文章目录
5.1 磁盘调度算法
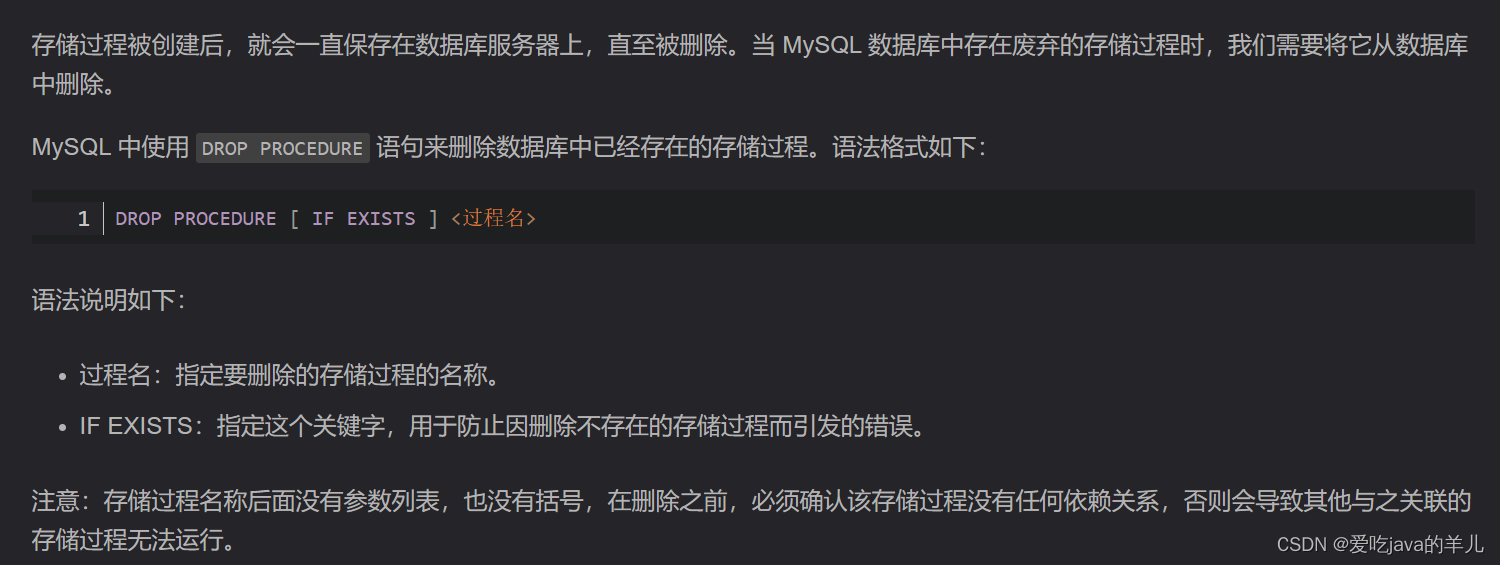
1. 先来先服务算法( First Come First Served, FCFS) 算法
顾名思义,先到来的请求,先被服务。
2. 最短寻道时间优先算法( Shortest Seek Time First, SSTF) 算法
最短寻道时间优先(Shortest Seek First,SSF)算法的工作方式是,优先选择从当前磁头位置所需寻道时间最短的请求。
3. 扫描算法( SCAN ) 算法
最短寻道时间优先算法会产生饥饿的原因在于:磁头有可能再一个小区域内来回得移动。
为了防止这个问题,可以规定:磁头在一个方向上移动,访问所有未完成的请求,直到磁头到达该方向上的最后的磁道,才调换方向,这就是扫描(Scan)算法。
这种算法也叫做电梯算法,比如电梯保持按一个方向移动,直到在那个方向上没有请求为止,然后改变方向。
4. 循环扫描算法( Circular Scan, CSCAN ) 算法
循环扫描(Circular Scan, CSCAN )规定:只有磁头朝某个特定方向移动时,才处理磁道访问请求,而返回时直接快速移动至最靠边缘的磁道,也就是复位磁头,这个过程是很快的,并且返回中途不处理任何请求,该算法的特点,就是磁道只响应一个方向上的请求。
5. LOOK 与 CLOOK 算法
我们前面说到的扫描算法和循环扫描算法,都是磁头移动到磁盘「最始端或最末端」才开始调换方向。
那这其实是可以优化的,优化的思路就是磁头在移动到「最远的请求」位置,然后立即反向移动。
那针对 SCAN 算法的优化则叫 LOOK 算法,它的工作方式,磁头在每个方向上仅仅移动到最远的请求位置,然后立即反向移动,而不需要移动到磁盘的最始端或最末端,反向移动的途中会响应请求。
5.2 进程写文件时,进程发生了崩溃,已写入的数据会丢失吗?
大概就是,进程写文件(使用缓冲 IO)过程中,写一半的时候,进程发生了崩溃,已写入的数据会丢失吗?
答案,是不会的。
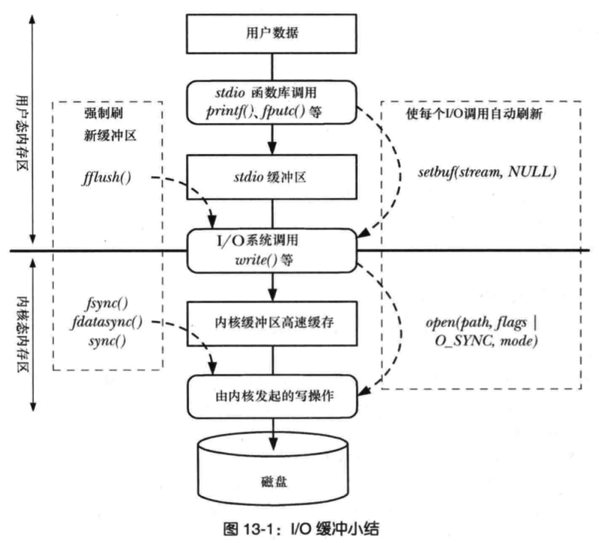
因为进程在执行 write (使用缓冲 IO)系统调用的时候,实际上是将文件数据写到了内核的 page cache,它是文件系统中用于缓存文件数据的缓冲,所以即使进程崩溃了,文件数据还是保留在内核的 page cache,我们读数据的时候,也是从内核的 page cache 读取,因此还是依然读的进程崩溃前写入的数据。
内核会找个合适的时机,将 page cache 中的数据持久化到磁盘。但是如果 page cache 里的文件数据,在持久化到磁盘化到磁盘之前,系统发生了崩溃,那这部分数据就会丢失了。
当然, 我们也可以在程序里调用 fsync 函数,在写文文件的时候,立刻将文件数据持久化到磁盘,这样就可以解决系统崩溃导致的文件数据丢失的问题。
7.2 进程写文件时,进程发生了崩溃,已写入的数据会丢失吗?
5.3 进程写文件时,断电了,文件内容会丢失吗?
写文件的时候,操作系统为了加快写的效率,通常会使用 page cache 技术,也就是先把数据写到内存,然后在某个时机再进行统一刷盘,已到达空间换时间的目的。
如果在写的过程中,断电了,存在内存中的数据是会丢失的,至于丢失多少,主要取决于刷盘的时机,也就是 kernel 的参数(可以使用 sysctl -a | grep dirty )进行查看。
5.4 Linux 脏页刷盘的参数有哪些?
-

-
如上参数分三组,任何一组参数的条件满足即会将脏数据刷新到磁盘
1. 根据脏数据的绝对大小
vm.dirty_background_bytes: 触发会刷的脏数据大小,单位:byte,默认:0vm.dirty_bytes: 触发回刷的脏数据大小(会阻塞应用进程异步写数据到cache),默认:0
2. 根据脏数据占可用内存的比例
vm.dirty_background_ratio : 内存中脏数据达到系统可用内存的百分比时,会触发内核会启 flush进程将内存中的脏数据刷新到磁盘。此时应用进程不会被阻塞。默认:10
vm.dirty_ratio : 内存中脏数据达到系统可用内存的百分比时,会触发使系统不得不开始处理缓存脏页(因为此时脏页数量已经比较多,为了避免数据丢失需要将一定脏页刷入外存);在此过程中很多应用进程可能会因为OS处理文件IO而阻塞。默认:20
PS:XXX_bytes 参数如果设置,则XXX_ratio的参数会被忽略
3. 定时起线程刷新
vm.dirty_expire_centisecs : 脏数据超时回刷时间。下一次刷新线程唤醒时,内存中脏数据的时间超过此间隔的数据将会刷新到磁盘 。单位:1/100s,默认:3000,
dirty_writeback_centisecs : 脏数据回刷进程定期唤醒时间,单位:1/100s,默认:500

![BUUCTF [ACTF新生赛2020]swp 1](https://img-blog.csdnimg.cn/direct/fb6afa02cddb4c9282c6cd8f858e850f.png)