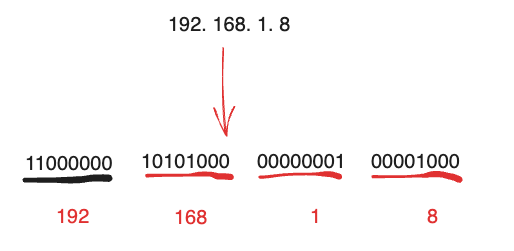
keys * 这个命令千万别在生产环境乱用,危险级别不亚于flushdb。因为Redis是单线程操作,在数据特别庞大的情况下。Keys会引发Redis锁(数据过多一直查询处理),并且增加Redis的CPU占用。很多公司的运维都是禁止了这个命令的
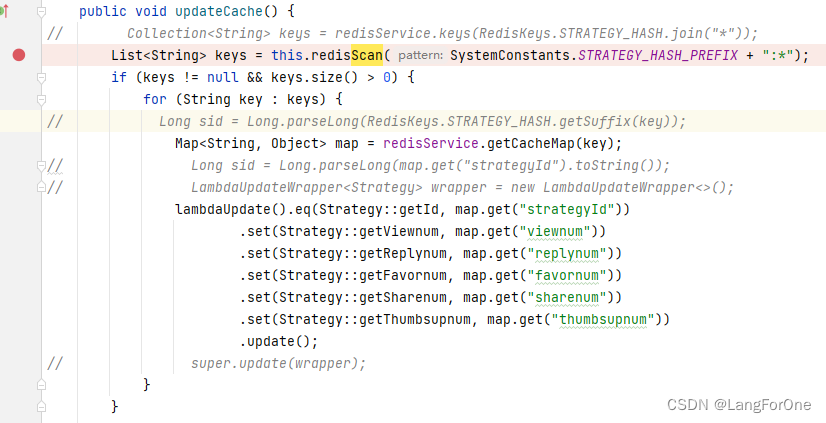
当需要扫描key,匹配出自己需要的key时,可以使用 scan 命令
scan操作的Helper实现
import java.io.IOException;
import java.nio.charset.StandardCharsets;
import java.util.ArrayList;
import java.util.List;
import java.util.function.Consumer;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.redis.connection.RedisConnection;
import org.springframework.data.redis.core.Cursor;
import org.springframework.data.redis.core.ScanOptions;
import org.springframework.data.redis.core.StringRedisTemplate;
import org.springframework.stereotype.Component;
@Component
public class RedisHelper {
@Autowired
private StringRedisTemplate stringRedisTemplate;
/**
* scan 实现
* @param pattern 表达式
* @param consumer 对迭代到的key进行操作
*/
public void scan(String pattern, Consumer<byte[]> consumer) {
this.stringRedisTemplate.execute((RedisConnection connection) -> {
try (Cursor<byte[]> cursor = connection.scan(ScanOptions.scanOptions().count(Long.MAX_VALUE).match(pattern).build())) {
cursor.forEachRemaining(consumer);
return null;
} catch (IOException e) {
e.printStackTrace();
throw new RuntimeException(e);
}
});
}
/**
* 获取符合条件的key
* @param pattern 表达式
* @return
*/
public List<String> keys(String pattern) {
List<String> keys = new ArrayList<>();
this.scan(pattern, item -> {
//符合条件的key
String key = new String(item,StandardCharsets.UTF_8);
keys.add(key);
});
return keys;
}
}
demo写到这步已经可以用了,注意传参的String pattern是要带*号的,比如我想查user_info:1、user_info:2等等数据,则匹配user_info:前缀(redis的key最好用枚举类+定义常量),此时传参的pattern即为"user_info:* "
但此demo会有一个问题:没法移动cursor,也只能scan一次,并且容易导致redis链接报错。
之后的优化思路和手段请见:
在RedisTemplate中使用scan代替keys指令




![[NOIP2016 普及组] 回文日期](https://img-blog.csdnimg.cn/direct/c0495f9f05004418816f008697a54536.png)