1、vue中模拟鼠标点击下拉框
<xxx-select
ref="aaa"
:value="form.serviceCharge"
placeholder="请输入"
@add="(value) => getBasGoods(value)"
:configInfo="configInfo"
/>
vue中模拟鼠标点击
this.$refs.aaa.$el.click()
2、springboot服务假死
linux服务器查看cpu和内存
top -c
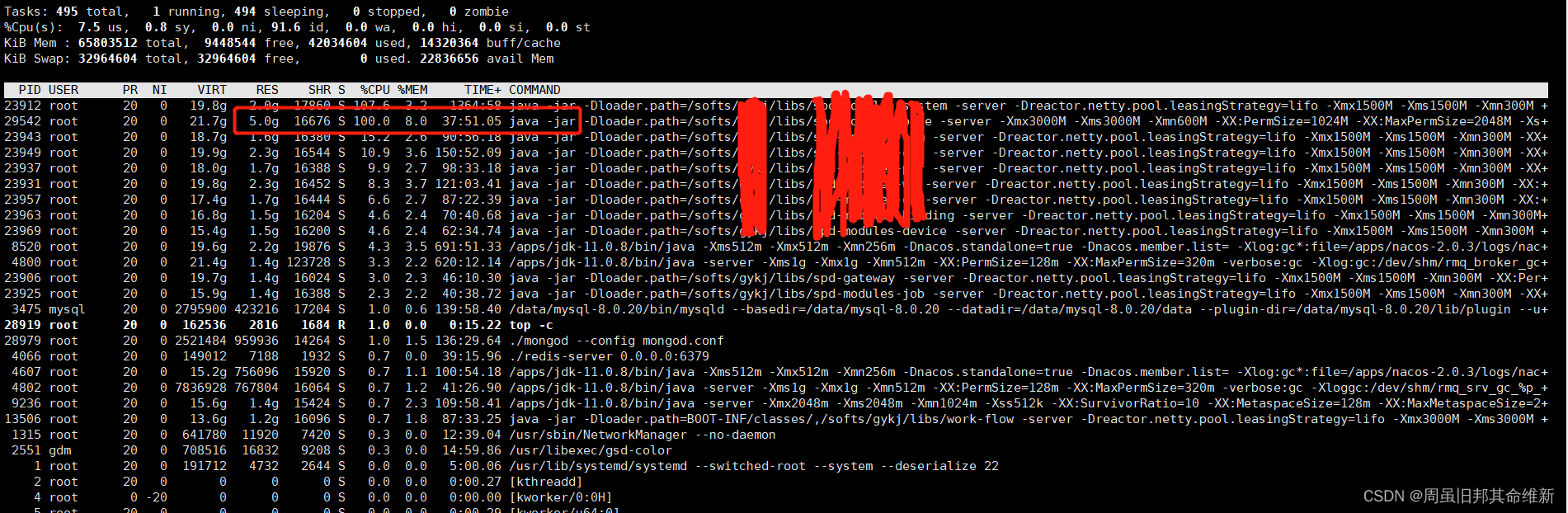
可以看到pid为29542的进程占用内存在导出时一直升高,查看进程堆栈信息:
jstack 29542
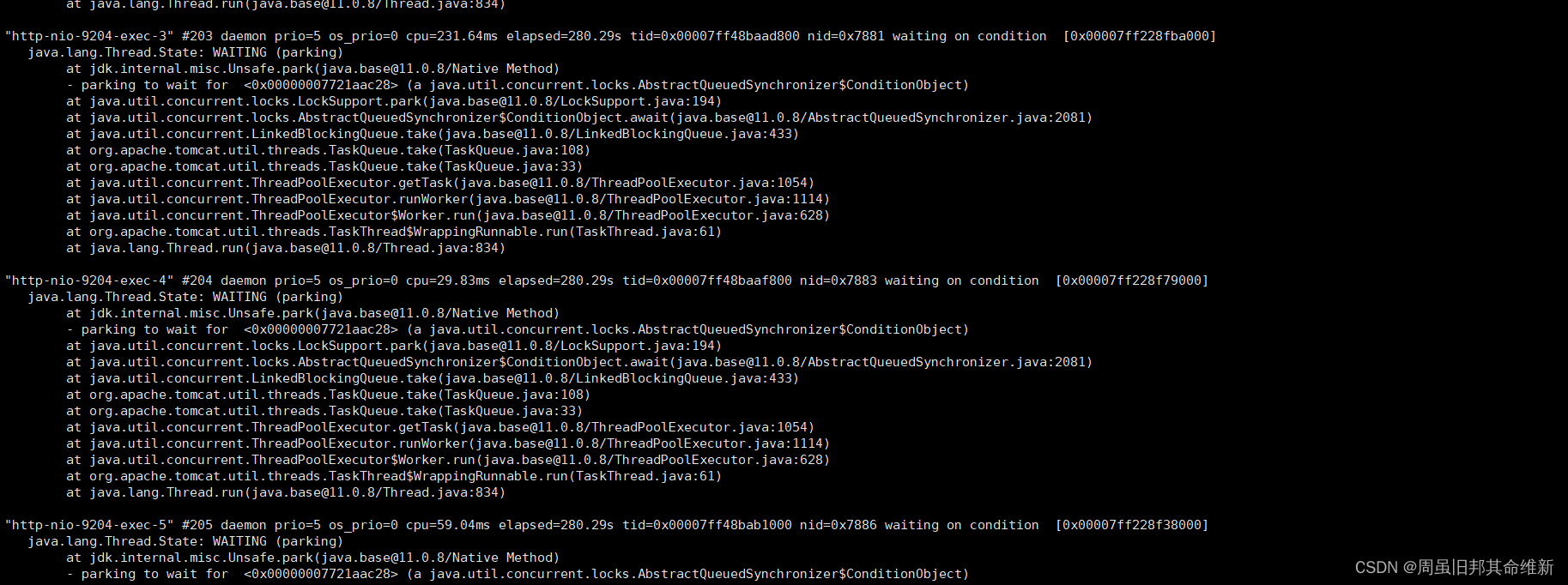
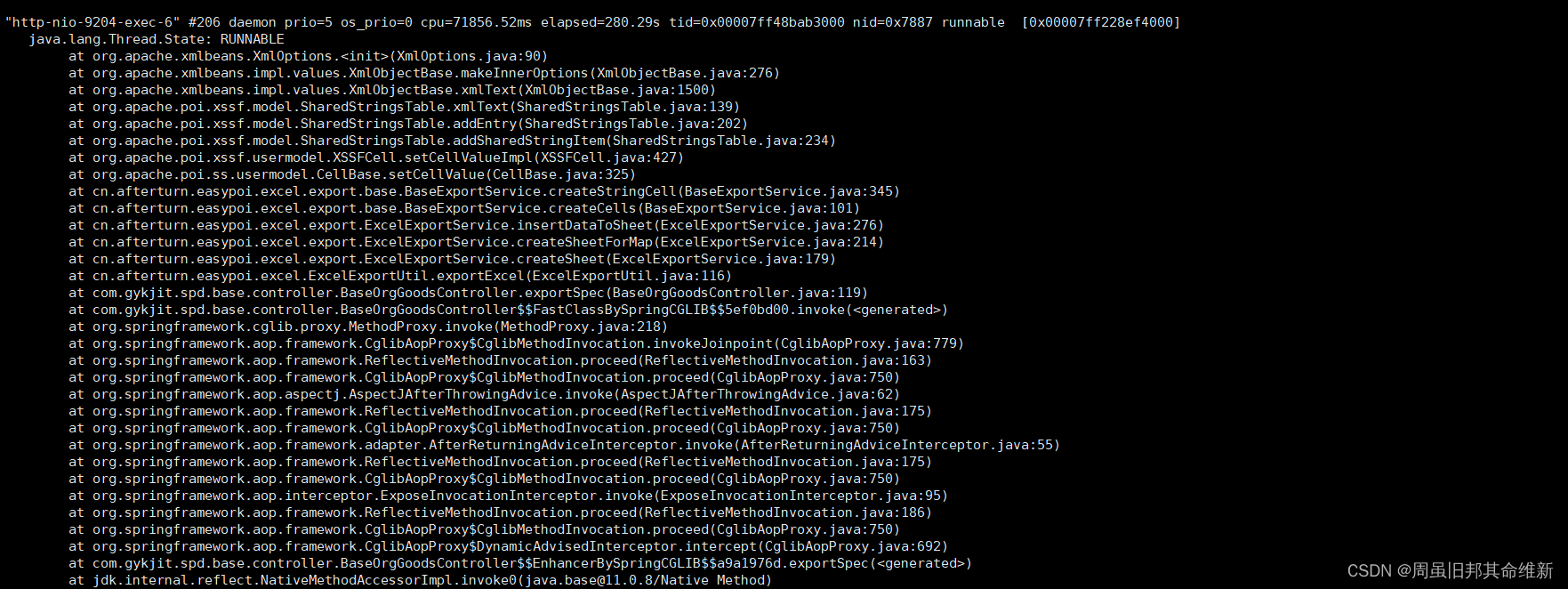
发现有很多线程都在WAITING,同时在堆栈信息中找到基础服务的一个导出相关业务日志,通过top -c命令观察这个导出操作前后的cpu和内存资源变化,发现大数据量导出时内存在持续上升,直至服务假死。
3、linux创建root权限账号并修改密码
sudo useradd -ou 0 -g 0 fox
sudo passwd fox
4、springboot服务假死
实时监控服务内存及gc情况
jstat -gc <java_pid> 5000
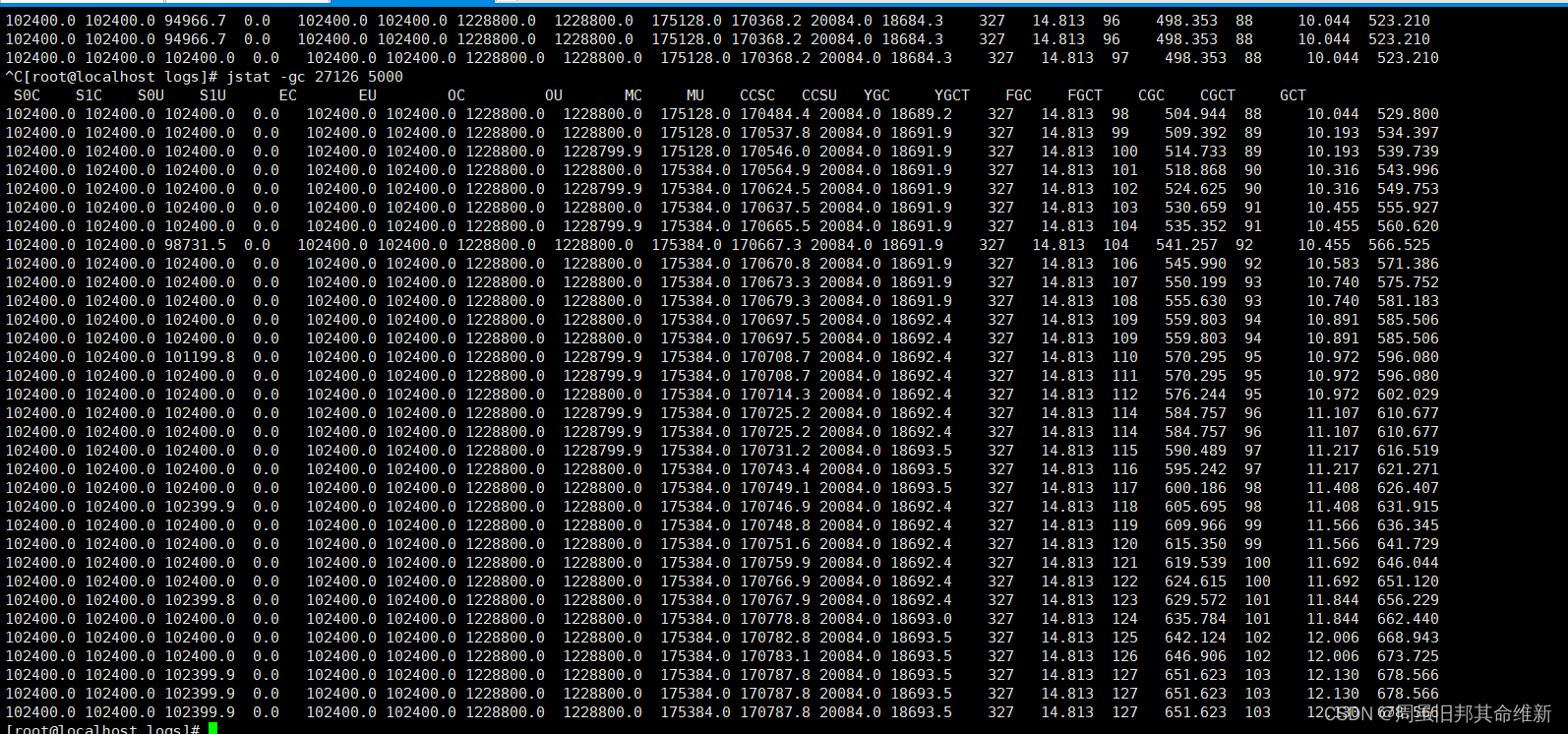
发现进程随着启动时间越来越长,年轻代和老年代内存使用率越来越高,导致频繁gc
通过服务器上安装的arthas工具查看
java -jar arthas-boot.jar 13156
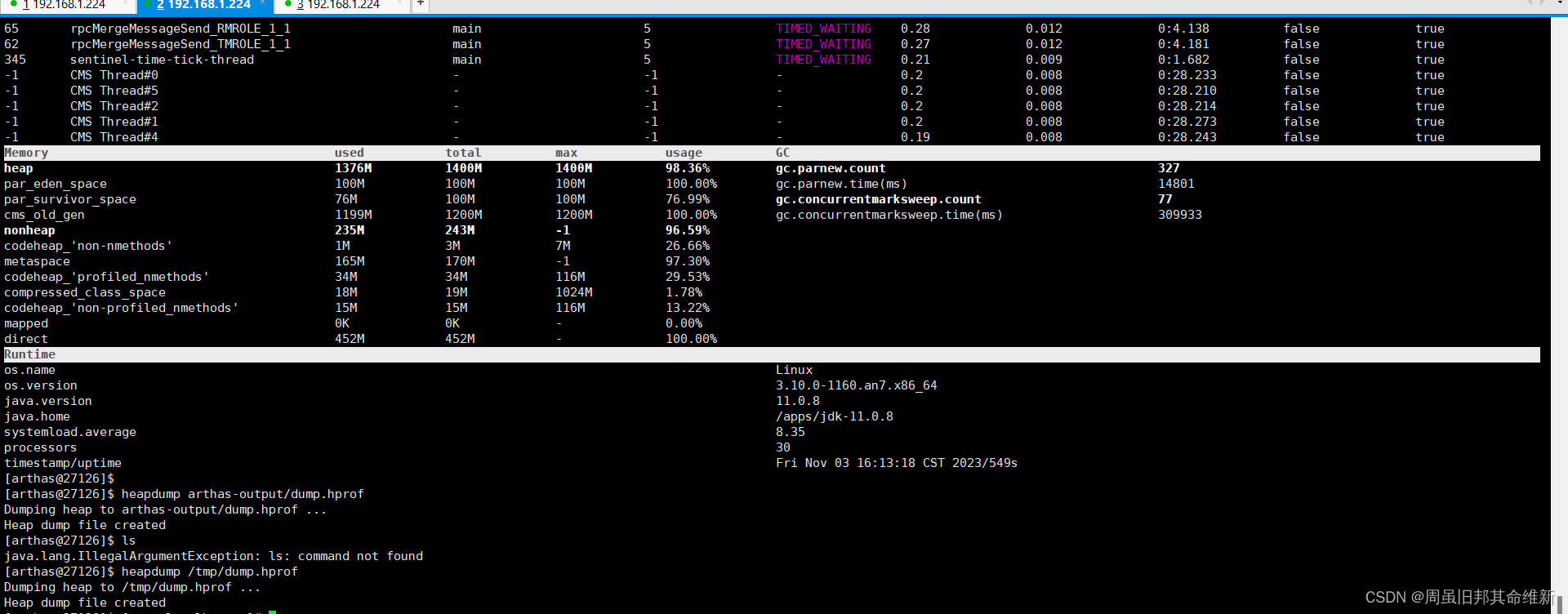
通过arthas导出dump文件
heapdump /tmp/1/dump.hprof
使用visualvm分析dump文件,发现大对象中排在前面的对象多数都和swagger有关
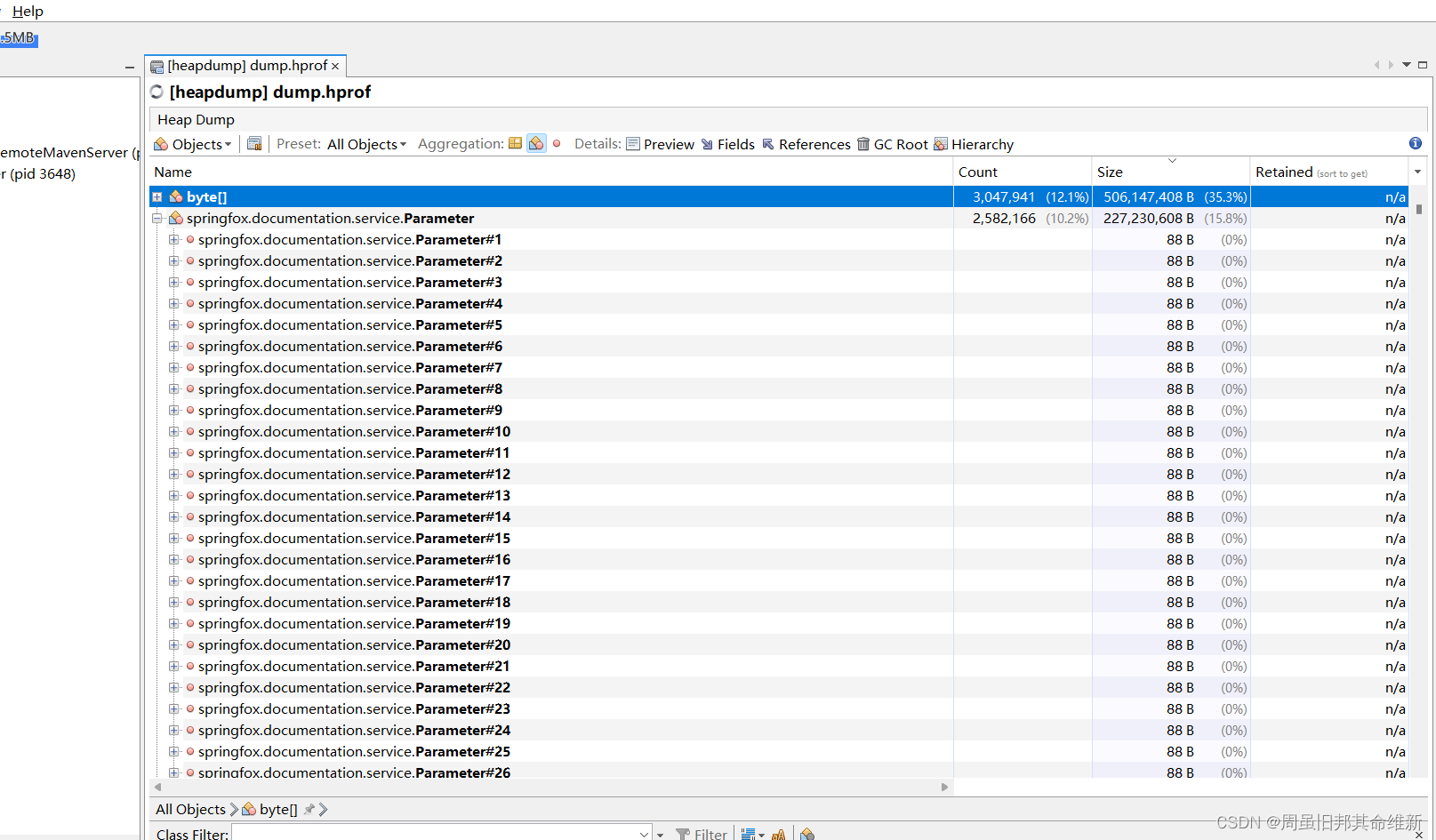
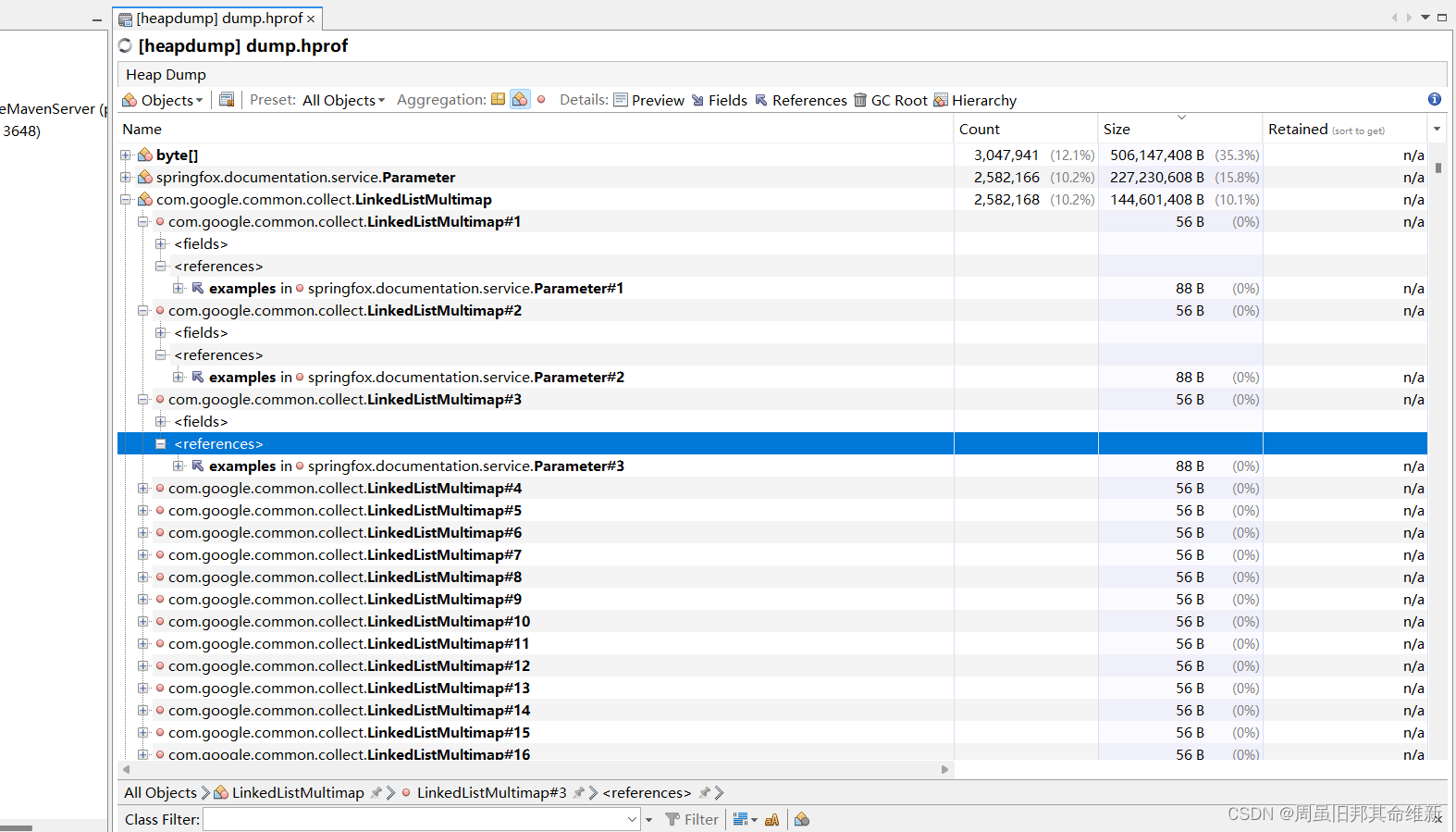
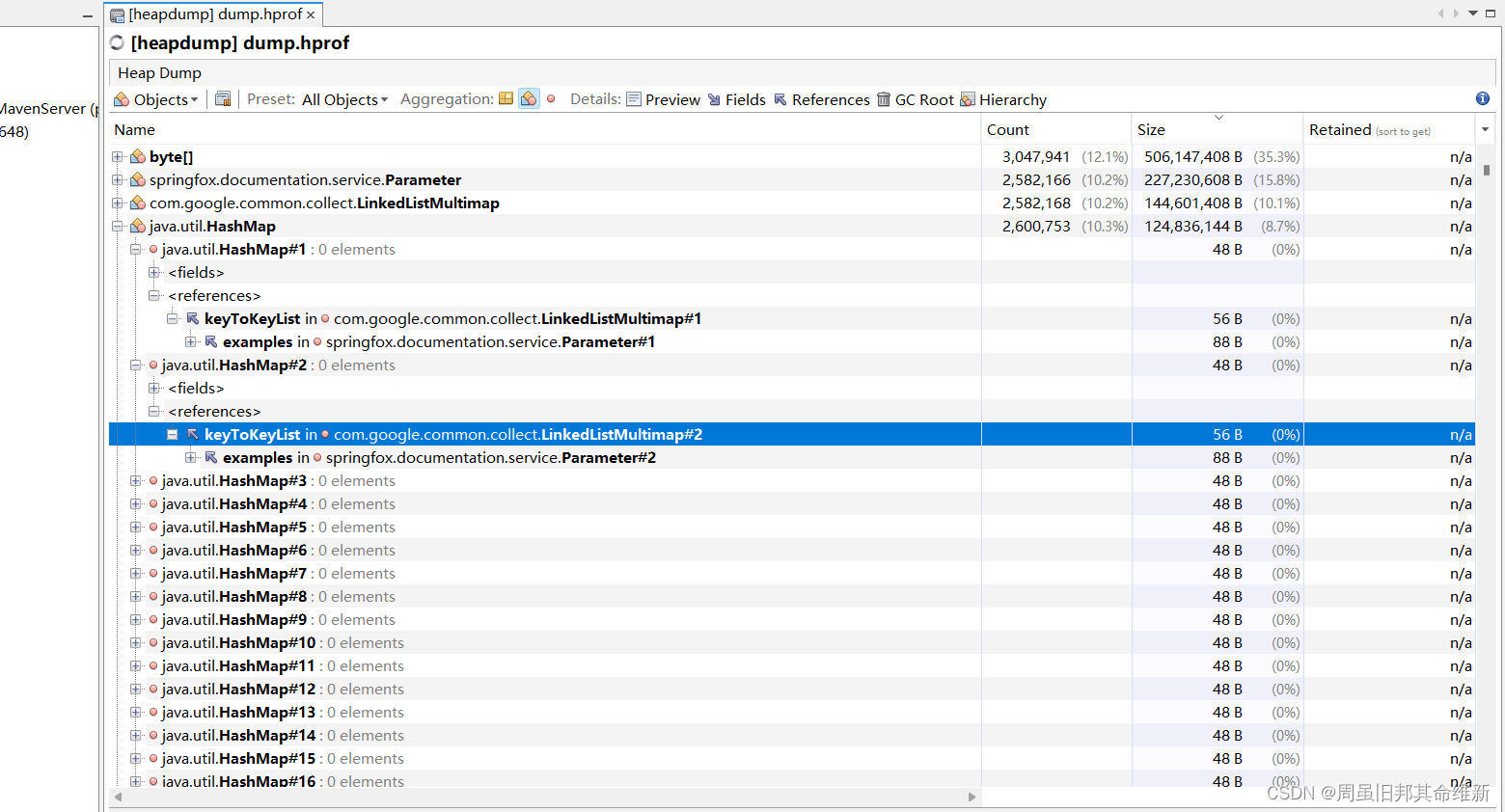
解决方法:正式分支代码去除swagger自动配置
修改后服务重新启动,运行一段时间后观察内存占用稳定,没有出现内存打满的情况。
5、seata死锁问题
业务场景:微服务A和B操作的是同一条数据,A在对数据进行修改后,经过一些列判断调用B,B在经过一些业务处理后对数据进行删除。
现象:A在调用B后进入阻塞等待,B在执行到对数据进行删除的操作时阻塞,日志未打印删除语句,B服务经过近5分钟阻塞后打印删除语句,以及一条SELECT FOR UPDATE 语句,日志显示SELECT FOR UPDATE 语句执行花费近5分钟,此时看A的日志也阻塞结束,异常信息为调用超时
分析:在阻塞之后,看日志打印时间A的调用超时报错信息先出现,B的日志打印删除语句及SELECT FOR UPDATE 语句后出现,猜测是出现死锁,A超时后释放锁以后B才取得锁继续执行。且SELECT FOR UPDATE 语句在整个项目中都不存在,猜测和项目中使用的分布式事物框架seta可能有关。
查看seata官网文档,分析seata事物的流程
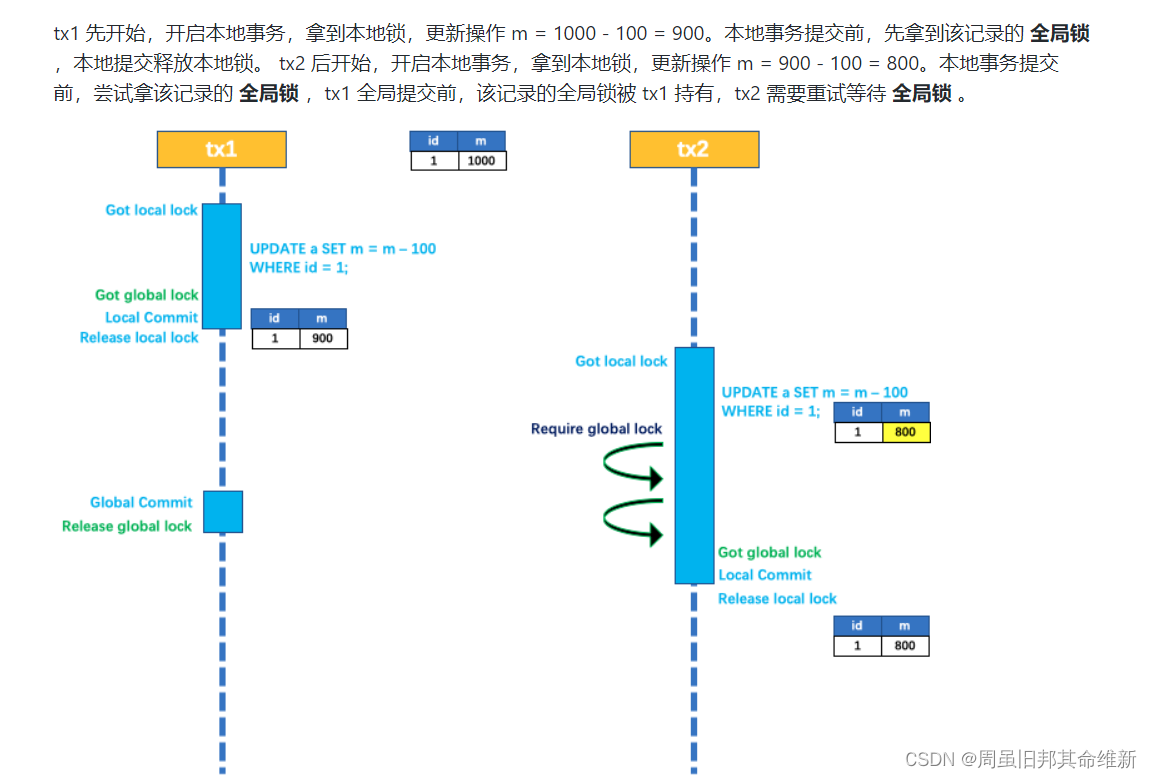
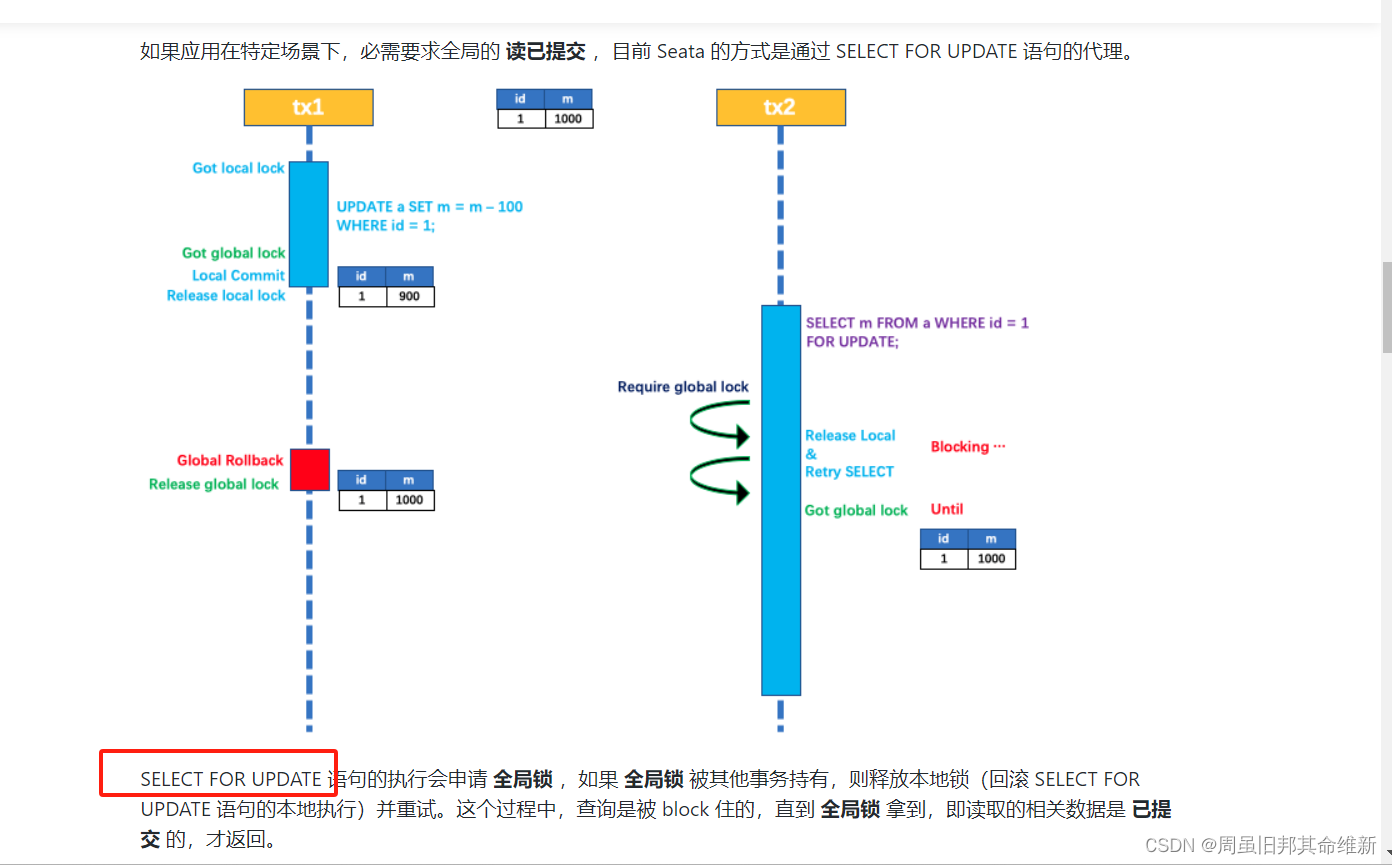
根据官网文档分析阻塞前后的流程:
- A获取本地锁
- A执行更新操作
- 本地事务提交前,尝试拿该记录的全局锁
- 本地事物提交,释放本地锁
- A调用B,A进入阻塞等待
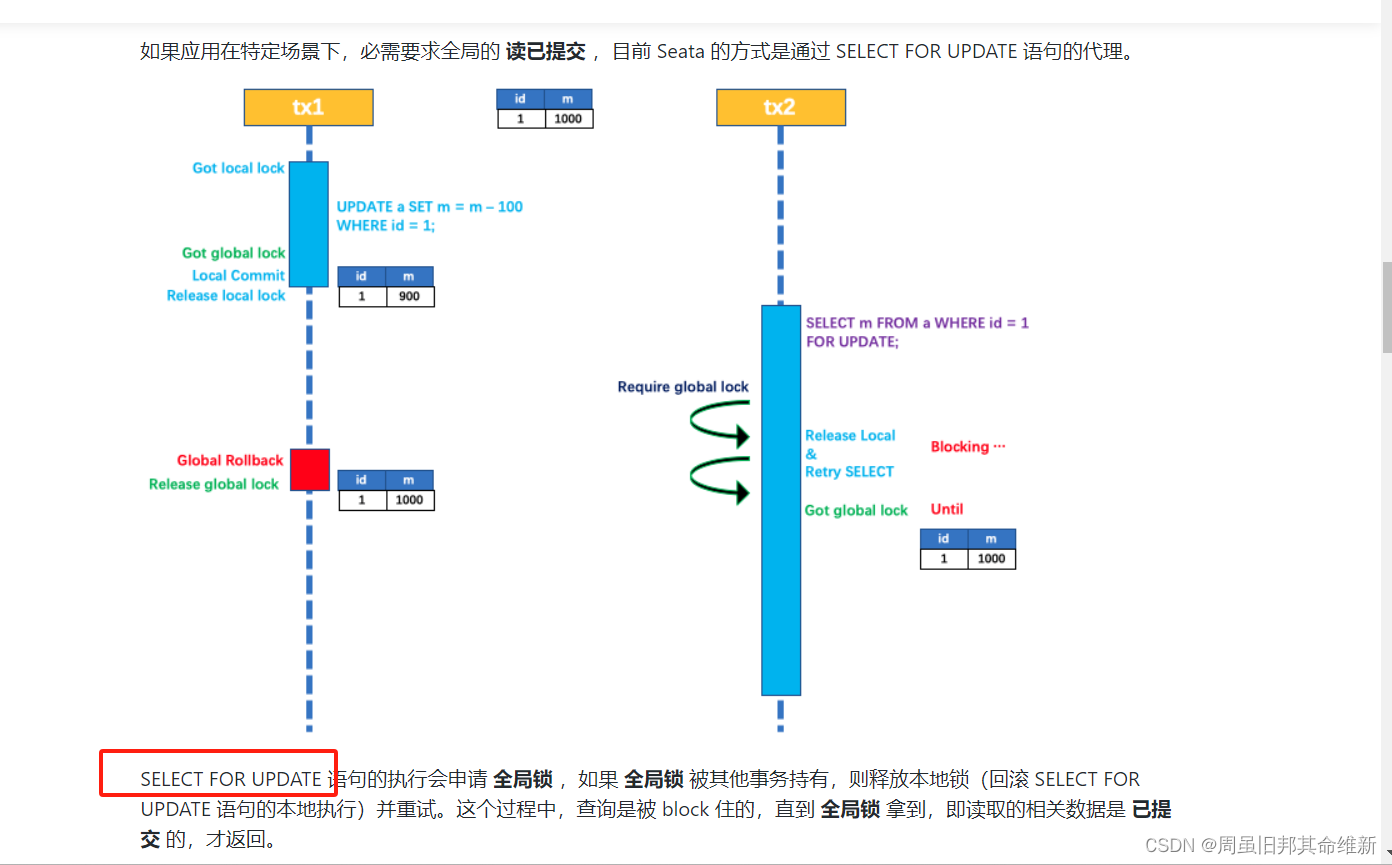
- B获取本地锁
- B进行删除操作前,先根据删除语句构建出前置镜像 TableRecords,执行sql语句,根据前置镜像的主键id构建出执行sql之后的查询sql语句,根据修改之后记录构建后置镜像(即B日志信息中的SELECT FOR UPDATE 语句)
- SELECT FOR UPDATE 语句的执行会申请全局锁,如果 全局锁 被其他事务持有,则释放本地锁(回滚 SELECT FOR UPDATE 语句的本地执行)并重试。
- B进入阻塞等待
- A调用超时,释放全局锁
- B执行删除操作,打印SELECT FOR UPDATE 语句
6、在node节点执行kubectl命令报错
error: no configuration has been provided, try setting KUBERNETES_MASTER environment variable
问题原因:kubectl命令需要使用kubernetes-admin来运行
问题解决:
1.将主节点中的/etc/kubernetes/admin.conf文件拷贝到从node节点相同目录下
2.配置环境变量
[root@node-192-168-137-131 kubernetes]# echo "export KUBECONFIG=/etc/kubernetes/admin.conf" >> ~/.bash_profile
[root@node-192-168-137-131 kubernetes]# source ~/.bash_profile
再次执行kubectl命令成功

这里我们会发现,为何不需要指定api-server地址就可以直接执行相关命令,那是因为刚刚我们从master节点拷贝过来的admin.conf这个配置文件存放的是k8s用户权限相关的配置!
7、远程debug
服务器jar包启动配置
nohup java -jar -Dloader.path=$GLOBAL_PATH/libs/xx -agentlib:jdwp=transport=dt_socket,server=y,suspend=n,address=192.168.1.xx:5005 $JAVA_OPTS $SPD_WM > $SPD_WM_LOG 2>&1 &
本地idea配置
-agentlib:jdwp=transport=dt_socket,server=y,suspend=n,address=*:5005

8、线上服务异常堆栈信息未打印
线上服务报错的时候,我们自然而然想到的是根据日志或者其他手段查看报错的具体异常,但是有些时候我们却发现异常没有堆栈信息。只有短短的异常类信息,例如
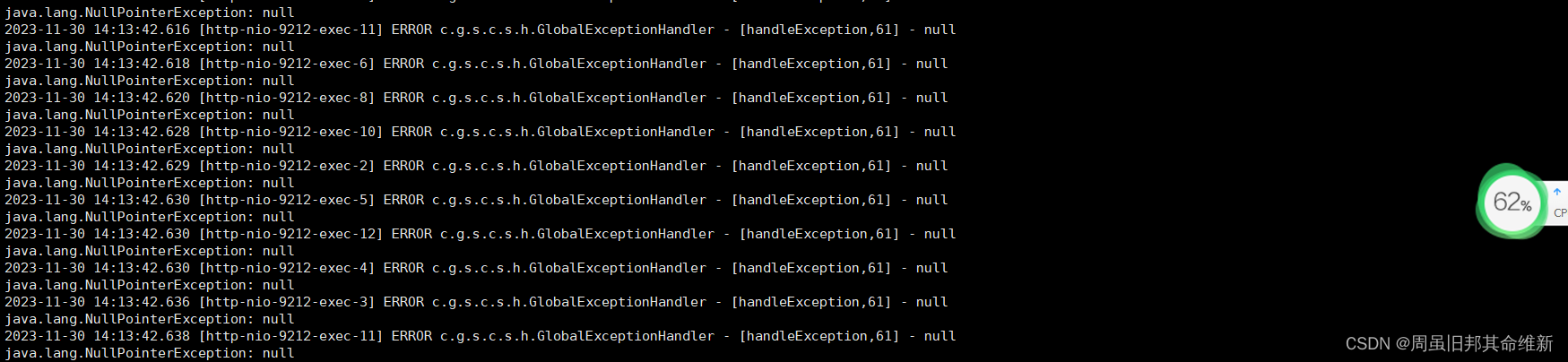
这种行为是JVM为了提升性能,对于JIT编译后的代码,在一定条件下使用预先生成的异常代替真正的异常对象,这些预先生成的异常没有堆栈,抛出速度非常快也无需额外分配内存。
JDK5中引入了-XX:-OmitStackTraceInFastThrow这个参数,具体可以看release note.
The compiler in the server VM now provides correct stack backtraces for all “cold” built-in exceptions. For performance purposes, when such an exception is thrown a few times, the method may be recompiled. After recompilation, the compiler may choose a faster tactic using preallocated exceptions that do not provide a stack trace. To disable completely the use of preallocated exceptions, use this new flag: -XX:-OmitStackTraceInFastThrow.
接下来,我们继续详细了解下触发异常fastthrow的触发条件和动机和关闭后的潜在影响。
FastThrow动机和触发条件
bool treat_throw_as_hot = false;
ciMethodData* md = method()->method_data();
if (ProfileTraps) {
//如果有太多次,则 treat_throw_as_hot 为 true
if (too_many_traps(reason)) {
treat_throw_as_hot = true;
}
if (C->trap_count(reason) != 0
&& method()->method_data()->trap_count(reason) != 0
&& has_ex_handler()) {
treat_throw_as_hot = true;
}
}
if (treat_throw_as_hot
&& (!StackTraceInThrowable || OmitStackTraceInFastThrow)) {
ciInstance* ex_obj = NULL;
switch (reason) {
case Deoptimization::Reason_null_check:
//对于 NullPointerException 返回对应的空堆栈的内置 NullPointerException 对象
ex_obj = env()->NullPointerException_instance();
break;
case Deoptimization::Reason_div0_check:
//对于 ArithmeticException 返回对应的空堆栈的内置 ArithmeticException 对象
ex_obj = env()->ArithmeticException_instance();
break;
case Deoptimization::Reason_range_check:
//对于 ArrayIndexOutOfBounds 返回对应的空堆栈的内置 NullPoArrayIndexOutOfBoundsinterException 对象
ex_obj = env()->ArrayIndexOutOfBoundsException_instance();
break;
case Deoptimization::Reason_class_check:
if (java_bc() == Bytecodes::_aastore) {
//对于 ArrayStoreException 返回对应的空堆栈的内置 ArrayStoreException 对象
ex_obj = env()->ArrayStoreException_instance();
} else {
//对于 ClassCastException 返回对应的空堆栈的内置 ClassCastException 对象
ex_obj = env()->ClassCastException_instance();
}
break;
default:
break;
}
当某个 JDK 内置异常通过某一个方法抛出过多次数时(常见是 NullPointerException),自动省略异常堆栈,其实就是 Throwable.getOurStacktrace() 返回空数组。底层实现的方式是当这些异常被抛出时,会记录在方法的 method_data 中。当这些异常被抛出时,检查对应方法的 method_data 是否有过多次数的这些异常被抛出,如果有,则使用不含堆栈的异常对象替换原有异常对象从而实现异常堆栈被忽略。
那么从上面的jdk代码可以看出同时满足以下四个条件,异常才会被预定义的无堆栈异常替换。
-
treat_throw_as_hot, 一般就是hot exception, 该异常已经被抛过很多次了,具体怎么判定可以看你下面代码
- 同样的异常抛出太多
- 同样的异常抛出次数不为0以及方法拥有local-exceptionn-handler,那么将抛出的所有同类型异常都认为是hot。local-exception-handler是否存在取决于该方法或者调用路径上的任何一个caller方法是否有exception handler,需要读method的元数据。
-
!StackTraceInThrowable || OmitStackTraceInFastThrow, 由于这两个参数值默认都是true,所以默认整体条件满足。
-
异常是设定内的五种异常
- NullPointerException
- ArithmeticException
- ArrayIndexOutOfBoundsException
- ArrayStoreException
- ClassCastException
但是,我们一般会在 JVM 启动参数中加入 -XX:-OmitStackTraceInFastThrow 将其关闭,主要原因是:
- OmitStackTraceInFastThrow 这个参数仅针对某些 Java 内置异常(上面源码已经列出),对于我们自定义或者框架自定义的异常没用。
- 分析是否过多,仅对于抛出异常的方法,但是是否是同一调用路径,并没有考虑。
- 微服务线程可能会运行很长时间,我们业务日志量非常大,每一个小时产生一个新文件。假设某个方法每天抛出一定量的 NullPointerException 但是不多,并没有及时发现。日积月累,某一天突然就没有堆栈了。之后如果这个方法大量抛出 NullPointerException,我们却看不到堆栈,还得去挨个翻之前的日志,这样太低效率了。
关闭Fast Throw方法,添加启动参数:
-XX:-OmitStackTraceInFastThrow
异常日志精简手段参考https://zhuanlan.zhihu.com/p/428375711


![ElementPlusError: [ElPagination] 你使用了一些已被废弃的用法,请参考 el-pagination 的官方文档](https://img-blog.csdnimg.cn/f3345dafc51640b98eec9572a2852ec3.png)