大数据时代,在数据量,计算量,计算时间上都是单机无法胜任的,通过简单的增强单机已经无法解决。普遍的解决方案为将多个单机组合起来进行存储和计算的分布式集群来处理。
Hadoop支持使用普通机器组成可拓展的分布式主从集群实现了对大数据的分布式存储(HDFS)、分布式计算(MapReduce )和资源调度(YARN)。下面分别介绍原理和常用命令;
一、HDFS分布式存储文件系统
hdfs作为一个可以在多台机器上读写文件的分布式文件系统,它有几个问题,如何解决以及相关概念:
-
超大文件如果比单机硬盘还大,该如何存储和快速读取?
答: 明显需要把大文件切分为多个"小块" ,然后存储到多台机器上,这样可以利用多台机器的io能力来快速读写。这个被切分的“小块”叫做block,默认是固定大小的,固定大小可以简化计算处理。
hdfs在每台数据节点机器上启动一个DataNode进程专门负责block读写和记录block的信息; -
文件切分的block保存在多台机器上,如何知道在哪些机器上,如何通信?
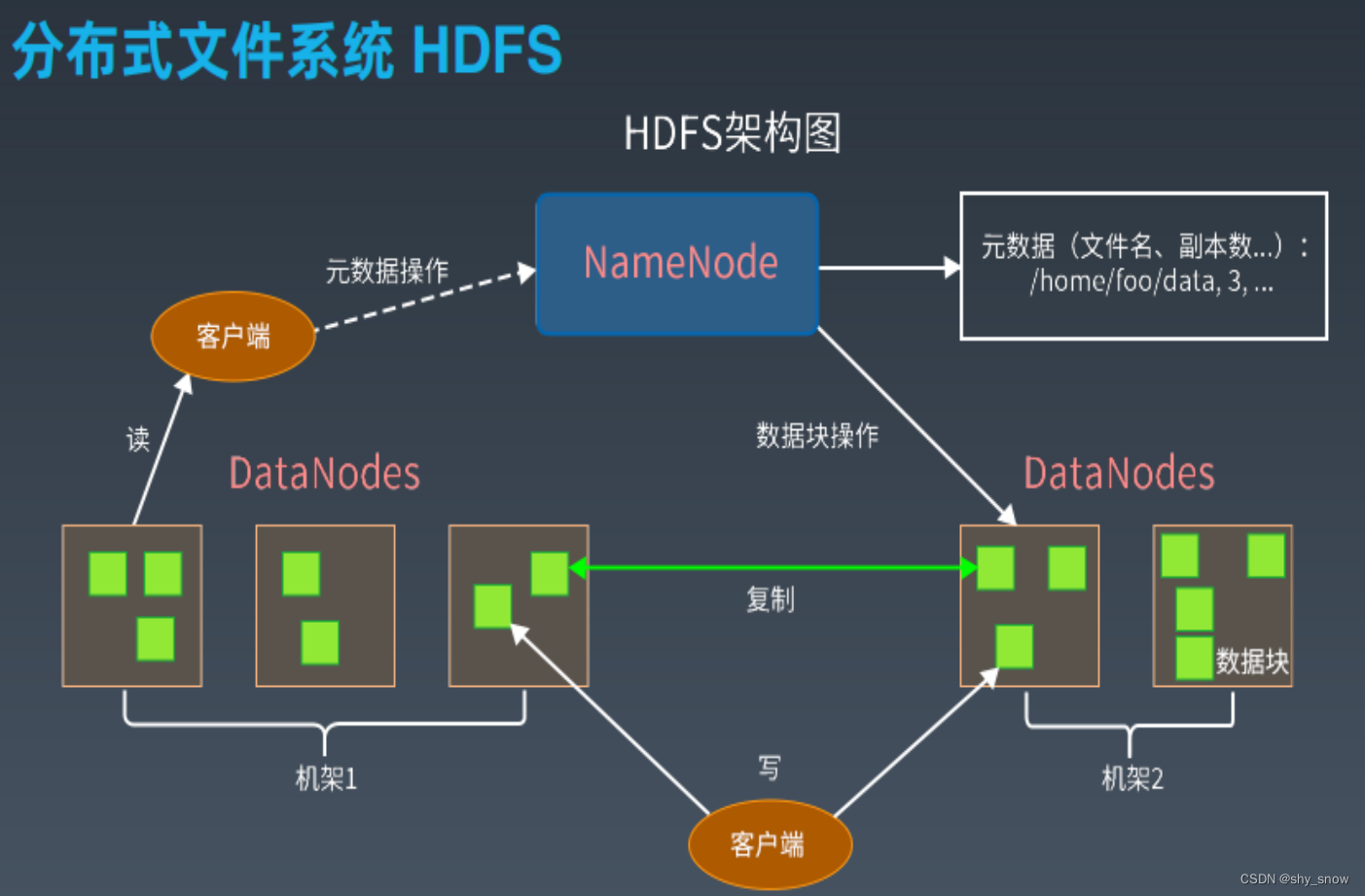
答: hdfs设置为主从集群,专门有一个NameNode节点负责接收读写请求,对外提供目录;所以只要和这个NameNode节点通信即可。 -
文件切分的block保存在多台机器上,读写时如何知道他们的位置?
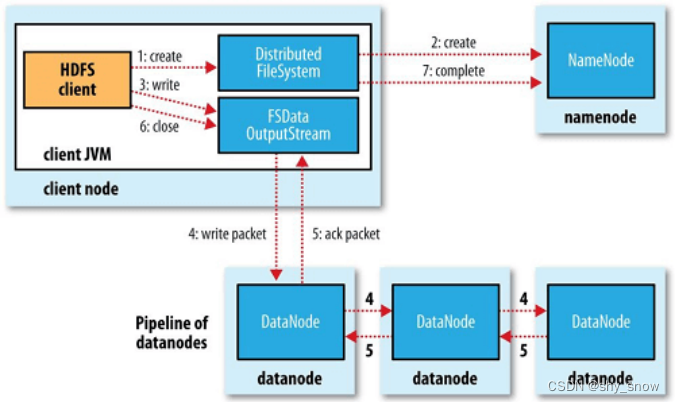
答: hdfs专门有一个NameNode进程负责接收读写请求,并保存文件名和block的id,DataNode会上报block的信息。需要读取文件的时候,只要发请求给NameNode节点,它会根据元数据查询到对应的block位置(DataNode启动时会汇报block信息给NameNode),顺序读取block为流;
-
常用操作命令
官方文档
1.上传/下载
将本地路径中的文件上传到hdfs
hdfs dfs -put urls(hdfs文件) /opt/index (本地路径)
将hdfs中的文件下载到本地路径
hdfs dfs -get urls(hdfs文件) /opt/index (本地路径)
2.查看hdfs文件系统内文件列表
hdfs dfs -ls /
3.删除hdfs中的文件
hdfs dfs -rm urls
4.删除hdfs中的文件夹
hdfs dfs -rm -r urls
5.创建目录
hdfs dfs -mkdir urls
6.查看文件内容
hdfs dfs –cat urls
7.查看文件末尾内容
hdfs dfs –tail urls
二、MapReduce分布式计算
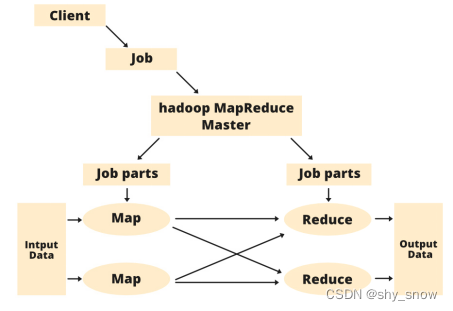
Hadoop MapReduce 是一个用于处理海量数据的编程模型和分布式计算框架,能让用户通过实现一些简单的接口就能完成对海量数据在上千台机器上实现并行计算的工作。
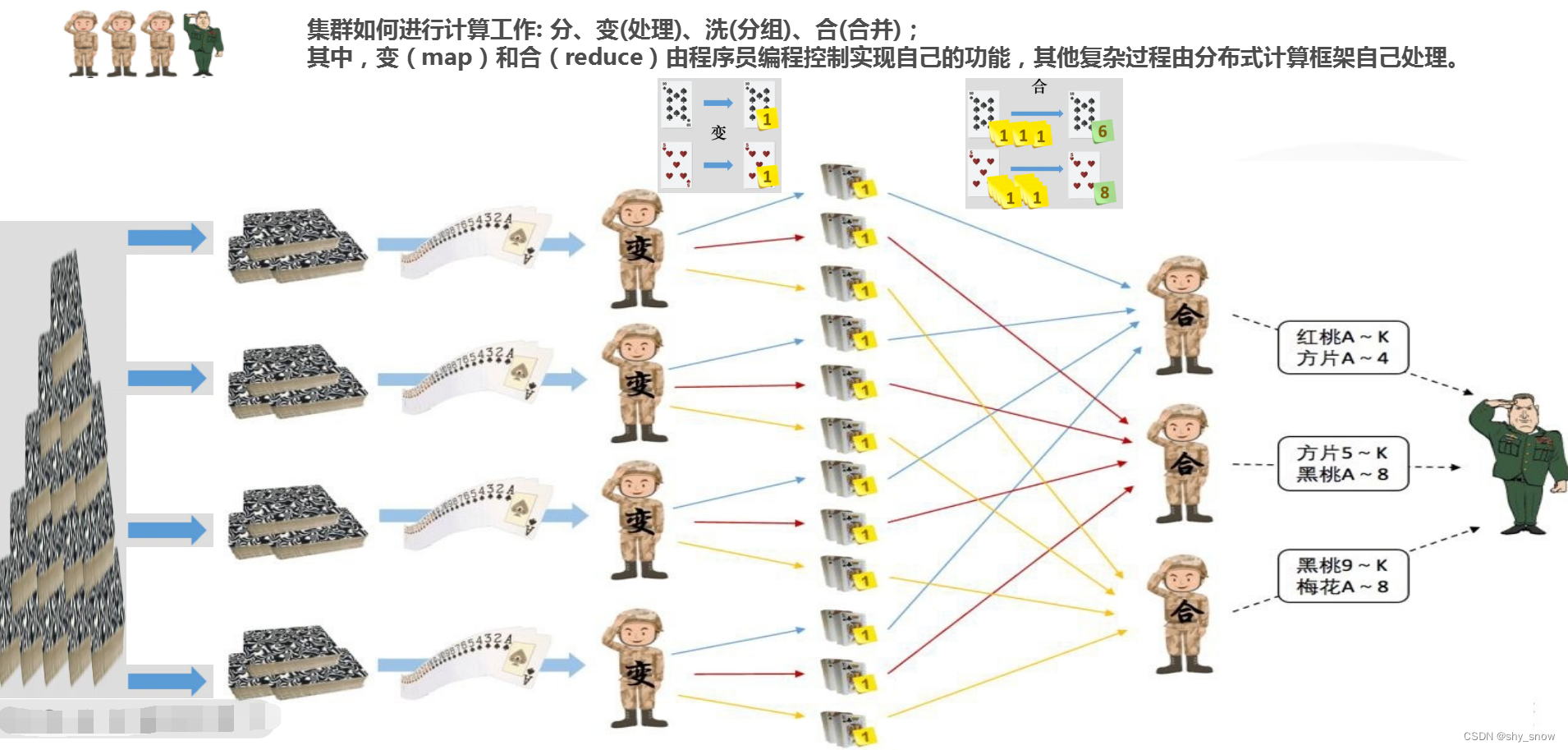
以WordCount这个统计文本中单词出现频率的小例子来看下MapReduce是如何进行分布式计算的。
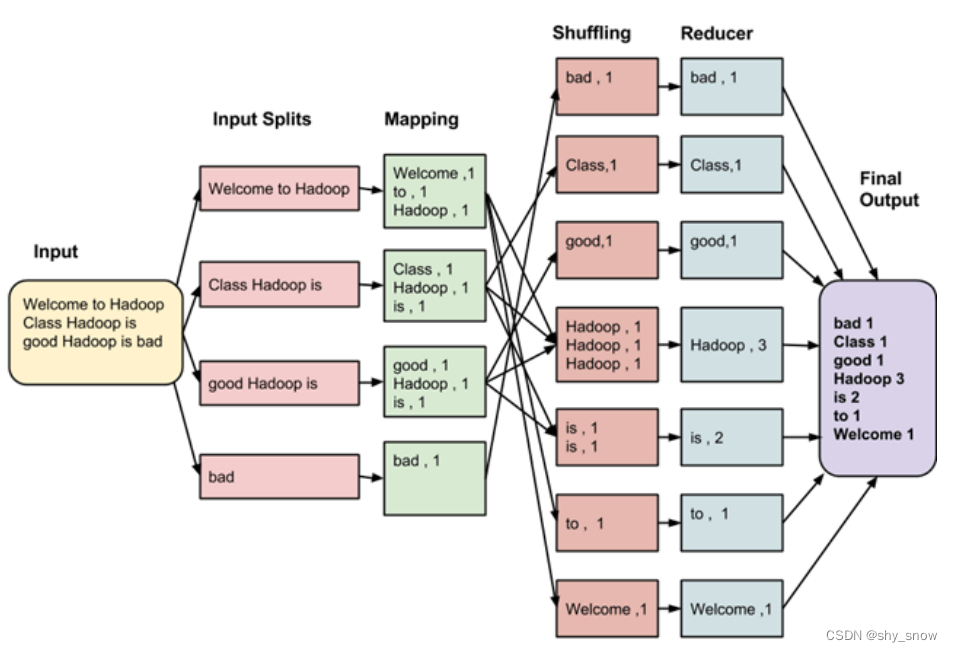
Input:数据写入 HDFS;
Input Splits:就近分割成固定大小的块(128MB),将作为 Mapping 阶段的输入。每个 split 任务对应一个 mapping 任务;
Mapping: 将执行映射计算(类似于循环),1比1的根据业务逻辑将输入对映射成输出对。WordCount 例子中是按字分割(key),值就是简单的计1(value);
Shuffling:洗牌阶段类似于 SQL 查询中的根据 key 分组,相同 key 的键值对简单的放在一起,并交给 Reducer 做聚合;
Reducer:对分组数据做统计,本例就是对 value 做累加,最后输出结果到 HDFS。
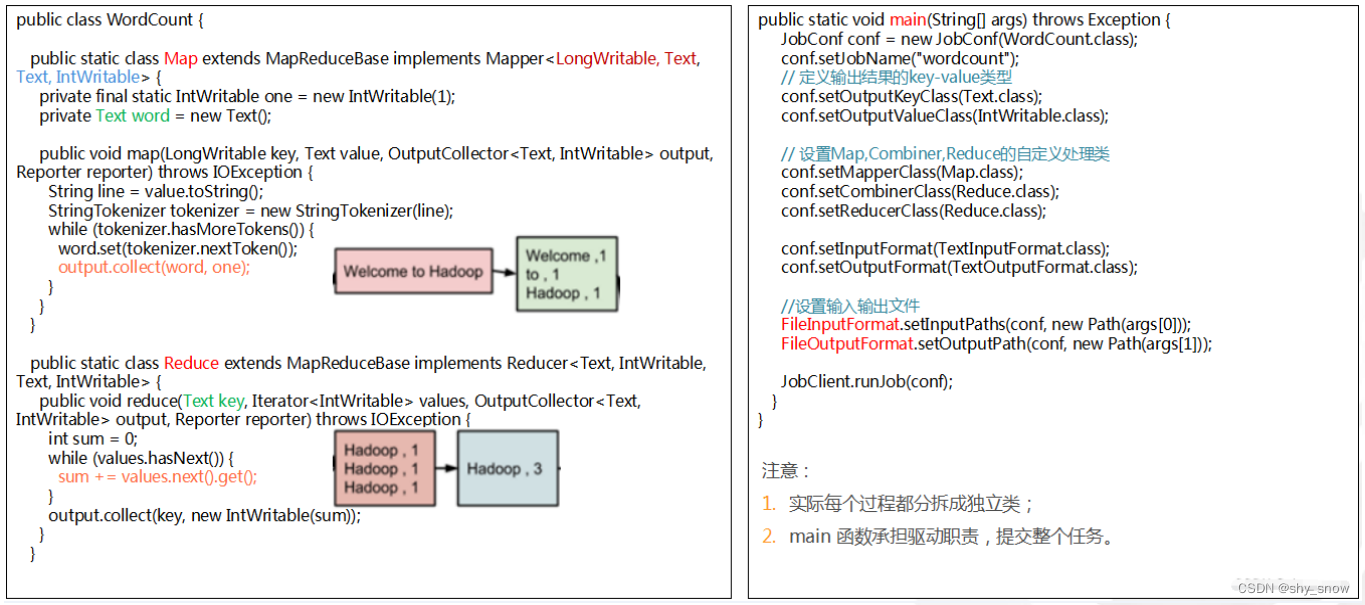
代码参加https://blog.csdn.net/shy_snow/article/details/126617976
三、YARN资源调度
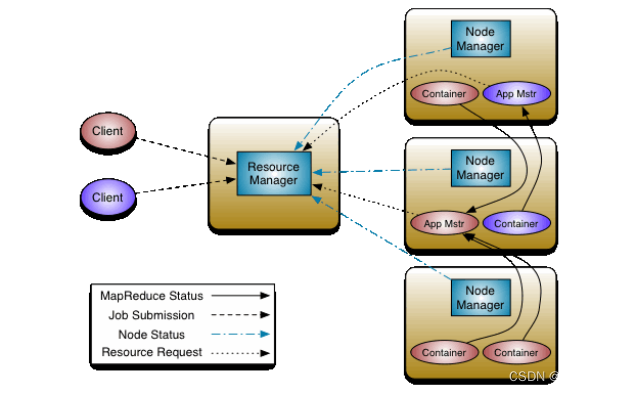
YARN 是资源协调服务器,包含资源管理(RM-NM)和任务执行(AM-Containers)两套机制。
ResourceManager (RM) :YARN 集群的主资源管理程序,仲裁整体资源并对请求做分配。通过 NM 监管节点资源,根据客户端请求,启动并监控 AM 服务,根据 AM 请求,在 NM 上启动其他 Container。
NodeManager (NM):运行在单个节点上的资源管理程序。日常向 RM 报告节点资源情况,接收 RM 分配任务并执行。重点功能包括创建、监控、汇报和杀死容器(NM在启动之前会将所有必要库复制到本地文件系统)。
YARN Client:YARN客户机,用来提交和启动YARN Application,需要与RM通信以尝试启动一个YARN 应用程序。
YARN Application:YARN的应用程序。一个应用程序包含一个负责资源申请的主进程(AM),以及若干个实际执行计算的 Container。
YARN Application Master(AM):应用程序的主管理进程(每个应用都会有一个),本身不参与计算,主要用来向RM协调资源。其本身也运行在YARN容器中。
YARN Container:YARN 容器本质上是在服务器上封装好的一个物理资源集合(包括CPU内核、RAM和磁盘),作为被调度的最小单元来执行的工作。每个节点上可以创建多个容器。
四、参考
[1]https://www.jianshu.com/p/2fa09d9c5b80
[2]https://blog.csdn.net/qq_30168227/article/details/122770339
[3]https://www.jianshu.com/p/2fa09d9c5b80