论文题目:
PromptRank: Unsupervised Keyphrase Extraction Using Prompt
论文日期:2023/05/15(ACL 2023)
论文地址:https://arxiv.org/abs/2305.04490
GitHub地址:https://github.com/HLT-NLP/PromptRank
文章目录
- Abstract
- 1. Introduction
- 2. Related Work
- 2.1 Unsupervised Keyphrase Extraction
- 2.2 Prompt Learning
- 3. PromptRank
- 3.1 Candidates Generation
- 3.2 Probability Calculation
- 3.3 Position Penalty Calculation
- 3.4 Candidates Ranking
- 4. Experiments
- 4.1 Datasets and Evaluation Metrics
- 4.2 Baselines and Implementation Details
- 4.3 Overall Results
- 4.4 Ablation Study
- 4.4.1 Effects of Position Penalty
- 4.4.2 Effects of Template Length
- 4.4.3 Effects of Template Content
- 4.4.4 Effects of Hyperparameter α
- 4.4.5 Effects of Hyperparameter γ
- 4.4.6 Effects of the PLM
- 4.5 Case Study
- 5. Conclusion
Abstract
关键词提取(keyphrase extraction, KPE)任务是指从给定文档中自动选择短语来概括其核心内容。基于embedding的算法最近实现了最先进的(SOTA)性能,这些算法根据候选文本的嵌入与文档嵌入的相似度对候选文本进行排序。然而这样的解决方案要么难以解决文档和候选长度的差异,要么无法充分利用没有进一步微调的预训练语言模型(PLM)。为了解决这些问题,本文提出一种简单有效的无监督方法PromptRank,基于具有encoder-decoder架构的PLM。具体来说,PromptRank将文档输入编码器,并根据设计的提示词(prompt)计算解码器生成候选词的概率。在六个广泛使用的基准上对所提出的PromptRank进行了广泛的评估。与SOTA方法的MDERank相比,PromptRank在top5、top10和top15返回结果中,F1分数分别提高了34.18%、24.87%和17.57%,这表明了使用prompt进行无监督关键词提取的巨大潜力。
1. Introduction
关键词提取旨在自动地从给定的文档中选择短语,以简洁地概括主题,帮助读者快速理解关键信息,并为后续的信息检索、文本挖掘、摘要等任务提供便利。现有的关键词提取工作可以分为有监督和无监督两类。随着深度学习的发展,有监督的关键词提取方法通过使用先进的架构取得了巨大的成功,如LSTM和Transformer。然而,有监督的方法需要大规模的标记训练数据,并且可能对新领域的泛化性很差。而无监督的关键词提取方法,主要包括基于统计(statistics-based)、基于图(graph-based)和基于嵌入(embedding-based)的方法,在工业场景中更受欢迎。
基于嵌入的方法最近取得了SOTA性能,可以进一步分为两种。第一种方法,比如EmbedRank和SIFRank,将文档和候选关键词嵌入到一个潜在空间中,计算文档和候选关键词嵌入之间的相似度,然后选择最相似的前k个关键词。由于文档和文档的候选关键词之间的长度差异,这些方法的性能没有达到最优,对于长文档更是如此。为了缓解这种问题第二种方法被提出:通过利用预训练语言模型(PLM),MDERank将候选关键词的嵌入替换为掩码文档的嵌入,其中候选关键词与原始文档相屏蔽。在掩码文档和原始文档长度相近的情况下,测量它们的距离,距离越大,掩码候选文档作为关键词的重要性越高。尽管MDERank解决了长度差异的问题,但它面临着另一个挑战:PLM没有专门针对测量这种距离进行优化,因此需要对比微调(contrastive fine-tuning)来进一步提高性能。这给训练和部署关键词提取系统带来了额外的负担。此外,当更强大的PLM出现时,这会阻碍大型语言模型的快速应用。
受CLIP工作的启发,在这篇论文中,作者建议通过将候选关键词放入一个精心设计的模板(即prompt)来扩展候选词的长度。然后为了比较文档和相应的提示信息,采用encoder-decoder架构将输入(即原始文档)和输出(即提示信息)映射到共享的潜在空间。encoder-decoder架构已经被广泛采用,并通过对齐输入和输出空间在许多领域取得了巨大的成功,包括机器翻译,图像描述等。基于prompt的无监督关键词提取方法可以同时解决上述现有基于嵌入的方法存在的问题:一方面,提示长度的增加可以缓解文档和候选词之间的差异;另一方面,可以直接利用具有encoder-decoder架构的PLM(例如T5)来测量相似性,而无需任何微调。在选择候选关键词后,将给定文档输入编码器,并根据设计的prompt计算解码器生成候选关键词的概率。概率越高,候选词越重要。
PromptRank是第一个使用prompt进行无监督关键词提取的系统。它只需要文档本身,不需要更多的信息。充足的实验证明了PromptRank在长短文本上的有效性。
这篇论文的主要贡献总结如下:
(1) 提出了PromptRank,一种简单有效的无监督关键词提取方法,使用具有encoder-decoder架构的PLM对候选词进行排序。该方法是第一个使用prompt进行无监督关键词抽取的方法;
(2) 进一步研究了影响排序效果的因素,包括候选位置信息(candidate position information)、提示长度(prompt length)和提示内容(prompt content);
(3) PromptRank在六个广泛使用的基准上进行了评估。实验结果表明,PromptRank在很大程度上优于当前的SOTA方法MDERank,展示了使用prompt进行无监督关键词提取的巨大潜力。
2. Related Work
2.1 Unsupervised Keyphrase Extraction
主流的无监督关键词提取方法分为三类:基于统计的方法、基于图的方法和基于嵌入的方法。基于统计的方法通过综合考虑候选词的统计特征(如频率、位置、大小写和其他捕获的上下文信息特征)来对候选词进行排序。基于图的方法最早由TextRank提出,该方法以候选词为顶点,根据候选词的共现性关系构造边,并通过PageRank确定顶点的权重。后续的工作,如SingleRank,TopicRank,PositionRank和MultipartiteRank等,都是对TextRank的改进。
近年来,基于嵌入的方法取得了不错的性能。EmbedRank根据文档和候选人之间嵌入的相似性对候选人进行排名。SIFRank遵循了嵌入的思想,将句子嵌入模型SIF与预训练语言模型ELMo相结合,以获得更好的嵌入表示。然而,由于文档和候选文本的长度不匹配,这些算法在处理长文本时表现不佳。MDERank通过将候选文档的嵌入替换为掩码文档的嵌入来解决这个问题,但在没有微调的情况下未能充分利用PLM。为了解决这些问题,这篇论文提出了一种基于提示学习的无监督关键词提取方法PromptRank。除了基于统计、基于图和基于嵌入的方法,AttentionRank使用预训练的语言模型计算自注意力和交叉注意力,以确定候选词在文档中的重要性和语义相关性。
2.2 Prompt Learning
在NLP领域,提示学习(prompt learning)被认为是种新的范式,可以取代在下游任务上对预训练语言模型进行微调。相比微调,自然语言形式的prompt更符合模型的预训练任务。提示学习已被广泛应用于许多NLP任务,如文本分类、关系抽取、命名实体识别、文本生成等。这篇论文首次使用提示学习进行无监督关键词提取,利用具有encoder-decoder架构的PLM的能力,如BART和T5。作者的工作也受到CLIP的启发,使用提示来增加候选词的长度以缓解长度不匹配问题。
3. PromptRank

POS,即part-of-speech,词性标注。
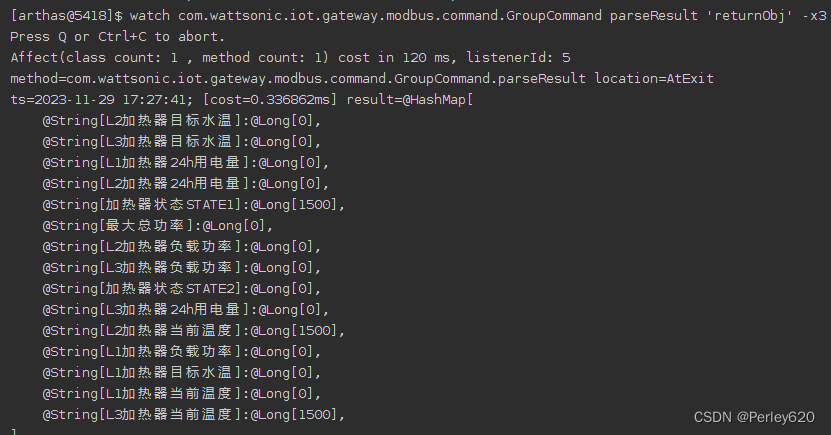
PromptRank的核心架构如上图所示。PromptRank由以下四个主要步骤组成:
(1) 给定文档
d
d
d,根据词性序列生成候选集
C
=
{
c
1
,
c
2
,
.
.
.
,
c
n
}
C = \{c_1, c_2, ..., c_n\}
C={c1,c2,...,cn};
(2) 将文档输入编码器后,对于每个候选词
c
∈
C
c \in C
c∈C,利用设计的提示信息计算解码器生成候选词的概率,记为
p
c
p_c
pc;
(3) 利用位置信息计算
c
c
c 的位置惩罚,记为
r
c
r_c
rc;
(4) 根据概率和位置惩罚计算最终得分
s
c
s_c
sc,然后按
s
c
s_c
sc 降序排列候选词。
3.1 Candidates Generation
作者按照通常做法,对分词和词性标注后的内容使用正则表达式提取名词短语作为关键短语候选,正则表达式为<NN. *|JJ> * <NN.*>
3.2 Probability Calculation
为了解决基于嵌入方法的局限性,作者采用了一个encoder-decoder架构将原始文档和填充候选词的模板转换到共享的潜在空间。文档和模板之间的相似度由解码器生成填充模板的概率决定。概率越高,填充的模板与文档的对齐越紧密,候选词就被认为越重要。为了简化计算,选择将候选词放在模板的末尾,这样只需要计算候选词的概率就可以确定其排序。
具体来说,用原始文档填充编码器模板,用一个候选文档填充解码器模板,然后基于PLM得到候选解码器模板的序列概率
p
(
y
i
∣
y
<
i
)
p(y_i | y<i)
p(yi∣y<i)。长度归一化对数似然(length-normalized log-likelihood)因其优越的性能而得到广泛应用,因此,可以按照下面的公式计算一个候选词的概率:
p
c
=
1
(
l
c
)
α
∑
i
=
j
j
+
l
c
−
1
l
o
g
p
(
y
i
∣
y
<
i
)
p_c = \frac {1} {(l_c)^{\alpha}} \sum_{i=j}^{j+l_c-1} log\ p(y_i | y<i)
pc=(lc)α1i=j∑j+lc−1log p(yi∣y<i) 其中,
j
j
j 是候选词
c
c
c 的起始索引,
l
c
l_c
lc 是候选词的长度,
α
\alpha
α 是调节PromptRank对候选词长度倾向的超参数。使用值为负的
p
c
p_c
pc 按降序来评价候选词的重要性。
3.3 Position Penalty Calculation
当我们写文章时,通常从文章的要点开始。研究表明,候选词在文档中的位置可以作为一个有效的统计特征用于关键词提取。
When writing an article, it is common practice to begin with the main points of the article.感觉不是很靠谱吧
在这篇论文中,作者使用位置惩罚通过乘法来调节候选词的对数概率。对数概率为负,因此对于不重要的位置,对应的位置惩罚值更大。这将导致在不重要位置上的候选词总体得分较低,从而降低它们被选为关键词的可能性。具体来说,对于候选词
c
c
c,PromptRank计算其位置惩罚如下:
r
c
=
p
o
s
l
e
n
+
β
r_c = \frac {pos} {len} + \beta
rc=lenpos+β 其中
p
o
s
pos
pos是候选词
c
c
c第一次出现的位置,
l
e
n
len
len 是文档的长度,
β
\beta
β 是一个正值参数,用于调节位置信息的影响力。
β
\beta
β 值越大,位置信息在计算位置惩罚时的作用越小,即当
β
\beta
β 较大时,两个位置对位置惩罚
r
c
r_c
rc 的贡献的差异会减小。因此,可以使用不同的
β
\beta
β 值来控制候选位置的敏感性。
作者还观察到位置信息的有效性与文档长度相关。文章越长,位置信息越有效。因此,对于较长的文档,为
β
\beta
β 分配较小的值。根据经验,作者根据文档的长度将
β
\beta
β 表述为:
β
=
γ
l
e
n
3
\beta = \frac {\gamma} {len^3}
β=len3γ 其中 {\gamma} 是一个超参数,需要通过实验来确定。
3.4 Candidates Ranking
在获得位置罚分
r
c
r_c
rc 后,PromptRank计算最终得分如下:
s
c
=
r
c
×
p
c
s_c = r_c \times p_c
sc=rc×pc利用位置惩罚来调整候选词的对数概率,降低远离文章开头的候选词被选为关键词的可能性。作者根据最终得分按降序对候选词进行排序,最后选取前k个候选词作为关键词。
4. Experiments
4.1 Datasets and Evaluation Metrics
为了进行全面而准确的评估,作者在六个广泛使用的数据集上评估了PromptRank,与目前的SOTA方法MDERank一致。这些数据集是Inspec、SemEval-2010、SemEval-2017、DUC2001、NUS和Krapivin。数据集的统计信息如下表所示:

按照之前的工作,使用F1对top5、top10和top15的候选词进行评估。在计算F1时,将删除重复的候选项,并应用词干提取。
4.2 Baselines and Implementation Details
作者选择了与MDERank相同的基线。这些基线包括基于图的方法,如TextRank、SingleRank、TopicRank 和MultipartiteRank基于统计的方法,如YAKE,以及基于嵌入的方法,如EmbeddRank、SIFRank和MDERank 本身,对于MDERank,直接使用了其基线结果。为了公平地比较,确保了PromptRank和MDERank预处理和后处理的一致性。作者还使用T5-base(2.2亿个参数)模型,它与MDERank中使用的BERT-base具有相似的参数规模。此外,为了匹配BERT的设置,编码器输入的最大长度设置为512。
PromptRank是一种无监督算法,只需要设置两个超参数:
α
\alpha
α 和
γ
\gamma
γ。PromptRank被设计为具有开箱即用的泛化能力,而不是拟合单个数据集。因此,作者使用相同的超参数在六个数据集上评估PromptRank。这里将
α
\alpha
α 设置为
0.6
0.6
0.6,
γ
\gamma
γ 设置为
1.2
×
1
0
8
1.2 \times 10^8
1.2×108。
4.3 Overall Results

上面的表格展示了PromptRank和基线模型在六个数据集上的F1@5、F1@10和F1@15得分的结果。结果表明,PromptRank在所有6个数据集上几乎所有评价指标上都取得了最好的性能,证明了所提方法的有效性。具体来说,PromptRank的表现优于SOTA方法MDERank,在F1@5、F1@10和F1@15上分别取得了34.18%、24.87%和17.57%的平均相对提升。值得注意的是,与嵌入和SIFRank相比,MDERank主要提高了两个超长数据集(Krapivin,NUS)上的性能,而所提出的方法PromptRank在几乎所有数据集上都取得了最佳性能。这突出了所提出方法的泛化能力,可以在具有不同文档长度的不同数据集上很好地工作。
随着文本长度的增加,文本与候选文本之间的长度差异会越来越严重。为了进一步研究PromptRank解决这个问题的能力,作者将其与EmbeddRank和MDERank在六个数据集上的平均性能F1@5,F1@10,F1@15进行了比较。随着文档长度的增加,候选词数量迅速增加,关键词抽取性能下降。

如上图所示,EmbedRank受长度差异的影响特别大,性能下降很快。MDERank和PromptRank都缓解了这种下降。然而,在MDERank中使用的掩码文档嵌入并不像预期的那样工作。这是因为BERT没有被训练来保证越重要的短语被屏蔽,嵌入的变化越剧烈。BERT只是被训练来恢复掩码令牌。通过利用PLM的encoder-decoder结构并使用prompt,PromptRank不仅比MDERank更有效地解决了嵌入在长文本上的性能下降问题,而且在短文本上的表现也优于两者。
4.4 Ablation Study
4.4.1 Effects of Position Penalty
为了评估位置惩罚对PromptRank整体性能的贡献,作者进行了仅根据候选词的提示概率进行排序的实验。结果如下表所示:

没有位置惩罚的PromptRank的表现明显优于MDERank。当考虑位置惩罚时,性能进一步提高,特别是在长文本数据集上。这表明基于提示的概率是PromptRank的核心,而位置信息可以提供更多的好处。
4.4.2 Effects of Template Length
PromptRank通过将候选词填充到模板中来解决嵌入的长度差异。为了研究模板能在多长时间可以避免嵌入的缺陷,作者使用不同长度的模板进行了实验,分别为0、2、5、10和20。除长度为0的组外,每个长度包含4个手工模板(详见附录A.2),位置信息不使用。为了排除模板内容的影响,对于每个模板,计算每个数据集的性能与Inspec(short text)数据集的性能的比率,以衡量文本长度增加造成的退化。

如上图所示,折线越高,退化越小。长度为0和2的模板退化严重,面临着与嵌入相同的问题,使得prompt难以利用。长度大于等于5的模板较好地解决了长度差异问题,为模板选择提供指导。
4.4.3 Effects of Template Content

模板的内容直接影响关键词提取的性能。一些典型的模板及其结果如上述表格所示(没有使用位置信息)。模板1是空的,结果最差。模板2-5的长度相同,都是5,性能优于模板1。模板4在所有指标上都取得了最佳性能。因此,本文得出结论,设计良好的提示是有益的。请注意,所有模板都是手动设计的,将模板构造的自动化留给未来的工作。
4.4.4 Effects of Hyperparameter α
PromptRank对候选词长度的倾向由
α
\alpha
α 控制,
α
\alpha
α 越高,越倾向于选择较长的候选词。为了探究不同
α
\alpha
α 值的影响,作者在不使用位置信息的情况下进行了实验,将
α
\alpha
α 从0.2调整为1,步长为0.1。
α
\alpha
α 在6个数据集上的最优值如下表所示:

L
a
k
L_{ak}
Lak是黄金关键词的平均字数,直观地说,数据集中
L
a
k
L_{ak}
Lak越小,
α
\alpha
α 的最优值就越小。结果表明,大多数数据集都符合这一猜想。请注意,最高
L
a
k
L_{ak}
Lak 的SemEval2017对
α
\alpha
α 不敏感原因是SemEval2017数据集中黄金关键短语的分布相对更均衡。为了保持PromptRank的泛化能力,建议选择在每个基准上表现良好的
α
\alpha
α,而不是追求所有数据集的最佳平均F1。因此,建议将
α
\alpha
α 设置为0.6。
4.4.5 Effects of Hyperparameter γ
位置信息的影响由
β
\beta
β 控制,
β
\beta
β 越大,位置信息对排名的影响越小。之前的工作表明,包含位置信息可以在提高长文本性能的同时,降低短文本的性能。为了解决这个问题,作者通过超参数
γ
\gamma
γ 根据文档长度动态调整
β
\beta
β,旨在最大限度地减少大
β
\beta
β 对短文本的影响,同时最大化小
β
\beta
β 对长文本的好处。通过实验,确定
γ
\gamma
γ 的最优值为
1.2
×
1
0
8
1.2 \times 10^8
1.2×108。通过在六个数据集上计算
β
\beta
β 的平均值显示在表5中。如表3所示,PromptRank在短文本上的性能保持不变,而在长文本上的性能有显著提升。
4.4.6 Effects of the PLM
PromptRank使用T5-base作为默认的PLM,但是为了探究PromptRank的机制是否局限于特定的PLM,作者使用不同大小和类型的模型进行了实验,例如BART。结果如表6所示,即使超参数和提示针对T5-base进行了优化,所有模型的性能都优于当前的SOTA方法MDERank。这表明PromptRank并不局限于特定的PLM,并且对于不同的encoder-decoder结构的PLM具有很强的通用性。当有更强大的PLM可用时,该方法能够快速应用新的PLM。

4.5 Case Study
为了证明PromptRank的有效性,作者从Inspec数据集中随机选择一个文档,并比较MDERank和PromptRank产生的分数之间的差异。作者对原始分数进行归一化并以热图的形式呈现它们,颜色越暖,分数越高,候选词越重要。金色的关键字用粗体斜体下划线。对比发现,与MDERank相比,PromptRank更准确地给黄金关键词打高更好地区分不相关的候选。实验结果表明,PromptRank比SOTA方法MDERank具有更好的性能。


5. Conclusion
这篇论文提出了一种基于prompt的无监督关键词提取方法PromptRank,采用encoder-decoder架构的PLM。根据解码器设计的提示来计算生成候选词的概率,从而对候选词进行排序。在六个广泛使用的基准上进行的广泛实验,证明了所提出方法的有效性,明显优于强大的基线。彻底研究了影响PromptRank性能的各种因素,并获得了有价值的见解。该方法不需要对PLM的架构进行任何修改,也不引入任何额外参数,使其成为一种简单而强大的关键词提取方法。
关注微信公众号:
夏小悠,以获取更多文章、论文PPT等资料^_^