1.介绍
ElasticSearch是基于Lucene的开源搜索及分析引擎,使用Java语言开发的搜索引擎库类,并作为Apache许可条款下的开放源码发布,是当前流行的企业级搜索引擎。 它可以被下面这样准确的形容:
- 一个分布式的实时文档存储,每个字段可以被索引与搜索。
- 一个分布式实时分析搜索引擎。
- 能胜任上百个服务节点的扩展,并支持 PB 级别的结构化或者非结构化数据。
1.1.主要功能及应用场景
除了搜索,结合Kibana、Logstash、Beats开源产品,Elastic Stack(简称ELK)还被广泛运用在大数据近实时分析领域
主要功能:
1)海量数据的分布式存储以及集群管理,达到了服务与数据的高可用以及水平扩展;
2)近实时搜索,性能卓越。可以对结构化、全文、地理位置等类型数据的处理;
3)海量数据的近实时分析(聚合功能)
应用场景:
1)网站搜索、垂直搜索、代码搜索;
2)日志管理与分析、安全指标监控、应用性能监控、Web抓取舆情分析。
1.2.ELK生态认知
如下是从官方博客中找到图,这张图展示了ELK生态以及基于ELK的场景(最上方)

1.3.基础概念
- Near Realtime(NRT) 近实时。数据提交索引后,立马就可以搜索到。
- Cluster 集群,一个集群由一个唯一的名字标识,默认为“elasticsearch”。集群名称非常重要,具有相同集群名的节点才会组成一个集群。集群名称可以在配置文件中指定。
- Node 节点:存储集群的数据,参与集群的索引和搜索功能。像集群有名字,节点也有自己的名称,默认在启动时会以一个随机的UUID的前七个字符作为节点的名字,你可以为其指定任意的名字。通过集群名在网络中发现同伴组成集群。一个节点也可是集群。
- Index 索引: 一个索引是一个文档的集合(等同于solr中的集合)。每个索引有唯一的名字,通过这个名字来操作它。一个集群中可以有任意多个索引。
- Type 类型:指在一个索引中,可以索引不同类型的文档,如用户数据、博客数据。从6.0.0 版本起已废弃,一个索引中只存放一类数据。
- Document 文档:被索引的一条数据,索引的基本信息单元,以JSON格式来表示。
- Shard 分片:在创建一个索引时可以指定分成多少个分片来存储。每个分片本身也是一个功能完善且独立的“索引”,可以被放置在集群的任意节点上。
- Replication 备份: 一个分片可以有多个备份(副本)
为了方便理解,作一个ES和数据库的对比
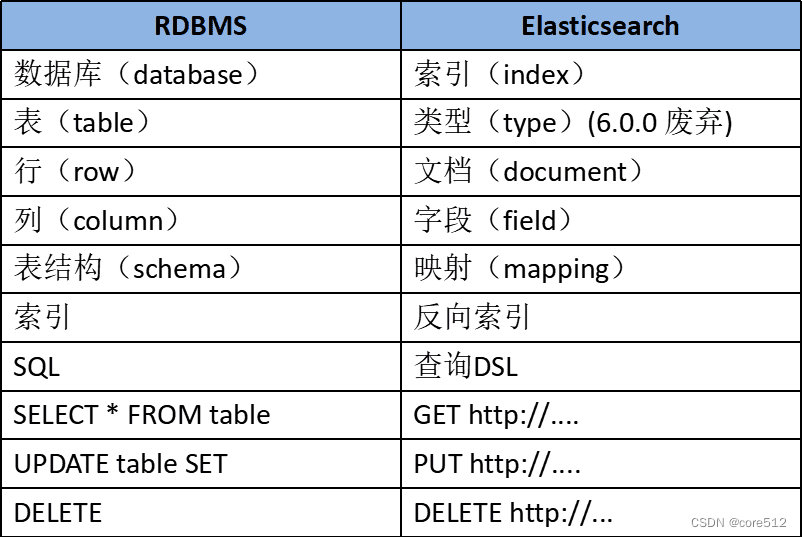
2.安装
2.1.官网
官方网站:https://www.elastic.co/cn/
官方2.x中文教程中安装教程:https://www.elastic.co/guide/cn/elasticsearch/guide/current/running-elasticsearch.html
官方ElasticSearch下载地址:https://www.elastic.co/cn/downloads/elasticsearch
官方Kibana下载地址:https://www.elastic.co/cn/downloads/kibana
2.2.安装
安装Java:安装 Elasticsearch 之前,你需要先安装一个较新的版本的 Java,最好的选择是,你可以从 www.java.com在新窗口打开 获得官方提供的最新版本的 Java。安装以后,确认是否安装成功:

下载ElasticSearch
解压

增加elasticSearch用户:必须创建一个非root用户来运行ElasticSearch(ElasticSearch5及以上版本,基于安全考虑,强制规定不能以root身份运行。)如果你使用root用户来启动ElasticSearch,则会有如下错误信息:

所以我们增加一个独立的elasticsearch用户来运行
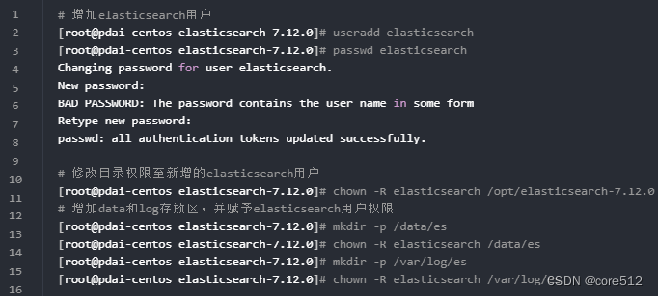
进入elasticsearch.yml文件修改上述的data和log路径

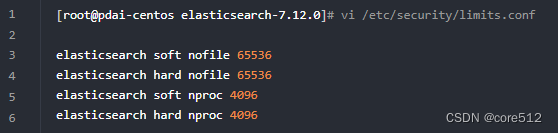
修改Linux系统的限制配置
(1)修改系统中允许应用最多创建多少文件等的限制权限。Linux默认来说,一般限制应用最多创建的文件是65535个。但是ES至少需要65536的文件创建权限。
(2)修改系统中允许用户启动的进程开启多少个线程。默认的Linux限制root用户开启的进程可以开启任意数量的线程,其他用户开启的进程可以开启1024个线程。必须修改限制数为4096+。因为ES至少需要4096的线程池预备。ES在5.x版本之后,强制要求在linux中不能使用root用户启动ES进程。所以必须使用其他用户启动ES进程才可以。
(3)Linux低版本内核为线程分配的内存是128K。4.x版本的内核分配的内存更大。如果虚拟机的内存是1G,最多只能开启3000+个线程数。至少为虚拟机分配1.5G以上的内存。
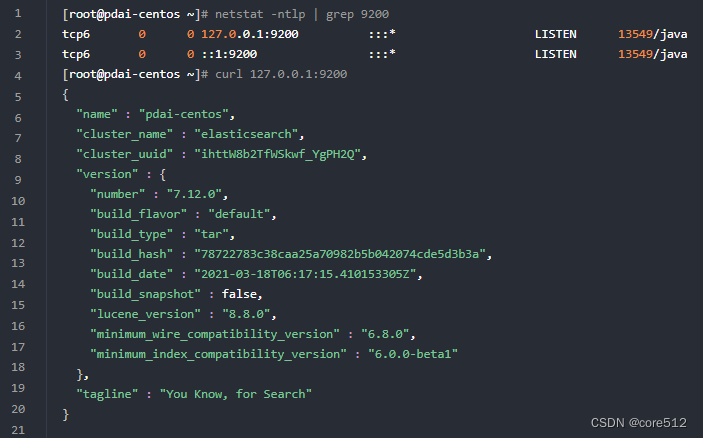
启动ElasticSearch

查看安装是否成功
安装kibana
下载Kibana
Kibana是界面化的查询数据的工具,下载时尽量下载与ElasicSearch一致的版本。
解压
使用elasticsearch用户权限

启动
配置密码
(1)停止kibana和elasticsearch服务
(2)将xpack.security.enabled设置添加到ES_PATH_CONF/elasticsearch.yml文件并将值设置为true
(3)启动elasticsearch (./bin/elasticsearch -d)
(4)执行如下密码设置器,./bin/elasticsearch-setup-passwords interactive来设置各个组件的密码
(5)将elasticsearch.username设置添加到KIB_PATH_CONF/kibana.yml 文件并将值设置给elastic用户: elasticsearch.username: “elastic”
(6)创建kibana keystore, ./bin/kibana-keystore create
(7)在kibana keystore 中添加密码 ./bin/kibana-keystore add elasticsearch.password
(8)重启kibana 服务即可 nohup ./bin/kibana &
3.查询和聚合的使用
3.1.DSL查询之复合查询
3.1.1 bool query(布尔查询)
Bool查询语法有以下特点:
子查询可以任意顺序出现
可以嵌套多个查询,包括bool查询
如果bool查询中没有must条件,should中必须至少满足一条才会返回结果。
bool查询包含四种操作符,分别是must,should,must_not,filter。他们均是一种数组,数组里面是对应的判断条件。
must: 必须匹配。贡献算分
must_not:过滤子句,必须不能匹配,但不贡献算分
should: 选择性匹配,至少满足一条。贡献算分
filter: 过滤子句,必须匹配,但不贡献算分
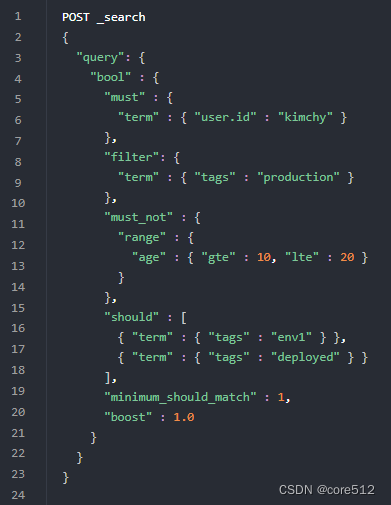
3.1.2 function_score(函数查询)
script_score
如果需要预定义函数之外的功能,可以根据需要通过脚本进行实现
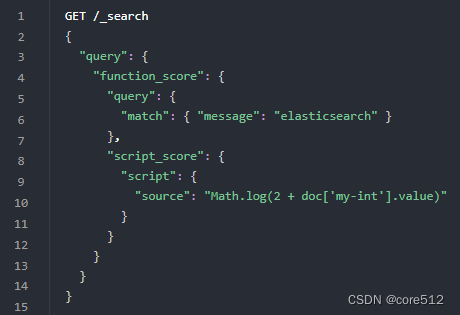
3.2.DSL查询之全文搜索
3.2.1.match多个词深入
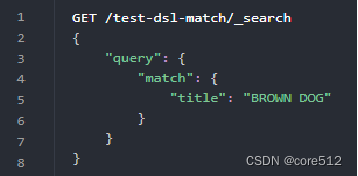
它在内部实际上先执行两次 term 查询,然后将两次查询的结果合并作为最终结果输出。和如下语句查询结果是等同的
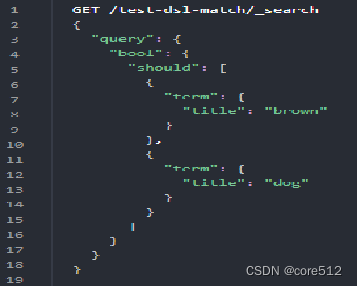
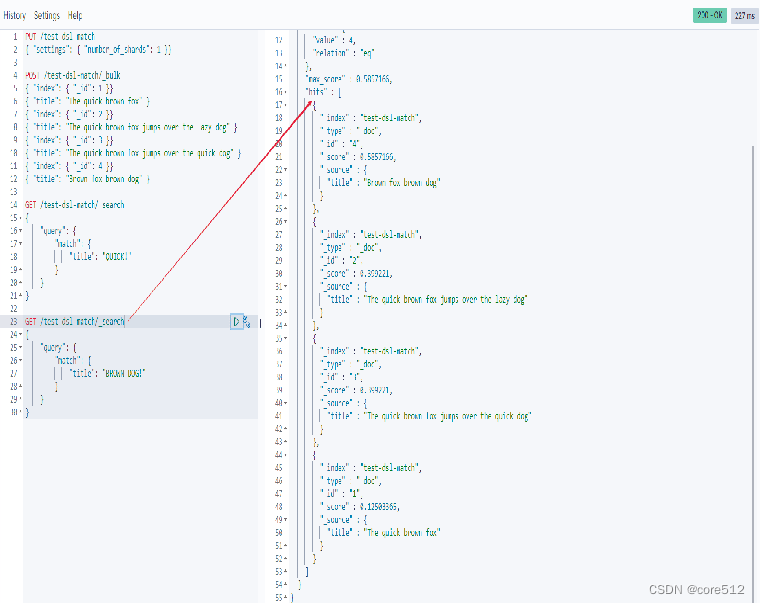
3.2.2.match的匹配精度
如果用户给定 3 个查询词,想查找至少包含其中 2 个的文档,该如何处理?将 operator 操作符参数设置成 and 或者 or 都是不合适的。
match 查询支持 minimum_should_match 最小匹配参数,这让我们可以指定必须匹配的词项数用来表示一个文档是否相关。 我们可以将其设置为某个具体数字,更常用的做法是将其设置为一个百分数,因为我们无法控制用户搜索时输入的单词数量

当给定百分比的时候, minimum_should_match 会做合适的事情:在之前三词项的示例中, 75% 会自动被截断成 66.6% ,即三个里面两个词。无论这个值设置成什么,至少包含一个词项的文档才会被认为是匹配的。
3.3.DSL查询之term
查询分基于文本查询和基于词项的查询,term主要讲基于词项的查询
字段是否存在:exist:文档字段的索引值可能不存在,exist表示查找是否存在字段
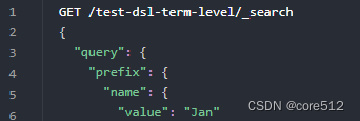
前缀:prefix:通过前缀查找某个字段
多个分词匹配:terms:按照多个分词term匹配,它们是or的关系
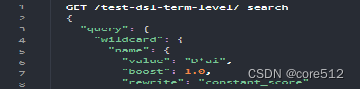
通配符:wildcard:通配符匹配,比如*
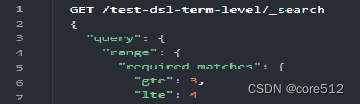
范围:range:常常被用在数字或者日期范围的查询
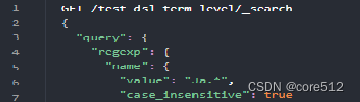
正则:regexp:通过正则表达式查询

3.4.聚合查询之Bucket
ElasticSearch中桶在概念上类似于 SQL 的分组(GROUP BY)
标准的聚合:聚合操作被置于顶层参数 aggs 之下(完整形式 aggregations 同样有效)
动态脚本的聚合:ElasticSearch还支持一些基于脚本(生成运行时的字段)的复杂的动态聚合
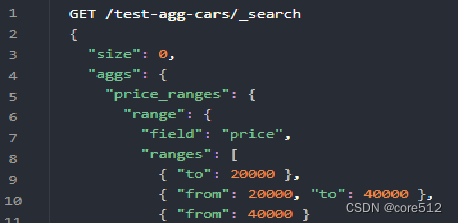
对number类型聚合:Range:基于Range的聚合,使用户能够定义一组范围-每个范围代表一个桶。
对IP类型聚合:IP Range:专用于IP值的范围聚合
对日期类型聚合:Date Range:专用于日期值的范围聚合

3.5.聚合查询之Metric
指标(Metrics) 对桶内的文档进行统计计算,类似于 COUNT() 、 SUM() 、 MAX() 等统计方法
单值分析:
标准stat类型
avg 平均值
max 最大值
min 最小值
sum 和
value_count 数量
其它类型
weighted_avg 带权重的avg
cardinality 基数(distinct去重)
median_absolute_deviation 中位值
非单值分析:
stats型
stats 包含avg,max,min,sum和count
matrix_stats 针对矩阵模型
string_stats 针对字符串
百分数型
percentiles 百分数范
percentile_ranks 百分数排行
地理位置型
geo_bounds Geo bounds
geo_centroid Geo-centroid
geo_line Geo-Line
Top型
top_hits 分桶后的top hits
top_metrics
3.6.聚合查询之Pipline
管道聚合(Pipeline Aggregation)简单而言就是让上一步的聚合结果成为下一个聚合的输入
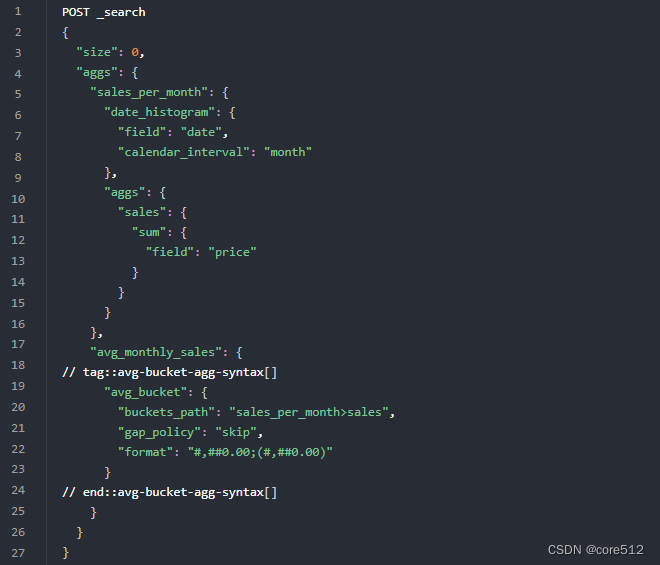
嵌套的bucket聚合:聚合出按月价格的直方图
Metic聚合:对上面的聚合再求平均值
字段含义:
buckets_path:指定聚合的名称,支持多级嵌套聚合。
gap_policy 当管道聚合遇到不存在的值,有点类似于term等聚合的(missing)时所采取的策略,可选择值为:skip、insert_zeros。
skip:此选项将丢失的数据视为bucket不存在。它将跳过桶并使用下一个可用值继续计算。
format 用于格式化聚合桶的输出(key)。
以上内容主要用于构筑知识体系,用的时候查询下即可
4.性能优化
4.1.硬件配置优化
CPU 配置:大多数 Elasticsearch 部署往往对 CPU 要求不高。因此,相对其它资源,具体配置多少个(CPU)不是那么关键。常见的集群使用4 到 8 个核的机器。
内存配置:如果有一种资源是最先被耗尽的,它可能是内存。排序和聚合都很耗内存,所以有足够的堆空间来应付它们是很重要的。64 GB 内存的机器是非常理想的,但是 32 GB 和 16 GB 机器也是很常见的。少于8 GB 会适得其反(你最终需要很多很多的小机器),大于 64 GB 的机器也会有问题。
内存分配:当机器内存小于 64G 时,遵循通用的原则,50% 给 ES,50% 留给 lucene。
禁止 swap:禁止 swap,一旦允许内存与磁盘的交换,会引起致命的性能问题。可以通过在 elasticsearch.yml 中 bootstrap.memory_lock: true,以保持 JVM 锁定内存,保证 ES 的性能。
磁盘:硬盘对所有的集群都很重要,对大量写入的集群更是加倍重要(例如那些存储日志数据的)。硬盘是服务器上最慢的子系统,这意味着那些写入量很大的集群很容易让硬盘饱和,使得它成为集群的瓶颈。尽量使用固态硬盘(SSD)。
4.2.查询方面优化
带 routing 查询:查询的时候,可以直接根据 routing 信息定位到某个分配查询,不需要查询所有的分配,经过协调节点排序。routing 默认值是文档的 id,也可以采用自定义值,比如用户 ID。
Filter VS Query:Elasticsearch 针对 Filter 查询只需要回答「是」或者「否」,不需要像 Query 查询一样计算相关性分数,同时Filter结果可以缓存。
深度翻页:在使用 Elasticsearch 过程中,应尽量避免大翻页的出现。
正常翻页查询都是从 from 开始 size 条数据,这样就需要在每个分片中查询打分排名在前面的 from+size 条数据。如果 from 或者 size 很大的话,导致参加排序的数量会同步扩大很多,最终会导致 CPU 资源消耗增大。
可以结合实际业务特点,文档 id 大小如果和文档创建时间是一致有序的,可以以文档 id 作为分页的偏移量,并将其作为分页查询的一个条件。
Cache的设置及使用:QueryCache: ES查询的时候,使用filter查询会使用query cache, 如果业务场景中的过滤查询比较多,建议将querycache设置大一些,以提高查询速度。
FieldDataCache: 在聚类或排序时,field data cache会使用频繁,因此,设置字段数据缓存的大小,在聚类或排序场景较多的情形下很有必要。
4.3.集群架构设计
Elasticsearch 集群在架构拓朴时,采用主节点、数据节点和负载均衡节点分离的架构,在 5.x 版本以后,又可将数据节点再细分为“Hot-Warm”的架构模式。
Elasticsearch 的配置文件中有 2 个参数,node.master 和 node.data。这两个参数搭配使用时,能够帮助提供服务器性能。
主(master)节点:
配置 node.master:true 和 node.data:false,该 node 服务器只作为一个主节点,但不存储任何索引数据,专门负责处理集群的管理以及加强状态的整体稳定性。
因为这 3 个 master 节点不包含数据也不会实际参与搜索以及索引操作,所以master 节点的 CPU,内存以及磁盘配置可以比 data 节点少很多的。
数据(data)节点:
配置 node.master:false 和 node.data:true,该 node 服务器只作为一个数据节点,只用于存储索引数据,使该 node 服务器功能单一,只用于数据存储和数据查询,降低其资源消耗率。
hot 节点主要是索引节点(写节点),同时会保存近期的一些频繁被查询的索引。由于进行索引非常耗费 CPU 和 IO,即属于 IO 和 CPU 密集型操作,建议使用 SSD 的磁盘类型,保持良好的写性能。将节点设置为 hot 类型需要 elasticsearch.yml 如下配置:node.attr.box_type: hot。
warm节点是为了处理大量的,而且不经常访问的只读索引而设计的。由于这些索引是只读的,warm 节点倾向于挂载大量磁盘(普通磁盘)来替代 SSD。内存、CPU 的配置跟 hot 节点保持一致即可;节点数量一般也是大于等于 3 个。将节点设置为 warm 类型需要 elasticsearch.yml 如下配置:node.attr.box_type: warm。




![洛谷 [AGC032B] Balanced Neighbors](https://img-blog.csdnimg.cn/direct/08fbeb61c68a4662ad4c0915313f2716.png)