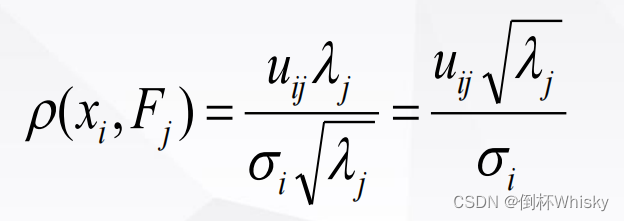本文仅供学习,不作任何商业用途,严禁转载。绝大部分资料来自----计算机系统结构教程(第二版)张晨曦等
计算机体系结构----流水线技术(三)
- 3.1 流水线的基本概念
- 3.1.1 什么是流水线
- 3.1.2 流水线的分类
- 1. 部件级流水线、处理机级流水线及系统级流水线
- 2.单功能流水线与多功能流水线
- 3. 静态流水线与动态流水线
- 4. 线性流水线与非线性流水线
- 5. 顺序流水线与乱序流水线
- 3.2 流水线的相关与冲突
- 3.2.1 一条经典的5级流水线
- 1. 取址周期(IF)
- 2. 指令译码/读寄存器周期(ID)
- 3. 执行/有效地址计算周期(EX)
- 4. 存储器访问/分支完成周期(MEM)
- 5. 写回周期(WB)
- 3.2.2 相关与流水线冲突
- 1. 相关
- 2. 流水线冲突
3.1 流水线的基本概念
3.1.1 什么是流水线
工业上的流水线大家一定都很熟悉了,例如汽车装配生产流水线等。在这样的流水线中,整个装配过程被分为多道工序,每道工序由一个人(或多人)完成,各道工序所花的时间也差不多。整条流水线流动起来后,每隔一定的时间间隔(差不多就是一道工序的时间)就有一辆汽车下线。如果我们跟踪一辆汽车的装配全过程,就会发现其总的装配时间并没有缩短,但由于多辆车的装配在时间上错开后,重叠进行,因此最终能达到总体装配速度(吞吐率)的提高。
在计算机中也可以采用类似的方法,把一个重复的过程分解为若干个子过程(相当于上面的工序),每个子过程由专门的功能部件来实现。把多个处理过程在时间上错开,依次通过各功能段,这样,每个子过程就可以与其他的子过程并行进行。这就是流水线技术(pipelining)。流水线中的每个子过程及其功能部件称为流水线的级或段(stage),段与段相互连接形成流水线。流水线的段数称为流水线的深度(Pipeline Depth)。
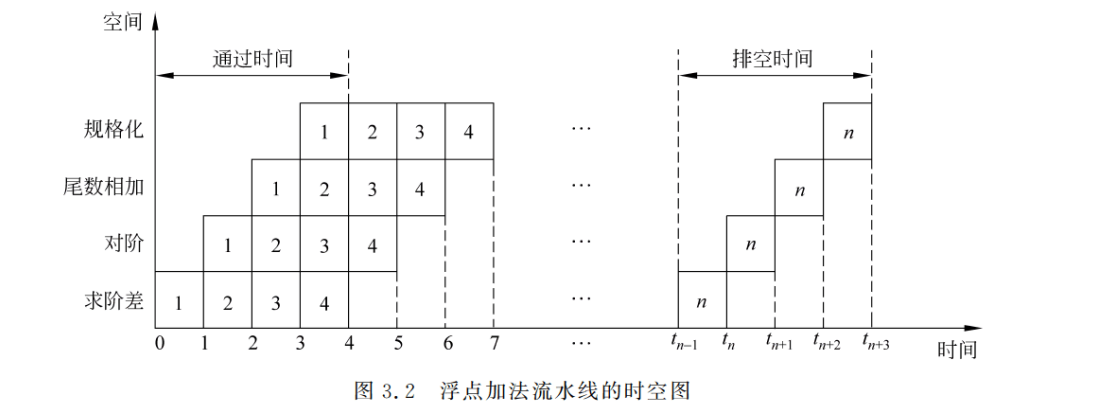
把流水线技术应用于指令的解释执行过程,就形成了指令流水线。把流水线技术应用于运算的执行过程,就形成了运算操作流水线,也称为部件级流水线。图 3.1 是一条浮点加法流水线,它把执行过程分解为求阶差、对阶、尾数相加、规格化 4 个子过程,每一个子过程在各自独立的部件上完成。如果各段的时间相等,都是Δt,那么,虽然完成一次浮点加法所需要的总时间(从“入”到“出”)还是 4Δt,但若在输人端连续送入加法任务,则从加法器的输出端来看,却是每隔一个 Δt 就能出一个浮点加法结果。因此,该流水线能把浮点加法运算的速度提高 3 倍。

一般采用时空图来描述流水线的工作过程。图 3.2 是上述 4 段流水线的时空图。图中横坐标表示时间,纵坐标表示空间,即流水线中的流水段。格子中的数字 1 代表第 1 个运算,2代表第 2个运算…”。第 1个运算在时刻 0 进入流水线;第 2 个运算在时刻1进入流水线,同时第 1个运算离开“求阶差”段而进人“对阶”段:第 3 个运算在时刻 2 进入流水线同时第 1个运算离开“对阶”段而进人“尾数相加”段,第 2 个运算离开“求阶差”段而进人“对阶”段:第 4 个运算在时刻3 进入流水线,同时第 1 个运算离开“尾数相加”段而进人“规格化”段,第 2个运算离开“对阶”段而进入“尾数相加”段,第 3 个运算离开“求阶差”段而进入“对阶”段:以此类推。
从上面的分析可以看出,流水技术有以下特点:
(1) 流水线把一个处理过程分解为若干个子过程,每个子过程由一个专门的功能部件来实现。因此,流水线实际上是把一个大的处理功能部件分解为多个独立的功能部件,并依靠它们的并行工作来提高处理速度(吞吐率)。
(2) 流水线中各段的时间应尽可能相等,否则将引起流水线堵塞和断流,因为时间最长的段将成为流水线的瓶颈(Bottleneck of a Pipeline),此时流水线中的其他功能部件就不能充分发挥作用了。因此瓶颈问题是流水线设计中必须解决的。
(3) 流水线每一个段的后面都要有一个缓冲寄存器(锁存器),称为流水寄存器。其作用是在相邻的两段之间传送数据,以提供后面流水段要用到的信息。其另一个作用是隔离各段的处理工作。避免相邻流水段电路的相互打扰。
(4) 流水技术适合于大量重复的时序过程,只有在输入端不断地提供任务,才能充分发
挥流水线的效率。
(5) 流水线需要有通过时间和排空时间。它们分别是指第一个任务和最后一个任务从进人流水线到流出结果的那个时间段,如图 3.2 所示。在这两个时间段中,流水线都不是满负荷的。经过“通过时间”后,流水线进入满载工作状态,整条流水线的效率才能得到充分发挥。
3.1.2 流水线的分类
流水线可以从不同的角度和观点来分类,下面是几种常见的分类。
1. 部件级流水线、处理机级流水线及系统级流水线
按照流水技术用于计算机系统的等级不同,可以把流水线分为 3 种:部件级流水线、处
理机级流水线和系统级流水线。部件级流水线是把处理机中的部件进行分段,再把这些分段相互连接而成的。它使得运算操作能够按流水方式进行。图 3.1 中的浮点加法流水线就是一个典型的例子。这种流水线也称为运算操作流水线(Arithmetic Pipeline)。
处理机级流水线又称指令流水线(Instruction Pipeline)。它是把指令的执行过程按照流水方式进行处理,即把一条指令的执行过程分解为若干人子过程,每个子过程在独立的功能部件中执行。3.4.1节中论述的 5 段指令流水线就是一个例子,它能同时重叠执行 5 条指令。
系统级流水线是把多个处理机串行连接起来,对同一数据流进行处理,每个处理机完成整个任务中的一部分。前一台处理机的输出结果存人存储器中,作为后一台处理机的输入。这种流水线又称宏流水线(Macro Pipeline)。
2.单功能流水线与多功能流水线
这是按照流水线所完成的功能来分类的。
1)单功能流水线(Unifunction Pipeline)单功能流水线是指流水线各段之间的连接固定不变、只能完成一种固定功能的流水线如前面介绍的浮点加法流水线就是单功能流水线。若要完成多种功能,可采用多条单功能流水线。例如 Cray-1 巨型机有 12 条单功能流水线。
2)多功能流水线(Multifunction Pipeline)
多功能流水线是指各段可以进行不同的连接,以实现不同功能的流水线。美国 TI公司 ASC 处理机中采用的运算流水线就是多功能流水线,它有 8 个功能段,按不同的连接可以实现浮点加减法运算和定点乘法运算,如图 3.3 所示。
3. 静态流水线与动态流水线
多功能流水线可以进一步分为静态流水线和动态流水线两种
- 静态流水线(Static Pipeline)
静态流水线是指在同一时间内,多功能流水线中的各段只能按同一种功能的连接方式工作的流水线。当流水线要切换到另一种功能时,必须等前面的任务都流出流水线之后,才能改变连接。例如,上述 ASC 的 8 段只能或者按浮点加减运算连接方式工作,或者按定点乘运算连接方式工作。在图 3.4 中,当要在n个浮点加法后面进行定点乘法时,必须等最后一个浮点加法做完、流水线排空后,才能改变连接,开始新的运算。
2)动态流水线(Dynamic Pipeline)
动态流水线是指在同一时间内,多功能流水线中的各段可以按照不同的方式连接,同时执行多种功能的流水线。它允许在某些段正在实现某种运算时,另一些段却在实现另一种运算。当然,多功能流水线中的任何一个功能段只能参加到一种连接中。动态流水线的优点是:更加灵活,能提高各段的使用率,能提高处理速度,但其控制复杂度增加了。
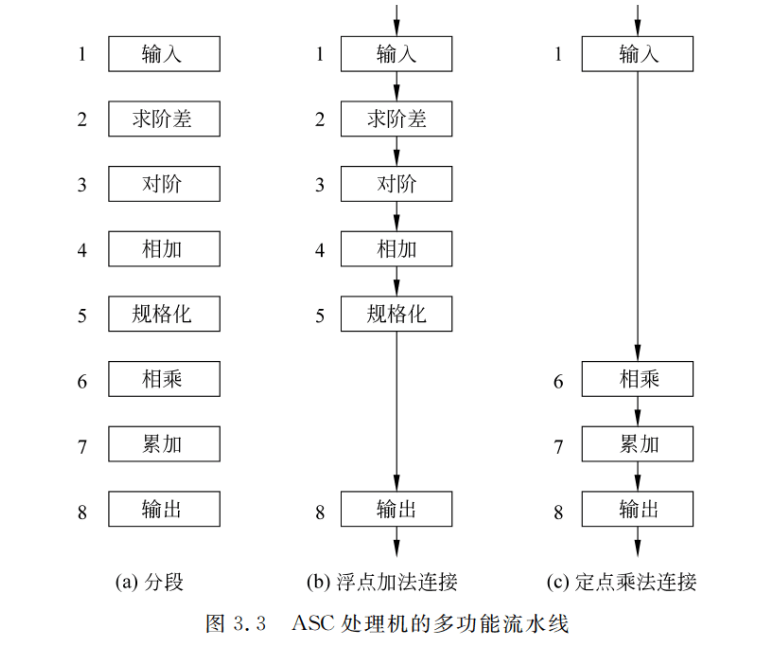
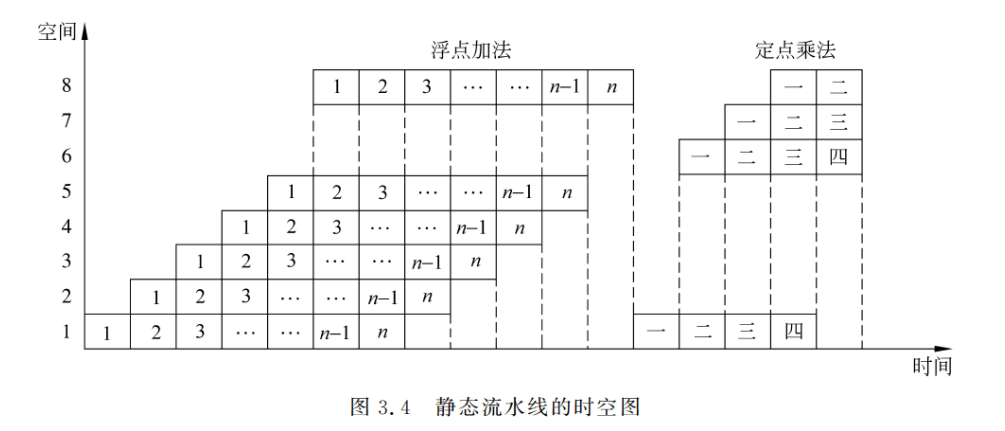
对于图 3.3 的情况,动态流水线的工作过程如图 3.5 所示。这里,定点乘法提前开始了(相对于静态流水线而言)。可以提前多少取决于任务的流动情况,要保证不能在公用段发生冲突。
对于静态流水线来说,只有当输入的是一串相同的运算任务时,流水的效率才能得到充分的发挥。如果交替输入不同的运算任务,则流水线的效率会降低到和顺序处理方式的一样。而动态流水线则不同.它允许多种运算在同一条流水线中同时进行。因此,在一般情况下,动态流水线的效率比静态流水线的高。但是,动态流水线的控制要复杂得多。所以目前大多数的流水线是静态流水线。
4. 线性流水线与非线性流水线
按照流水线中是否存在反馈回路,可以把流水线分为以下两类。
1)线性流水线(Linear Pipeline)
线性流水线是指各段串行连接、没有反馈回路的流水线。数据通过流水线中的各段时,每一个段最多只流过一次。
2)非线性流水线(Nonlinear Pipeline) ==
非线性流水线是指各段除了有串行的连接外,还有反馈回路的流水线。图 3.6 是一个非线性流水线的示意图。它由 4 段组成,经反馈回路和多路开关使某些段要多次通过。S3的输出可以反馈到 S2,而 S4的输出可以反馈到S1。(注:非线性流水线可以看成bypass旁路,用以降低数据依赖data dependence)==
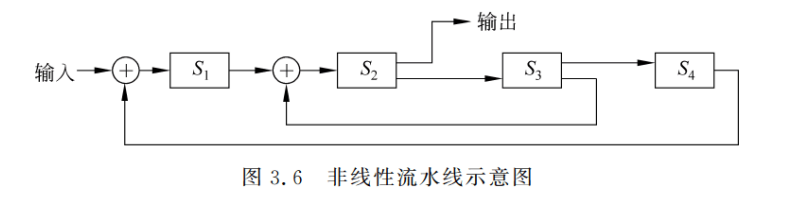
非线性流水线常用于递归或组成多功能流水线。在非线性流水线中,一个重要的问题是确定什么时候向流水线引进新的任务,才能使该任务不会与先前进入流水线的任务发生争用流水段的冲突。这就是所谓的非线性流水线的调度问题,3.3 节将详细讨论这个问题。
5. 顺序流水线与乱序流水线
根据流水线中任务流入和流出的顺序是否相同,可以把流水线分为以下两种。
1) 顺序流水线(In-order Pipeline)
在顺序流水线中,流水线输出端任务流出的顺序与输入端任务流入的顺序完全相同每一个任务在流水线的各段中是一个跟着一个顺序流动的。
2)乱序流水线(Out-of-order Pipeline)----又简称成OoO
在乱序流水线中,流水线输出端任务流出的顺序与输人端任务流入的顺序可以不同,允许后进入流水线的任务先完成。这种流水线又称为无序流水线、错序流水线、异步流水线。通常把指令执行部件中采用了流水线的处理机称为流水线处理机。如果处理机具有向量数据表示和向量指令,则称为向量流水处理机,简称向量机:否则就称为标量流水处理机。
3.2 流水线的相关与冲突
3.2.1 一条经典的5级流水线
在论述流水线的相关与冲突之前,先来介绍一条经典的 5 段 RISC 流水线。先考虑在非流水情况下是如何实现的。把一条指令的执行过程分为以下 5 个时钟周期。
1. 取址周期(IF)
以程序计数器(PC)中的内容作为地址,从存储器中取出指令并放入指令寄存器(IR);同时 PC 值加 4(假设每条指令占 4 个字节),指向顺序的下一条指令。
2. 指令译码/读寄存器周期(ID)
对指令进行译码,并用 IR 中的寄存器地址去访问通用寄存器组,读出所需的操作数。
3. 执行/有效地址计算周期(EX)
在这个周期,ALU 对在上一个周期准备好的操作数进行运算或处理。不同指令所进行的操作不同。
(1) load 和 store 指令: ALU 把指令中所指定的寄存器的内容与偏移量相加,形成访存有效地址。
(2) 寄存器-寄存器 ALU 指令: ALU 按照操作码指定的操作对从通用寄存器组中读出的数据进行运算。
(3) 寄存器-立即数 ALU 指令: ALU 按照操作码指定的操作对从通用寄存器组中读出的操作数和指令中给出的立即数进行运算。
(4) 分支指令:ALU 把指令中给出的偏移量与 PC 值相加,形成转移目标的地址。同时.对在前一个周期读出的操作数进行判断,确定分支是否成功。
4. 存储器访问/分支完成周期(MEM)
- load 指令和 store 指令
如果是 load 指令,就用上一个周期计算出的有效地址从存储器中读出相应的数据:如果是 store 指令,就把指定的数据写人入这个有效地址所指出的存储器单元。 - 分支指令
如果分支“成功”,就把在前一个周期中计算好的转移目标地址送入 PC。分支指令执行完成;否则,就不进行任何操作。(注意:PC是在内从中的,所以分支成功送入PC就是送入存储器中)。
其他类型的指令在此周期不做任何操作
5. 写回周期(WB)
把结果写入通用寄存器组。对于 ALU 运算指令来说,这个结果来自 ALU,而对于load 指令来说,这个结果来自存储器。
在上述 5 个周期的实现方案中,分支指令和 store 指令需要 4 个周期==(但是分支指令和store指令也需要经历WB阶段,虽然这个阶段CPU不进行操作)==,其他指令需要 5个周期才能完成。==在追求更高性能的方案中,可以把分支指令的执行提前到 ID 周期完成这样分支指令只需要两个周期。(在ILP指令并行中可能会使用这个技术)==不过,为了实现这一点,需要增设一个专门用于计算转移目标地址的加法器。
把上述实现方案改造为流水线实现是比较简单的,只要把上面的每一个周期作为一个流水段,并在各段之间加上锁存器,就构成了如图 3.17 所示的 5 段流水线。这些锁存器称为流水寄存器。如果在每个时钟周期启动一条指令,则采用流水方式后的性能将是非流水方式的 5 倍。当然,事情也没这么简单,还要解决好流水处理带来的一些问题。
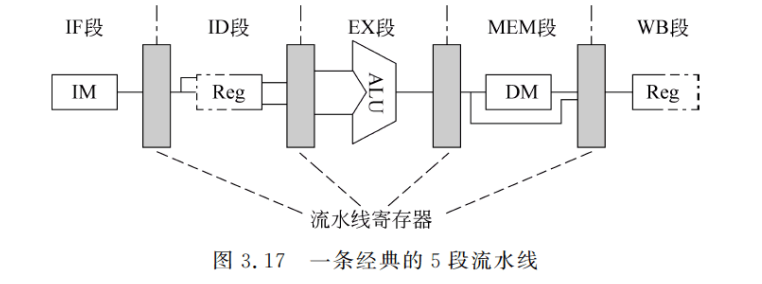
首先,在流水线方式下,要保证不会在同一时钟周期要求同一个功能段做两件不同的工作。例如,不能要求 ALU 既做有效地址计算,又同时做算术运算。RISC 指令集比较简洁,所以该要求不难实现。
其次,为了避免 IF 段的访存(取指)与 MEM 段的访存(读写数据)发生冲突(冲突原因:PC是放在MEM里面的),必须采用分离的指令存储器和数据存储器,或者是仍采用一个公用的存储器,但要采用分离的指令Cache 和数据 Cache。一般是采用后者。
第三,ID 段要对通用寄存器组进行读操作,而 WB 段要对通用寄存器组进行写操作,为了解决对同一通用寄存器的访问冲突,我们把写操作安排在时钟周期的前半拍完成,把读操作安排在后半拍完成。在图 3.17 以及后面的图中,用部件 Reg 的边框为实线来表示进行读或写操作,而虚线则表示不进行操作。
第四,图 3.17 中没有考虑 PC 的问题。为了做到每一个时钟周期启动一条指令,必须在每个时钟周期都进行 PC 值加 4 的操作。这要在 IF 段完成,为此需要设置一个专门的加法器。另外,分支指令也要修改 PC 的值,它是到 MEM 段才会进行修改的。3.4.2 节将详细讨论分支的处理问题。
需要说明的是,这里给出的方案并不是性能最好或者成本最低的,它只是用来帮助我们更好地理解指令流水线的原理和实现。
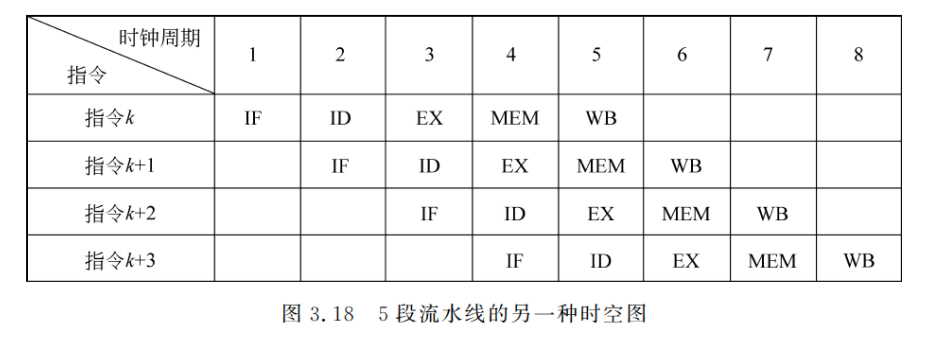
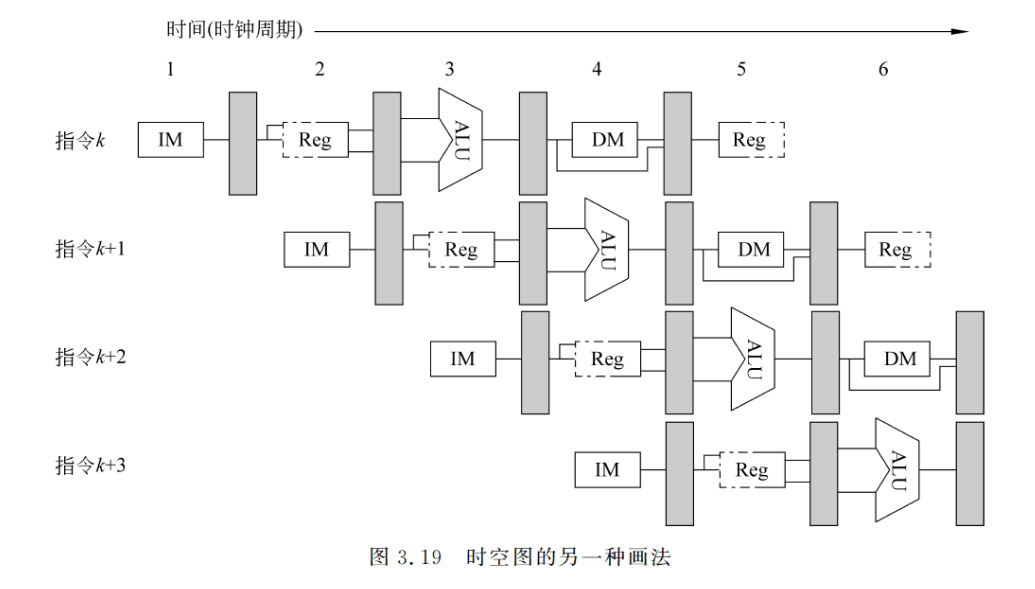
3.1.1 节中介绍了流水线的时空图。为便于后面的讨论,下面介绍另外一种时空图,如图 3.18 所示。它是如图 3.17 所示的流水线的时空图。其横向与图 3.2 中的横坐标类似,表示的是时间。这里用的是时钟周期。但纵向和时空区中的内容与图 3.2 的不同。图 3.2的纵坐标(向上)是各流水段,时空区中填的是所处理的任务,而图 3.18 中的纵向(向下)却是所执行的指令(相当于图 3.2 中的任务)按顺序列出,时空分区中填的是各流水段的名称这种时空图更直观地展现了指令的重叠执行情况。图 3.19 是这种时空图的又一种画法,它以数据通路的快照形式更直观地展现了部件重叠工作的情况。在后面的论述中,将经常采用这两种时空图。
3.2.2 相关与流水线冲突
1. 相关
相关(dependence)是指两条指令之间存在某种依赖关系。如果指令之间没有任何关系,那么当流水线有足够的硬件资源时,它们就能在流水线中顺利地重叠执行,不会引起任何停顿。但如果两条指令相关,它们也许就不能在流水线中重叠执行或者只能部分重叠研究程序中指令之间存在什么样的相关,对于充分发挥流水线的效率有重要的意义。
相关有三种类型:数据相关(也称真数据相关)、名相关、控制相关。
1)数据相关/数据依赖/真数据相关(Data Dependence)
考虑两条指令i和j,i在j的前面(下同),如果下述条件之一成立,则称指令j与指令i数据相关:
(1) 指令j使用指令i产生的结果;
(2) 指令j与指令 k 数据相关,而指令k又与指令i数据相关。
其中第(2)个条件表明,数据相关具有传递性。两条指令之间如果存在第一个条件所指出的相关的链,则它们是数据相关的。数据相关反映了数据的流动关系,即如何从其产生者流动到其消费者。
例如,下面这一段代码存在数据相关。

其中箭头表示必须保证的执行顺序。它由产生数据的指令指向使用该数据的指令。
当数据的流动是经过寄存器时,相关的检测比较直观和容易,因为寄存器是统一命名的,同一寄存器在所有指令中的名称都是唯一的。而当数据的流动是经过存储器时,检测就比较复杂了,因为形式上相同的地址其有效地址未必相同,如某条指令中的 10(R5)与另一条指令中的 10(R5)可能是不同的(R5 的内容可能发生了变化);而形式不同的地址其有效地址却可能相同(就是说不同的寄存器RX,可能指向同一块内存)。
2)名相关/名称依赖(Name Dependence)
这里的名是指指令所访问的寄存器或存储器单元的名称。如果两条指令使用了相同的名,但是它们之间并没有数据流动,则称这两条指令存在名相关。指令j与指令i之间的名相关有以下两种:
(1)== 反相关(Anti-Dependence)==。如果指令 ;所写的名与指令 所读的名相同,则称指令i和;发生了反相关。反相关指令之间的执行顺序是必须严格遵守的,以保证i读的值是正确的。
(2) 输出相关(Output Dependence)。如果指令 j和指i 所写的名相同,则称指令i和j发生了输出相关。输出相关指令的执行顺序是不能颠倒的,以保证最后的结果是指令i 写进去的。
与真数据相关不同,名相关的两条指令之间并没有数据的传送,只是使用了相同的名而已。如果把其中一条指令所使用的名换成别的,并不影响另外一条指令的正确执行。因此可以通过改变指令中操作数的名来消除名相关,这就是换名(renaming)技术。对于寄存器操作数进行换名称为寄存器换名(Register Renaming)。寄存器换名既可以用编译器静态实现,也可以用硬件动态完成。
例如,考虑下述代码。

DIV.D 和 ADD.D存在反相关。进行寄存器换名,即把后面的两个 F8 换成 S后,变成

这就消除了原代码中的反相关。
3)控制相关/控制依赖(Control Dependence)
控制相关是指由分支指令引起的相关。它需要根据分支指令的执行结果来确定后面该执行哪个分支上的指令。一般来说,为了保证程序应有的执行顺序,必须亚格按照控制相关确定的顺序执行。
控制相关的一个最简单的例子是 if 语句中的 then 部分,例如:

这里的 if pl 和if p2 编译成目标代码以后都是分支指令。语句 S1 与 p1 控制相关,S2 与 p2控制相关。S 与 p1 和 p2 均无关。
控制相关带来了以下两个限制。
(1) 与一条分支指令控制相关的指令不能被移到该分支之前;否则这些指令就不受该分支控制了。对于上述的例子,then 部分中的指令不能移到 if 语句之前。
(2) 如果一条指令与某分支指令不存在控制相关,就不能把该指令移到该分支之后对于上述的例子,不能把 S 移到 if 语句的 then 部分中。
2. 流水线冲突
流水线冲突(Pipeline Hazard) 是指对于具体的流水线来说,由于相关的存在,使得指令流中的下一条指令不能在指定的时钟周期开始执行。
流水线冲突有以下三种类型 :
(1) 结构冲突(Structural Hazard): 因硬件资源满足不了指令重叠执行的要求而发生的冲突。
(2) 数据冲突(Data Hazard): 当指令在流水线中重叠执行时,因需要用到前面指令的执行结果而发生的冲突。
(3) 控制冲突(Control Hazard): 流水线遇到分支指令或其他会改变 PC 值的指令所起的冲突。
在设计流水线时,需要很好地解决冲突问题;否则,就可能影响流水线的性能甚至导致错误的执行结果。当发生冲突时,往往需要使某些指令推后执行,从而使流水线出现停顿。这会降低流水线的效率和实际的加速比。
在后面的讨论中,我们约定: 当一条指令被暂停时,在该暂停指令之后流出的所有指令都要被暂停,而在该暂停指令之前流出的指令则继续进行。显然,在整个暂停期间,流水线不会启动新的指令。
- 结构冲突
在流水线处理机中,如果某种指令组合因为资源冲突而不能正常执行,则称该处理机有结构冲突。为了能够使各种组合的指令都能顺利地重叠执行,就需要对功能部件进行全流水处理或重复设置足够多的资源。
下面以访存冲突为例来说明结构冲突及其解决办法。有些流水线处理机只有一个存储器,数据和指令都存放在这个存储器中。在这种情况下,当执行 load 指令需要存取数时,若又要同时完成其后某条指令的“取指令”,那么就会发生访存冲突,如图 3.20 中带阴影的 M所示。
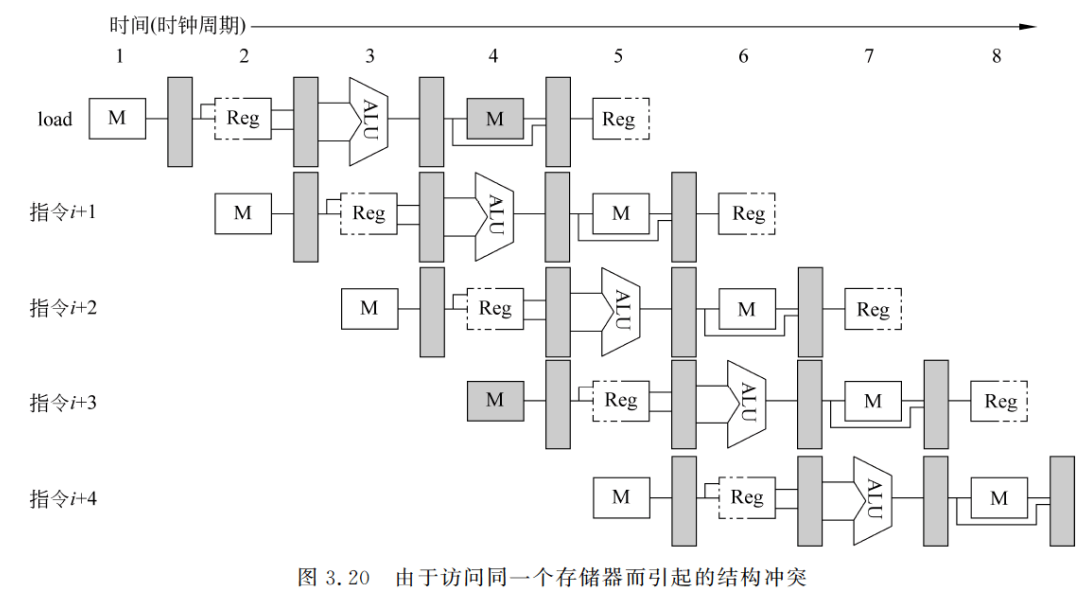
为了消除这个结构冲突,可以在前一条指令访问存储器时,将流水线停顿一个时钟周期,推迟后面取指令的操作,如图 3.21 所示。该停顿周期往往被称为“流水线气泡”,简称==“气泡”==。
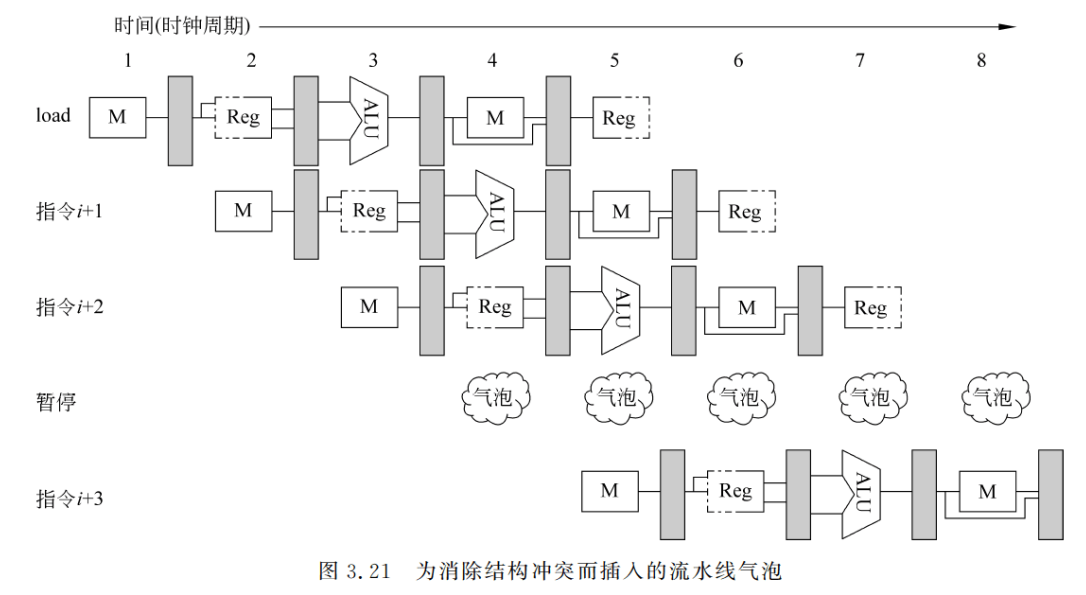
也可以用如图 3.22 所示的时空图来表示上述停顿情况。在图 3.22 中,将停顿周期标记为 stall,并将指令 i+3 的所有操作右移一个时钟周期。在这种情况下,在第 4 个时钟周期没有启动新指令。指令 i+3 要推迟到第 9 个时钟周期才完成。在第 8 个时钟周期,流水线中没有指令完成。
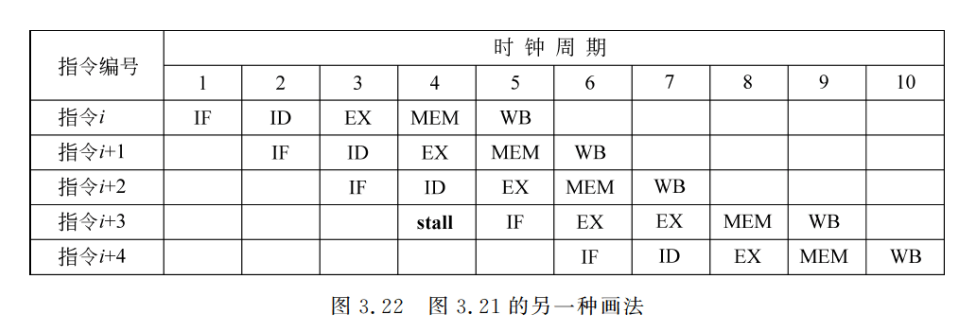
可以看出,为消除结构冲突而引入的停顿将影响流水线的性能。由于这种冲突出现的频度不低,因此一般是采用分别设置独立的指令存储器和数据存储器方法,或者仍只设置个存储器,但采用两个分离的 Cache: 指令 Cache,数据 Cache。
既然结构冲突会导致处理机的性能下降,那为什么有些计算机却允许结构冲突的存在呢?其主要原因是为了减少硬件成本。如果把流水线中的所有功能单元完全流水化,或者重复设置足够份数,那么所花费的成本将相当高。假如结构冲突并不是经常发生,那么为之大量增加硬件就可能不值得了。
- 数据冲突
(1) 数据冲突简介
当相关的指令彼此靠得足够近时,它们在流水线中的重叠执行或者重新排序会改变指令读/写操作数的顺序,使之不同于它们串行执行时的顺序。这就是发生了数据冲突。考虑以下指令在流水线中的执行情况。

DADD 指令后的所有指令都要用到 DADD 指令的计算结果,如图 3.23 所示。DADD指令在其 WB 段(第 5 个时钟周期)才将计算结果写入存器 R1,但是 DSUB 指令在其 ID段(第 3 个时钟周期)就要从寄存器 R1 读取该结果,这就是一个数据冲突。若不采取措施防止这一情况发生,则 DSUB 指令读到的值就是错误的。XOR 指令也受到这种冲突的影响,它在第 4 个时钟周期从 R1 读出的值也是错误的。而 AND 指令则可以正常执行,这是因为它是在第 5 个时钟周期的后半拍才从寄存器读数据的,而 DADD 指令在第 5 个时钟周期的前半拍已将结果写入寄存器。
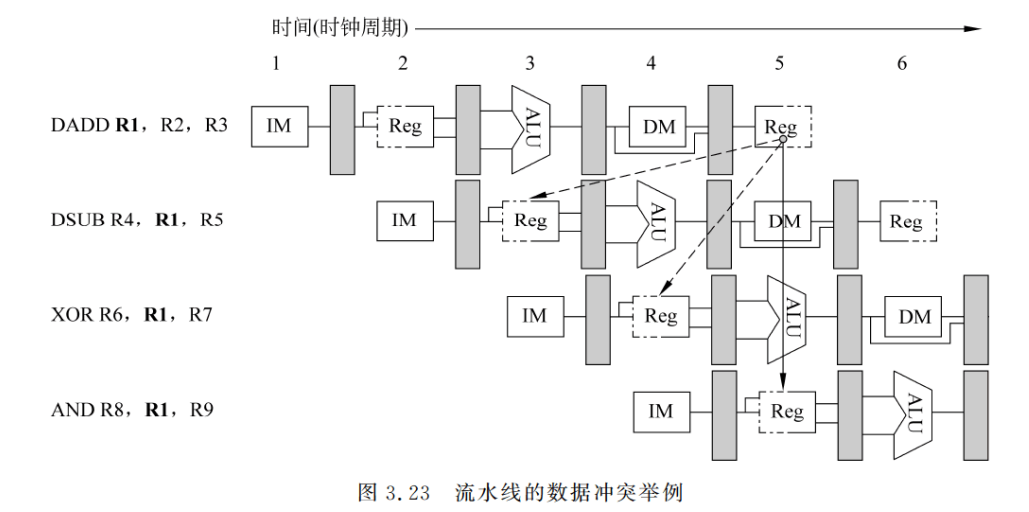
按照指令读访问和写访问的先后顺序,可以将数据冲突分为三种类型。习惯上,这些冲突是按照流水线必须保持的访问顺序来命名的。考虑两条指令i和j,且i在之前进入流水线,可能发生的数据冲突有以下几种。
①写后读冲突(Read After Write,RAW):指令j用到指令i的计算结果,而且在i将结果写入寄存器之前就去读该寄存器,因而得到的是旧值。这是最常见的一种数据冲突,它对应于真数据相关。图 3.23 中的数据冲突都是写后读冲突。
②写后写冲突(Write After Write,WAW): 指令j和指令i的结果寄存器相同,而且j在i写入之前就先对该寄存器进行了写入操作,从而导致写入顺序错误。最后在结果寄存器中留下的是i写入的值,而不是j写入的值。这种冲突对应于输出相关。
写后写冲突仅发生在这样的流水线中:❶流水线中不止一个段可以进行写操作;❷指令被重新排序了。前面介绍的 5 段流水线由于只在 WB 段写寄存器,所以不会发生写后写冲突。在第 5 章中介绍的流水线允许指令重新排序,就可能发生这种冲突。
③读后写冲突(Write After Read,WAR): 指令j的目的寄存器和指令i的源操作数寄存器相同,而且;在读取该寄存器之前就先对它进行了写操作,导致,读到的值是错误的。这种冲突是由反相关引起的。
读后写冲突在前述 5 段流水线中不会发生,因为这种流水线中的所有读操作(在ID 段)都在写结果操作(在 WB 段)之前发生。读后写冲突仅发生在这样的情况下:❶有些指令的写结果操作提前了,而有些指令的读操作滞后了;❷指令被重新排序了。
(2) 使用定向技术(forwarding/bypassing)减少数据冲突引起的停顿
当出现如图 3.23 所示的写后读冲突时,为了保证指令序列的正确执行,一种简单的处理方法是暂停流水线中 DADD 之后的所有指令,直到 DADD 指令将计算结果写入寄存器R1 之后,再让 DADD 之后的指令继续执行。但这种暂停会导致性能下降。
为了减少停顿时间,可以采用定向技术(forwarding/bypassing,也称为旁路)来解决写后读冲突。定向技术的关键思想是: 在发生写后读相关的情况下,在计算结果尚未出来之前,后面等待使用该结果的指令并不见得马上就要用该结果。如果能够将该计算结果从其产生的地方(ALU 的出口)直接送到其他指令需要它的地方(ALU 的入口),那么就可以避免停顿。对F图 3.23 的情况,可以把 DADD 指令产生的结果直接送给 DSUB 和 XOR 指,这样就能避免停顿.如图 3.24 所示。图中从流水寄存器到功能部件入口的连线表示定向路径,箭头表示数据的流向。显然,这些指令都能顺利执行而不会导致停顿。
从图 3.23 还可以看出,流水线中的指令所需要的定向结果可能不仅仅是前一条指令的计算结果,而且还有可能是前面与其不相邻的指令的计算结果。
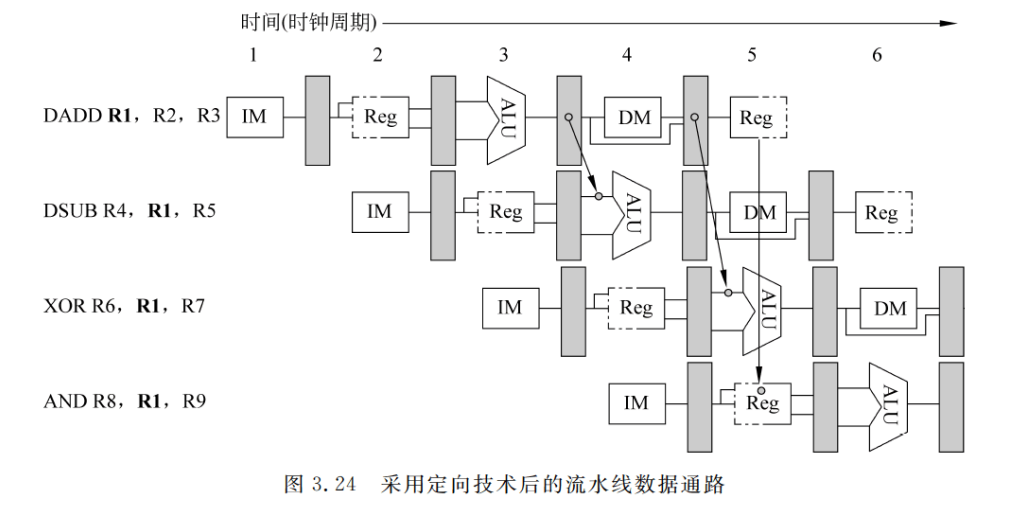
我们可以这样来实现定向:
①EX 段和 MEM 段之间的流水存器中保存的 ALU 运算结果总是送到 ALU 的入口。
②当定向硬件检测到前一个 ALU 运算结果写入的存器就是当前 ALU 操作的源存器时,那么控制逻辑就选择定向的数据作为 ALU 的输人,而不采用从通用寄存器组读出的数据。
上述定向技术可以推广到更一般的情况:将结果数据从其产生的地方直接传送到所有需要它的功能部件。也就是说,结果数据不仅可以从某一功能部件的输出定向到其自身的输入,而且还可以定向到其他功能部件的输入。
(3) 需要停顿的数据冲突
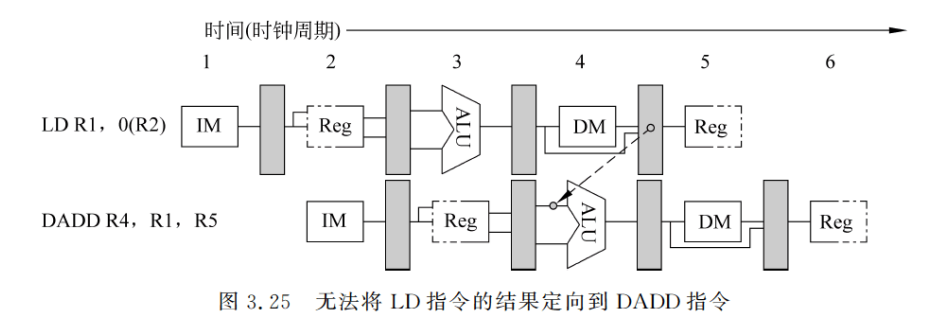
并不是所有的数据冲突都可以用定向技术来解决的。参照图 3.25,DADD 指令要使用LD 指令的结果,如图 3.25 中的虚线所示。显然,这个定向是无法实现的。为保证上述指令序列能在流水线中正确执行,需要设置一个称为“流水线互锁机制(Pipeline Interlock)的功能部件。一般来说,流水线互锁机制的作用是检测发现数据冲突并使流水线停顿,直至冲突消失。停顿是从等待相关数据的指令开始,到相应的指令产生所需数据为止。停顿导致在流水线中插入气泡,使得被停顿指令的 CPI增加了相应的时钟周期数。
(4) 依靠编译器解决数据冲突
为了减少停顿,对于无法用定向技术解决的数据冲突,可以通过在编译时让编译器重新组织指令顺序来消除冲突,这种技术称为“指令调度”(Instruction Scheduling)或“流水线调度”(Pipeline Scheduling)。实际上,对于各种冲突,都有可能用指令调度来解决下面通过一个例子来进一步说明,考虑以下表达式。
A
=
B
+
C
D
=
E
−
F
A = B + C \\ D = E - F
A=B+CD=E−F
表 3.5 左边是这两个表达式编译后所形成的代码。在这个代码序列中,DADD Ra,Rb.Rc与LD Rc,C之间存在数据冲突,DSUB Rd,Re,Rf与 LD Rf,F之间也是如此。为了保证流水线能正确执行调度前的指令序列,必须在指令的执行过程中插入两个停顿周期(分别在 DADD 和 DSUB 执行前)。而在调度后的指令序列中,加大了 DADD 和 DSUB 指令与LD 指令的距离。通过采用定向,可以消除数据冲突,因而不必在执行过程中插入任何停顿周期。(注意:这里默认使用了bypassing旁路技术,上一条指令的MEM出来的数据直接旁路到下一条指令的ALU输入)

- 控制冲突
==在流水线中,控制冲突可能会比数据冲突造成更多的性能损失,所以同样需要得到很好的处理。执行分支指令的结果有两种,一种是分支“成功”,PC 值改变为分支转移的目标地址;另一种则是“不成功”或者“失败”,这时 PC 值保持正常递增,指向顺序的下一条指令对分支指令“成功”的情况来说,是在条件判定和转移地址计算都完成后,才改变 PC 值的。==对于本篇文章3.2.1节中的 5 段流水线来说,改变 PC 值是在 MEM 段进行的。(注:因为PC在MEM中,所以改变PC值是在MEM阶段进行的。)
处理分支指令最简单的方法是“冻结”(freeze)或者“排空”(flush)流水线。即一旦在流水线的译码段 ID 检测到分支指令,就暂停其后的所有指令的执行,直到分支指令到达MEM段、确定是否成功并计算出新的 PC 值为止。然后,按照新的 PC 值取指令,如图 3.26 所示。在这种情况下,分支指令给流水线带来了三个时钟周期的延迟。这种方法的优点在于其简单性。(注:图3.26里面分支目标指令存在两个IF,其中第一个IF的是分支失败下面的一条指令,如果分支计算成功,第二个IF取的是目标地址的指令,如果分支失败,IF取的是分支失败下面的一条指令,和第一个IF取的指令是一样的)
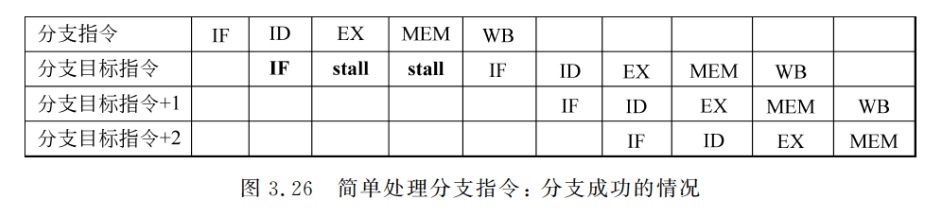
分支失败时的时空图与图 3.26 类似,只是分支指令之后执行的指令不是分支目标的指令,而是后继地址的指令。显然,这种让流水线空等的方法不是一种好的选择。后面我们将对其进行改进。
在后面的叙述中,我们把由分支指令引起的延迟称为分支延迟(Branch Delay)。
分支指令在目标代码中出现的频度是不低的,统计结果表明,每三四条指令就有一条是分支指令。当分支延迟比较大时,所带来的性能损失是相当大的。所以降低分支延迟对于充分发挥流水线的效率是十分重要的。
为减少分支延迟,可采取以下措施:
(1) 在流水线中尽早判断出(或者猜测)分支是否成功;
(2) 尽早计算出分支目标地址。
这两种措施要同时采用,缺一不可。因为只有判断出转移是否成功而且得到分支目标地址后才能进行转移。
可以把这两步工作提前到 ID 段完成,即分支指令是在ID 段的末尾执行完成的(注:即在ID阶段结束后我们就可以得到分支是否成功以及分支目标地址),这样就可以把分支延迟减少到一个时钟周期(注:即我们可以在ID的下一个时钟周期就开始取指分支指令的下一条指令)。
进一步减少分支延迟的方法有许多种。下面只介绍三种通过软件(编译器)来处理的方法,更复杂的软硬件结合的方法将在后面讨论。这三种方法有一个共同的特点:它们对分支的处理方法在程序的执行过程中始终是不变的。它们要么总是预测分支成功,要么总是预测分支失败。
(1)预测分支失败
当 ID 段检测到分支指令时,让流水线空等是一种“不作为”的策略,是一种“懒惰”的处理方法,显然不可取。可以让流水线通过预测选择两条分支路径中的一条,继续处理后续指令。预测有两种选择:猜测分支成功,或者猜测分支失败。不管哪一种,都可以通过编译器来优化性能,让代码中最常执行的路径与所选的预测方向一致。
预测分支失败的方法是沿失败的分支继续处理指令,即允许分支指令后的指令继续在流水线中流动,就好像什么都没发生似的。当确定分支是失败时,就可以将分支指令看作一条普通指令,流水线正常流动,如图 3.27(a)所示;当确定分支成功时,流水线就把在分支指令之后取出的指令转化为空操作,并按分支目标地址重新取指令执行,如图 3.27(b)所示。采用这种方法处理分支指令的后续指令时,要保证分支结果出来之前不会改变处理器的状态,以便一旦猜错时,处理器就能够回退到原先的状态。

(注:整体思想就是我们认为/预测这个分支是失败的,然后让分支之后的后继指令执行,如果“运气好”,分支真的失败了,后继指令本来就是分支失败时候执行的,我们只是提前了一个cycle执行它,不会有什么问题,所有后续流水线照常执行,但如果我们预测分支失败但实际上分支成功了,看图3.27 b里面分支指令在ID阶段时,指令i+1已经在IF阶段了,这个指令i+1是分支失败应该执行的后继指令,虽然我们对这个后继指令取指了,但是我们后面就让这条指令不要再走了,把这个失败后继指令变成idle,我们跳到分支目标指令去执行)
综上所述,预测分支失败时,如果分支真失败了,不会发生停顿(stall),但是如果预测分支失败,分支成功了,就会发生一个停顿(stall)。
(2) 预测分支成功
这种方法按分支成功的假设进行处理。当流水线 ID 段检测到分支指令后,一旦计算出了分支目标地址,就开始从该目标地址取指令执行。
在前述 5 段流水线中,由于判断分支是否成功与分支目标地址计算是在同一流水段(ID阶段)完成的,所以这种方法对减少该流水线的分支延迟没有任何好处。但在其他的一些流水线处理机中,特别是那些具有隐含设置条件码或分支条件更复杂(因而更慢)的流水线处理机中,在确定分支是否成功之前.就能得到分支的目标地址。这时采用这种方法便可以减少分支延迟。
(3) 延迟分支(Delayed Branch)/分支延迟槽(Delayed Branch slot)
这种方法的主要思想是从逻辑上“延长”分支指令的执行时间。把延迟分支看成由原来的分支指令和若干个延迟槽构成。不管分支是否成功,都要按顺序执行延迟槽中的指令。在采用延迟分支的实际计算机中,绝大多数的延迟槽都是一个,即
- 分支指令
- 延迟槽中的指令
- 后继指令
后面只讨论这种情况。
在这种情况下,流水线的执行情况如图 3.28 所示。可以看出,只要分支延迟槽中的指令是有用的,流水线中就没有出现停顿,这时延迟分支的方法能很好地减少分支延迟。
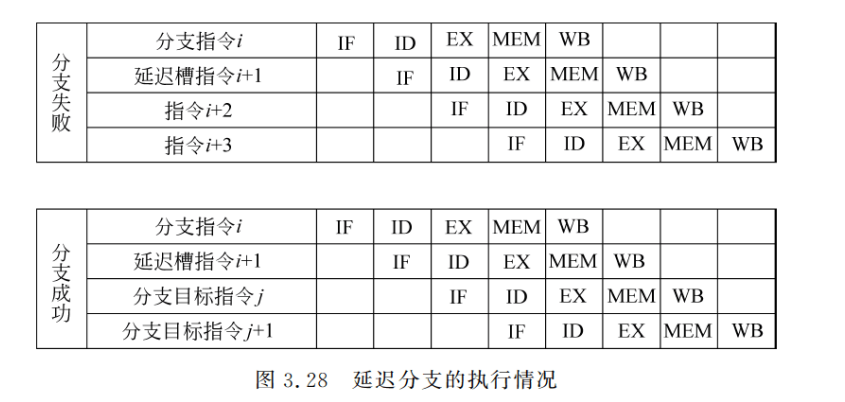
放入延迟槽中的指令是由编译器来选择的。实际上延迟分支能否带来好处完全取决于编译器能否把有用的指令调度到延迟槽中。这也是一种指令调度技术。常用的调度方法有三种:从前调度、从目标处调度、从失败处调度,如图 3.29 所示。图中,上面的代码是调度前的,下面的代码是调度后的。
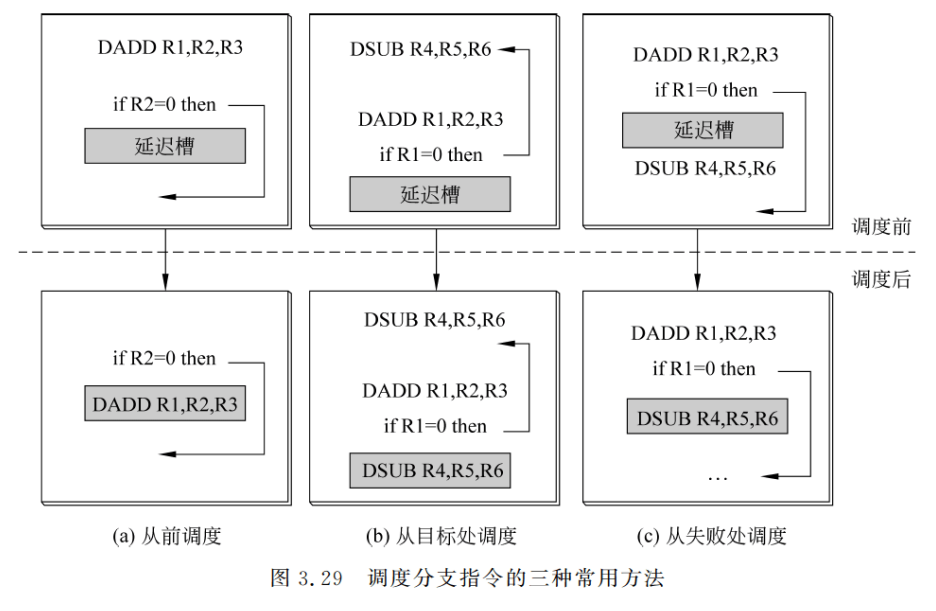
图 3.29(a)表示的是从前调度,它把位于分支指令之前的一条独立的指令移到延迟槽当无法采用从前调度时,就采用另外两种方法。图 3.29(b)表示的是从目标处调度,它把目标处的指令复制到延迟槽。同时,还要修改分支指令的目标地址,如图 3.29(b)中的箭头所示。之所以是复制到延迟槽,而不是把该指令移过去,是因为从别的路径可能也要执行到该指令。从目标处调度实际上是猜测了分支是成功的。所以当分支成功概率比较高时(例如循环转移),采用这种方法比较好;否则,采用从失败处调度比较好(见图 3.29©)。需要注意的是,当猜测错误时,要保证图 3.29(b)和图 3.29©中调度到延迟槽中的指令的执行不会影响程序的正确性(当然,这时延迟槽中的指令是无用的)。在图 3.29(b)和图 3.29©的指令序列中,由于分支指令是使用 R1 来判断的,所以不能把产生 R1 的值的 DADD 指令调度到延迟槽。
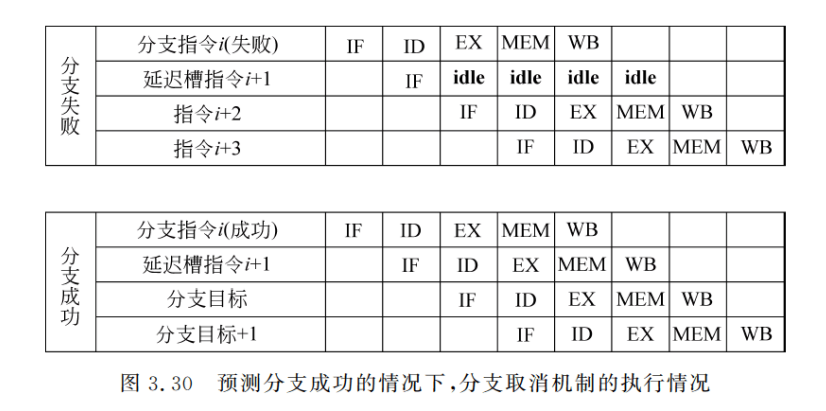
上述方法受到两个因素的限制,一个是可以被放入延迟槽中的指令要满足一定的条件:另一个是编译器预测分支转移方向的能力。为了提高编译器在延迟槽中放入有用指令的能力,许多处理机采用了分支取消(canceling 或 nullifying)机制。在这种机制中,分支指令隐含了预测的分支执行方向。当分支的实际执行方向和事先所预测的一样时,执行分支延迟槽中的指令;否则就将该指令转化成空操作。图 3.30 给出了预测分支成功的情况下,分支取消机制在分支成功和失败两种情况下的执行过程。

![[CustomMessages] section](https://img-blog.csdnimg.cn/direct/9573978ebfe2476b8b35e1346e7931e1.png)