假设我们一个 batch 有
n
n
n 个样本,一共有
k
k
k 个 GPU 每个 GPU 分到
m
j
m_j
mj 个样本。假设样本刚好等分,则有
m
j
=
n
k
m_{j}=\frac nk
mj=kn 。我们考虑总的损失函数
l
l
l 对参数
w
w
w 的导数:
∂
L
o
s
s
∂
w
=
∂
⌊
1
n
∑
i
=
1
n
l
(
x
i
,
y
i
)
⌋
∂
w
=
1
n
∑
i
=
1
n
∂
l
(
x
i
,
y
i
)
∂
w
=
m
1
n
∂
[
1
m
1
∑
i
=
1
m
1
l
(
x
i
,
y
i
)
]
∂
w
+
m
2
n
∂
[
1
m
2
∑
i
=
m
1
+
1
m
1
+
m
2
l
(
x
i
,
y
i
)
]
∂
w
+
⋯
+
m
k
n
∂
[
1
m
k
∑
i
=
m
k
−
1
+
1
m
k
−
1
+
m
k
l
(
x
i
,
y
i
)
]
∂
w
=
∑
j
=
1
k
m
j
n
∂
[
1
m
j
∑
i
=
m
j
−
1
+
1
m
j
−
1
+
m
j
l
(
x
i
,
y
i
)
]
∂
w
=
∑
j
=
1
k
m
j
n
∂
l
o
s
s
j
∂
w
\begin{aligned} \begin{aligned}\frac{\partial Loss}{\partial w}\end{aligned}& =\frac{\partial\left\lfloor\frac1n\sum_{i=1}^nl(x_i,y_i)\right\rfloor}{\partial w} \\ &=\frac1n\sum_{i=1}^n\frac{\partial l(x_i,y_i)}{\partial w} \\ &=\frac{m_1}n\frac{\partial\left[\frac1{m_1}\sum_{i=1}^{m_1}l(x_i,y_i)\right]}{\partial w}+\frac{m_2}n\frac{\partial\left[\frac1{m_2}\sum_{i=m_1+1}^{m_1+m_2}l(x_i,y_i)\right]}{\partial w}+\cdots+\frac{m_k}n\frac{\partial\left[\frac1{m_k}\sum_{i=m_{k-1}+1}^{m_{k-1}+m_k}l(x_i,y_i)\right]}{\partial w} \\ &=\sum_{j=1}^k\frac{m_j}n\frac{\partial\left[\frac1{m_j}\sum_{i=m_{j-1}+1}^{m_{j-1}+m_j}l(x_i,y_i)\right]}{\partial w} \\ &=\sum_{j=1}^k\frac{m_j}n\frac{\partial loss_j}{\partial w} \end{aligned}
∂w∂Loss=∂w∂⌊n1∑i=1nl(xi,yi)⌋=n1i=1∑n∂w∂l(xi,yi)=nm1∂w∂[m11∑i=1m1l(xi,yi)]+nm2∂w∂[m21∑i=m1+1m1+m2l(xi,yi)]+⋯+nmk∂w∂[mk1∑i=mk−1+1mk−1+mkl(xi,yi)]=j=1∑knmj∂w∂[mj1∑i=mj−1+1mj−1+mjl(xi,yi)]=j=1∑knmj∂w∂lossj
其中:
w
w
w 是模型参数,
∂
L
o
s
s
∂
w
\frac{\partial Loss}{\partial w}
∂w∂Loss 是大小为
n
n
n 的big batch的真实梯度,
∂
l
o
s
s
j
∂
w
\frac{\partial loss_j}{\partial w}
∂w∂lossj 是 GPU/node
k
k
k 的小批量梯度,
x
i
x_i
xi 和
y
i
y_i
yi 是数据点
i
i
i,
l
(
x
i
,
y
i
)
l(x_i,y_i)
l(xi,yi) 是根据前向传播计算出的数据点
i
i
i 的损失,
n
n
n 是数据集中数据点的总数,
k
k
k 是 GPU/Node的总数,
m
k
m_k
mk 是分配给 GPU/节点的样本数量,
m
1
+
m
2
+
⋯
+
m
k
=
n
m_1+m_2+\cdots+m_k=n
m1+m2+⋯+mk=n。当
m
1
=
m
2
=
⋯
=
m
k
=
n
k
m_1=m_2=\cdots=m_k=\frac nk
m1=m2=⋯=mk=kn时,我们可以进一步有:
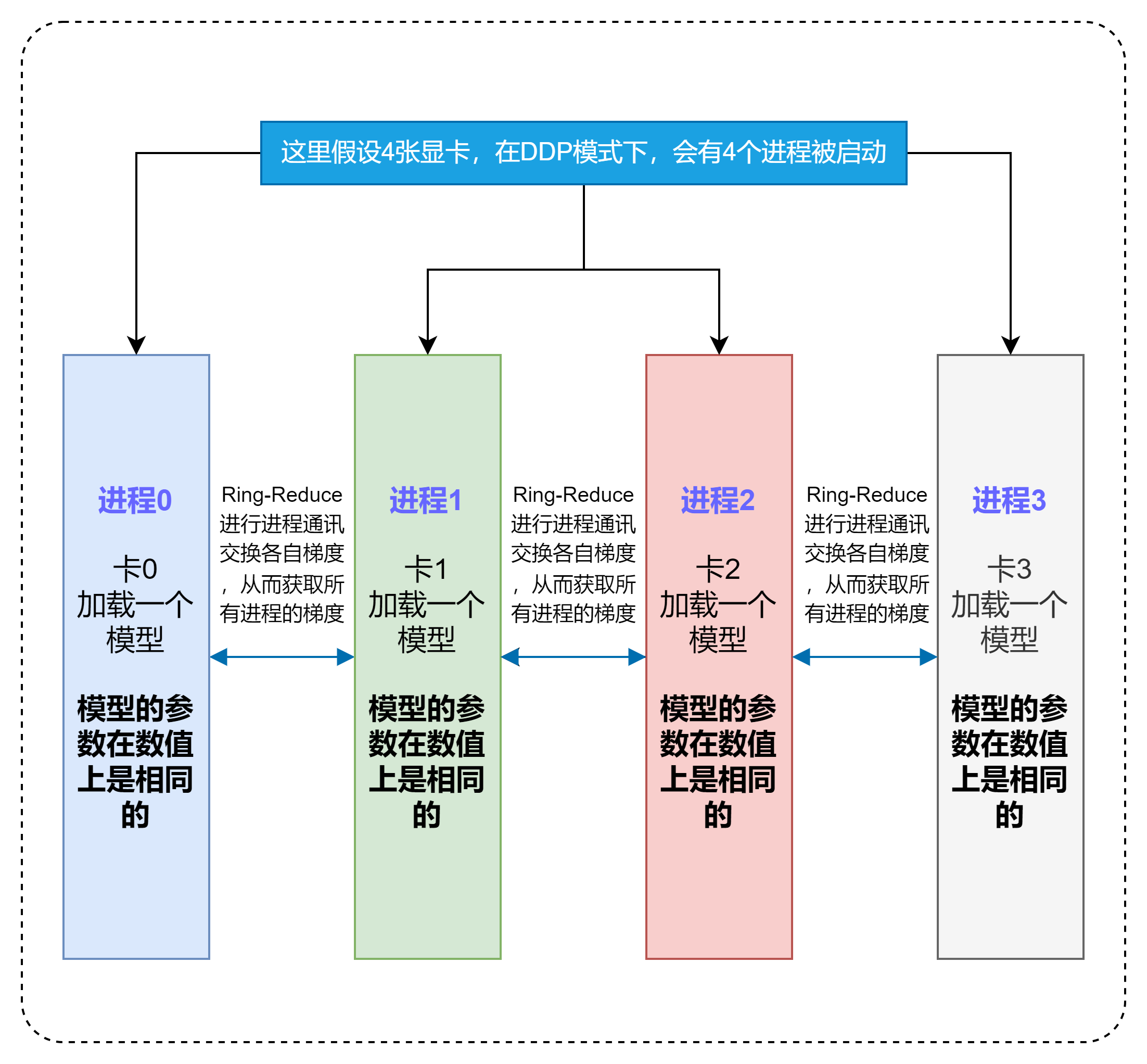
∂
L
o
s
s
∂
w
=
1
k
[
∂
l
o
s
s
1
∂
w
+
∂
l
o
s
s
2
∂
w
+
⋯
+
∂
l
o
s
s
k
∂
w
]
\frac{\partial{Loss}}{ \partial w }=\frac{1}{k}\big[\frac{\partial loss_1}{\partial w}+\frac{\partial loss_2}{\partial w}+\cdots+\frac{\partial loss_k}{\partial w}\big]
∂w∂Loss=k1[∂w∂loss1+∂w∂loss2+⋯+∂w∂lossk]
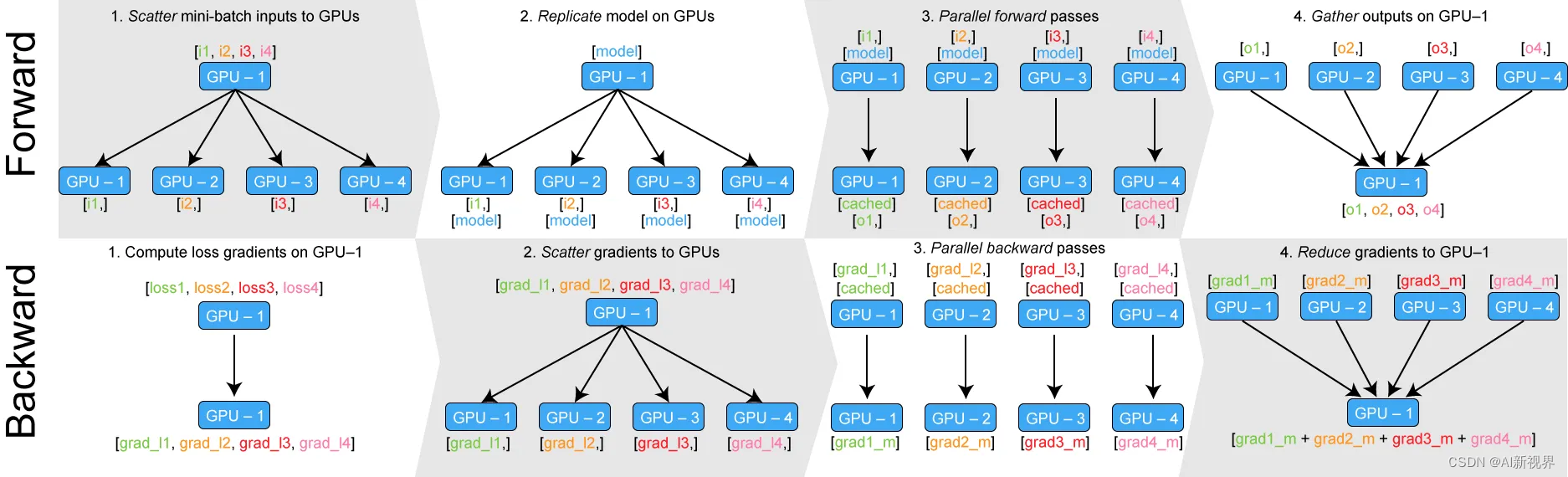
Local Rank(局部GPU编号):在单个节点(机器)上可能有多个进程,每个进程可能管理一个或多个GPU。local_rank是指一个进程所管理的GPU在该节点上的编号。例如,如果一个节点上有8个GPU,那么每个进程的local_rank的范围将是0到7。在PyTorch中,这通常是由torch.distributed.launch模块在启动进程时内部设置的。这对于确保每个进程使用不同的GPU至关重要,以避免资源冲突。
编写程序,键盘输入n,计算1前n项之和。 测试案例: 输入:10 输出:22.47 代码如下: set serveroutput on
declare v_sum number:0;v_n number;beginv_n:&n;for i in 1..v_n loopv_sum:v_sumsqrt(i);
end loop;
d…
运行环境为ubuntu20.04
如在/home/zoe/map运行.sh文件:
进入到/home/zoe文件夹下:
cd /home/zoe/map
第一种运行方式:
sh play.sh 结果: 第二种方式: 使用chmod修改文件的执行权限,然后运行
chmod x …













![[Oracle]编写程序,键盘输入n,计算1+前n项之和。测试案例:输入:10 输出:22.47](https://img-blog.csdnimg.cn/direct/dd2d5d4e3e8e4a40aaaba93a90d3d64b.png)