源码基于:Linux 5.4
约定:
- 芯片架构:ARM64
- 内存架构:UMA
- CONFIG_ARM64_VA_BITS:39
- CONFIG_ARM64_PAGE_SHIFT:12
- CONFIG_PGTABLE_LEVELS :3
0. 前言
之前在《Linux DMA... 零拷贝》博文分享了DMA 技术和零拷贝技术,在进行I/O设备和内存的数据传输的时候,数据搬运的工作全部交给DMA 控制器,而CPU 不再参与任何与数据搬运相关的事情,这样CPU就可以去处理别的事务。
用户层与外设或子系统可能需要大量数据交互,这样就需要大量的内存,而随着系统的长时间运行,物理内存可能存在大量的碎片,想要申请很大的一块物理内存已经成为奢望。并且,从性能方面考虑,用户层和子系统都希望减少交互的次数,更希望一次性将数据都交给 DMA控制器搬运。这就诞生了 scatterlist 的概念。
scatterlist 是 Linux 内核关于内存比较核心数据结构,翻译为 “离散列表”,根据实际使用场景更确切可以理解为 “物理内存的离散列表”,就是通过这个 scatterlist 将物理不同大小的物理内存链接起来,一次性送给 DMA 控制器搬运。
因为光有离散还不够,还需要将这些离散收集,所以在 Linux kernel 中,会看到很多 sg 的名字,这就是 scatter-gather 的缩写。
本文将详细剖析 scatterlist 的原理和使用。
1. 数据结构
1.1 struct sg_table
include/linux/scatterlist.h
struct sg_table {
struct scatterlist *sgl; /* the list */
unsigned int nents; /* number of mapped entries */
unsigned int orig_nents; /* original size of list */
};如本文的第2 节,分配、初始化sg_table时,会传入需要申请的 sg 数量。为了性能,这些 sg 在申请的时候不是一个一个申请,而是一堆一堆的 sg 数组方式申请,这个sg 数组允许的最大值为SG_MAX_SINGLE_ALLOC:
#define SG_MAX_SINGLE_ALLOC (PAGE_SIZE / sizeof(struct scatterlist))即,每次申请最后可以申请 SG_MAX_SINGLE_ALLOC 个sg (即一个page)。每个sg 结构体是32 bytes,所以系统允许一次性申请 sg 个数为 4096 / 32 = 128 个;
sgl:每次申请的 sg 数组内部的物理内存是连续的,但每个 sg数组的首地址可能不相同,所以需要连接起来。sgl 就是用来串联每个 sg 数组;
orig_nents:sgl 中有效的 sg 个数。这里之所以说到 “有效”,是因为 sg 数组的最后一个都用来串联使用;
nents:mapped entries;
sg_table的 sgl 管理图如下:
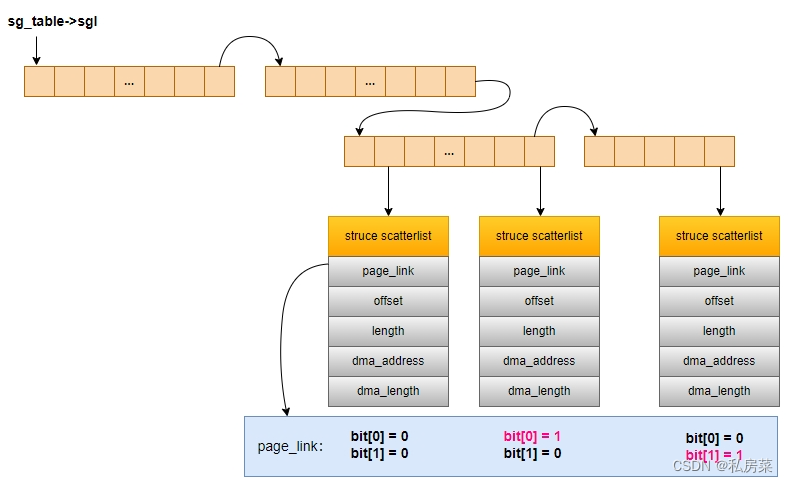
如图,假设这里有 4 个 sg 数组:
- 第一个sg 数组的首地址会存入 sg_table 的 sql 中;
- 每一个 sg 数组的最后一个 sg 为sg 铰链(chain),指向下一个 sg 数组,其成员page_link 的 bit[0] 和 bit[1] 将作为铰链的状态:
- 若都为0,表示其为有效的、普通的 sg;
- 若 bit[0] = 1表示该sg 为铰链 sg;
- 若 bit[1] = 1表示该sg为 结束sg;
1.1 struct scatterlist
include/linux/scatterlist.h
struct scatterlist {
unsigned long page_link;
unsigned int offset;
unsigned int length;
dma_addr_t dma_address;
#ifdef CONFIG_NEED_SG_DMA_LENGTH
unsigned int dma_length;
#endif
};page_link:
- 对于chain sg 来说,记录下一个 SG 数组的首地址,并且用bit[0] 和 bit[1] 来表示是chain sg 还是 end sg;
- 对于 end sg 来说,只有bit[1] 为1,其他无意义;
- 对于普通 sg 来说,记录的是关联的内存页块的地址;
为什么可以使用 bit[0] 和 bit[1] ?
- 当一次分配 sg个数为 SG_MAX_SINGLE_ALLOC,将从 buddy中分配 1 个page,该页块的首地址是页对齐的,此地址 bit[0] ~ bit[11] 都为0,所以其中 bit[0] 和 big[1] 可以另作他用;
- 而当分配的 sg 数量不够SG_MAX_SINGLE_ALLOC,则会从 kmalloc 中分配 object,但这个 object 所在的slab 也是页对齐的,而 struct scatterlist 为 32 个字节,所以该 object 的首地址的 bit[0] ~ bit[4] 都为0,所以其中 bit[0] 和 big[1] 也可以另作他用。
offset:关联页块的页内偏移量;
length:关联的内存页块大小;
dma_address:
dma_length:
2. sg_alloc_table()
lib/scatterlist.c
int sg_alloc_table(struct sg_table *table, unsigned int nents, gfp_t gfp_mask)
{
int ret;
ret = __sg_alloc_table(table, nents, SG_MAX_SINGLE_ALLOC,
NULL, 0, gfp_mask, sg_kmalloc);
if (unlikely(ret))
__sg_free_table(table, SG_MAX_SINGLE_ALLOC, 0, sg_kfree);
return ret;
}
EXPORT_SYMBOL(sg_alloc_table);参数:
- table:sg_table 的地址;
- nents:sgl 的个数,根据此值创建nents 个sg;
- gfp_mask:进行sg_kmalloc() 时需要的分配掩码;
该函数核心调用的是 __sg_alloc_table(),其中有两个参数:
- sg_kmalloc:回调函数,用以批量分配 sg 的内存;
- SG_MAX_SINGLE_ALLOC:系统规定了每次 sg_kmalloc 的最大个数,即每次批量申请的sg 总内存最多为 1个 page,每个sg 结构体是32 bytes,所以系统允许一次性申请 sg 个数为 4096 / 32 = 128 个;
2.1 __sg_alloc_table()
lib/scatterlist.c
int __sg_alloc_table(struct sg_table *table, unsigned int nents,
unsigned int max_ents, struct scatterlist *first_chunk,
unsigned int nents_first_chunk, gfp_t gfp_mask,
sg_alloc_fn *alloc_fn)
{
struct scatterlist *sg, *prv;
unsigned int left;
unsigned curr_max_ents = nents_first_chunk ?: max_ents;
unsigned prv_max_ents;
//准备初始化 sg_table,先memset
memset(table, 0, sizeof(*table));
//sg 条目数量不能为0
if (nents == 0)
return -EINVAL;
#ifdef CONFIG_ARCH_NO_SG_CHAIN
if (WARN_ON_ONCE(nents > max_ents))
return -EINVAL;
#endif
//初始化还没有申请的sg数目
left = nents;
prv = NULL;
do {
unsigned int sg_size, alloc_size = left;
//确定此次需要申请的sg 个数
//申请的sg超过最大值,将分多次分配
if (alloc_size > curr_max_ents) {
alloc_size = curr_max_ents;
sg_size = alloc_size - 1; //申请的sg数组中,最后一个作为一个chain,不作为有效sg
} else
sg_size = alloc_size;
//还剩余多少sg没有申请
left -= sg_size;
if (first_chunk) {
sg = first_chunk;
first_chunk = NULL;
} else {
sg = alloc_fn(alloc_size, gfp_mask); //调用sg分配的回调函数
}
if (unlikely(!sg)) {
/*
* Adjust entry count to reflect that the last
* entry of the previous table won't be used for
* linkage. Without this, sg_kfree() may get
* confused.
*/
if (prv)
table->nents = ++table->orig_nents;
return -ENOMEM;
}
/*
* 初始化此次申请的sg 数组,这些sg 在物理上是连续的,所以可以直接memset
* 另外,还会调用sg_mark_end() 初始化最后一个sg为 end sg
*/
sg_init_table(sg, alloc_size);
//更新sg_table->nents,初始化时 nents和orig_nents相同
table->nents = table->orig_nents += sg_size;
/*
* 当再次进入循环时,说明需要的nents是大于max_nents的,那么上一次申请肯定是按照最大值
* 申请.
* 第一次申请时,会将sg数组放入sg_table的sgl
* 当再进入循环时,需要连接新建的sg数组,所以要将prv的最后一个sg设为CHAIN
*/
if (prv)
sg_chain(prv, prv_max_ents, sg);
else
table->sgl = sg;
//如果没剩余sg需要分配了,将推出循环,此时将最新分配的sg数组的最后一个sg设为END
if (!left)
sg_mark_end(&sg[sg_size - 1]);
prv = sg;
prv_max_ents = curr_max_ents; //能进入下一个循环的话,上一个sg数组肯定按最大值申请的
curr_max_ents = max_ents;
} while (left);
return 0;
}
EXPORT_SYMBOL(__sg_alloc_table);2.2 sg_kmalloc()
lib/scatterlist.c
static struct scatterlist *sg_kmalloc(unsigned int nents, gfp_t gfp_mask)
{
if (nents == SG_MAX_SINGLE_ALLOC) {
/*
* Kmemleak doesn't track page allocations as they are not
* commonly used (in a raw form) for kernel data structures.
* As we chain together a list of pages and then a normal
* kmalloc (tracked by kmemleak), in order to for that last
* allocation not to become decoupled (and thus a
* false-positive) we need to inform kmemleak of all the
* intermediate allocations.
*/
void *ptr = (void *) __get_free_page(gfp_mask);
kmemleak_alloc(ptr, PAGE_SIZE, 1, gfp_mask);
return ptr;
} else
return kmalloc_array(nents, sizeof(struct scatterlist),
gfp_mask);
}函数比较简单,当申请的时候按照 SG_MAX_SINGLE_ALLOC,那么是一次性申请 4K 内存,系统直接调用 __get_free_page() 从buddy 中分配;当没有达到 4K 内存,则通过 kmalloc_array() 申请 ;
3. sg_free_table()
lib/scatterlist.c
void sg_free_table(struct sg_table *table)
{
__sg_free_table(table, SG_MAX_SINGLE_ALLOC, false, sg_kfree);
}
EXPORT_SYMBOL(sg_free_table);是sg_alloc_table() 的逆过程,唯一不同的是回调函数换成 sg_kfree()。
3.1 __sg_free_table()
lib/scatterlist.c
void __sg_free_table(struct sg_table *table, unsigned int max_ents,
unsigned int nents_first_chunk, sg_free_fn *free_fn)
{
struct scatterlist *sgl, *next;
unsigned curr_max_ents = nents_first_chunk ?: max_ents;
if (unlikely(!table->sgl))
return;
sgl = table->sgl;
while (table->orig_nents) {
unsigned int alloc_size = table->orig_nents; //sg_table中还有多少个sg
unsigned int sg_size;
/**
* 如果sg_table中sg大于max,取出下一个sg 数组的首地址存入next,
* 如果sg_table中所剩不够max,那这应该是最后一个sg数组了
*/
if (alloc_size > curr_max_ents) {
next = sg_chain_ptr(&sgl[curr_max_ents - 1]);
alloc_size = curr_max_ents;
sg_size = alloc_size - 1;
} else {
sg_size = alloc_size;
next = NULL;
}
table->orig_nents -= sg_size;
if (nents_first_chunk)
nents_first_chunk = 0;
else
free_fn(sgl, alloc_size); //调用释放回调函数
sgl = next;
curr_max_ents = max_ents;
}
table->sgl = NULL;
}
EXPORT_SYMBOL(__sg_free_table);
3.2 sg_kfree()
lib/scatterlist.c
static void sg_kfree(struct scatterlist *sg, unsigned int nents)
{
if (nents == SG_MAX_SINGLE_ALLOC) {
kmemleak_free(sg);
free_page((unsigned long) sg);
} else
kfree(sg);
}该函数是 sg_kmalloc() 的逆过程,当申请 sg 按照SG_MAX_SINGLE_ALLOC,则该sg 数组是从 buddy 申请,所以调用 free_page() 归还给 buddy;当不是按照 SG_MAX_SINGLE_ALLOC,则是从 kmalloc() 申请得来的,所以调用 kfree() 归还给kmalloc。
4. 其他 API
4.1 sg_mark_end()
include/linux/scatterlist.h
static inline void sg_mark_end(struct scatterlist *sg)
{
/*
* Set termination bit, clear potential chain bit
*/
sg->page_link |= SG_END;
sg->page_link &= ~SG_CHAIN;
}清除bit[0] 中的 chain 标识,配上 bit[1] 上的 END 标识,即将该 sg 配置为 END;
4.2 sg_unmark_end()
include/linux/scatterlist.h
static inline void sg_unmark_end(struct scatterlist *sg)
{
sg->page_link &= ~SG_END;
}解除 END 标识;
4.3 sg_chain()
include/linux/scatterlist.h
static inline void sg_chain(struct scatterlist *prv, unsigned int prv_nents,
struct scatterlist *sgl)
{
/*
* offset and length are unused for chain entry. Clear them.
*/
prv[prv_nents - 1].offset = 0;
prv[prv_nents - 1].length = 0;
/*
* Set lowest bit to indicate a link pointer, and make sure to clear
* the termination bit if it happens to be set.
*/
prv[prv_nents - 1].page_link = ((unsigned long) sgl | SG_CHAIN)
& ~SG_END;
}用以配置铰链 sg,offset 和 length 为0,通过该函数将当前的sg 数组与下一个 sg 数组通过 chain sg 捆绑在一起。
4.4 sg_set_page()
include/linux/scatterlist.h
static inline void sg_set_page(struct scatterlist *sg, struct page *page,
unsigned int len, unsigned int offset)
{
sg_assign_page(sg, page);
sg->offset = offset;
sg->length = len;
}本函数用以将当前 sg 与内存页块进行关联。
参数:
- sg:当前 sg;
- page:需要关联的内存页块;
- len:页块的大小;
- offset:页块内偏移量;
4.5 sg_assign_page()
include/linux/scatterlist.h
static inline void sg_assign_page(struct scatterlist *sg, struct page *page)
{
unsigned long page_link = sg->page_link & (SG_CHAIN | SG_END);
/*
* In order for the low bit stealing approach to work, pages
* must be aligned at a 32-bit boundary as a minimum.
*/
BUG_ON((unsigned long) page & (SG_CHAIN | SG_END));
#ifdef CONFIG_DEBUG_SG
BUG_ON(sg_is_chain(sg));
#endif
sg->page_link = page_link | (unsigned long) page;
}本函数用以将当前 sg->page_link 重新关联到新的内存页块,但保留之前的bit[0] 和 bit[1] 属性;
参数:
- sg:当前 sg;
- page:需要关联的内存页块;
4.6 判断chain/last
//判断当前sg是否为chain
#define sg_is_chain(sg) ((sg)->page_link & SG_CHAIN)
//判断当前sg是否为last
#define sg_is_last(sg) ((sg)->page_link & SG_END)4.7 获取sg和page
//chain sg用来获取下一个指向的sg数组
#define sg_chain_ptr(sg) \
((struct scatterlist *) ((sg)->page_link & ~(SG_CHAIN | SG_END)))
//获取sg关联的页块地址
static inline struct page *sg_page(struct scatterlist *sg)
{
#ifdef CONFIG_DEBUG_SG
BUG_ON(sg_is_chain(sg));
#endif
return (struct page *)((sg)->page_link & ~(SG_CHAIN | SG_END));
}参考博客:
ION 内存管理器——system heap
DMA 与 scatterlist 技术简介