文章目录
- 一、一些奇怪的现象
- 二、用户级缓冲区
- 三、用户级缓冲区刷新问题
- 四、一些其他问题
- 1.缓冲区刷新的时机
- 2.为什么要有这个缓冲区
- 3.这个缓冲区在哪里?
- 4.这个FILE对象属于用户呢?还是操作系统呢?这个缓冲区,是不是用户级的缓冲区呢?
- 5.为什么前面的图④中C语言系列接口打印了两次?
一、一些奇怪的现象
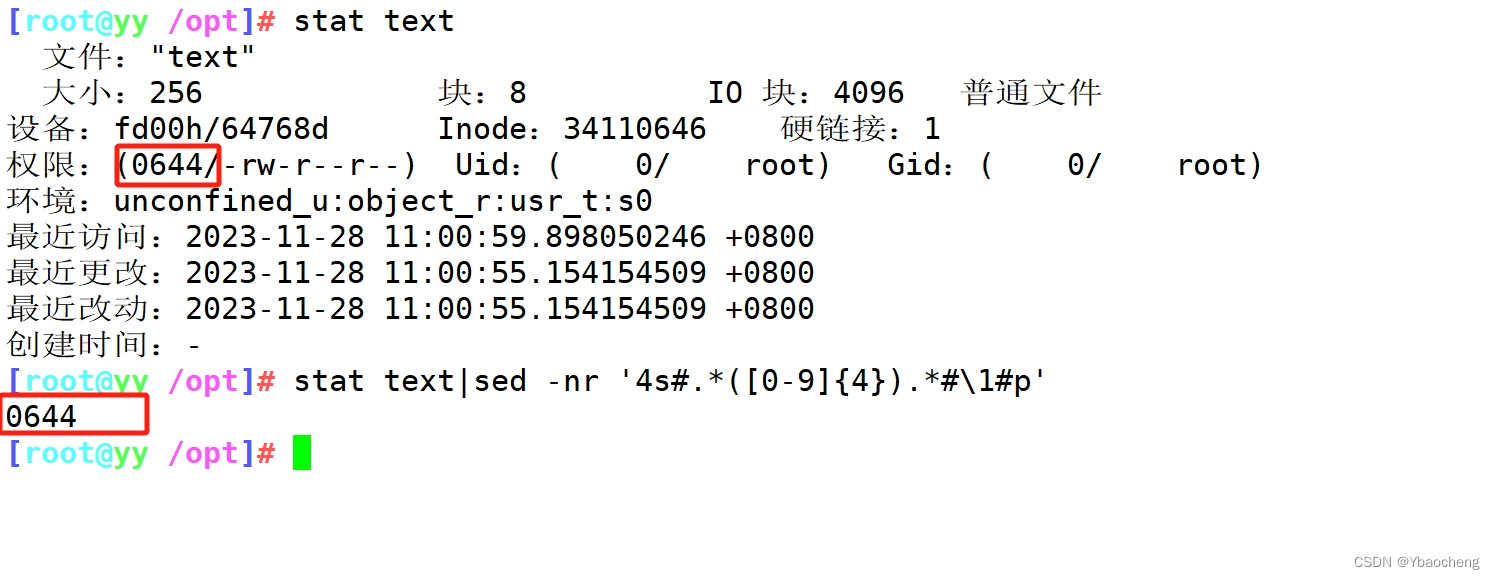
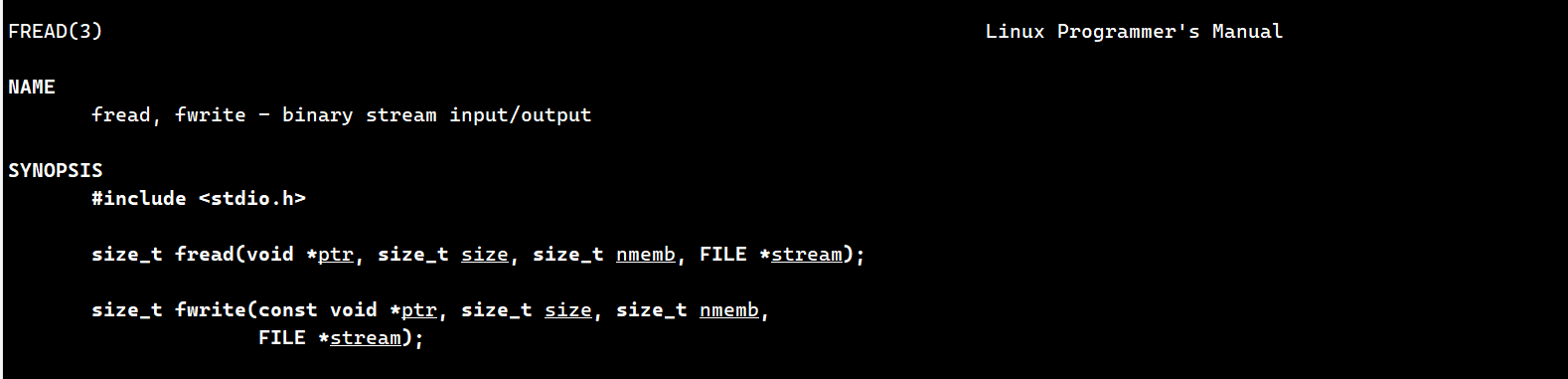
首先我们需要先注意这两个函数,即fwrite和fread函数
注意这两个函数中
fread中,表示从stream流中读取size个单位的nmemb大小的数据放入ptr处。注意这里的返回值返回的是成功读取的个数,即与size是类似的
fwrite中,表示向stream流中写入size个单位的nmem大小的数据从ptr中。注意这里的返回值返回的是成功写入的个数,与size是类似的
而下面这个函数中

它的意思是向fd文件描述符对应的文件中,写入buf位置的count个字节,这里的返回值返回的是写入成功字节的个数,与count是类似的
当我们的代码为如下的时候
#include <stdio.h>
#include <string.h>
#include <unistd.h>
int main()
{
const char* fstr = "hello fwrite\n";
const char* str = "hello write\n";
//C语言
printf("hello printf\n"); //stdout-->1
fprintf(stdout,"hello fprintf\n");//stdout-->1
fwrite(fstr,strlen(fstr),1,stdout);//stdout-->1
//操作系统提供的systemcall
write(1,str,strlen(str)); //1
return 0;
}
最终运行结果为,我们将这个运行结果称作为①

如果我们不变代码,而是在运行的时候加上重定向,那么最终运行结果为如下,我们将其称之为②

如果我们将代码改为如下,即在最后加上一个fork
#include <stdio.h>
#include <string.h>
#include <unistd.h>
int main()
{
const char* fstr = "hello fwrite\n";
const char* str = "hello write\n";
//C语言
printf("hello printf\n"); //stdout-->1
fprintf(stdout,"hello fprintf\n");//stdout-->1
fwrite(fstr,strlen(fstr),1,stdout);//stdout-->1
// close(1);
//操作系统提供的systemcall
write(1,str,strlen(str)); //1
fork();
return 0;
}
那么最终运行结果为如下,我们记作③

同样是这段代码,我们对其做一个重定向,我们记作④
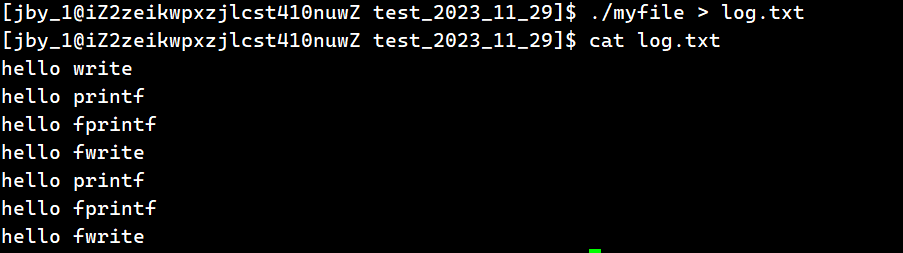
最终如下图所示
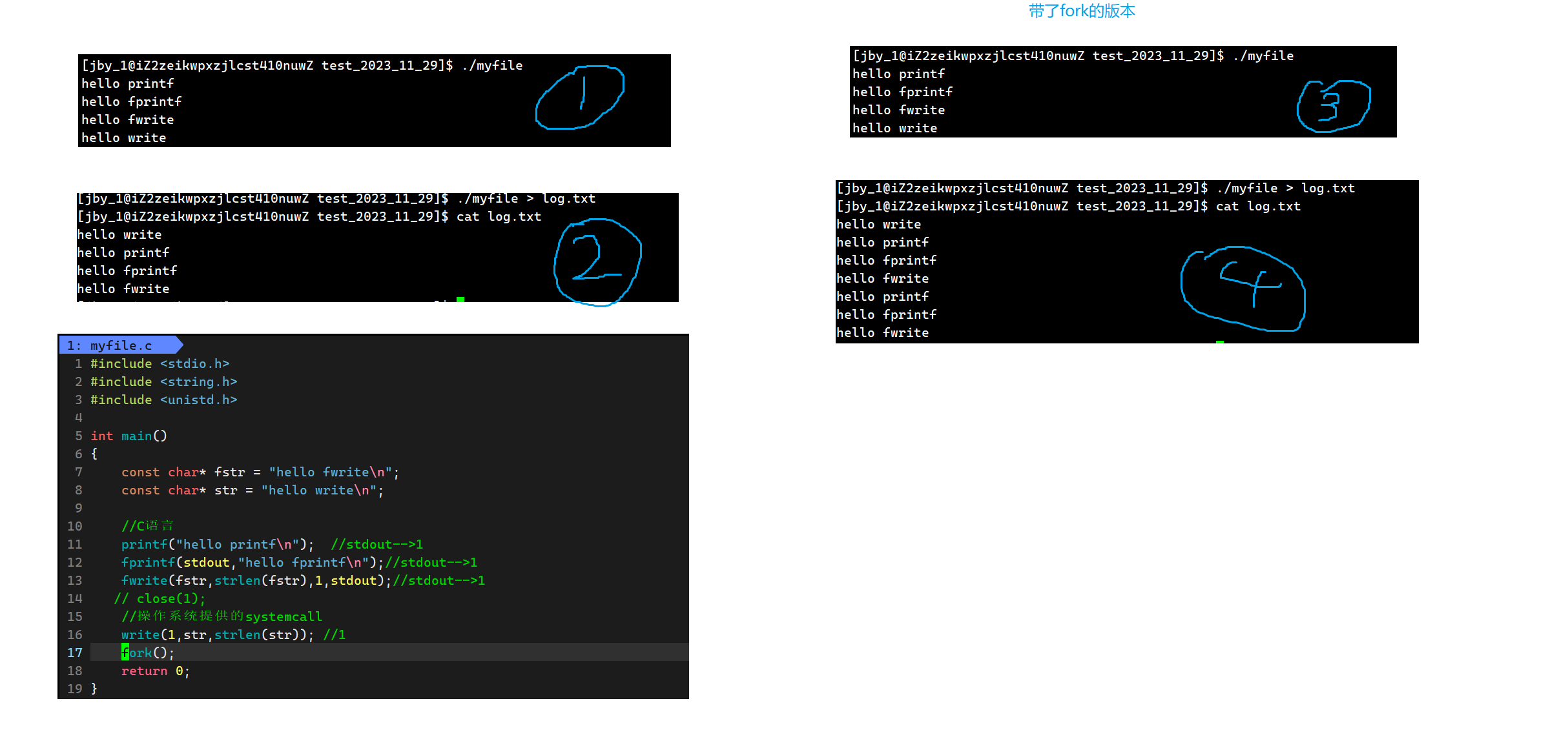
对于一二三而言,都是非常容易理解的,唯独二我们也许会好奇为什么系统调用接口会提前打印。
对于第四个,我们会发现,对于C语言的接口而言都打印了两遍,而对于系统调用的接口而言,是不受到这些影响的,依然只打印一次。虽然我们不知道为什么C语言的接口被打印了两遍,但是我们知道这个一定与fork有关
如果我们的代码是这样的
#include <stdio.h>
#include <string.h>
#include <unistd.h>
int main()
{
const char* fstr = "hello fwrite\n";
// const char* str = "hello write\n";
//C语言
printf("hello printf\n"); //stdout-->1
fprintf(stdout,"hello fprintf\n");//stdout-->1
fwrite(fstr,strlen(fstr),1,stdout);//stdout-->1
close(1);
//操作系统提供的systemcall
// write(1,str,strlen(str)); //1
// fork();
return 0;
}
那么运行结果为

如果我们的代码是这样的,将所有的\n都给去掉,
#include <stdio.h>
#include <string.h>
#include <unistd.h>
int main()
{
const char* fstr = "hello fwrite";
// const char* str = "hello write\n";
//C语言
printf("hello printf"); //stdout-->1
fprintf(stdout,"hello fprintf");//stdout-->1
fwrite(fstr,strlen(fstr),1,stdout);//stdout-->1
close(1);
//操作系统提供的systemcall
// write(1,str,strlen(str)); //1
// fork();
return 0;
}
运行结果为,什么内容也没有了,我们将下图记作⑤

如果我们紧接着将close给去掉了
#include <stdio.h>
#include <string.h>
#include <unistd.h>
int main()
{
const char* fstr = " hello fwrite";
// const char* str = "hello write\n";
//C语言
printf("hello printf"); //stdout-->1
fprintf(stdout,"hello fprintf");//stdout-->1
fwrite(fstr,strlen(fstr),1,stdout);//stdout-->1
//close(1);
//操作系统提供的systemcall
// write(1,str,strlen(str)); //1
// fork();
return 0;
}
运行结果为如下,我们可以看到已经有东西打印出来了

如果我们将代码改为下面的
#include <stdio.h>
#include <string.h>
#include <unistd.h>
int main()
{
//const char* fstr = " hello fwrite";
const char* str = "hello write";
//C语言
// printf("hello printf"); //stdout-->1
// fprintf(stdout,"hello fprintf");//stdout-->1
// fwrite(fstr,strlen(fstr),1,stdout);//stdout-->1
write(1,str,strlen(str)); //1
close(1);
//操作系统提供的systemcall
// fork();
return 0;
}
那么最终运行结果为如下,我们可以看到打印出来东西了,我们将下面的记作⑥

所以最终情况汇总如下
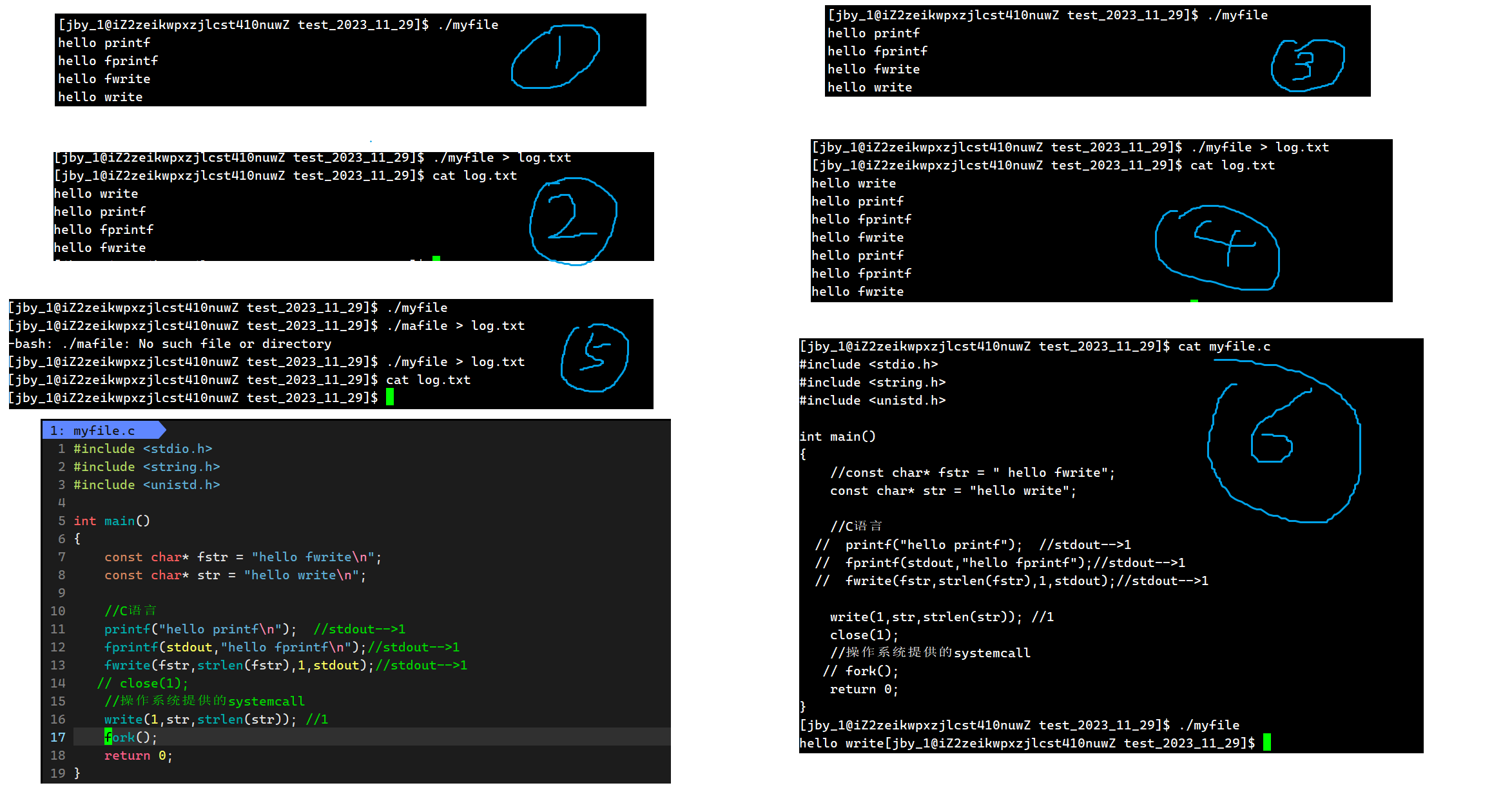
我们发现上面了很多的奇怪的现象了
二、用户级缓冲区
我们知道像printf/fprintf/fwrite/fputs/…这些C式的接口,他们最终的底层一定是调用write这个系统调用的,但是为什么他们之前出现了上面很多奇怪的现象呢?
而我们知道这些C式的接口一定会将数据写入缓冲区的
所以说这个缓冲区一定不在操作系统内部!!!不是系统级别的缓冲区!
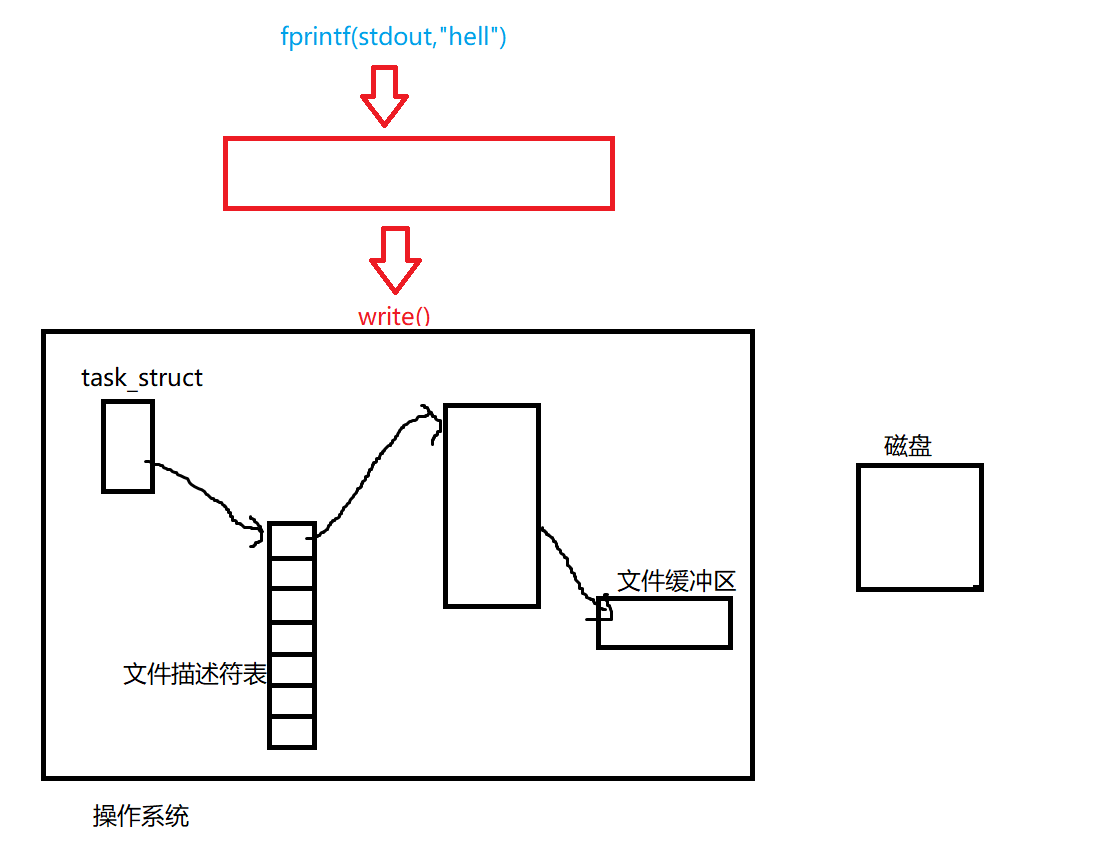
因为一旦,我们将这些数据写入到对应的操作系统中,如下图所示
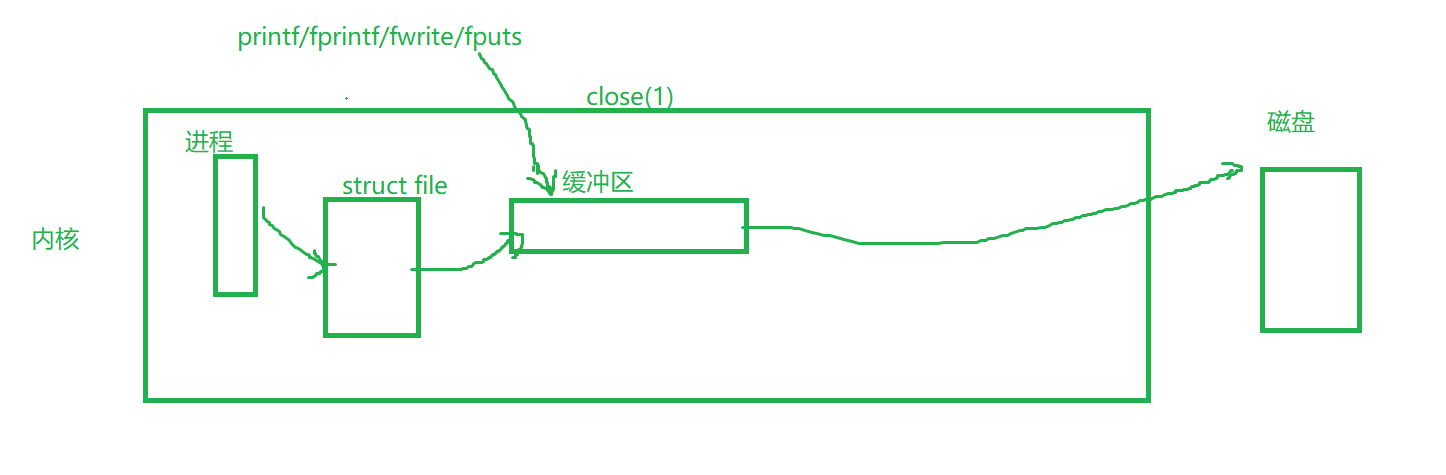
它在close的时候就一定可以找到对应的文件,比如我们关闭的是1号文件。然后将对应的数据刷新到磁盘中。直接就可以刷新了。它应该是可以看到结果的,可是根据我们的第⑤号运行结果中可以看出来,它是没有看到的,所以一定是不在操作系统内部的。
而第六图中,write可以看到,是因为它直接写到了系统级别的缓冲区,当close的时候,就会刷新系统级别的缓冲区。
所以说,我们所说的缓冲区都是语言层的。
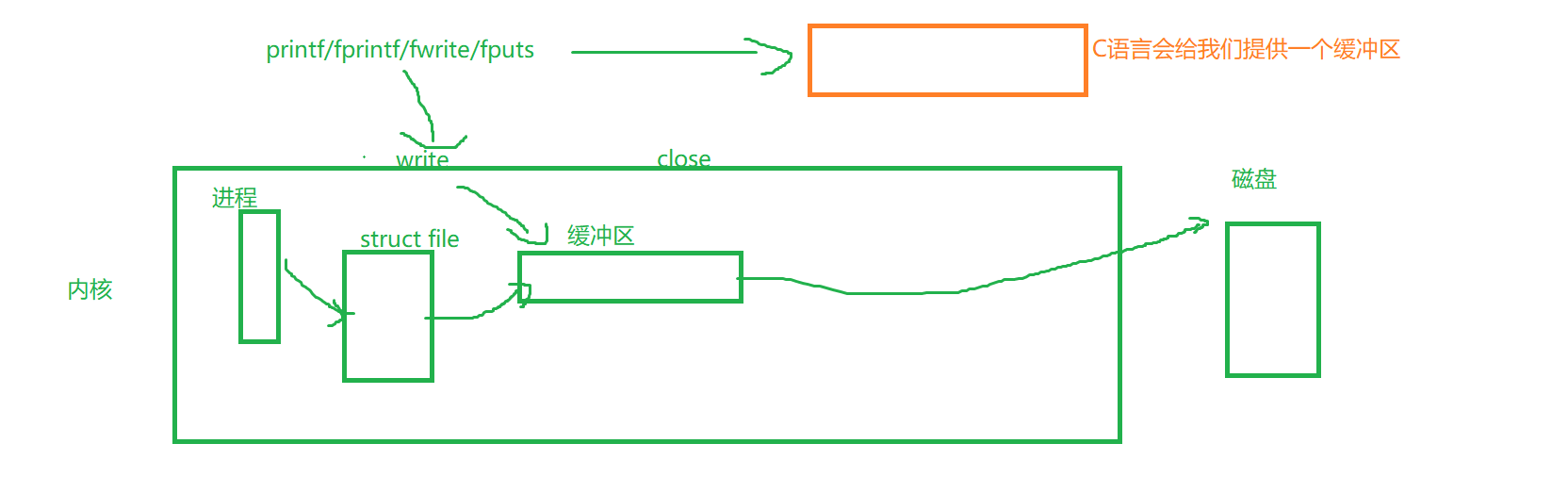
所以说,我们的数据写入的时候,都会先写入到这个C语言层面的缓冲区,随后在通过write写入到系统级别的缓冲区
如下所示才是正确的缓冲区流向
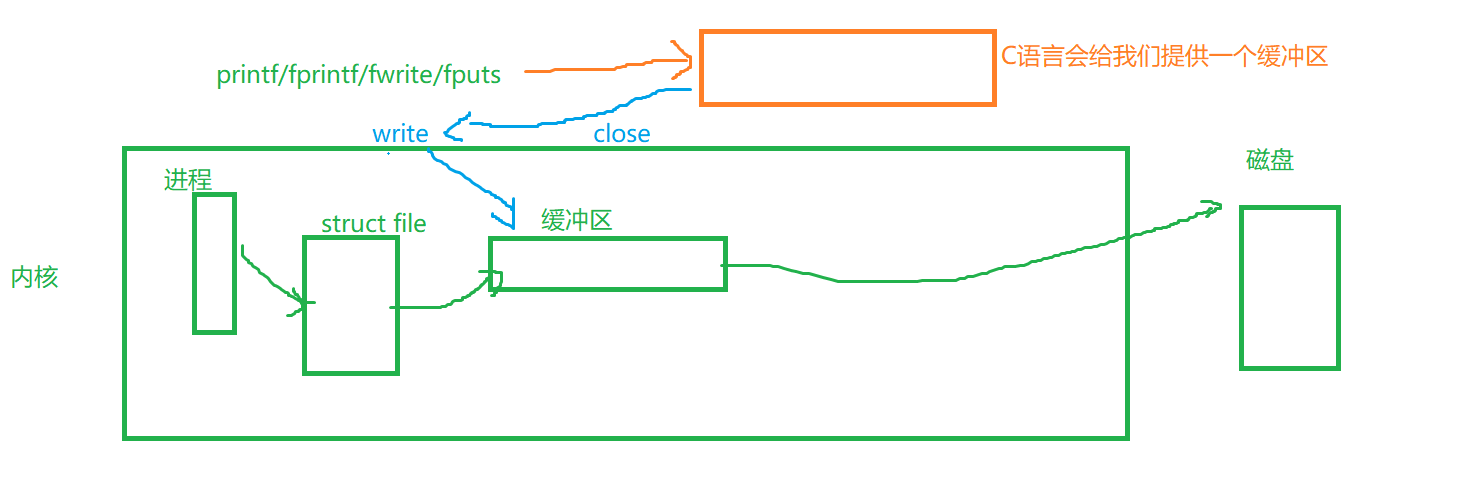
所以这样就解释了前面的五和六两张图的情况
就是因为printf/fprintf这些函数会去使用C提供的一个语言层面的缓冲区,然数据都写到这里来了,而我们最后直接close的时候只能刷新内核级别的缓冲区,所以最终什么结果也没有。而前面的write些往内核里面去写入的,所以最终close的时候会刷新里面的缓冲区,从而使得数据打印出来
所以最终就解释了下面的这个现象
#include <stdio.h>
#include <string.h>
#include <unistd.h>
int main()
{
const char* fstr = " hello fwrite";
const char* str = "hello write";
//C语言
printf("hello printf"); //stdout-->1
fprintf(stdout,"hello fprintf");//stdout-->1
fwrite(fstr,strlen(fstr),1,stdout);//stdout-->1
write(1,str,strlen(str)); //1
close(1);
//操作系统提供的systemcall
// fork();
return 0;
}
最终运行结果为

就是因为,前面的三个接口都是写入到了C语言层面上的缓冲区了,并没有写入到内核级别的缓冲区,而write是会写入到内核级别的缓冲区的,而close只会刷新内核级别的缓冲区,而关闭以后,原先在C语言级别缓冲区的数据由于1号文件被关闭了,而我们在程序结束的时候确实是会刷新C语言级别的缓冲区,不过在刷新这个缓冲区的时候,wirte要利用1号文件写入到内核中。可是此时1号文件已经被关闭了,所以无法写入。
而我们知道显示器的文件的刷新方案是行刷新,所以在printf执行完,就会立即遇到\n,将数据进行刷新
所以刷新的本质就是将数据通过1+write写入到内核中
而上面的C语言层面的缓冲区就是用户级缓冲区
我们还记得之前的_exit和exit其实是有区别的
exit是c语言的接口,它能看到这个用户级别缓冲区,可以对其进行刷新(fflush(stdout)),然后调用_exit进程退出
而_exit是一个系统调用,看不到这个用户级缓冲区,它就直接关闭了程序了。
目前我们可以认为,只要将数据刷新到了内核,数据就可以到硬件了
所以说,上层所谓的fflush等等,都是通过调用write将数据写入到缓冲区中。
三、用户级缓冲区刷新问题
- 无缓冲:直接刷新
- 行缓冲:不刷新,直到遇到\n才刷新-------比如显示器
- 全缓冲:缓冲区满了,才刷新-----------比如文件写入到普通文件的时候
所以fprintf/fwrite这些接口最后写入到的都是C缓冲区,然后根据一定的刷新策略调用write接口,最后写到操作系统中
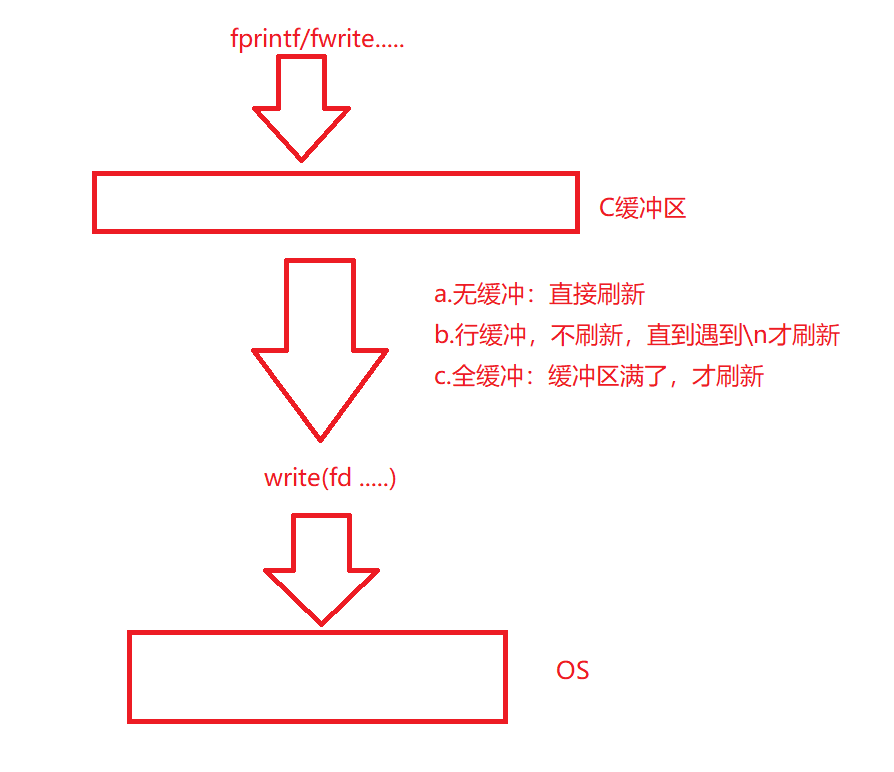
有了上面的理解,我们就可以直到,像fflush接口中,里面绝对使用了write函数

因为只有write才可以将数据写入到操作系统内核中。
四、一些其他问题
1.缓冲区刷新的时机
在行缓冲的时候,就比如像显示器写入的时候策略就是行缓冲
对于全缓冲,就比如往普通文件写入时候就是全缓冲
还有一种缓冲区刷新的时机是进程退出的时候
虽然我们没有刷新但是,此时是进程退出,会自动刷新C语言缓冲区

但是要注意,如果我们在退出之前,关闭了1号文件,那么就无法完成刷新了。因为write接口无法写入到1号文件了
2.为什么要有这个缓冲区
- 解决效率问题-----用户的效率问题(我们只需要将数据移交给缓冲区即可,至于如何放到操作系统里面,不需要我们去自己完成,由缓冲区去完成。类似于我们将包裹交给快递公司。但是最后快递公司一般不会只有一件包裹就去递送,而是有了很多件包裹以后,或者今天要关门了,会去统一的配送,这就类似于缓冲区的刷新)
- 配合格式化(我们之前的printf函数中,我们打印的时候需要先将数据给格式化再写入缓冲区中,比如printf(“hello %d”,123)这行代码中,我们写入到缓冲区的时候已经变为了"hello 123")
这个缓冲区,我们一般把他叫做文件流,在C++中也是叫做文件流。
因为我们之前的fprintf/fwrite这些接口会将数据源源不断的写入到缓冲区中。然后这些缓冲区的数据会源源不断的刷新到操作系统中。
而这个过程就是源源不断的往里面写,然后源源不断的删除。
有进有出。所以就有了流的概念,就是文件流。
3.这个缓冲区在哪里?
我们直到,像fflush,fprintf这些接口始终绕不开FILE这个东西

而FILE是一个结构体,而它里面必须要封装fd
FILE里面其实还有对应打开文件的缓冲区字段和维护信息
所以说,其实,这个这个所谓的stdout,就是将hello world给放到stdout所对应文件中的缓冲区中,随后便会通过write写入到操作系统中
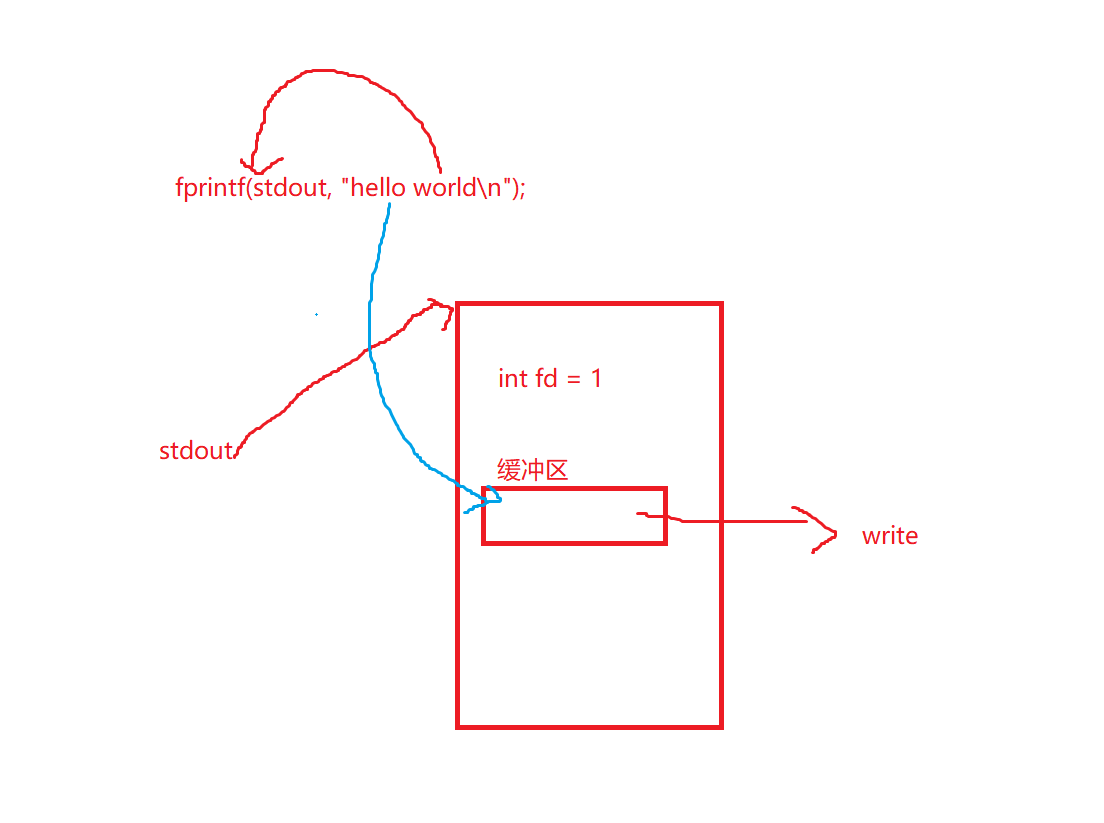
所以这个缓冲区就在FILE里面
就比如我们现在打开了10个文件,就有10个缓冲区了。每个文件都有对应的缓冲区
所以每一个文件都会通过它的自己的缓冲区,刷新到其对应的文件上。
4.这个FILE对象属于用户呢?还是操作系统呢?这个缓冲区,是不是用户级的缓冲区呢?
这个FILE对象一定属于用户。语言都属于用户层。
所以这个缓冲区,就是用户级缓冲区
所以我们就知道了,下面这个函数返回的为很么要是FILE*了

fopen是libc.so库中提供的接口。
这个fopen在底层会去调用open系统调用,帮我们建立内核级别的文件对象。然后拿到文件描述符,在语言层给我们malloc(FILE),所以返回的是FILE*
5.为什么前面的图④中C语言系列接口打印了两次?
即在下面代码中,出现了下面的情况
#include <stdio.h>
#include <string.h>
#include <unistd.h>
int main()
{
const char* fstr = "hello fwrite\n";
const char* str = "hello write\n";
//C语言
printf("hello printf\n"); //stdout-->1
fprintf(stdout,"hello fprintf\n");//stdout-->1
fwrite(fstr,strlen(fstr),1,stdout);//stdout-->1
write(1,str,strlen(str)); //1
//操作系统提供的systemcall
fork();
return 0;
}
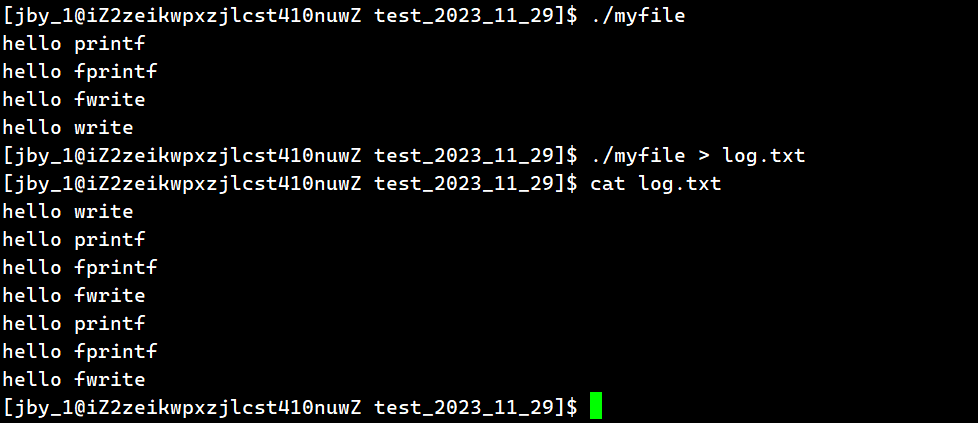
对于没有重定向的,我们很清楚打印流程
而我们一旦使用重定向,那么缓冲方案变为了全缓冲,因为全缓冲是在普通文件写入的时候才使用的。
也就是说,遇到\n不在刷新了,而是等缓冲区被写满才刷新
所以我们前面用C接口写的这三行数据也写不满缓冲区,所以会留在缓冲区里面。因为缓冲区并没有被刷新
而最后的write系统调用就会直接写入到操作系统中,故而会先打印出来。
所以截止至此,已经解释了为什么前面的二号图中,顺序会出现问题的现象,因为最后进程退出的时候,会强制刷新。
我们可以用这段代码,来验证一下结果
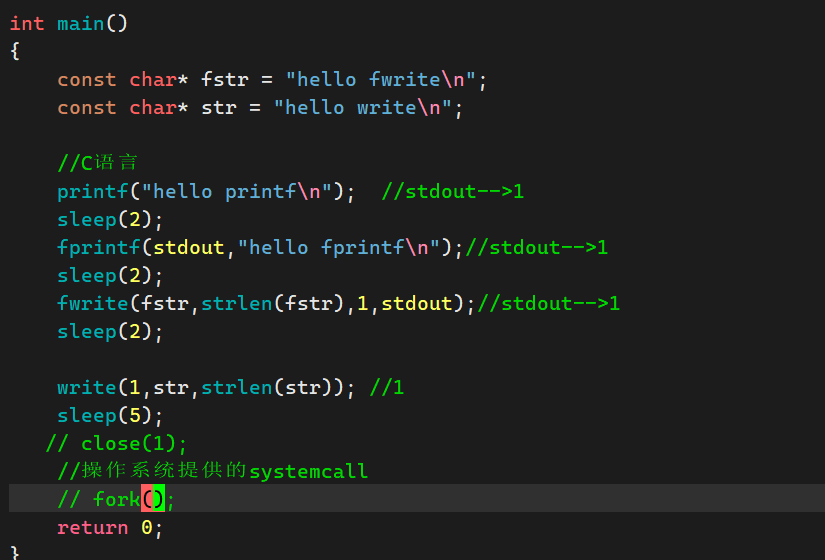
运行结果为如下
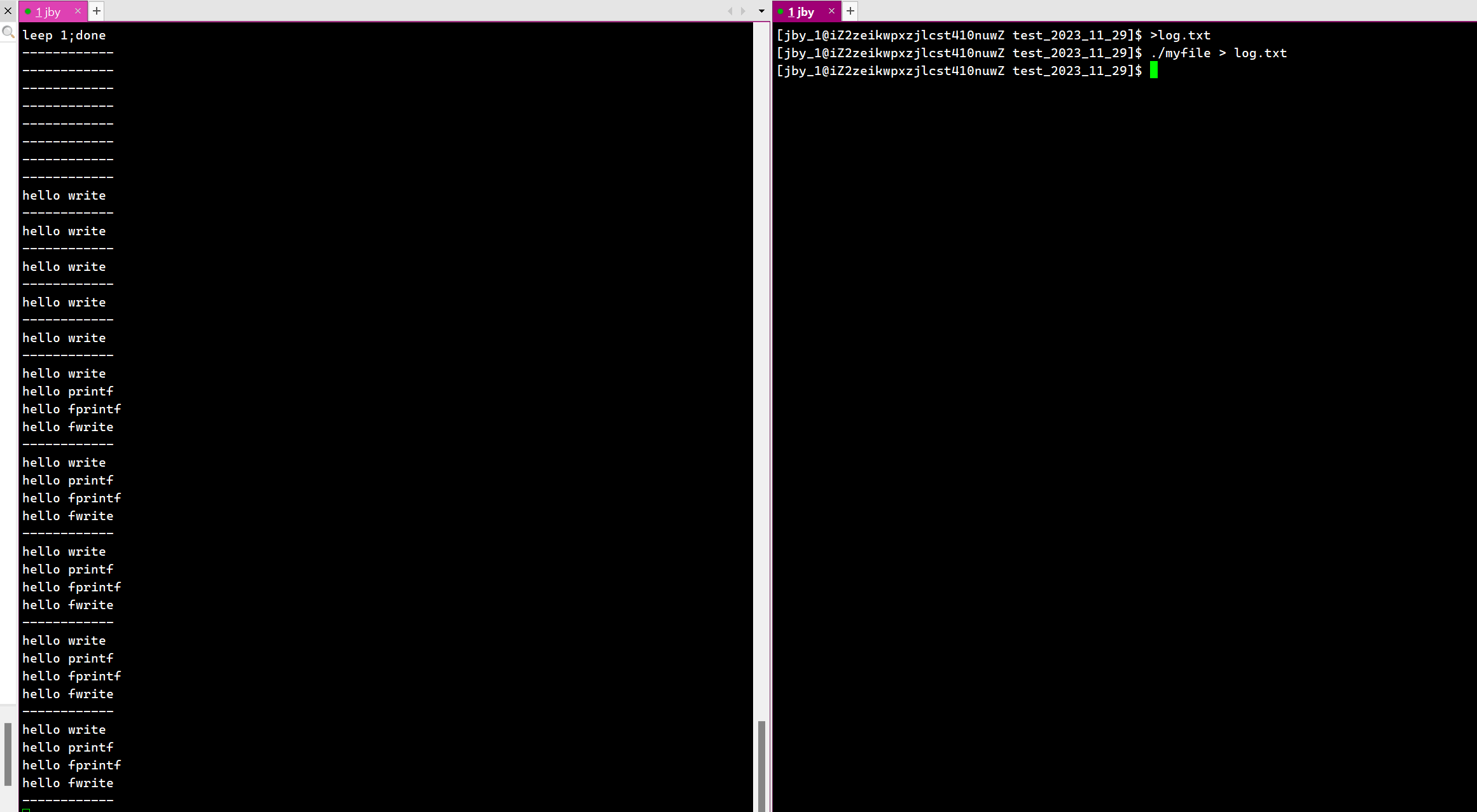
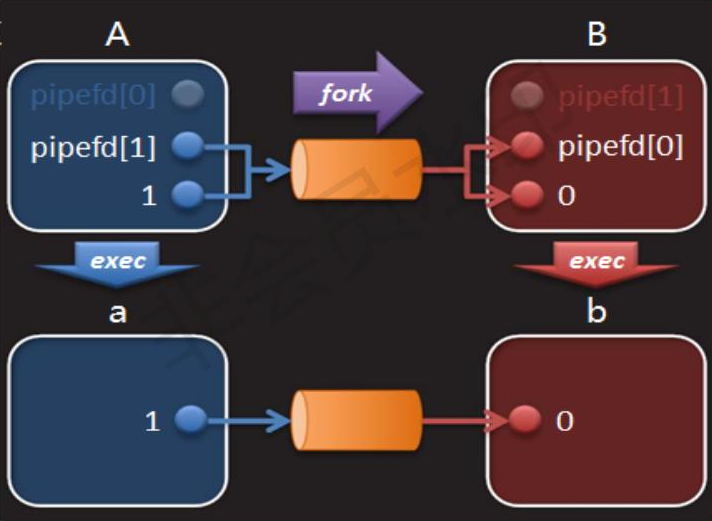
而我们后面将代码加上一个fork以后。
而我们此时,write接口已经写入了。那些C语言系列的接口的数据还在缓冲区中,此时我们fork以后,会创建子进程,共享代码,然后数据以写时拷贝的方式存在。
而我们这个缓冲区就是用户级缓冲区,是我们FILE的一部分,也就是说,就相当于在堆里面的一个数据。而父进程在想要刷新的时候,其实本质就是清空缓冲区,也就是要修改。所以此时会发生写时拷贝,父子进程就对这段缓冲区各自拥有了一份。所以我们最终就发现了这段数据被刷新了两份。
所以我们就看到了C接口被刷新了两次。

![[笔记]dubbo发送接收](https://img-blog.csdnimg.cn/direct/7ca575bb0d09448994416e144d5c6069.png)