【本节目标】
1. 为什么要学习string类
2. 标准库中的string类
1. 为什么要学习string类
1.1 C语言中的字符串
C语言中,字符串是以'\0'结尾的一些字符的集合,为了操作方便,C标准库中提供了一些str系列的库函数, 但是这些库函数与字符串是分离开的,不太符合OOP(面向对象)的思想,而且底层空间需要用户自己管理,稍不留神可能还会越界访问。
2. 标准库中的string类
2.1 string类(了解)
string类的文档介绍

总结:
1. string是表示字符串的字符串类
2. 该类的接口与常规容器的接口基本相同,再添加了一些专门用来操作string的常规操作。
3. string在底层实际是:basic_string模板类的别名,typedef basic_string string;
4. 不能操作多字节或者变长字符的序列。
在使用string类时,必须包含#include<string>头文件以及using namespace std。
2.2 string类的常用接口说明
1. string类对象的常见构造
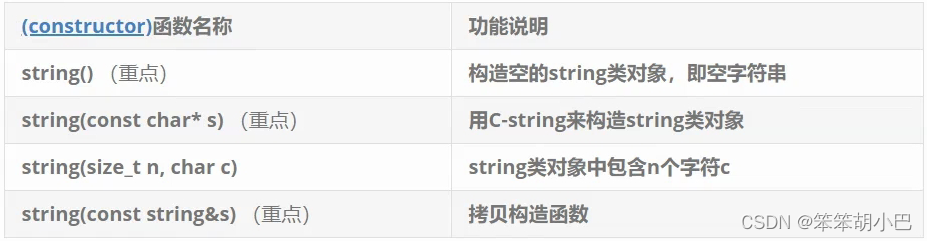
void Teststring()
{
string s1; // 构造空的string类对象s1
string s2("hello bit"); // 用C格式字符串构造string类对象s2
string s3(s2); // 拷贝构造s3
string s4 = s3;// 拷贝构造s4
}我们再来介绍一下string其他相关的构造

(3)Copies the portion(一部分) of str that begins at the character position pos and spans(跨越) len characters (or until the end of str, if either str is too short or if len is string::npos).
我们来使用一下该函数:
string (const string& str, size_t pos, size_t len = npos);

我们再来看一下npos是什么?

所以我们就可以完全理解上面的函数:复制字符串 str 从字符位置 pos 开始,跨越 len 个字符(或者直到 str 的末尾,如果 str 太短或 len 为 string::npos)的部分。
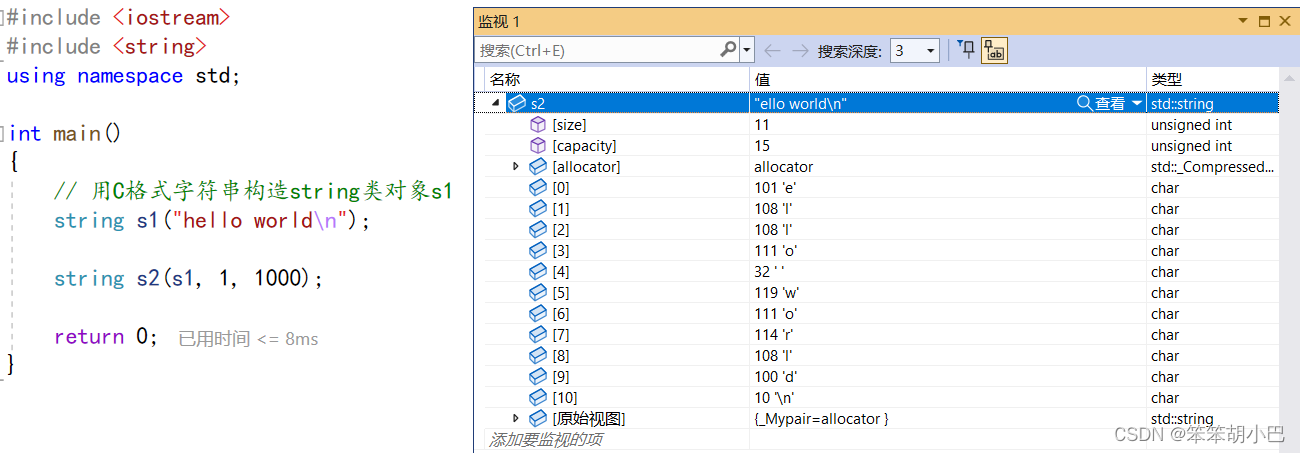
(5)Copies the first n characters from the array of characters pointed by s.
我们来使用一下该函数:
string (const char* s, size_t n);

这个构造函数比较简单,就是复制字符数组 s 指向的前 n 个字符,不过这里要注意该函数的第一个参数是字符串,而不是string类滴对象。
(5)Fills the string with n consecutive(连续的) copies of character c.
我们来使用一下该函数:
string (size_t n, char c);
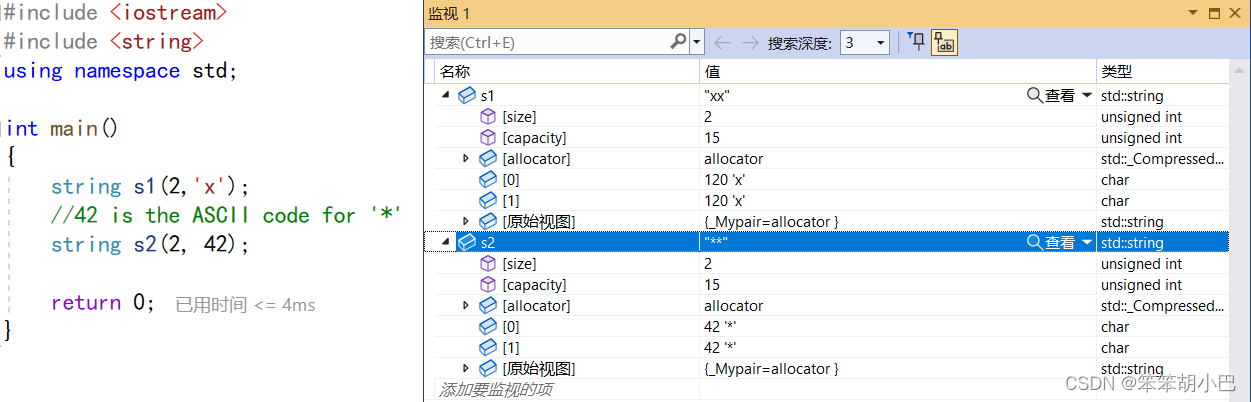
这个构造函数就是用字符 c 的连续副本填充字符串,填充的数量为 n。
(7)Copies the sequence of characters in the range [first,last), in the same order.
这个构造函数涉及迭代器,我们后面再讲解。
2.string类对象的析构函数
析构函数会自动调用的,我们可以不用重点关注在这一块。
3. string类对象的赋值
这里赋值可以支持string类的对象,常量字符串和字符。
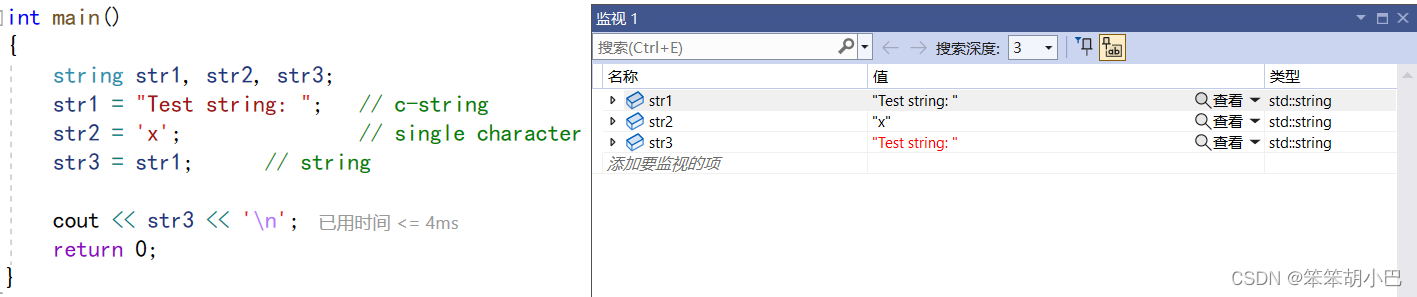
4. string类对象的遍历和访问

-
4.1.通过下标 + [ ]运算符重载实现
//遍历和访问
int main()
{
string str("Test string");
//下面两个函数结果相同,结果是不包含'\0'的
cout << "size:" << str.size() << endl;//推荐使用
cout << "length:" << str.length() << endl;
for (size_t i = 0; i < str.size(); i++)
{
cout << str[i];
}
cout << endl;
return 0;
}运行结果:

我们再来写一个字符串的逆序
//字符串的逆序
int main()
{
string str("Test string");
int begin = 0, end = str.size() - 1;
while (begin < end)
{
char tmp = str[begin];
str[begin] = str[end];
str[end] = tmp;
++begin;
--end;
}
for (size_t i = 0; i < str.size(); i++)
{
cout << str[i];
}
cout << endl;
return 0;
}
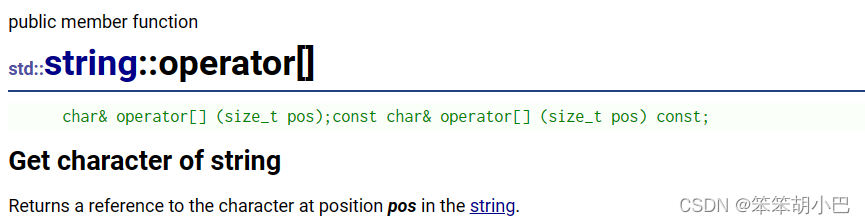
上面的逆序字符串交换的这个代码很繁琐,C++为我们提供了Swap函数接口
于是我们根据上面的swap函数就可以这样写
//字符串的逆序
int main()
{
string str("Test string");
int begin = 0, end = str.size() - 1;
while (begin < end)
{
swap(str[begin], str[end]);
++begin;
--end;
}
for (size_t i = 0; i < str.size(); i++)
{
cout << str[i];
}
cout << endl;
return 0;
}运行结果:

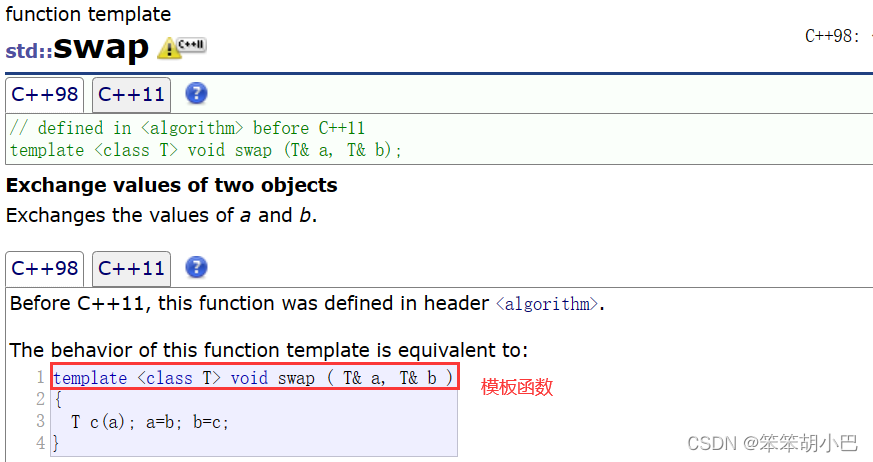
我们现在再来看一个细节,也就是我们之前提到的const的成员函数,这里的[ ]运算符重载实现了两个,这里是两个不同的函数,它们的参数是不同的,第二个隐形的this指针用了const修饰,这里我们要提一下参数匹配的问题。
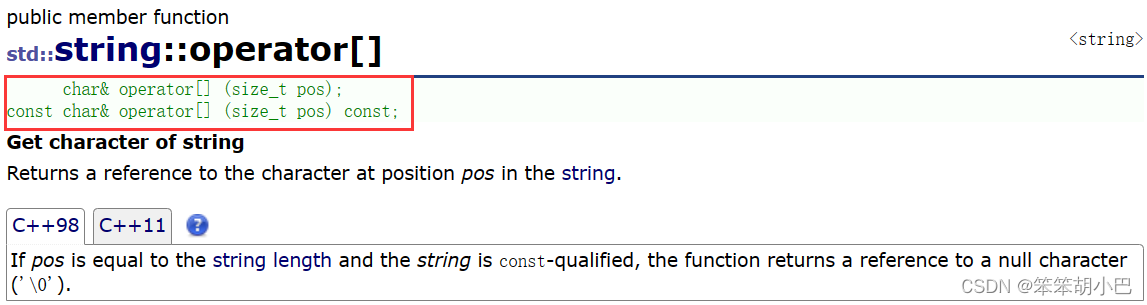
#include <iostream>
#include <string>
using namespace std;
int main()
{
string s1("hello world");
const string s2("hello world");
// 如果只实现了const char& operator[] (size_t pos) const;
s1[0];//权限缩小
s2[0];//权限平移
// 但是此时返回值是const char& - 返回值不可修改
//s2[0] = 'x';//error:error C3892: “s2”: 不能给常量赋值
//所以就提供了char& operator[] (size_t pos);
s1[0] = 'x';
return 0;
}-
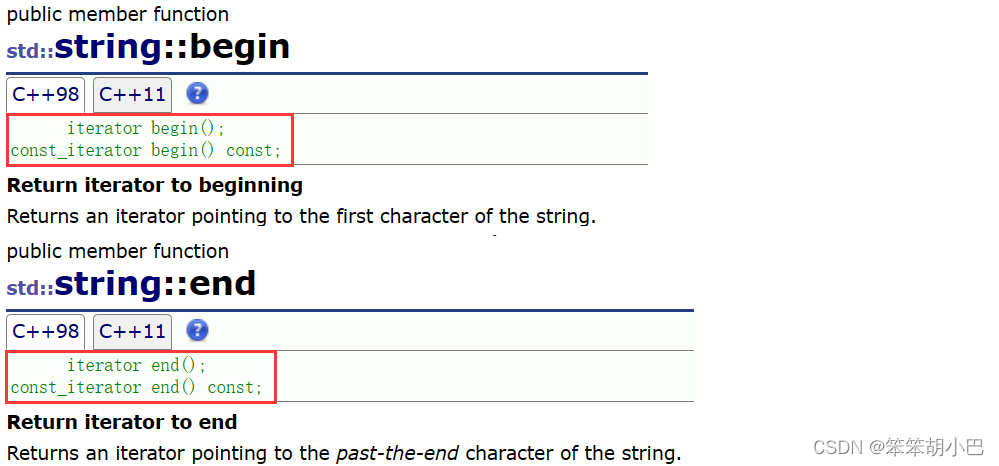
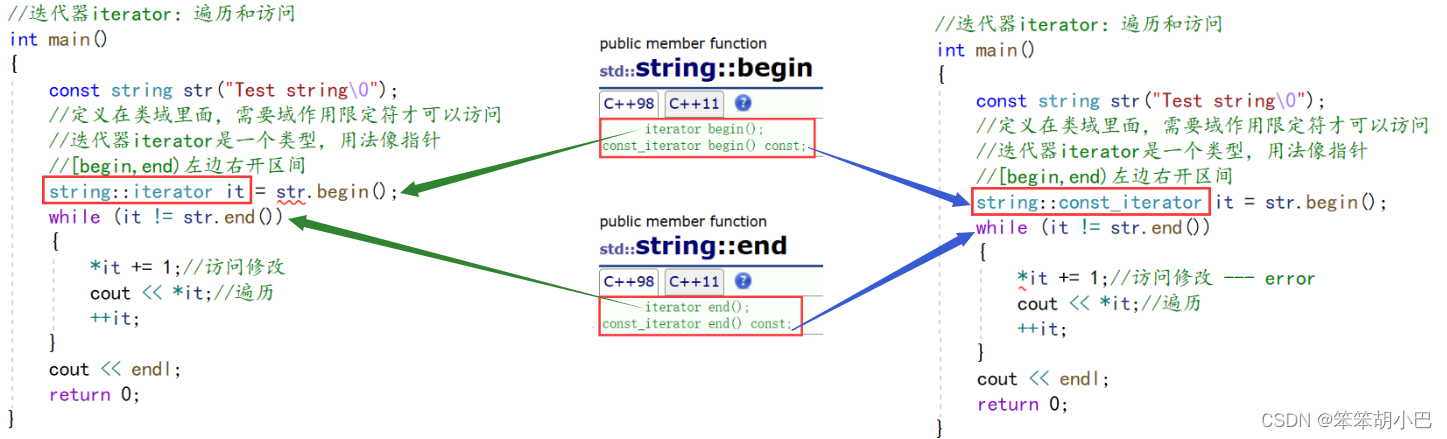
4.2.迭代器(Iterator)
//迭代器iterator:遍历和访问
int main()
{
string str("Test string\0");
//定义在类域里面,需要域作用限定符才可以访问
//迭代器iterator是一个类型,用法像指针
//[begin,end)左边右开区间
string::iterator it = str.begin();
while (it != str.end())
{
*it += 1;//访问修改
cout << *it;//遍历
++it;
}
cout << endl;
return 0;
}运行结果:

解析:

总结:虽然下标 + [ ]很方便,但是它仅仅适用于这些底层物理空间连续,比如string、vector等等。但是链式结构,树形和哈希结构,只能用迭代器,迭代器才是容器访问主流形态。
所以我们上面的逆序就不用写上面的这么多代码,C++为我们提供了逆置的函数:reverse
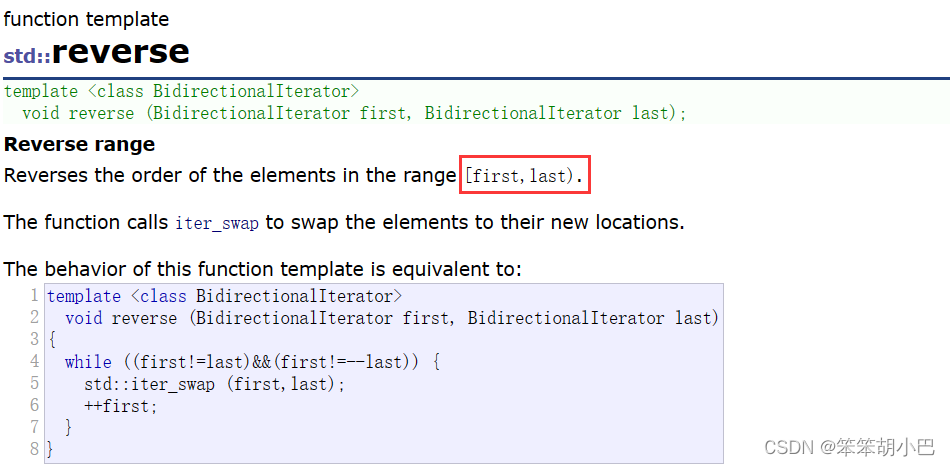
所以就可以直接这样写:
//字符串的逆序
int main()
{
string str("Test string");
string::iterator it = str.begin();
reverse(str.begin(), str.end());
while (it != str.end())
{
cout << *it;
++it;
}
cout << endl;
return 0;
}运行结果:

上面通过函数模板实现,注意泛型编程不是针对某个容器的迭代器实现的,函数模板是针对各个容器迭代器实现。关于我们的迭代器,begin获取一个字符的迭代器,end获取最后一个字符下一个位置,普通的迭代器是可读可写的,但是这里也有一个细节,我们这里迭代器也实现了重载,const重载的只能进行可读。
当我们对只读对象进行迭代器遍历的时候,就出现错误了。同时这里还有一个细节,我们发现上面是const_iterator,而不是const iterator,中间多了一个_,这里的const_iterator本质上是保护迭代器指向的数据"*it"不能被修改,而不是const iterator是迭代器本身不能被修改,也就"it"不能被修改,否则这样无法++,无法遍历,不符合我们的需求。
4.3.反向迭代器
我们也可以通过反向迭代器进行遍历和访问,但是此时的遍历是逆序的。

样例:
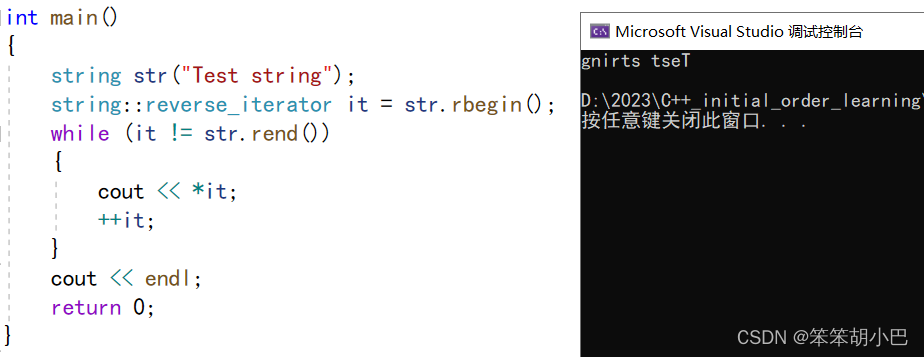
我们可以观察到反向迭代器也实现了两个版本,但是普通情况下我们基本上很少定义const对象,只有在传参的时候我们才最容易出现const对象。
//void fun(const string s1){}//调用拷贝构造,深拷贝,代价大
void fun(const string& s1)//引用,作为str的别名,开销小
{
//error
//string::reverse_iterator it = s1.rbegin();
//const的对象调用rbegin应该返回const_reverse_iterator
string::const_reverse_iterator it = s1.rbegin();
while (it != s1.rend())
{
*it = 1;//const迭代器不可修改,error:“it”: 不能给常量赋值
cout << *it;
++it;
}
cout << endl;
}
int main()
{
string str("Test string");
string::reverse_iterator it = str.rbegin();
while (it != str.rend())
{
*it = 1;//普通迭代器不可修改
cout << *it;
++it;
}
cout << endl;
fun(str);
return 0;
}不过通常我们都使用下标 + [ ]进行逆序遍历,但是反向迭代器也是非常有用的,对于链表这种没有下标的逆序遍历就需要使用反向迭代器。对于上面的迭代器,类型名都是非常长的,而且比较容易写错,这里我们可以使用之前我们讲到的auto关键字自动推至类型,但是这个写法对代码的可读性不好。

关于迭代器这里,之前的迭代器实现了两个版本,容易混淆,于是C++11就对const对象的迭代器进行了单独的处理,在普通迭代器前面加上了字符'c'表示此时的对象是cosnt的。

4.4.范围for
#include <iostream>
using namespace std;
int main()
{
string str("Test string");
for (auto e : str)
{
cout << e;
}
cout << endl;
return 0;
}范围for在我们这里不仅可以支持string,还能支持vertor,list等其他容器。我们现在再来介绍一下下面的元素存取相关函数。

我们先来看一个代码
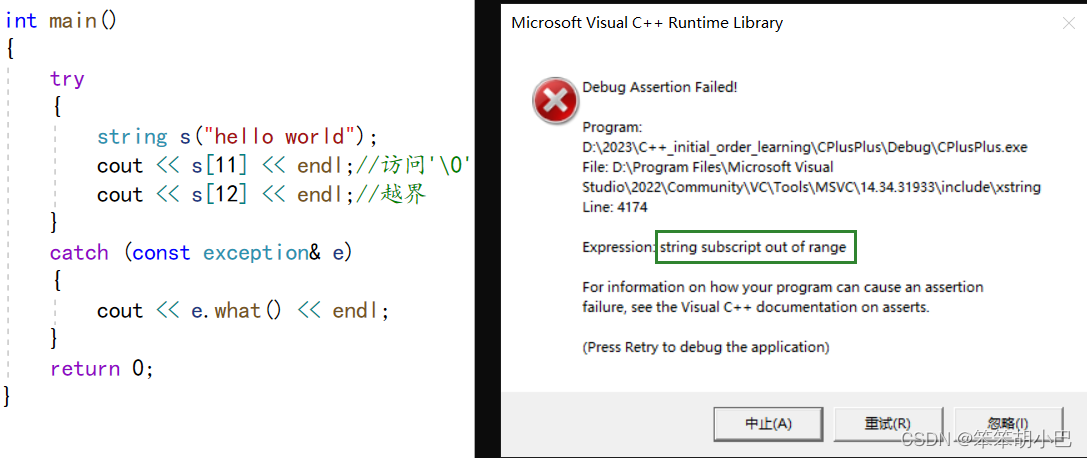
当我们如果不小心访问了越界元素,此时程序就会报错,但是此时看右边我们知道是assert断言出错,如果我们不想出现这个报错界面,并且提示一下错误信息,就可以使用at,at也可以访问元素,它返回字符串中位置 pos 处的字符的引用,当访问越界的时候,此时提示信息"invalid string position"。
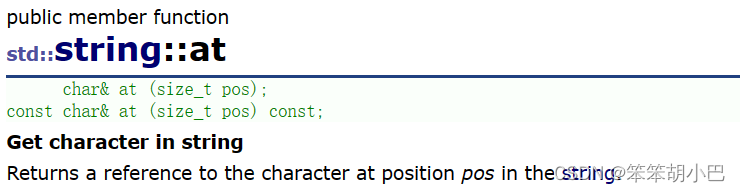
我们来验证一下。
再来看一下front和back,它们是访问字符串的头位置和尾位置的字符

int main()
{
string s("hello world");
cout << s.front() << endl;
cout << s.back() << endl;
cout << s[0] << endl;
cout << s[s.size() - 1] << endl;
return 0;
}运行结果:

一般情况上我们很少用frong和back,因为我们可以通过pos为0和size-1位置访问头和尾元素。
5. string类对象的容量操作

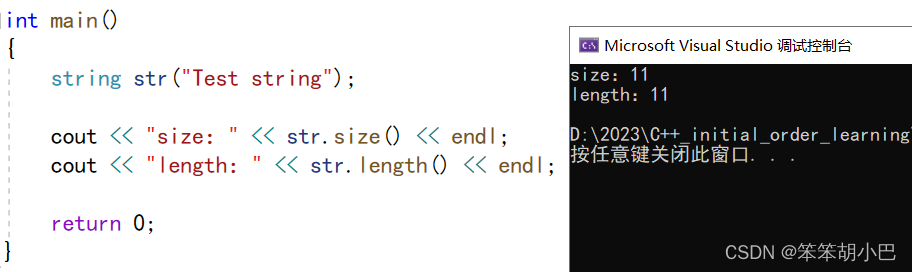
5.1. size()与length()方法底层实现原理完全相同,引入size()的原因是为了与其他容器的接口保持一 致,一般情况下基本都是用size()。
 5.2.max_size()返回字符串可以达到的最大长度,不同的机器这个最大长度是不一样的,下面的测试是32位机器下,
5.2.max_size()返回字符串可以达到的最大长度,不同的机器这个最大长度是不一样的,下面的测试是32位机器下,
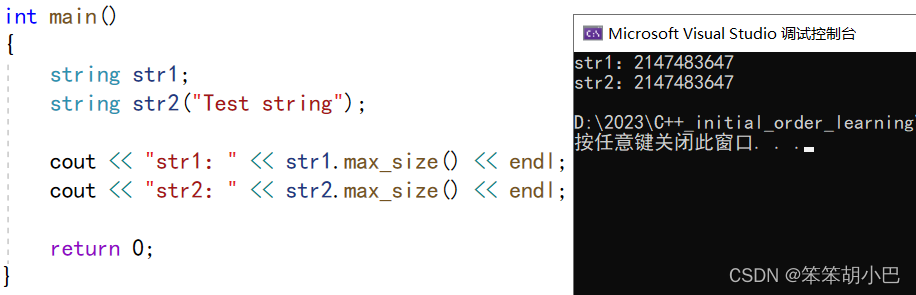
虽然上面给了我们这个字符串能到达的最大长度,但是这个值没有参考意义,实际上我们开辟不了这个最大长度的空间,使得字符串到达的最大长度。我们来验证一下
int main()
{
try
{
string str1;
string str2("Test string");
cout << "str1:" << str1.max_size() << endl;
cout << "str2:" << str2.max_size() << endl;
//reverse:为字符串预留空间 - 相当于扩容
//实践中没有参考的价值和意义
str1.reserve(str1.max_size());
}
catch(const exception& e)
{
cout << e.what() << endl;
}
return 0;
}运行结果:

5.3.capacity()返回空间总大小
 注意:这里的容量是有效字符的数量,而'\0'不属于有效字符,这里实际上开了16个字节的空间,其中一个用来存 '\0'。
注意:这里的容量是有效字符的数量,而'\0'不属于有效字符,这里实际上开了16个字节的空间,其中一个用来存 '\0'。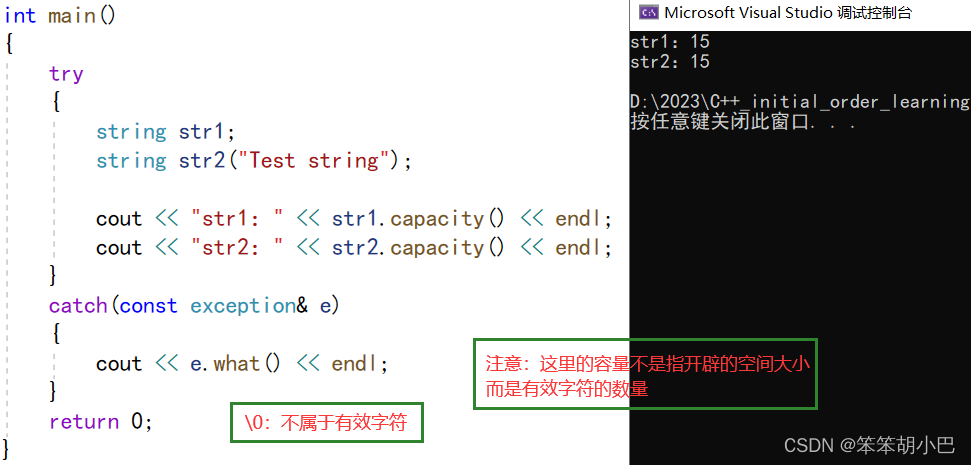
我们这里还能用来检测string的扩容机制
int main()
{
try
{
string str1;
size_t old = str1.capacity();
cout << "str1:" << str1.capacity() << endl;
//检测string的扩容机制
for (size_t i = 0; i < 100; i++)
{
str1.push_back('x');
if (old != str1.capacity())
{
cout << "str1:" << str1.capacity() << endl;
old = str1.capacity();
}
}
}
catch(const exception& e)
{
cout << e.what() << endl;
}
return 0;
}vs下结果:P. J. 版本 - 1.5倍扩容

Linux(g++)下结果:SGI版本 - 2倍扩容
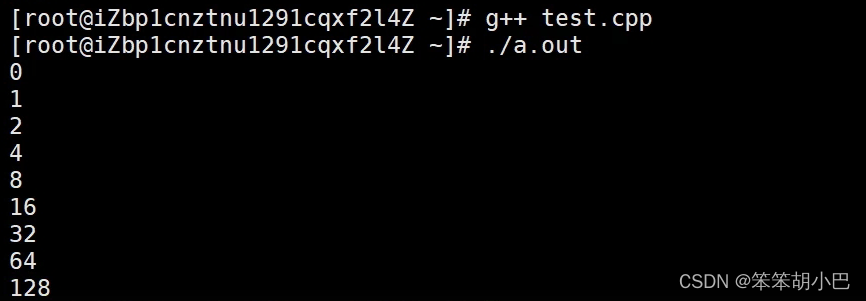
5.4.reserve(size_t res_arg=0):为string预留空间,不改变有效元素个数,当reserve的参数小于 string的底层空间capacity总大小时,reserver不会改变容量大小。
int main()
{
try
{
string str1;
str1.reserve(100);
size_t old = str1.capacity();
cout << "str1:" << str1.capacity() << endl;
//检测string的扩容机制
for (size_t i = 0; i < 100; i++)
{
str1.push_back('x');
if (old != str1.capacity())
{
cout << "str1:" << str1.capacity() << endl;
old = str1.capacity();
}
}
}
catch(const exception& e)
{
cout << e.what() << endl;
}
return 0;
}reserve可以和capaciy搭配使用,当使用reverse(100)的时候,此时就已经开辟了100空间,后面就不需要扩容了。如果我们确定需要多少空间时,提前开空间即可,此后就不需要扩容了。但是这里我们只需开辟100个空间,而程序却开辟了111个空间,因为vs下可能存在了内存对齐机制,会以它内部的规则去对齐,从而会开辟更大一点,Linux下直接开辟你确定所要的空间。
vs下运行结果:

Linux下的结果:

我们再来看一下当reserve的参数小于 string的底层空间capacity总大小时,reserver不会改变容量大小。
int main()
{
string str2("hello world!xxxxxxxxxxx");
str2.reserve(100);
cout << "str2:" << str2.capacity() << endl;
str2.reserve(5);
cout << "str2:" << str2.capacity() << endl;
return 0;
}vs下运行结果:

Linux下的结果:

当reserve的参数小于 string的底层空间capacity总大小时,vs平台下reserver不会改变容量大小,Linux下reserver会改变容量大小,但是它缩小空间只会缩小到该字符串的有效字符数量size处,它是不会影响到已经存储的字符串的。
5.5. resize(size_t n) 与 resize(size_t n, char c)都是将字符串中有效字符个数改变到n个,不同的是当字符个数增多时:resize(n)用’\0'来填充多出的元素空间,resize(size_t n, char c)用字符c来填充多出的元素空间。注意:resize在改变元素个数时,如果是将元素个数增多,可能会改变底层容量的大小,如果是将元素个数减少,底层空间总大小不变。
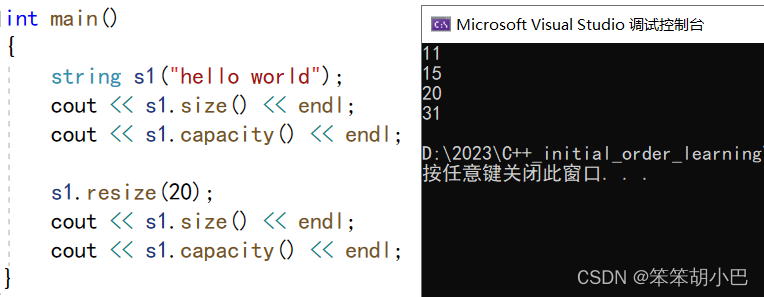
reserve只影响我们的容量,不会影响数据,而resize既影响容量,也会影响数据。我们会发现s1的大小和容量都增加了,那它是用什么填充这些空间的呢?

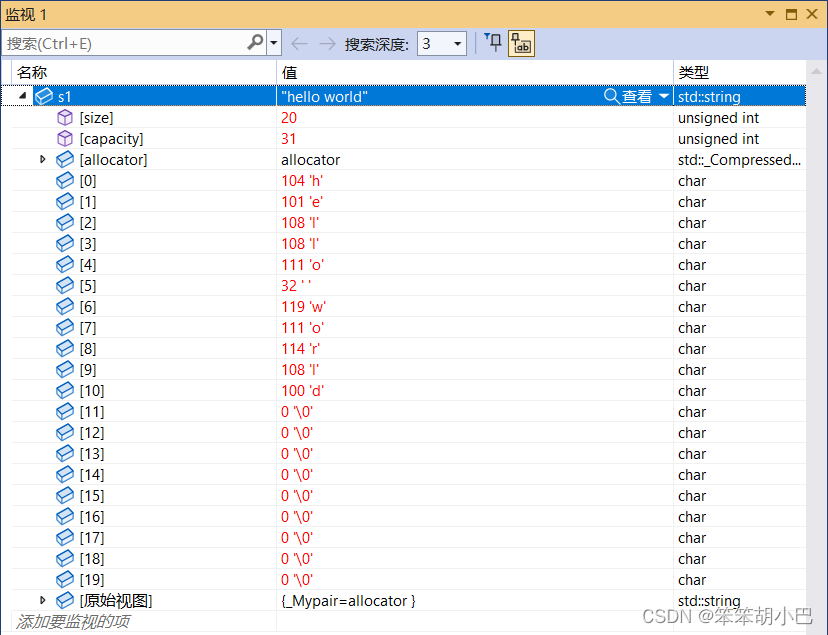
我们先来看一下大于当前容量的情况,我们可以通过监视窗口观察到,但是'\0'不一定是标识字符,有效字符属于0到size-1范围内。
我们再来看一下大于size但是小于capacity的情况
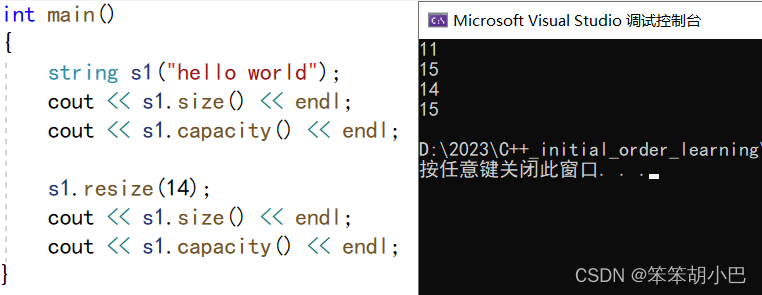
此时容量大小没有改变,只变化了数据,仅仅变化了size。如果小于size呢?
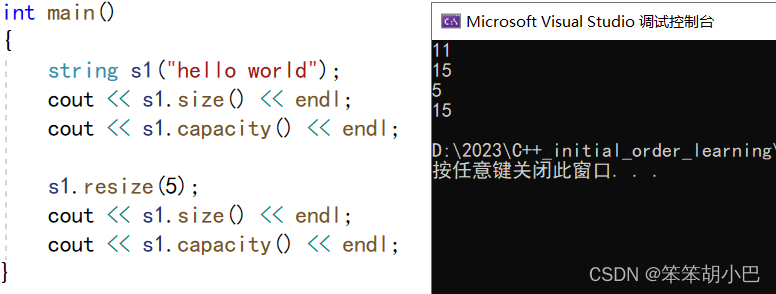
看一下监视窗口
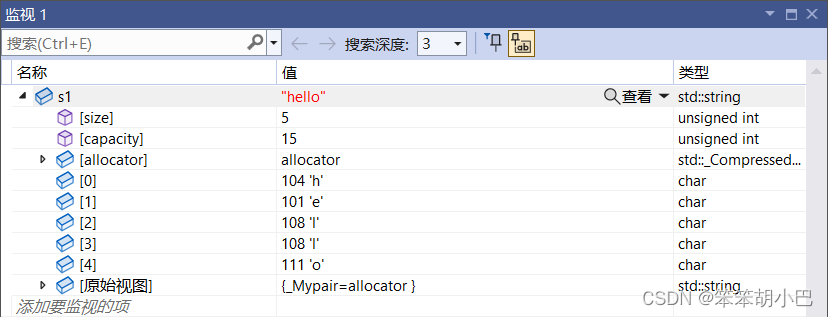
此时删除了数据,只保留前resize个。resize应用的场景是开辟空间并指定字符初始化。注意:C++中new对应C语言中的malloc函数,而C++中没有C语言中对应的realloc扩容函数。所以C++中,我们如果使用字符数组,就会使用string,而string中提供了相应的接口,从而进行扩容。
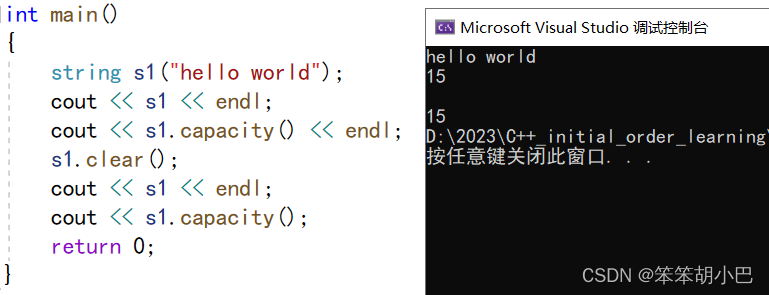
5.6.clear()只是将string中有效字符清空,不改变底层空间大小。
6. string类对象的增删查改操作
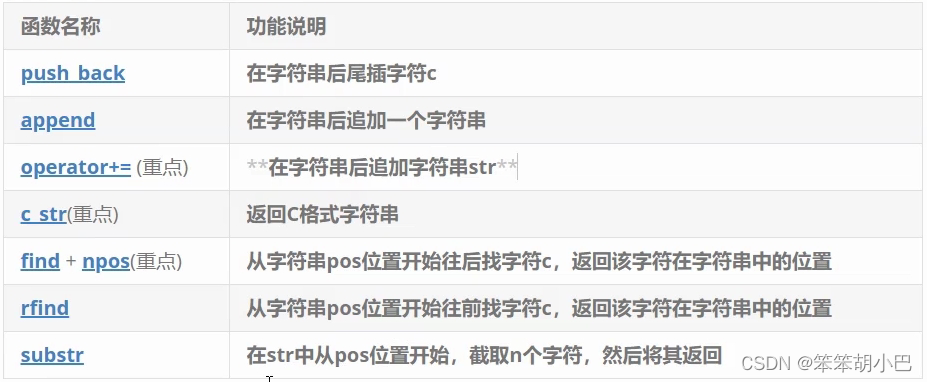
6.1.增加
在string尾部追加字符时,s.push_back(c) / s.append(1, c) / s += 'c'三种的实现方式差不多,一般情况下string类的+=操作用的比较多,+=操作不仅可以连接单个字符,还可以连接字符串。

这里有一个问题:string s1 = "hello world";//这个可行吗?可行,这里是一个单参数的构造函数,它会隐式类型转换,它先去构造,然后再拷贝构造,不过这里编译器可能会优化成直接构造。

我们来看一下append的使用。
int main()
{
std::string str;
std::string str2 = "Writing ";
std::string str3 = "print 10 and then 5 more";
// used in the same order as described above:
str.append(str2); // "Writing "
str.append(str3, 6, 3); // "10 "
str.append("here: "); // "here: "
str.append("dots are cool", 5); // "dots "
str.append(10u, '.'); // ".........."
str.append(str3.begin() + 8, str3.end()); // " and then 5 more"
std::cout << str << '\n';
return 0;
}我们上面有了尾插,那我们有没有头插呢?或者在中间插入呢?
// inserting into a string
#include <iostream>
#include <string>
int main ()
{
std::string str="to be question";
std::string str2="the ";
std::string str3="or not to be";
std::string::iterator it;
// used in the same order as described above:
str.insert(6,str2); // to be (the )question
str.insert(6,str3,3,4); // to be (not )the question
str.insert(10,"that is cool",8); // to be not (that is )the question
str.insert(10,"to be "); // to be not (to be )that is the question
str.insert(15,1,':'); // to be not to be(:) that is the question
it = str.insert(str.begin()+5,','); // to be(,) not to be: that is the question
str.insert (str.end(),3,'.'); // to be, not to be: that is the question(...)
str.insert (it+2,str3.begin(),str3.begin()+3); // (or )
std::cout << str << '\n';
return 0;
}实际中头插使用较少,因为要挪动数据,效率不高。那删除字符呢?
6.2.删除

// string::erase
#include <iostream>
#include <string>
int main ()
{
std::string str ("This is an example sentence.");
std::cout << str << '\n';
// "This is an example sentence."
str.erase (10,8); // ^^^^^^^^
std::cout << str << '\n';
// "This is an sentence."
str.erase (str.begin()+9); // ^
std::cout << str << '\n';
// "This is a sentence."
str.erase (str.begin()+5, str.end()-9); // ^^^^^
std::cout << str << '\n';
// "This sentence."
return 0;
}6.3.查找
注意:
- pos含义:搜索字符串中要查找的第一个字符的位置。
- 函数返回值:第一个匹配项的第一个字符的位置。 如果未找到任何匹配项,则该函数返回
string::npos。

// string::find
#include <iostream> // std::cout
#include <string> // std::string
int main ()
{
std::string str ("There are two needles in this haystack with needles.");
std::string str2 ("needle");
// different member versions of find in the same order as above:
std::size_t found = str.find(str2);
if (found!=std::string::npos)
std::cout << "first 'needle' found at: " << found << '\n';
found=str.find("needles are small",found+1,6);
if (found!=std::string::npos)
std::cout << "second 'needle' found at: " << found << '\n';
found=str.find("haystack");
if (found!=std::string::npos)
std::cout << "'haystack' also found at: " << found << '\n';
found=str.find('.');
if (found!=std::string::npos)
std::cout << "Period found at: " << found << '\n';
// let's replace the first needle:
str.replace(str.find(str2),str2.length(),"preposition");
std::cout << str << '\n';
return 0;
}现在我们来使用一下find,查找字符串的后缀是什么?这里我们会使用到substr。

int main()
{
string s1("Test.cpp");
string s2("Test.tar.zip");
size_t pos1 = s1.find('.');
if(pos1 != string::npos)
{
string suff1 = s1.substr(pos1, s1.size() - pos1);
cout << suff1 << endl;//.cpp
string suff2 = s1.substr(pos1);//默认取到结尾
cout << suff2 << endl;//.cpp
}
size_t pos2 = s2.find('.');
if (pos2 != string::npos)
{
string suff1 = s2.substr(pos2, s2.size() - pos2);
cout << suff1 << endl;//.tar.zip
string suff2 = s2.substr(pos2);//默认取到结尾
cout << suff2 << endl;//.tar.zip
}
//搜索字符串中由参数指定的序列的最后一次出现
size_t pos3 = s2.rfind('.');
if (pos2 != string::npos)
{
string suff1 = s2.substr(pos3, s2.size() - pos3);
cout << suff1 << endl;//.zip
string suff2 = s2.substr(pos3);//默认取到结尾
cout << suff2 << endl;//.zip
}
return 0;
}运行结果:

如何将一个网址分开呢?
#include <iostream>
#include <string>
using namespace std;
int main()
{
string str("https://cplusplus.com/reference/string/string/substr/");
string sub1, sub2, sub3;
size_t pos1 = str.find(':');
//左闭右开区间
sub1 = str.substr(0, pos1 - 0);
cout << sub1 << endl;
size_t pos2 = str.find('/', pos1 + 3);
sub2 = str.substr(pos1 + 3, pos2 - (pos1 + 3));
cout << sub2 << endl;
sub3 = str.substr(pos2 + 1);
cout << sub3 << endl;
return 0;
}运行结果:
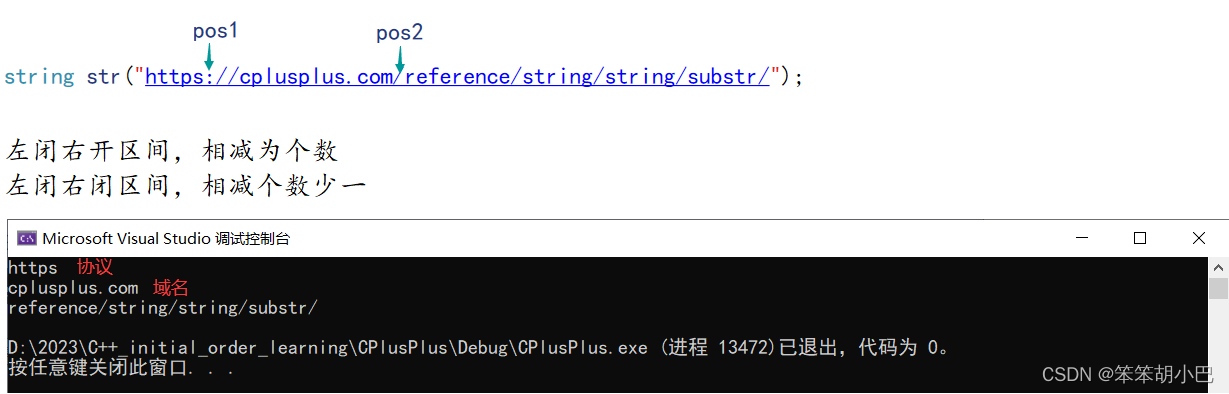
6.4.修改

// replacing in a string
#include <iostream>
#include <string>
int main ()
{
std::string base="this is a test string.";
std::string str2="n example";
std::string str3="sample phrase";
std::string str4="useful.";
// replace signatures used in the same order as described above:
// Using positions: 0123456789*123456789*12345
std::string str=base; // "this is a test string."
str.replace(9,5,str2); // "this is an example string." (1)
str.replace(19,6,str3,7,6); // "this is an example phrase." (2)
str.replace(8,10,"just a"); // "this is just a phrase." (3)
str.replace(8,6,"a shorty",7); // "this is a short phrase." (4)
str.replace(22,1,3,'!'); // "this is a short phrase!!!" (5)
// Using iterators: 0123456789*123456789*
str.replace(str.begin(),str.end()-3,str3); // "sample phrase!!!" (1)
str.replace(str.begin(),str.begin()+6,"replace"); // "replace phrase!!!" (3)
str.replace(str.begin()+8,str.begin()+14,"is coolness",7); // "replace is cool!!!" (4)
str.replace(str.begin()+12,str.end()-4,4,'o'); // "replace is cooool!!!" (5)
str.replace(str.begin()+11,str.end(),str4.begin(),str4.end());// "replace is useful." (6)
std::cout << str << '\n';
return 0;
}根据上面的查找和修改可以轻松解决一个我们曾经遇到的问题,将日期"2023-11-23"中的'-'修改为'/'。
int main()
{
string str("2023-11-23");
cout << str << endl;
size_t pos = str.find('-');
// '-'修改为'/'
while (pos != string::npos)
{
str.replace(pos, 1, 1, '/');
pos = str.find('-');
}
cout << str << endl;
return 0;
}我们看一下我们的代码有什么问题没?我们发现我们每次找'-'都是从字符串的其实位置开始找,那么这也效率比较低,其实我们第一找到'-'后,得到第一次出现'-'的位置,后面再找'-'就可以从上次找的位置+1即可,这样效率就提高很多,但是replace的效率比较低,我们下面替换一个字符还好,但是如果替换成'///'时,此时就要往后挪动数据才能插入,这样效率比较低,所以replace我们能少用尽量就少用。
int main()
{
string str("2023-11-23");
cout << str << endl;
size_t pos = str.find('-', 0);
// '-'修改为'/'
if (pos != string::npos)
{
str.replace(pos, 1, 1, '/');
pos = str.find('-', pos + 1);
}
cout << str << endl;
return 0;
}所以这里我们有更好的方法,使用范围for+赋值。
int main()
{
string str("2023-11-23");
cout << str << endl;
string str1;
for (auto ch : str)
{
if (ch == '-')
str1 += '/';
else
str1 += ch;
}
cout << str1 << endl;
str.swap(str1);
return 0;
}运行结果:

这里有一个细节问题:我们上面使用的是C++ 标准库中 std::string 类的成员函数。
string::swap 是 C++ 标准库中 std::string 类的成员函数,用于交换两个字符串的内容。它是在字符串对象上调用的函数,例如:
std::string str1 = "Hello";
std::string str2 = "World";
str1.swap(str2); // 交换 str1 和 str2 的内容
而 swap 是一个通用的 C++ 函数,用于交换两个对象的值。对于字符串来说,可以使用 std::swap 或直接使用 swap 来交换两个字符串的内容,例如:
std::string str1 = "Hello";
std::string str2 = "World";
std::swap(str1, str2); // 交换 str1 和 str2 的内容
// 或者直接使用 swap
swap(str1, str2);
主要区别在于调用方式和命名空间。string::swap 是 std::string 类的成员函数,而 swap 是一个通用的函数,可以在合适的作用域下直接使用或通过 std::swap 来调用。两者都可以用于交换字符串的内容。同时std::swap 参数是函数模板,使用的时候实例化,需要拷贝,消耗较大,而string::swap 是直接交换两个字符串的地址,后面实现string类的时候可以看到。
6.5.string::c_str:返回一个指向数组的指针,该数组包含表示字符串对象当前值的以 null 结尾的字符序列(即,一个 C 字符串)。
int main()
{
string s1 = "Sample string";
char* s2 = new char[s1.length() + 1];
//char * strcpy ( char * destination, const char * source );
//strcpy(s2, s1);//参数类型不匹配
//const char* c_str() const;//返回值为const char*
strcpy(s2, s1.c_str());
delete[] s2;
return 0;
}7. string类非成员函数
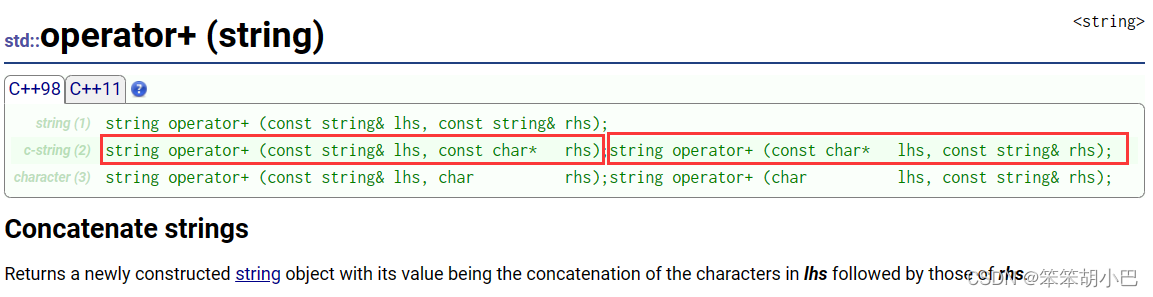
这里为什么实现了两种参数不同的方式?
这两个重载的 operator+ 函数是为了提供更大的灵活性,使得在字符串的拼接操作中更方便使用不同类型的参数。这是一种 C++ 中的重载技术,允许相同的操作符在不同的情境下具有不同的行为。
让我们分析这两个重载函数:
-
string operator+ (const string& lhs, const char* rhs);- 允许将一个
std::string对象和一个 C 字符串(以const char*表示)进行拼接。 - 这使得你可以直接将一个 C 字符串连接到一个
std::string对象的末尾。
- 允许将一个
-
string operator+ (const char* lhs, const string& rhs);- 允许将一个 C 字符串和一个
std::string对象进行拼接。 - 这使得你可以直接将一个
std::string对象连接到一个 C 字符串的末尾。
- 允许将一个 C 字符串和一个
这两种方式的存在是为了方便用户在不同的场景下进行字符串的拼接,无论是从 std::string 到 C 字符串,还是从 C 字符串到 std::string。
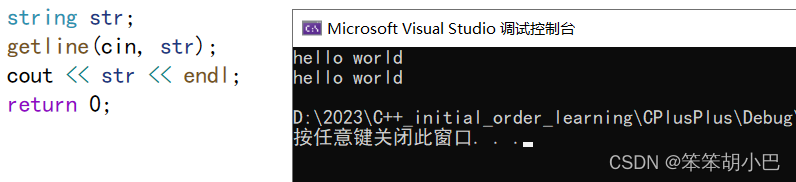
7.1.getline (string):从输入流 is 中提取字符并将它们存储到字符串 str 中,直到找到分隔字符 delim(或者对于 (2) 来说是换行符 '\n')。
流插入字符输入字符时默认以空格或者换行结束。
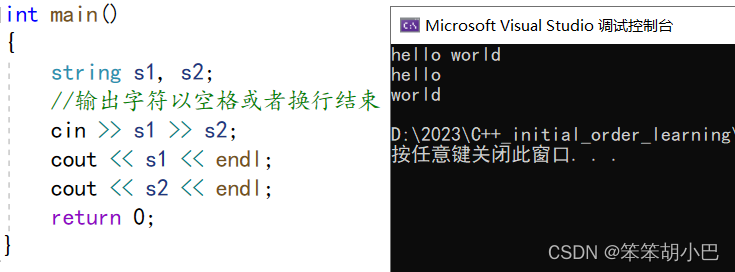
如果不想以空格作为字符输出结束的标志,就要使用getline().
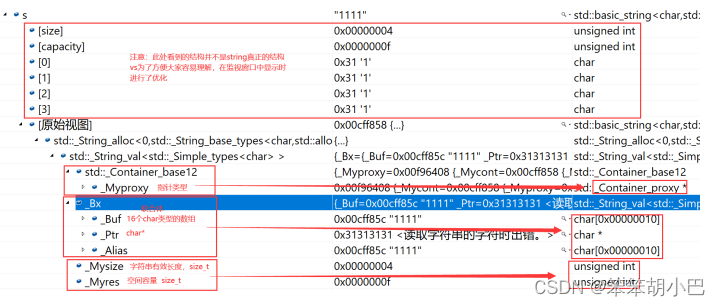
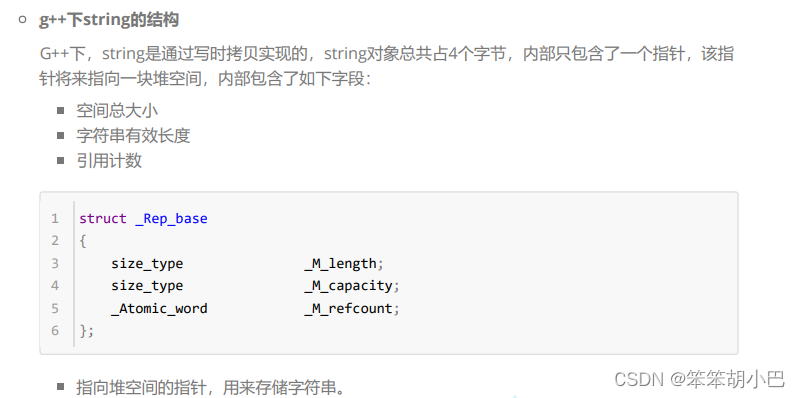
7.1. vs和g++下string结构的说明
注意:下述结构是在32位平台下进行验证,32位平台下指针占4个字节。
- vs下string的结构 string总共占28个字节,内部结构稍微复杂一点,先是有一个联合体,联合体用来定义
- string中字 符串的存储空间: 当字符串长度小于16时,使用内部固定的字符数组来存放 当字符串长度大于等于16时,从堆上开辟空间
- 当字符串长度小于16时,使用内部固定的字符数组来存放
- 当字符串长度大于等于16时,从堆上开辟空间
union _Bxty
{
// storage for small buffer or pointer to larger one
value_type _Buf[_BUF_SIZE];
pointer _Ptr;
char _Alias[_BUF_SIZE]; // to permit aliasing
} _Bx;
这种设计也是有一定道理的,大多数情况下字符串的长度都小于16,那string对象创建好之后,内 部已经有了16个字符数组的固定空间,不需要通过堆创建,效率高。
其次:还有一个size_t字段保存字符串长度,一个size_t字段保存从堆上开辟空间总的容量
最后:还有一个指针做一些其他事情。
故总共占16+4+4+4=28个字节。
上面的几个接口了解一下,下面的OJ题目中会有一些体现他们的使用。string类中还有一些其他的 操作,这里不一一列举,在需要用到时不明白了查文档即可。
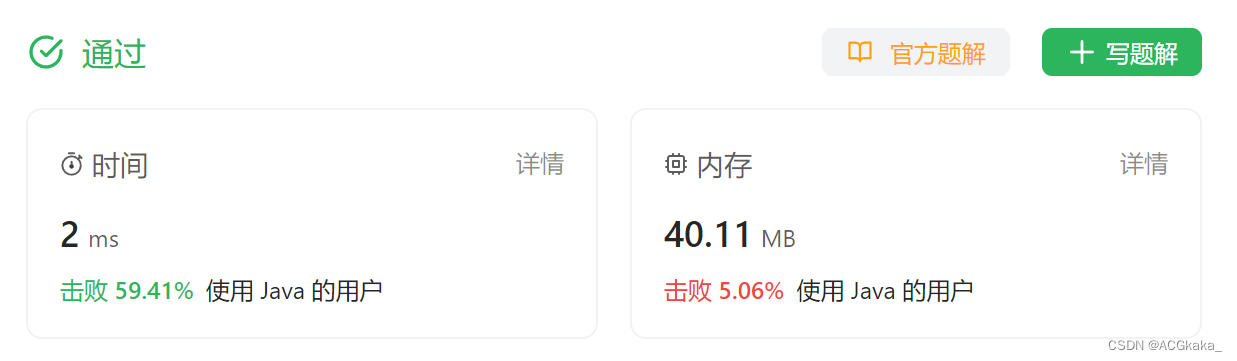
8.小试牛刀
仅仅反转字母
class Solution {
public:
bool isLetter(char ch)
{
if (ch >= 'a' && ch <= 'z')
return true;
if (ch >= 'A' && ch <= 'Z')
return true;
return false;
}
string reverseOnlyLetters(string S)
{
if (S.empty())
return S;
size_t begin = 0, end = S.size() - 1;
while (begin < end)
{
while (begin < end && !isLetter(S[begin]))
++begin;
while (begin < end && !isLetter(S[end]))
--end;
swap(S[begin], S[end]);
++begin;
--end;
}
return S;
}
};
找字符串中第一个只出现一次的字符
class Solution{
public:
int firstUniqChar(string s) {
// 统计每个字符出现的次数
int count[256] = {0};
int size = s.size();
for (int i = 0; i < size; ++i)
count[s[i]] += 1;
// 按照字符次序从前往后找只出现一次的字符
for (int i = 0; i < size; ++i)
if (1 == count[s[i]])
return i;
return -1;
}
};字符串里面最后一个单词的长度
#include<iostream>
#include<string>
using namespace std;
int main()
{
string line;
// 不要使用cin>>line,因为会它遇到空格就结束了
// while(cin>>line)
while (getline(cin, line))
{
size_t pos = line.rfind(' ');
cout << line.size() - pos - 1 << endl;
}
return 0;
}验证一个字符串是否回文
class Solution {
public:
bool isPalindrome(string s) {
int begin = 0;
int end = s.size() - 1;
while (begin < end)
{
while (!isalpha(s[begin]) && !isdigit(s[begin]) && begin < end)
begin++;
while (!isalpha(s[end]) && !isdigit(s[end]) && begin < end)
end--;
if (s[begin] >= 'A' && s[begin] <= 'Z')
s[begin] = tolower(s[begin]);
if (s[end] >= 'A' && s[end] <= 'Z')
s[end] = tolower(s[end]);
if (s[begin] != s[end])
return false;
if (begin < end)
{
++begin;
--end;
}
}
return true;
}
};字符串相加
class Solution {
public:
string addStrings(string num1, string num2) {
int end1 = num1.size() - 1;
int end2 = num2.size() - 1;
string str;
//进位
int next = 0;
while(end1 >= 0 || end2 >= 0)
{
int value1 = 0,value2 = 0;
if(end1 >= 0)
value1 = num1[end1--] - '0';
if(end2 >= 0)
value2 = num2[end2--] - '0';
int addvalue = value1 + value2 + next;
next = addvalue/10;
addvalue %= 10;
str.insert(0,1,addvalue + '0');
}
if(next == 1)
{
str.insert(0,1,'1');
}
return str;
}
};