一、数组
数组是一个容器,可以存入相同类型的多个数据元素。
-
数组局限性:
长度固定:(添加–扩容, 删除-缩容)
类型是一致的
对象数组 :
int[] arr = new int[5];
…
Student[] arr = new Student[5];
Student[] arr = new Student[3];
Student stu = new Student("张三",18);
Student stu2 = new Student("李四",28);
Student stu3= new Student("王老吉",38);
arr[0] = stu;
arr[1] = stu2;
arr[2] = stu3;
System.out.println(arr[0].name);
//Object类型的数组,可以存放任意引用类型, 如果是基本类型,会自动装箱
Object[] obj = new Object[5];
obj[0] = new Student("赵四",18);
obj[1] = new Teacher("杨老师",18);
obj[2] = "abc";
obj[3] = 111;
obj[4] = true;

二、集合
-
集合:集合是java中提供的一种容器,可以用来存储多个数据。
-
特点: 长度不固定,还可以存储不同的数据(但是一般都用同一类型)
集合和数组既然都是容器,它们有啥区别呢?
-
数组的长度是固定的。集合的长度是可变的。
-
数组中存储的是同一类型的元素,可以存储基本数据类型值。集合存储的都是对象。而且对象的类型可以不一致。在开发中一般当对象多的时候,使用集合进行存储。
1.集合的体系

2.Collection 常用的方法
2.1基本功能
public boolean add(E e): 把给定的对象添加到当前集合中 。public void clear():清空集合中所有的元素。public boolean remove(E e): 把给定的对象在当前集合中删除。public boolean contains(E e): 判断当前集合中是否包含给定的对象。public boolean isEmpty(): 判断当前集合是否为空。public int size(): 返回集合中元素的个数。public Object[] toArray(): 把集合中的元素,存储到数组中。
2.2高级功能
- boolean addAll(Collection<? extends E> c) 添加一个集合到当前集合
- boolean removeAll(Collection<?> c) 移除一个集合元素
- boolean retainAll(Collection<?> c) 两个集合都有的元素,思考元素去哪里?boolean又是什么意思?
- boolean containsAll(Collection<?> c) 判断当前集合是否包含指定集合的元素 一个还是所有?
2.3集合的遍历
public static void main(String[] args) {
Collection c = new ArrayList();
c.add("hello");
c.add("java");
c.add("collection");
//遍历集合
Object[] arr = c.toArray();
//String -> Object
for(int i=0;i<arr.length;i++){
String s = (String)arr[i];
System.out.println(s);
}
}
3.Iterator 迭代器
3.1迭代器的介绍
专门为集合提供遍历的一种技术
3.2迭代器的怎么使用
Collection c = new ArrayList();
Student student = new Student("张三",18);
Student student2 = new Student("李四",28);
Student student3 = new Student("王老吉",38);
c.add(student);
c.add(student2);
c.add(student3);
Iterator iterator = c.iterator();
while (iterator.hasNext()){
Student s = (Student) iterator.next();
System.out.println(s);
}
3.3迭代器的原理

三、数据结构
-
数据结构的有什么用?
数据结构:研究数据的存储
当你用着java里面的容器类很爽的时候,你有没有想过,怎么ArrayList就像一个无限扩充的数组,也好像链表之类的。好用吗?好用,这就是数据结构的用处,只不过你在不知不觉中使用了。
现实世界的存储,我们使用的工具和建模。每种数据结构有自己的优点和缺点,想想如果Google的数据用的是数组的存储,我们还能方便地查询到所需要的数据吗?而算法,在这么多的数据中如何做到最快的插入,查找,删除,也是在追求更快。
我们java是面向对象的语言,就好似自动档轿车,C语言好似手动档吉普。数据结构呢?是变速箱的工作原理。你完全可以不知道变速箱怎样工作,就把自动档的车子从 A点 开到 B点,而且未必就比懂得的人慢。写程序这件事,和开车一样,经验可以起到很大作用,但如果你不知道底层是怎么工作的,就永远只能开车,既不会修车,也不能造车。当然了,数据结构内容比较多,细细的学起来也是相对费功夫的,不可能达到一蹴而就。我们将常见的数据结构:堆栈、队列、数组、链表和红黑树 这几种给大家介绍一下,作为数据结构的入门,了解一下它们的特点即可。
1.常见的数据结构
数据存储的常用结构有:栈、队列、数组、链表和红黑树。我们分别来了解一下:
2.栈,队列

3.数组与链表
-
数组: 利于查询 ,不利于增删改
-
链表:不利于查询 ,利于增删改
(根据需求,选择对应的数据形式,进行存储)

四、List 接口的方法
-
void add(int index, E element)
-
Object get(int index)
-
ListIterator listIterator()
返回列表中的列表迭代器(按适当的顺序)。 -
Object set(int index, E element)
用指定的元素(可选操作)替换此列表中指定位置的元素。 -
ListIterator listIterator() : 此方法重要;不但可以正向还可以反向,还可以进行添加和修改
在迭代器在迭代元素时,用集合去操作,出现以下的异常:
ConcurrentModificationException 并发修改异常
- 解决方法
迭代器在进行迭代元素时,就用迭代器去修改(包括添加)
集合遍历元素时,就用集合去修改
1.List 子类特点
ArrayList类
底层数组 : 查询快,增删改慢
线程不安全: 不安全,效率高
Vecktor类
底层数组 : 查询快,增删改慢
线程安全: 安全,效率低
LinkedList类
底层链表 : 查询慢,增删改快
线程不安全: 不安全,效率高
以上子类的选择,根据项目的需要来做 (看情况)
2.AarryList的方法使用
四种遍历
ArrayList list = new ArrayList();
list.add("hello");
list.add("world");
list.add("java");
//数组
Object[] arr = list.toArray();
for(int i=0; i<arr.length;i++){
String s = (String)arr[i];
System.out.println(arr[i]);
}
//迭代器
Iterator iterator = list.iterator();
while (iterator.hasNext()){
System.out.println(iterator.next());
}
//列表迭代器
ListIterator listIterator = list.listIterator();
while (listIterator.hasNext()){
System.out.println(listIterator.next());
}
//size get()
for(int i=0; i<list.size();i++){
String s = (String)list.get(i);
System.out.println(arr[i]);
}
3.Vector类特有方法
-
addElement(E obj)
将指定的组件添加到此向量的末尾,将其大小增加1。 -
elementAt(int index)
返回指定索引处的组件。 -
elements()
返回此向量的组件的枚举。 -
firstElement()
返回此向量的第一个组件(索引号为 0的项目)。
JDK升级原因:
1. 效率
2. 简化书写
3. 安全
/*
* Vector类特有的方法
* addElement(E obj) 将指定的组件添加到此向量的末尾,将其大小增加1。 add()
elementAt(int index)返回指定索引处的组件。 get()
elements() 返回此向量的组件的枚举。 iterator
hasMoreElements() hasNext()
nextElement() next()
firstElement() 返回此向量的第一个组件(索引号为 0的项目)。
* */
Vector vector = new Vector();
vector.addElement("hello");
vector.addElement("world");
vector.addElement("java");
// for(int i=0;i<vector.size();i++){
// System.out.println(vector.elementAt(i));
// }
// System.out.println(vector.firstElement());
Enumeration enumeration = vector.elements();
while (enumeration.hasMoreElements()){
System.out.println(enumeration.nextElement());
}
4.LinkedList类特有的方法
-
addFirst(E e)
在该列表开头插入指定的元素。 -
addLast(E e)
将指定的元素追加到此列表的末尾。
五、泛型
-
泛型: 是一种把类型明确的工作推迟到创建对象或者调用方法的时候,才去明确的特殊类型, 参数化类型,把类型当做参数一样进行传递
-
格式:
<数据类型>
此处数据类型只能是引用类型 -
好处:
- 把运行时报的错误,提前到了编译期间
- 避免了强制转换
- 优化程序的设计,解决了黄色警告线
泛型的应用:
1.类上定义泛型
public class ObjectTool<T> {
private T obj;
public T getObj() {
return obj;
}
public void setObj(T obj) {
this.obj = obj;
}
}
2.方法上定义泛型
在方法中定义泛型,相当于可以传任意类型的参数
public <T> void show(T t){
System.out.println(t);
}
3.接口上定义泛型
- 方法1
class MyListImpl implements MyList<String>{
@Override
public void show(String s) {
}
}
- 方法2
class MyListImpl<T> implements MyList<T>{
@Override
public void show(T s) {
}
}
4.泛型通配符
<?> : 任意类型
<? extends E> : 向下限定 , E及子类
<? supter E > : 向上限定 , E及父类
六、增加for遍历集合
- 语法:
for(数据类型 变量名: 数组名或集合){
}//集合遍历 ,推荐使用增加for
1.静态导入
注意事项:
- 方法必须是静态
- 注意不要和本类的方法同名,如果同名,记得加前缀,由此可见,静态导入的方式,意义不太
import static java.lang.Math.abs;
import static java.lang.Math.max;
public static void main(String[] args) {
System.out.println(abs(-100));
System.out.println(java.lang.Math.max(100,200));
}
2.可变参数
-
可变参数:
定义时方法时不知道参数具体个数,可以使用此技术
-
格式:
修饰符 返回值 类型 方法名(数据类型... 参数名){
}
// ... 表示是可变参数
注意事项
- 可以了可变参数,此变量相当于是一个数组
- 如果方法里有多个参数,其它包含可变参数,那可变参数必须放在最后

3.数组转集合
Arrays.asList 此方法可以将数组转集合,但是本质还是数组,所以不能操作集合改变数组大小的方法
List<String> list = Arrays.asList("hello","world","java");
System.out.println(list);
System.out.println(list.get(0));
//UnsupportedOperationException
//list.add("java ee");
list.set(1,"hahaha");
for(String str:list){
System.out.println(str);
}
七、Set 接口

特点: 不包含重复的元素,无序(指的是存数据 ,和取数据的顺序是否一致)
1.HashSet子类
无序,唯一性
2.HashSet 如何实现唯一性(看源码)
HashSet 的底层是使用的HashMap
根据源码分析,得到要保证HashSet里的元素的唯一性,涉及到了Hash值 和equals方法
interface Collection{
....
}
interface Set extends Collection{
...
}
class HashSet implements Set{
// Collection 就相当于单身, Map 一对夫妻
private transient HashMap<E,Object> map;
public HashSet() {
map = new HashMap<>();
}
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
}
class HashMap implements Map{
final float loadFactor;
static final float DEFAULT_LOAD_FACTOR = 0.75f;
public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted
}
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
}
自定义对象,使用HashSet; 如果想实现当所有属性相同时,认为是重复,不添加;
需要重写hashcode 和 equals
3.去重原理
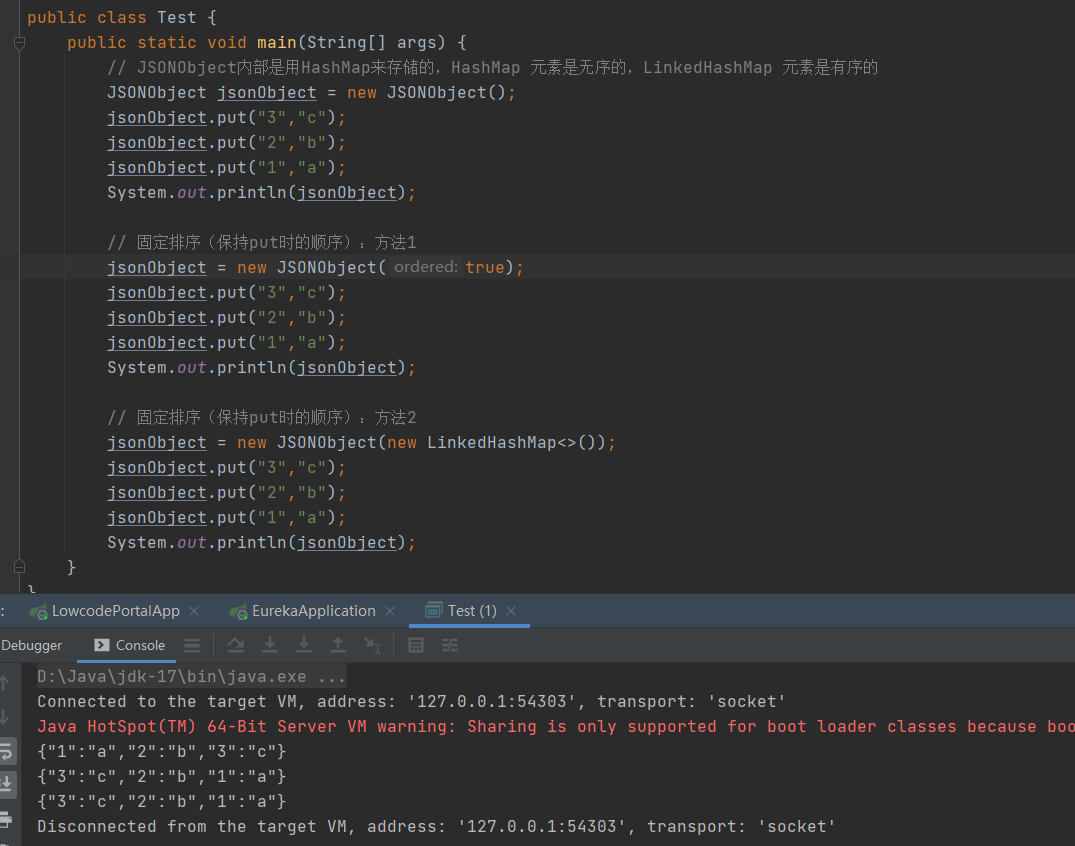
HashSet 的底层是HashMap, hashMap的底层是哈希表(数组和链表的结合)

什么是哈希表呢?
在JDK1.8之前,哈希表底层采用数组+链表实现,即使用链表处理冲突,同一hash值的链表都存储在一个链表里。但是当位于一个桶中的元素较多,即hash值相等的元素较多时,通过key值依次查找的效率较低。而JDK1.8中,哈希表存储采用数组+链表+红黑树实现,当链表长度超过阈值(8)时,将链表转换为红黑树,这样大大减少了查找时间。
简单的来说,哈希表是由数组+链表+红黑树(JDK1.8增加了红黑树部分)实现的,如下图所示。
看到这张图就有人要问了,这个是怎么存储的呢?
为了方便大家的理解我们结合一个存储流程图来说明一下:
总而言之,JDK1.8引入红黑树大程度优化了HashMap的性能,那么对于我们来讲保证HashSet集合元素的唯一,其实就是根据对象的hashCode和equals方法来决定的。如果我们往集合中存放自定义的对象,那么保证其唯一,就必须复写hashCode和equals方法建立属于当前对象的比较方式。
4.LinkedHashSet 子类
底层数据结构:哈希表+链表
保证了唯一性,链表保存有序(存储和取出是一致)

LinkedHashSet<String> hs = new LinkedHashSet<String>();
hs.add("hello");
hs.add("world");
hs.add("java");
hs.add("hello");
for(String str :hs){
System.out.println(str);
}
5.TreeSet 子类
-
特点:排序 和唯一
-
排序 : 自然排序(就是升序)和比较器排序
public static void main(String[] args) {
TreeSet<Integer> treeSet = new TreeSet<Integer>();
treeSet.add(66);
treeSet.add(18);
treeSet.add(12);
treeSet.add(66);
treeSet.add(77);
for(Integer integer: treeSet){
System.out.println(integer);
}
}
八、Map体系

1.概述
现实生活中,我们常会看到这样的一种集合:IP地址与主机名,身份证号与个人,系统用户名与系统用户对象等,这种一一对应的关系,就叫做映射。Java提供了专门的集合类用来存放这种对象关系的对象,即java.util.Map接口。
我们通过查看Map接口描述,发现Map接口下的集合与Collection接口下的集合,它们存储数据的形式不同,如下图。
Collection中的集合,元素是孤立存在的(理解为单身),向集合中存储元素采用一个个元素的方式存储。Map中的集合,元素是成对存在的(理解为夫妻)。每个元素由键与值两部分组成,通过键可以找对所对应的值。Collection中的集合称为单列集合,Map中的集合称为双列集合。- 需要注意的是,
Map中的集合不能包含重复的键,值可以重复;每个键只能对应一个值。
2.Map接口中的常用方法
public V put(K key, V value): 把指定的键与指定的值添加到Map集合中。public V remove(Object key): 把指定的键 所对应的键值对元素 在Map集合中删除,返回被删除元素的值。public V get(Object key)根据指定的键,在Map集合中获取对应的值。boolean containsKey(Object key)判断集合中是否包含指定的键。public Set<K> keySet(): 获取Map集合中所有的键,存储到Set集合中。public Set<Map.Entry<K,V>> entrySet(): 获取到Map集合中所有的键值对对象的集合(Set集合)。
九、面试题
第一题:List a=new ArrayList() 和 ArrayList a =new ArrayList()的区别?
List list = new ArrayList();
//这句创建了一个 ArrayList 的对象后把上溯到了 List。此时它是一个List对象了,有些ArrayList 有但是 List 没有的属性和方法,它就不能再用了。
ArrayList list=new ArrayList();
// 创建一对象则保留了ArrayList 的所有属性。所以需要用到 ArrayList 独有的方法的时候不能用前者。实例代码如下:
List list = new ArrayList();
ArrayList arrayList = new ArrayList();
list.trimToSize(); //错误,没有该方法。
arrayList.trimToSize(); //ArrayList里有该方法。
第二题:说一下ArrayList的扩容机制
(1)带初始容量参数的构造函数,用户可以自己定义容量
(2)默认构造函数,使用初始容量10构造一个空列表(无参数构造)
(3)构造包含指定collection元素的列表,这些元素利用该集合的迭代器按顺序返回
首先获取数组的旧容量,然后计算新容量的值,计算使用位运算,将其扩容至原来的1.5倍。
得到新容量的值后,校验扩容后的容量是否大于需要的容量,如果小于,则把最小需要容量当作扩容后的新容量。并确保扩容后的容量不超过数组能设置的最大大小值。
最后将老数组的数据复制到新的数组中。
第三题:Vector和ArrayList以及LinkedList区别和联系,以及分别的应用场景?
Vector的底层的实现其实是一个数组,是线程安全的实现类,方法都有synchronized
LinkedList的底层其实是一个双向链表,每一个对象都是一个Node节点,Node就是一个静态内部类,它是**线程不安全的,**所有的方法都没有加锁或者进行同步
这里先简单介绍一下,下面会对ArrayList的扩容机制进行分析
ArrayList是线程不安全的,如果不指定它的初始容量,那么它的初始容量是0,当第一次进行添加操作的时候它的容量将扩容为10
三种集合的使用场景
- Vector很少用,有其他线程安全的List集合
- 如果需要大量的添加和删除则可以选择LinkedList 原因是:它查询的时候需要遍历整个链表,插入和删除的时候无需移动节点
- 如果需要大量的查询和修改则可以选择ArrayList 原因:底层为数组,删除和插入需要移动其他元素,查询的时候根据下标来查
第四题:我们想要使用线程安全的List集合,你有什么办法?
1:可以使用Vector
2.自己重写类似于ArrayList的但是线程安全的集合
3.可以使用**Collections(工具类)**中的方法,将ArrayList变成一个线程安全的集合
4.可以使用java.util.concurrent包下的CopyOnWriteArrayList,它是线程安全的
第五题:那你说说CopyOnWriteArrayList是怎么实现线程安全的?
它是juc包下的,专门用于并发编程的,他的设计思想是:读写分离,最终一致,写时复制
它不能指定容量,初始容量是0.它底层也是一个数组,集合有多大,底层数组就有多大,不会有多余的空间
CopyOnWriteArrayList的缺点
底层是数组,删除插入的效率不高,写的时候需要复制,占用内存,浪费空间,如果集合足够大的时候容易触发GC
数据一致性问题。CopyOnWrite容器只能保证数据的最终一致性,不能保证数据的实时一致性。所以如果你希望写入的的数据,马上能读到,请不要使用CopyOnWrite容器。【当执行add或remove操作没完成时,get获取的仍然是旧数组的元素】。CopyOnWriteArrayList读取时不加锁只是写入和删除时加锁
应用场景:读操作远大于写操作的时候
CopyOnWriteArrayList和Collections.synchronizedList区别
CopyOnWriteArrayList和Collections.synchronizedList是实现线程安全的列表的两种方式。两种实现方式分别针对不同情况有不同的性能表现,其中CopyOnWriteArrayList的写操作性能较差,而多线程的读操作性能较好。而Collections.synchronizedList的写操作性能比CopyOnWriteArrayList在多线程操作的情况下要好很多,而读操作因为是采用了synchronized关键字的方式,其读操作性能并不如CopyOnWriteArrayList。因此在不同的应用场景下,应该选择不同的多线程安全实现类。










![[山东大学操作系统课程设计]实验2](https://img-blog.csdnimg.cn/direct/05b044f5940d4060b7484667c19856f5.png)
