一、新建环境
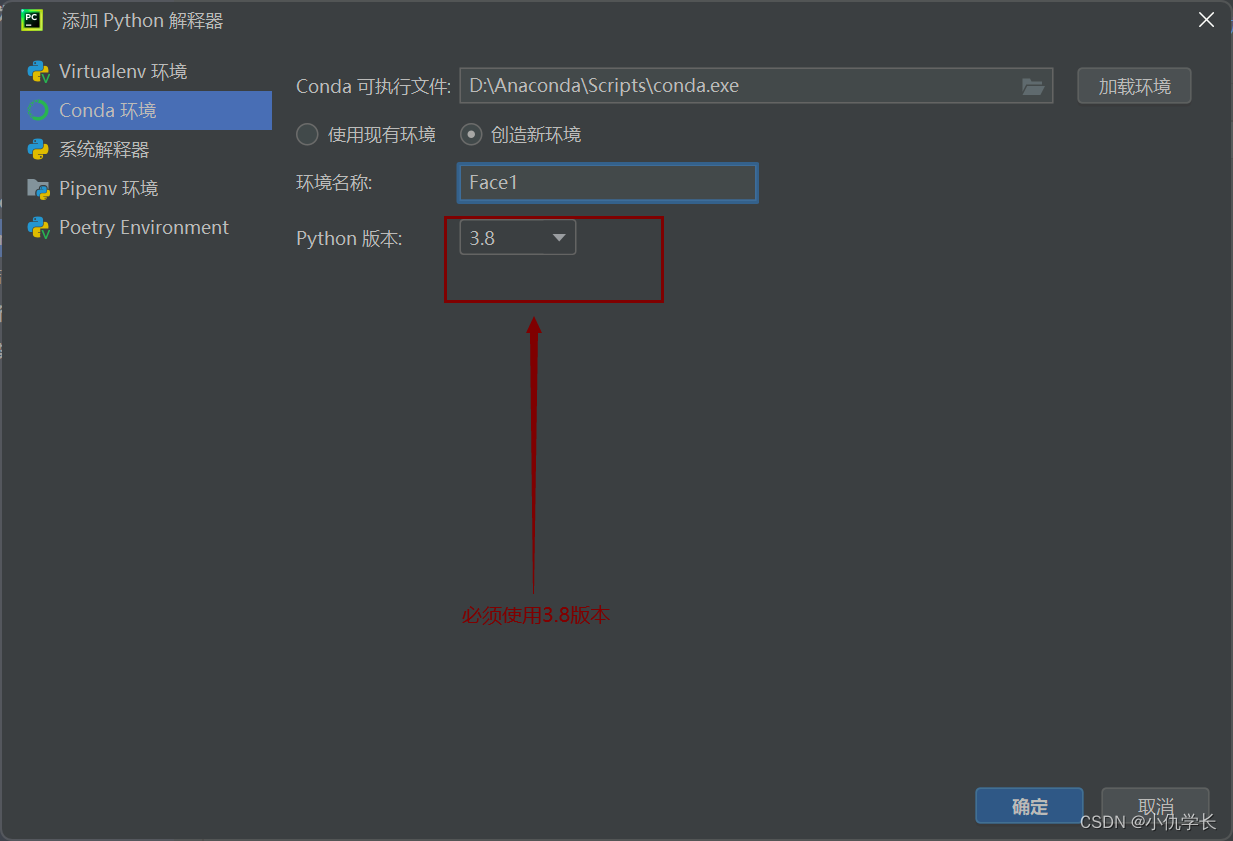
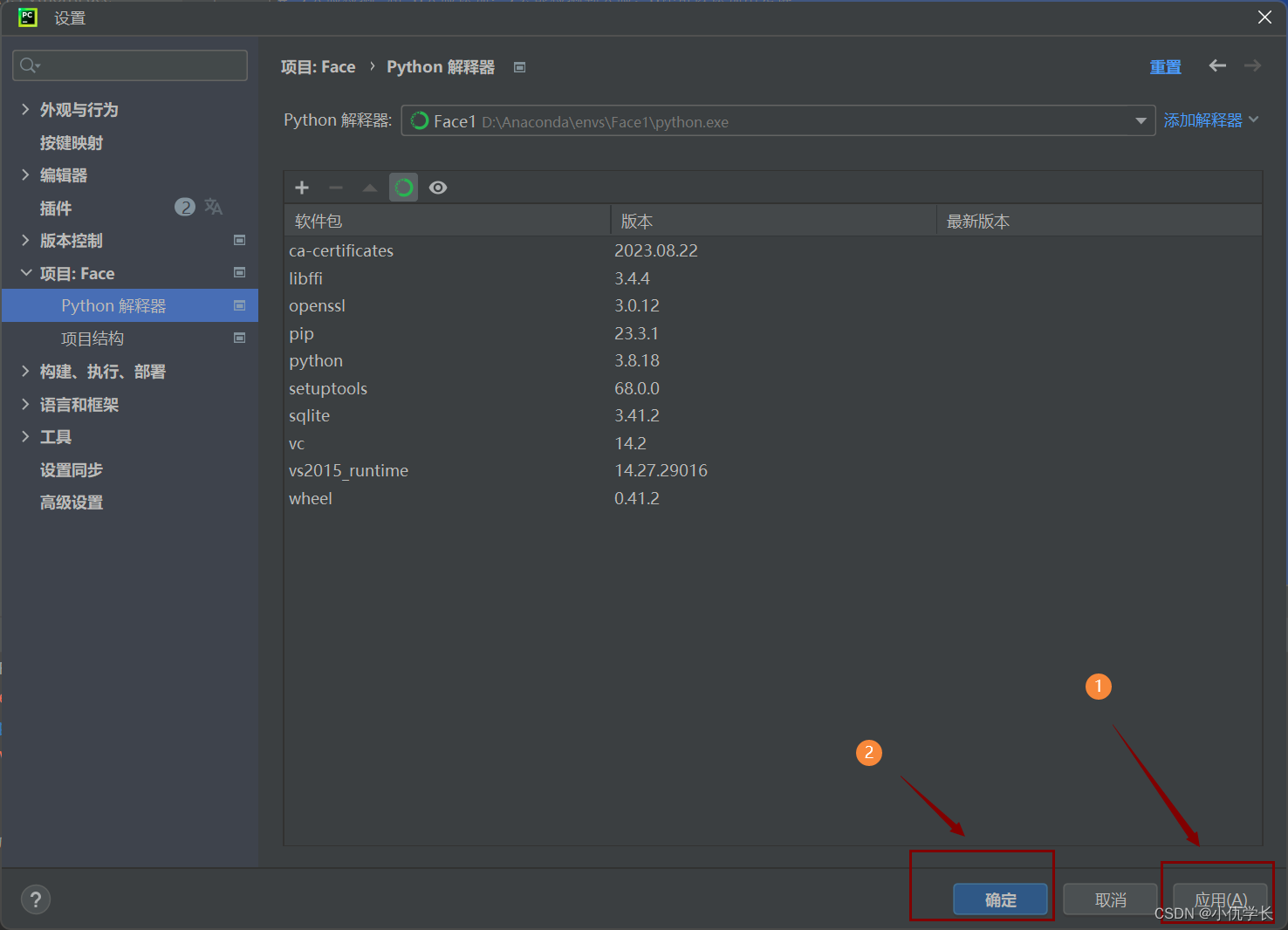
注意!!确定后需要关闭项目,重新打开,终端的环境才会变化!!
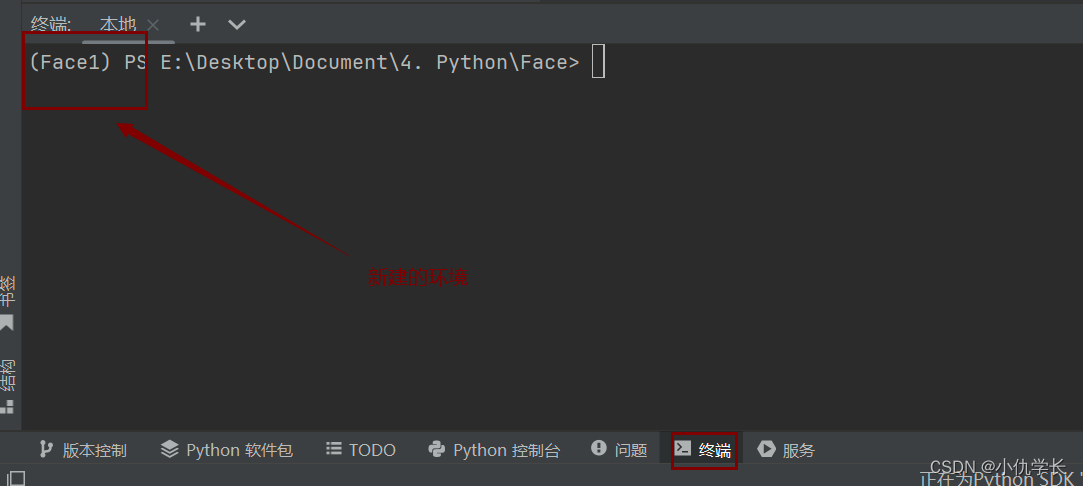
二、下载安装包(只需要3个即可)
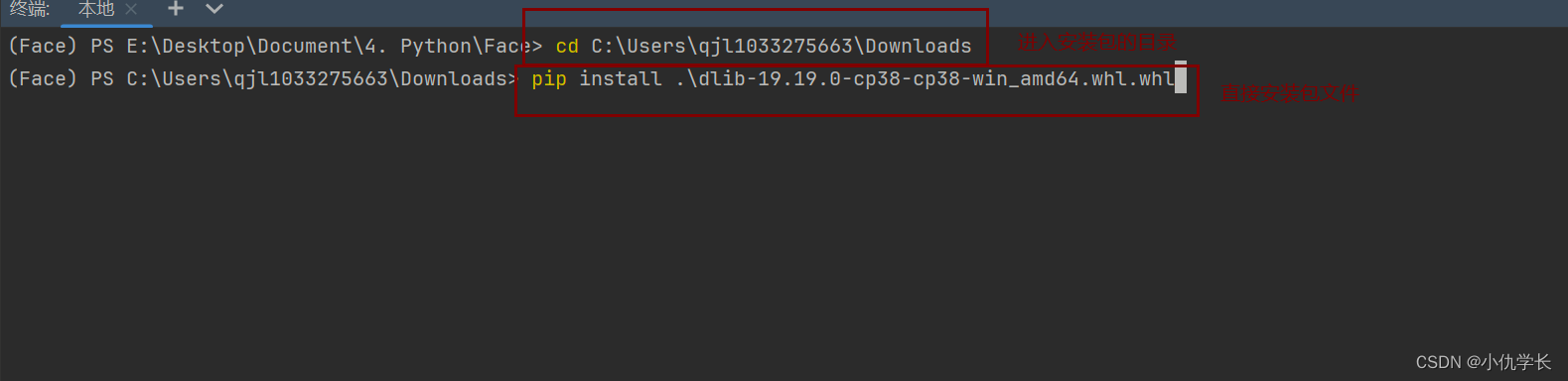
1. 下载dlib包
pip install dlib-19.19.0-cp38-cp38-win_amd64.whl.whl
这里我使用编译好的包文件。

2.下载face_recognition包
pip install face_recognition -i https://pypi.tuna.tsinghua.edu.cn/simple
3.安装opencv
pip install opencv-python -i https://pypi.tuna.tsinghua.edu.cn/simple
三、源码
import face_recognition
import cv2
import numpy as np
from PIL import Image, ImageDraw, ImageFont
known_face_names = []
known_face_encodings = []
def IsDuplicateName(name):
if name in known_face_names:
return True
return False
def AddPhoto(name, filename):
image = face_recognition.load_image_file(filename)
# 用 128 维的向量表示 1 张人脸
face_encoding = face_recognition.face_encodings(image)
if len(face_encoding) != 1:
return False
known_face_encodings.insert(0, face_encoding[0])
known_face_names.insert(0, name)
return True
def PutCNText(image, strs, local, sizes, colour):
"""
在 frame 中添加文字
"""
cv2img = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
pilimg = Image.fromarray(cv2img)
draw = ImageDraw.Draw(pilimg)
font = ImageFont.truetype("./simhei.ttf", sizes, encoding="utf-8")
draw.text(local, strs, colour, font=font)
return cv2.cvtColor(np.array(pilimg), cv2.COLOR_RGB2BGR)
def FaceRecognition(frame):
# 尺寸缩放为原来的 1/4,参数 (0, 0) 原意表示输出图像的大小
# 当指定为 (0, 0) 时,输出图像的大小会根据 fx 和 fy 参数进行计算
# 缩小图像 4 倍是为了加速人脸检测过程
small_frame = cv2.resize(frame, (0, 0), fx=0.25, fy=0.25)
# np.ascontiguousarray() 确保数组在内存中的存储是连续的
rgb_small_frame = np.ascontiguousarray(small_frame[:, :, ::-1])
# 得到检测到的人脸位置信息 face_locations
face_locations = face_recognition.face_locations(rgb_small_frame)
# 对 rgb_small_frame 中人脸进行编码,得到人脸向量 face_encodings
# 这个编码信息将用于后续的人脸比对和识别
face_encodings = face_recognition.face_encodings(rgb_small_frame, face_locations)
face_names = []
for face_encoding in face_encodings:
matches = face_recognition.compare_faces(known_face_encodings, face_encoding, tolerance=0.4)
# known_face_encodings 为列表,相同人脸为 True
name = ""
if True in matches:
first_match_index = matches.index(True)
name = known_face_names[first_match_index]
else:
name='未录入人员'
face_names.append(name)
for (top, right, bottom, left), name in zip(face_locations, face_names):
top *= 4
right *= 4
bottom *= 4
left *= 4
if name =='未录入人员':
cv2.rectangle(frame, (left, top), (right, bottom), (0, 0, 255), 2)
frame = PutCNText(frame, name, (left + 6, bottom - 24), 20, (0, 255, 255))
else:
cv2.rectangle(frame, (left, top), (right, bottom), (0, 255, 0), 2)
frame = PutCNText(frame, name, (left + 6, bottom - 24), 20, (255, 255, 255))
return frame
if __name__ == "__main__":
# 注册缓存 人名 和 人脸向量,用于后续人脸识别
AddPhoto("佳龙", "./photos/long.jpg")
video_capture = cv2.VideoCapture(0)
# 设置视频帧的 宽度 和 高度
# video_capture.set(cv2.CAP_PROP_FRAME_WIDTH, 1024) # 3
# video_capture.set(cv2.CAP_PROP_FRAME_HEIGHT, 768) # 4
# video_capture.set(cv2.CAP_PROP_FOURCC, cv2.VideoWriter_fourcc("M", "J", "P", "G"))
while video_capture.isOpened():
# 读取 1 帧视频图像
ret, frame = video_capture.read()
# print("frame.shape:", frame.shape) # frame.shape = (720, 1280, 3) 就是一张图片
# 如果读取失败,进入下一循环
if ret == False:
continue
frame = FaceRecognition(frame)
cv2.imshow("Face Recognition", frame)
# 退出条件
if cv2.waitKey(1) & 0xFF == ord("q"):
break
# 释放资源
video_capture.release()
cv2.destroyAllWindows()
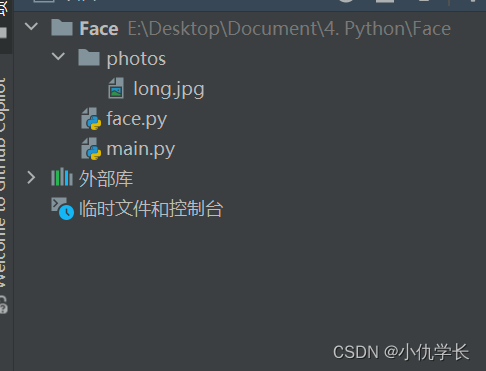
代码文件目录:



![[蓝桥杯习题]———位运算、判断二进制1个数](https://img-blog.csdnimg.cn/direct/01c827b0a04a4406a2294df52712ad02.gif#pic_center)