0 引言
设想这样的场景:你是一个工作室的老板,你的工作室主要用来生产名画的赝品;而真正的名画则为前人所创造,存放在收藏室中。你的赝品画会和真品画一起被鉴定家鉴定,而你的终极目标是成为一个以假乱真的工艺大师。通往目标的路自然十分坎坷,你首先要做的就是以假乱真。实际上,以假乱真相对容易一些,毕竟骗过一个毛头小子也能说是以假乱真,但让权威的鉴定专家也能眼拙就十分困难了。而你既然目的是成为一个工艺大师,那自然不会仅仅满足与骗过小白。于是你找上了一个立志于成为鉴定专家的人,你让他鉴定你伪造的画和真画,他会告诉你他的鉴定结果,让你能够知道自己的画是否被鉴定出来了,以便更好地提升技术;相反,你也会告诉他有没有鉴定出你的赝品画,让他的鉴定技艺也不断进步。
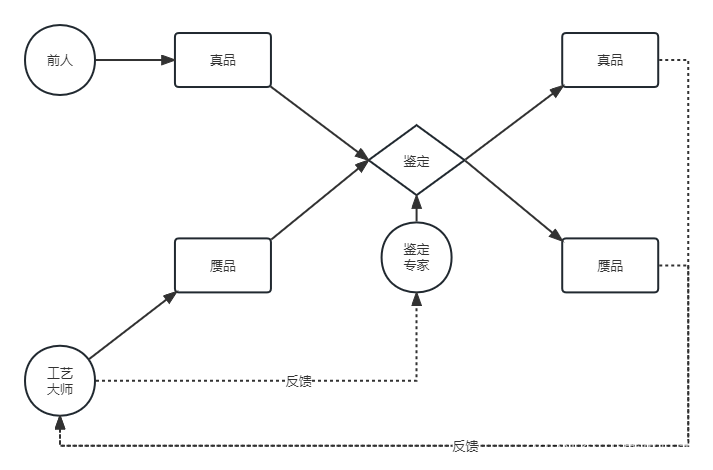
上述例子中,工艺大师模仿名画创造赝品,即生成器捕捉真实数据样本的潜在分布,并生成新的数据样本;鉴定专家判断送到眼前的画是真品还是赝品,即判别器判别输入是真实数据还是生成的样本。
1 简介
生成对抗网络(Generative Adversarial Nets,GAN)于 2014 年由 Ian J. Goodfellow 提出。GAN 的基本思想源自博弈论的二人零和博弈,由一个生成器和一个判别器构成,通过对抗学习的方式来训练。目的是估测数据样本的潜在分布并生成新的数据样本。 GAN 的优化过程是一个极小极大博弈 (Minimax game) 问题,优化目标是达到纳什均衡,使生成器估测到数据样本的分布。GAN 在图像和视觉计算、语音和语言处理、信息安全、棋类比赛等领域正在被广泛研究,具有巨大的应用前景。
2 基本原理
GAN 的核心思想来源于博弈论的纳什均衡。它设定参与游戏双方分别为一个生成器(Generator)和一个判别器 (Discriminator),生成器的目的是尽量去学习真实的数据分布,而判别器的目的是尽量正确判别输入数据是来自真实数据还是来自生成器;为了取得游戏胜利,这两个游戏参与者需要不断优化,各自提高自己的生成能力和判别能力,这个学习优化过程就是寻找二者之间的一个纳什均衡。
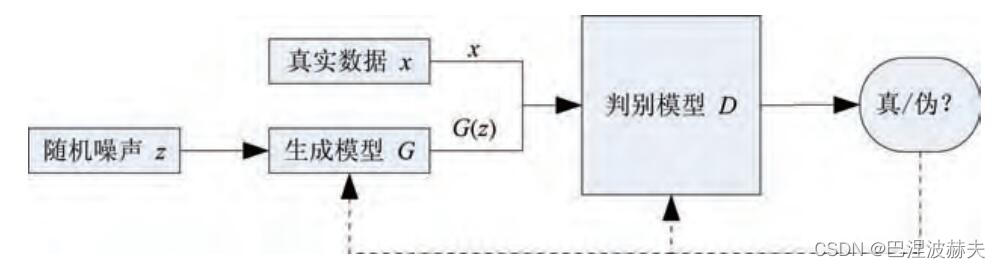
GAN 的计算流程与结构如上图所示,任意可微分的函数都可以用来表示 GAN 的生成器和判别器,由此,我们可以用可微函数 D D D 和 G G G 来分别表示判别器和生成器,他们的输入分别为真实数据分布 x x x 和随机变量 z z z 。 G G G 将随机变量 z z z (例如高斯分布,记作 p z p_z pz)映射成 G ( z ) G(z) G(z), G ( z ) G(z) G(z) 服从于一个尽可能逼近真实数据分布 p d a t a p_{data} pdata 的概率分布,这个概率分布通常记为 p g p_g pg。
对于判别器 D D D ,如果输入来自真实数据,则返回 1;如果输入是 G ( z ) G(z) G(z),则标注为 0。这里 D D D 的目标是实现对数据来源的二分类判别:
- 真——来源于真实数据 x x x 的分布;
- 伪——来源于生成器的伪数据 G ( z ) G(z) G(z)。
而 G G G 的目标是使自己生成的伪数据 G ( z ) G(z) G(z) 在 D D D 上表现 D ( G ( z ) ) D(G(z)) D(G(z)) 和真实数据 x x x 在 D D D 上表现 D ( x ) D(x) D(x) 一致。
D D D 和 G G G 相互对抗并迭代优化的过程使得二者性能不断提升,当最终 D D D 的判别能力提升到一定程度(成为鉴定专家),并且无法正确判别数据来源时,可以认为这个生成器 G G G 已经学到了真实数据的分布(成为工艺大师)。
3 目标函数
根据第 2 节内容可知,判别器的目标是,若输入
x
x
x 来自
p
d
a
t
a
p_{data}
pdata,则
D
(
x
)
D(x)
D(x) 应尽可能大;若输入
x
x
x 来自
p
g
p_g
pg ,则
1
−
D
(
G
(
z
)
)
1-D(G(z))
1−D(G(z)) 应尽可能大。为了目标函数更易表达,对二者取对数,即
log
D
(
x
)
\log D(x)
logD(x) 与
log
(
1
−
D
(
G
(
z
)
)
)
\log (1-D(G(z)))
log(1−D(G(z)))。数学公式为:
max
D
E
x
∼
p
d
a
t
a
[
log
D
(
x
)
]
+
E
z
∼
p
z
[
log
(
1
−
D
(
G
(
z
)
)
)
]
\max_D E_{x\sim p_{data}}\big[\log D(x)\big] + E_{z\sim p_z}\big[\log (1-D(G(z)))\big]
DmaxEx∼pdata[logD(x)]+Ez∼pz[log(1−D(G(z)))]
这里期望即为
1
N
∑
i
=
1
N
log
D
(
x
i
)
\frac1N\sum_{i=1}^N\log D(x_i)
N1∑i=1NlogD(xi)。
生成器的目标是,生成的
G
(
z
)
G(z)
G(z) 尽可能被鉴定器
D
D
D 识别为真实数据,即
D
(
G
(
z
)
)
D(G(z))
D(G(z)) 尽可能大,或者说
1
−
D
(
G
(
z
)
)
1-D(G(z))
1−D(G(z)) 尽可能小。同理,将其取对数,则数学公式为:
min
G
E
z
∼
p
z
[
log
(
1
−
D
(
G
(
z
)
)
)
]
\min_G E_{z\sim p_z}\big[\log (1-D(G(z)))\big]
GminEz∼pz[log(1−D(G(z)))]
根据两者的目标函数可知,
D
D
D 和
G
G
G 之前存在彼之所得必为吾之所失的关系,二者构成了一个零和博弈。
还记得第 0 节提到的例子嘛,我们不仅要骗过毛头小子,还要骗过鉴定专家。对应到
D
D
D 与
G
G
G 上就是,
G
G
G 产生的假样本能够骗过鉴别能力一流的
D
D
D。因此,在 GAN 的思路中,
D
D
D 只是工具,我们的终极目标还是
G
G
G,于是我们便得到了 GAN 优化的总目标,它是一个极小极大化问题,描述如下:
min
G
max
D
E
x
∼
p
d
a
t
a
[
log
D
(
x
)
]
+
E
z
∼
p
z
[
log
(
1
−
D
(
G
(
z
)
)
)
]
\min_G\max_D E_{x\sim p_{data}}\big[\log D(x)\big] + E_{z\sim p_z}\big[\log (1-D(G(z)))\big]
GminDmaxEx∼pdata[logD(x)]+Ez∼pz[log(1−D(G(z)))]
4 全局最优解的存在性
上一节我们从逻辑上构造出 GAN 的总体目标函数,并且 p d a t a = p g p_{data} = p_g pdata=pg 时应达到全局最优解(即 G G G 生成的伪样本与真样本别无二致)。
对于 GAN 的学习过程,我们需要训练模型 D D D 来最大化判别数据来源于真实数据 x x x 或者伪数据分布 G ( z ) G(z) G(z) 的准确率,同时,我们需要训练模型 G G G 来最小化 log ( 1 − D ( G ( z ) ) ) \log (1-D(G(z))) log(1−D(G(z)))。这里可以采用交替优化的方法:先固定生成器 G G G ,优化判别器 D D D,使得 D D D 的判别准确率最大化;然后固定判别器 D D D,优化生成器 G G G,使得 D D D 的判别准确率最小化。当且仅当 p d a t a = p g p_{data} = p_g pdata=pg 时达到全局最优解。
在实际训练中,同一轮参数更新时,一般对 D D D 的参数更新 k k k 次再对 G G G 的参数更新 1 次。
接下来我们证明全局最优解的情况下
p
d
a
t
a
=
p
g
p_{data} = p_g
pdata=pg 究竟是否成立。由于
z
∼
p
z
z\sim p_z
z∼pz 时
G
(
z
)
G(z)
G(z) 的结果与
x
∼
p
g
x\sim p_g
x∼pg 时的
x
x
x 等价,所以,可以记
V
(
D
,
G
)
=
E
x
∼
p
d
a
t
a
[
log
D
(
x
)
]
+
E
x
∼
p
g
[
log
(
1
−
D
(
x
)
)
]
V(D,G) = E_{x\sim p_{data}}\big[\log D(x)\big] + E_{x\sim p_g}\big[\log (1-D(x))\big]
V(D,G)=Ex∼pdata[logD(x)]+Ex∼pg[log(1−D(x))]
首先,在给定生成器
G
G
G 的情况下,我们只考虑优化判别器
D
D
D ,即
max
D
V
(
D
,
G
)
\max_D V(D,G)
maxDV(D,G),而
V
(
D
,
G
)
=
E
x
∼
p
d
a
t
a
[
log
D
(
x
)
]
+
E
x
∼
p
g
[
log
(
1
−
D
(
x
)
)
]
=
∫
p
d
a
t
a
⋅
log
D
d
x
+
∫
p
g
log
(
1
−
D
)
d
x
=
∫
[
p
d
a
t
a
⋅
log
D
+
p
g
log
(
1
−
D
)
]
d
x
\begin{align} V(D,G) &= E_{x\sim p_{data}}\big[\log D(x)\big] + E_{x\sim p_g}\big[\log (1-D(x))\big]\\ &= \int p_{data}\cdot \log D dx + \int p_g\log(1-D)dx\\ &= \int \Big[ p_{data}\cdot \log D + p_g\log(1-D)\Big]dx \end{align}
V(D,G)=Ex∼pdata[logD(x)]+Ex∼pg[log(1−D(x))]=∫pdata⋅logDdx+∫pglog(1−D)dx=∫[pdata⋅logD+pglog(1−D)]dx
上述等式用到了概率论的基本知识,简单回顾一下:
设连续型随机变量 X X X 的概率密度为 f ( x ) f(x) f(x) ,如果积分 ∫ − ∞ + ∞ x f ( x ) d x \int_{-\infty}^{+\infty}xf(x)dx ∫−∞+∞xf(x)dx 绝对收敛,则称此积分为随机变量 X X X 的数学期望或均值,记作 E ( X ) E(X) E(X) ,即
E ( x ) = ∫ − ∞ + ∞ x f ( x ) d x E(x) = \int_{-\infty}^{+\infty}xf(x)dx E(x)=∫−∞+∞xf(x)dx
设连续型随机变量 X X X 的概率密度为 f ( x ) f(x) f(x) ,如果积分 ∫ − ∞ + ∞ g ( x ) f ( x ) d x \int_{-\infty}^{+\infty}g(x)f(x)dx ∫−∞+∞g(x)f(x)dx 绝对收敛,则称此积分为随机变量 Y = g ( X ) Y=g(X) Y=g(X) 的数学期望或均值,即
E ( Y ) = E [ g ( X ) ] = ∫ − ∞ + ∞ g ( x ) f ( x ) d x E(Y) = E\big[g(X)\big] = \int_{-\infty}^{+\infty}g(x)f(x)dx E(Y)=E[g(X)]=∫−∞+∞g(x)f(x)dx
由于只考虑
D
D
D,因此考虑令
V
(
D
,
G
)
V(D,G)
V(D,G) 对
D
D
D 求偏导
∂
∂
D
V
(
D
,
G
)
=
∂
∂
D
∫
[
p
d
a
t
a
⋅
log
D
+
p
g
log
(
1
−
D
)
]
d
x
=
∫
∂
∂
D
[
p
d
a
t
a
⋅
log
D
+
p
g
log
(
1
−
D
)
]
d
x
=
∫
[
p
d
a
t
a
⋅
1
D
+
p
g
−
1
1
−
D
]
d
x
\begin{align} \frac{\partial}{\partial D}V(D,G) &= \frac{\partial}{\partial D}\int\Big[ p_{data}\cdot \log D + p_g\log(1-D)\Big]dx\\ &= \int\frac{\partial}{\partial D}\Big[ p_{data}\cdot \log D + p_g\log(1-D)\Big]dx\\ &= \int \Big[p_{data}\cdot\frac1D + p_g\frac{-1}{1-D} \Big]dx \end{align}
∂D∂V(D,G)=∂D∂∫[pdata⋅logD+pglog(1−D)]dx=∫∂D∂[pdata⋅logD+pglog(1−D)]dx=∫[pdata⋅D1+pg1−D−1]dx
我们要求的是
max
D
V
(
D
,
G
)
\max_DV(D,G)
maxDV(D,G) ,故令上式导数结果等于 0 ,即:
∫
[
p
d
a
t
a
⋅
1
D
+
p
g
−
1
1
−
D
]
d
x
=
0
\int \Big[p_{data}\cdot\frac1D + p_g\frac{-1}{1-D} \Big]dx = 0
∫[pdata⋅D1+pg1−D−1]dx=0
此时可求得:
D
G
∗
=
p
d
a
t
a
p
d
a
t
a
+
p
g
D_G^* = \frac{p_{data}}{p_{data}+p_g}
DG∗=pdata+pgpdata
此即为判别器的最优解。
再次强调, D ( x ) D(x) D(x) 表示输入 x x x 来自真实样本( x ∼ p d a t a x\sim p_{data} x∼pdata)的概率。 G ( z ) G(z) G(z) 表示输入一个 z ∼ p z z\sim p_z z∼pz ,输出一个 x ∼ p g x\sim p_g x∼pg。
将
D
G
∗
=
p
d
a
t
a
p
d
a
t
a
+
p
g
D_G^*=\frac{p_{data}}{p_{data}+p_g}
DG∗=pdata+pgpdata 代入总目标函数中,有:
min
G
max
D
V
(
D
,
G
)
=
min
G
V
(
D
G
∗
,
G
)
=
min
G
E
x
∼
p
d
a
t
a
[
log
D
G
∗
]
+
E
x
∼
p
g
[
log
(
1
−
D
G
∗
)
]
=
min
G
E
x
∼
p
d
a
t
a
[
log
p
d
a
t
a
p
d
a
t
a
+
p
g
]
+
E
x
∼
p
g
[
log
(
1
−
p
d
a
t
a
p
d
a
t
a
+
p
g
)
]
=
min
G
E
x
∼
p
d
a
t
a
[
log
p
d
a
t
a
p
d
a
t
a
+
p
g
]
+
E
x
∼
p
g
[
log
p
g
p
d
a
t
a
+
p
g
]
=
min
G
E
x
∼
p
d
a
t
a
[
log
(
p
d
a
t
a
(
p
d
a
t
a
+
p
g
)
/
2
⋅
1
2
)
]
+
E
x
∼
p
g
[
log
(
p
g
(
p
d
a
t
a
+
p
g
)
/
2
⋅
1
2
)
]
=
min
G
E
x
∼
p
d
a
t
a
[
log
(
p
d
a
t
a
(
p
d
a
t
a
+
p
g
)
/
2
)
]
+
E
x
∼
p
d
a
t
a
[
log
(
p
g
(
p
d
a
t
a
+
p
g
)
/
2
)
]
−
log
2
−
log
2
=
min
G
K
L
(
p
d
a
t
a
∣
∣
p
d
a
t
a
+
p
g
2
)
+
K
L
(
p
g
∣
∣
p
d
a
t
a
+
p
g
2
)
−
log
4
≥
−
log
4
\begin{align} \min_G\max_DV(D,G) &= \min_GV(D_G^*,G)\\ &= \min_G E_{x\sim p_{data}}\big[\log D_G^*\big] + E_{x\sim p_g}\big[\log (1-D_G^*)\big]\\ &= \min_G E_{x\sim p_{data}}\big[\log \frac{p_{data}}{p_{data}+p_g}\big] + E_{x\sim p_g}\big[\log (1-\frac{p_{data}}{p_{data}+p_g})\big]\\ &= \min_G E_{x\sim p_{data}}\big[\log \frac{p_{data}}{p_{data}+p_g}\big] + E_{x\sim p_g}\big[\log \frac{p_g}{p_{data}+p_g}\big]\\ &= \min_G E_{x\sim p_{data}}\big[\log \big(\frac{p_{data}}{(p_{data}+p_g)/2}\cdot\frac12\big)\big] + E_{x\sim p_g}\big[\log \big(\frac{p_g}{(p_{data}+p_g)/2}\cdot\frac12\big)\big]\\ &= \min_G E_{x\sim p_{data}}\big[\log \big(\frac{p_{data}}{(p_{data}+p_g)/2}\big)\big] + E_{x\sim p_{data}}\big[\log \big(\frac{p_g}{(p_{data}+p_g)/2}\big)\big] - \log2-\log2\\ &= \min_G KL(p_{data}||\frac{p_{data}+p_g}{2}) + KL(p_g||\frac{p_{data}+p_g}{2}) - \log4\\ &\ge -\log4 \end{align}
GminDmaxV(D,G)=GminV(DG∗,G)=GminEx∼pdata[logDG∗]+Ex∼pg[log(1−DG∗)]=GminEx∼pdata[logpdata+pgpdata]+Ex∼pg[log(1−pdata+pgpdata)]=GminEx∼pdata[logpdata+pgpdata]+Ex∼pg[logpdata+pgpg]=GminEx∼pdata[log((pdata+pg)/2pdata⋅21)]+Ex∼pg[log((pdata+pg)/2pg⋅21)]=GminEx∼pdata[log((pdata+pg)/2pdata)]+Ex∼pdata[log((pdata+pg)/2pg)]−log2−log2=GminKL(pdata∣∣2pdata+pg)+KL(pg∣∣2pdata+pg)−log4≥−log4
以上公式用到了 KL 散度,即相对熵(取值范围为 [ 0 , + ∞ ) [0,+\infty) [0,+∞)):
设 P ( x ) , Q ( x ) P(x),Q(x) P(x),Q(x) 是随机变量 X X X 上的两个概率分布,则在离散和连续随机变量的情形下,相对熵的定义分别为:
K L ( P ∣ ∣ Q ) = ∑ P ( x ) log P ( x ) Q ( x ) KL(P||Q) = \sum P(x)\log\frac{P(x)}{Q(x)} KL(P∣∣Q)=∑P(x)logQ(x)P(x)K L ( P ∣ ∣ Q ) = ∫ P ( x ) log P ( x ) Q ( x ) d x KL(P||Q) = \int P(x)\log\frac{P(x)}{Q(x)}dx KL(P∣∣Q)=∫P(x)logQ(x)P(x)dx
具体 KL 散度的概念、原理及推导在写了在写了(还么的建文件夹)。
因为上述公式中作为分母 p d a t a + p g p_{data}+p_g pdata+pg 是两个概率分布相加,取值范围在 [ 0 , 2 ] [0,2] [0,2] 之间,作为整体已经不能表示概率分布了,因此才有分母除 2 的操作。即令 log p g p d a t a + p g \log \frac{p_g}{p_{data}+p_g} logpdata+pgpg 重构成 log ( p d a t a ( p d a t a + p g ) / 2 ⋅ 1 2 ) \log \big(\frac{p_{data}}{(p_{data}+p_g)/2}\cdot\frac12\big) log((pdata+pg)/2pdata⋅21) 。
显然,当 p d a t a = p d a t a + p g 2 = p g p_{data} = \frac{p_{data}+p_g}{2} = p_g pdata=2pdata+pg=pg 时,等号成立。因此 p g ∗ = p d a t a p_g^* = p_{data} pg∗=pdata,此时 D G ∗ = 1 2 D_G^*=\frac12 DG∗=21。这说明,在 GAN 的总目标函数达到全局最优解时,生成器 G G G 能将输入的服从 p z p_z pz 分布的随机变量 z z z 映射成一个服从 p g p_g pg 的随机变量 G ( z ) G(z) G(z),且此时 p g = p d a t a p_g=p_{data} pg=pdata。而判别器 D D D 已经无法分辨出输入的输入到底是真样本还是伪样本了(不管输入 x x x 来自真样本还是 G G G 生成的伪样本,都只能输出来自真样本的概率为 1 2 \frac12 21)。
5 网络构建与训练
通常而言,判别器 D D D 和生成器 G G G 分别是两个独立的神经网络,依据不同的实际用途可以选择使用多层感知机(MLP)、卷积神经网络(CNN)、Seq2Seq 抑或是其他的一些神经网络。
判别器一般就是一个简单的分类网络,输出的值在 [ 0 , 1 ] [0,1] [0,1] 之间,表示输入来自真实样本的概率,大于 0.5 表示判别器认为其来自真实样本,否则则认为其是生成器生成的伪样本。
生成器则复杂一些,它输入是一个噪声,这个噪声通常让它服从高斯分布(其他的也行,没有硬性要求,实际应用时效果好就可),然后经生成器产生出类似于真实样本的伪样本。例如,如果我们想使用 GAN 生成图像,则生成器输入一个或多个随机噪声,经神经网络映射后转化成二维图像的形式。

对于网络的训练过程,在第 4 节开头已经叙述过了,这里再补充一些。
GAN 在每一次迭代训练过程中,均使用随机梯度下降法(SGD)进行参数更新(参数一般表示为 θ D \theta_D θD 和 θ G \theta_G θG)。训练整体思路为:随机初始化全局参数后,对于每一轮迭代训练,先训练判别器,使得其对于真样本输出 ≥ 0.5 \ge0.5 ≥0.5,对于伪样本,则输出 ≤ 0.5 \le0.5 ≤0.5 ,然后固定判别器;再训练生成器,使其产生的样本经过判别器输出后能尽可能地 ≥ 0.5 \ge 0.5 ≥0.5。
这里对于 SGD 以及 D D D 的损失函数(一般为交叉熵损失函数)属于神经网络基础内容,不再赘述。