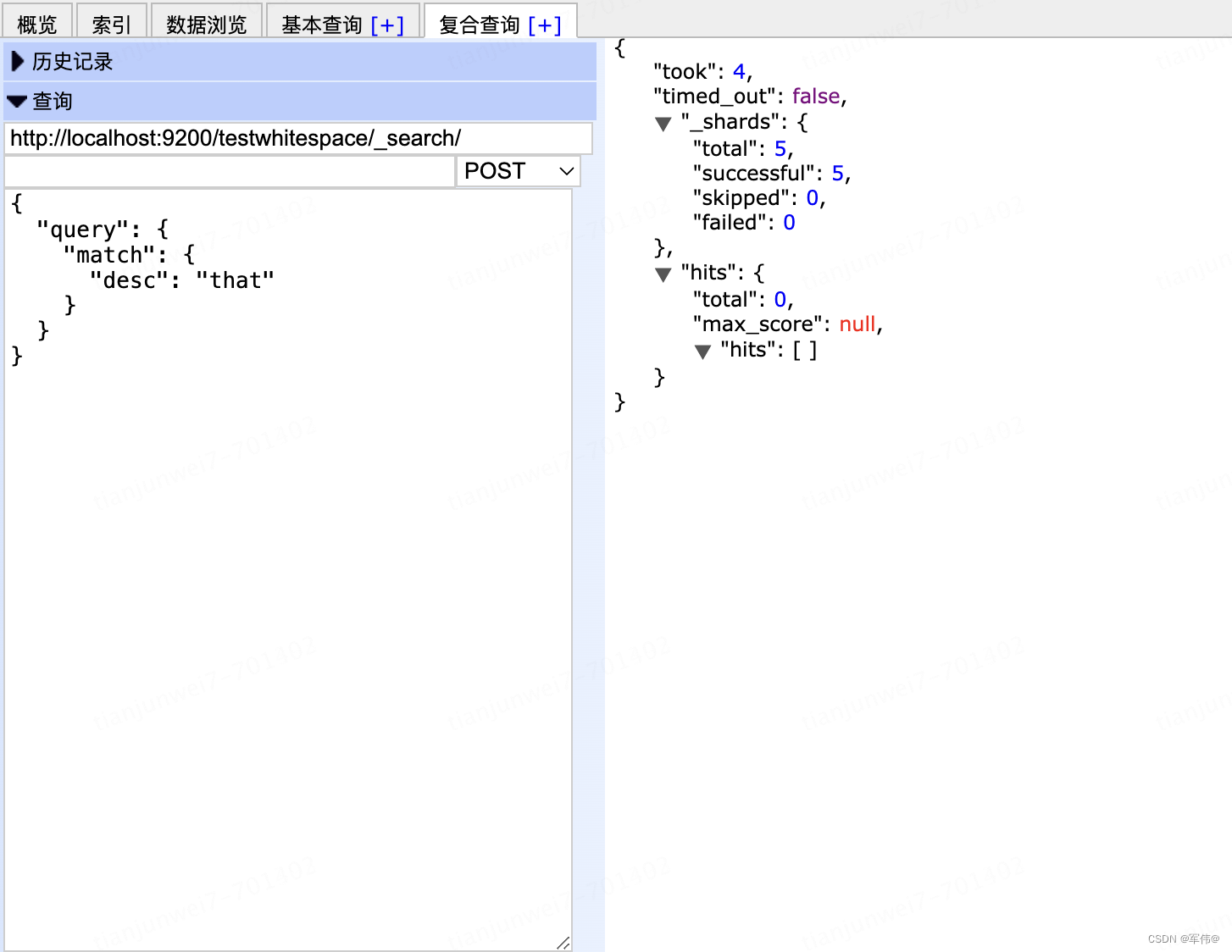
根据不存在的分词查询则查询不到
{
"query": {
"match": {
"desc": "that"
}
}
}