python pytorch实现RNN,LSTM,GRU,文本情感分类
数据集格式:
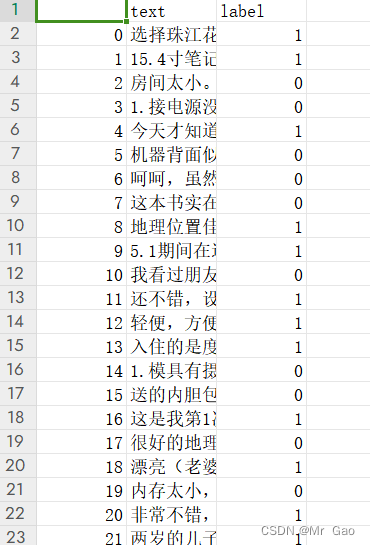
有需要的可以联系我
实现步骤就是:
1.先对句子进行分词并构建词表
2.生成word2id
3.构建模型
4.训练模型
5.测试模型
代码如下:
import pandas as pd
import torch
import matplotlib.pyplot as plt
import jieba
import numpy as np
"""
作业:
一、完成优化
优化思路
1 jieba
2 取常用的3000字
3 修改model:rnn、lstm、gru
二、完成测试代码
"""
# 了解数据
dd = pd.read_csv(r'E:\peixun\data\train.csv')
# print(dd.head())
# print(dd['label'].value_counts())
# 句子长度分析
# 确定输入句子长度为 500
text_len = [len(i) for i in dd['text']]
# plt.hist(text_len)
# plt.show()
# print(max(text_len), min(text_len))
# 基本参数 config
DEVICE = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print('my device:', DEVICE)
MAX_LEN = 500
BATCH_SIZE = 16
EPOCH = 1
LR = 3e-4
# 构建词表 word2id
vocab = []
for i in dd['text']:
vocab.extend(jieba.lcut(i, cut_all=True)) # 使用 jieba 分词
# vocab.extend(list(i))
vocab_se = pd.Series(vocab)
print(vocab_se.head())
print(vocab_se.value_counts().head())
vocab = vocab_se.value_counts().index.tolist()[:3000] # 取频率最高的 3000 token
# print(vocab[:10])
# exit()
WORD_PAD = "<PAD>"
WORD_UNK = "<UNK>"
WORD_PAD_ID = 0
WORD_UNK_ID = 1
vocab = [WORD_PAD, WORD_UNK] + list(set(vocab))
print(vocab[:10])
print(len(vocab))
vocab_dict = {k: v for v, k in enumerate(vocab)}
# 词表大小,vocab_dict: word2id; vocab: id2word
print(len(vocab_dict))
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.utils import data
import pandas as pd
# 定义数据集 Dataset
class Dataset(data.Dataset):
def __init__(self, split='train'):
# ChnSentiCorp 情感分类数据集
path = r'E:/peixun/data/' + str(split) + '.csv'
self.data = pd.read_csv(path)
def __len__(self):
return len(self.data)
def __getitem__(self, i):
text = self.data.loc[i, 'text']
label = self.data.loc[i, 'label']
return text, label
# 实例化 Dataset
dataset = Dataset('train')
# 样本数量
print(len(dataset))
print(dataset[0])
# 句子批处理函数
def collate_fn(batch):
# [(text1, label1), (text2, label2), (3, 3)...]
sents = [i[0][:MAX_LEN] for i in batch]
labels = [i[1] for i in batch]
inputs = []
# masks = []
for sent in sents:
sent = [vocab_dict.get(i, WORD_UNK_ID) for i in list(sent)]
pad_len = MAX_LEN - len(sent)
# mask = len(sent) * [1] + pad_len * [0]
# masks.append(mask)
sent += pad_len * [WORD_PAD_ID]
inputs.append(sent)
# 只使用 lstm 不需要用 masks
# masks = torch.tensor(masks)
# print(inputs)
inputs = torch.tensor(inputs)
labels = torch.LongTensor(labels)
return inputs.to(DEVICE), labels.to(DEVICE)
# 测试 loader
loader = data.DataLoader(dataset,
batch_size=BATCH_SIZE,
collate_fn=collate_fn,
shuffle=True,
drop_last=False)
inputs, labels = iter(loader).__next__()
print(inputs.shape, labels)
# 定义模型
class Model(nn.Module):
def __init__(self, vocab_size=5000):
super().__init__()
self.embed = nn.Embedding(vocab_size, 100, padding_idx=WORD_PAD_ID)
# 多种 rnn
self.rnn = nn.RNN(100, 100, 1, batch_first=True, bidirectional=True)
self.gru = nn.GRU(100, 100, 1, batch_first=True, bidirectional=True)
self.lstm = nn.LSTM(100, 100, 1, batch_first=True, bidirectional=True)
self.l1 = nn.Linear(500 * 100 * 2, 100)
self.l2 = nn.Linear(100, 2)
def forward(self, inputs):
out = self.embed(inputs)
out, _ = self.lstm(out)
out = out.reshape(BATCH_SIZE, -1) # 16 * 100000
out = F.relu(self.l1(out)) # 16 * 100
out = F.softmax(self.l2(out)) # 16 * 2
return out
# 测试 Model
model = Model()
print(model)
# 模型训练
dataset = Dataset()
loader = data.DataLoader(dataset,
batch_size=BATCH_SIZE,
collate_fn=collate_fn,
shuffle=True)
model = Model().to(DEVICE)
# 交叉熵损失
loss_fn = nn.CrossEntropyLoss()
optimizer = torch.optim.AdamW(model.parameters(), lr=LR)
model.train()
for e in range(EPOCH):
for idx, (inputs, labels) in enumerate(loader):
# 前向传播,计算预测值
out = model(inputs)
# 计算损失
loss = loss_fn(out, labels)
# 反向传播,计算梯度
loss.backward()
# 参数更新
optimizer.step()
# 梯度清零
optimizer.zero_grad()
if idx % 10 == 0:
out = out.argmax(dim=-1)
acc = (out == labels).sum().item() / len(labels)
print('>>epoch:', e,
'\tbatch:', idx,
'\tloss:', loss.item(),
'\tacc:', acc)
# 模型测试
test_dataset = Dataset('test')
test_loader = data.DataLoader(test_dataset,
batch_size=BATCH_SIZE,
collate_fn=collate_fn,
shuffle=False)
loss_fn = nn.CrossEntropyLoss()
out_total = []
labels_total = []
model.eval()
for idx, (inputs, labels) in enumerate(test_loader):
out = model(inputs)
loss = loss_fn(out, labels)
out_total.append(out)
labels_total.append(labels)
if idx % 50 == 0:
print('>>batch:', idx, '\tloss:', loss.item())
correct=0
sumz=0
for i in range(len(out_total)):
out = out_total[i].argmax(dim=-1)
correct = (out == labels_total[i]).sum().item() +correct
sumz=sumz+len(labels_total[i])
#acc = (out_total == labels_total).sum().item() / len(labels_total)
print('>>acc:', correct/sumz)
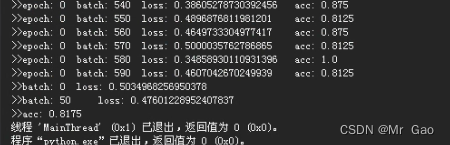
运行结果如下:



![Mybatisplus同时向两张表里插入数据[事务的一致性]](https://img-blog.csdnimg.cn/direct/fd1514bd194f41afbed78da7a890efaa.png)