0x0. 前言
继续MLC-LLM 支持RWKV-5推理以及对RWKV-5的一些思考文章里面提到的想法,探索一下使用OpenCompass来评测RWKV模型,对模型的实际表现有一个更客观的了解。我在尝试的过程中也碰到了一些问题,所以这里记录一下使用OpenCompass评测的流程以及在评测RWKV过程中解决的问题。这里主要是记录如何跑通,后续可能会跑一下榜单去对比一下其它的模型。目前使用这个fork的版本(https://github.com/BBuf/opencompass)就可以正常做RWKV系列模型的评测了。
0x1. 流程
我是参考OpenCompass官方的快速开始文档:https://opencompass.readthedocs.io/zh-cn/latest/get_started/quick_start.html ,然后写一个config来对RWKV-5-3B进行评测。模型部分添加了下面的2个文件:
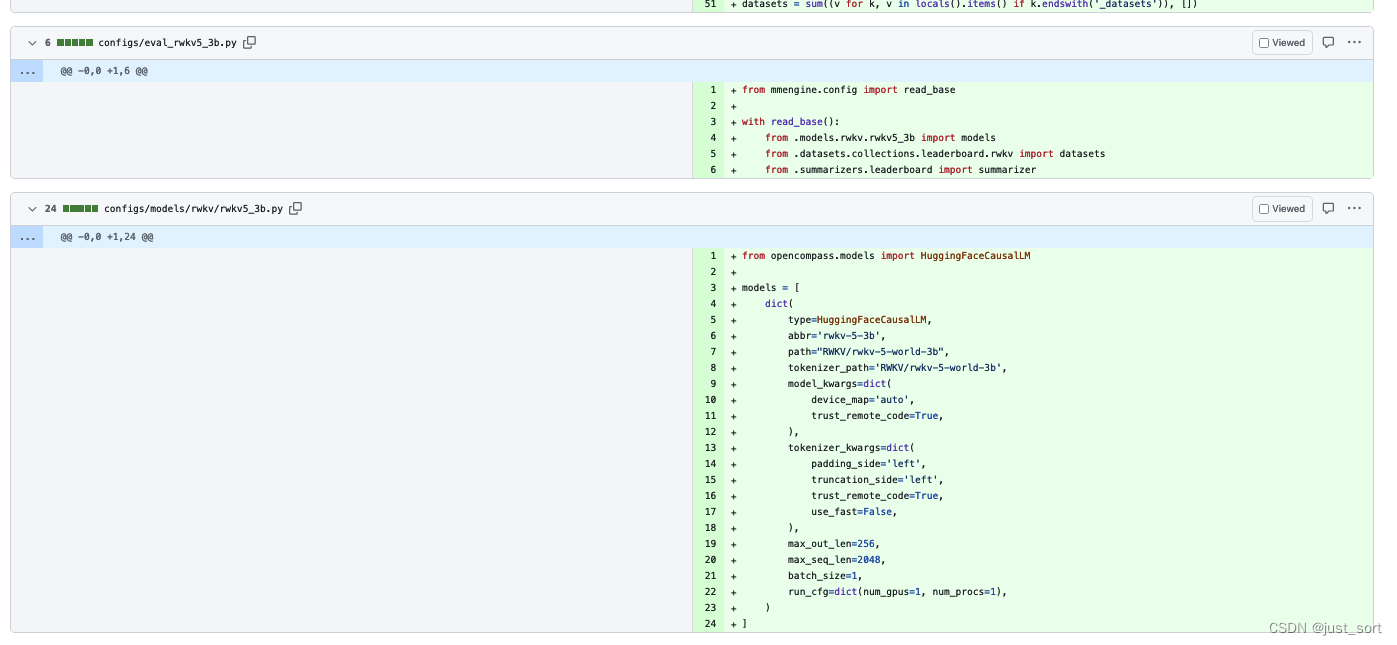 然后在评测数据集方面我挑选了和 RWKV-5 的训练进展(之二),与 SotA GPT 模型的性能对比(https://zhuanlan.zhihu.com/p/664079347) 里面相同的几个数据集来进行评测,配置文件写在这里:https://github.com/BBuf/opencompass/pull/1/files#diff-5a3fb40da6e965f866554e77966b0e22675f1b78272b5ac61667f64e23b6786a 。
然后在评测数据集方面我挑选了和 RWKV-5 的训练进展(之二),与 SotA GPT 模型的性能对比(https://zhuanlan.zhihu.com/p/664079347) 里面相同的几个数据集来进行评测,配置文件写在这里:https://github.com/BBuf/opencompass/pull/1/files#diff-5a3fb40da6e965f866554e77966b0e22675f1b78272b5ac61667f64e23b6786a 。
接下来就可以按照下面的步骤来评测RWKV-5-3B的HF模型(https://huggingface.co/RWKV/rwkv-5-world-3b)了。
主要参考OpenCompass的官方教程进行安装:https://opencompass.readthedocs.io/zh-cn/latest/get_started/installation.html 。
export HF_DATASETS_CACHE=xxx
export TRANSFORMERS_CACHE=xxx
git clone https://github.com/BBuf/opencompass
cd opencompass
pip install -r requirements.txt
pip install -e .
然后主要用到下面的两个指令来做评测以及prompt的可视化:
python3 tools/prompt_viewer.py configs/eval_rwkv5_3b.py用来可视化prompt,辅助debug
这里还有一个交互式的界面,有点惊艳。
python run.py configs/eval_rwkv5_3b.py运行rwkv-5-3b的评测,数据集可以通过opencompass/configs/models/rwkv/rwkv5_3b.py配置
0x2. 评测数据集示例
这里作为一个跑通的教程,我选取了 Lambada,CEval这两个数据集来测试流程的正确。
CEval 数据集是选择题,在Harness里面是以拼接选项算logits的方法来计算acc,所以在OpenCompass里面我对这几个数据集使用OpenCompass提供的计算ppl的方式进行评测,这个和Harness的方法比较类似。然后对于Lambada数据集,则采用gen的生成式任务进行评测。评测config见:https://github.com/BBuf/opencompass/pull/1
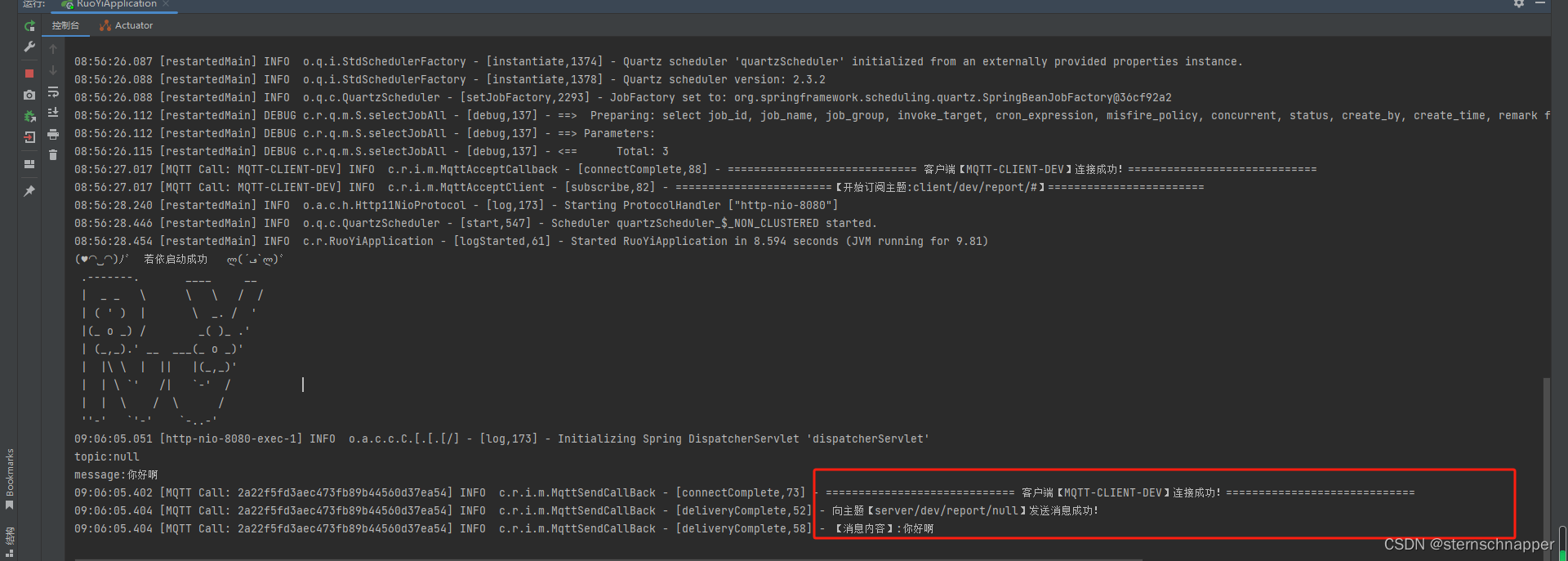
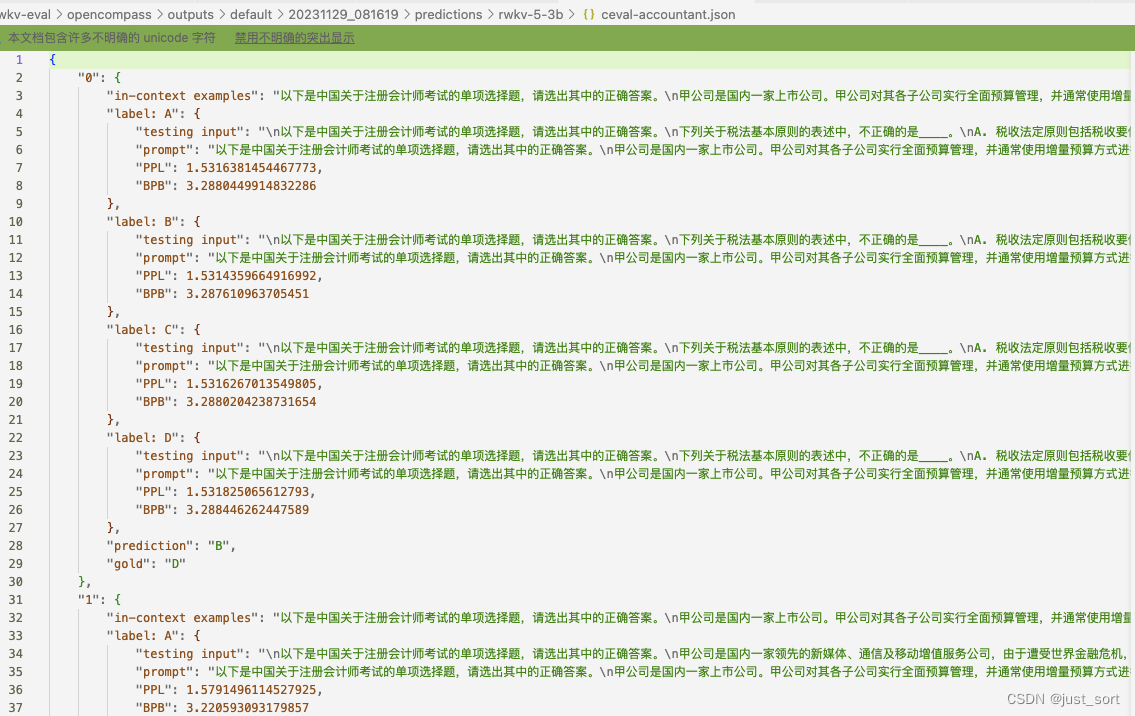
ceval的部分log结果展示:
Lambada的部分log结果展示:

等后续文章提供完整的评测结果和记录。
评测完成后OpenCompass会自动在outputs文件夹下面以表格的形式输出summary,非常直观的反应模型各大能力。
如果在评测过程中因为一些奇怪的原因挂掉了,但是又不是模型的问题,我们可以使用python run.py configs/eval_rwkv5_3b.py -r来续测,这样会在outputs下面最新时间戳的文件夹下复用已经评测的数据继续评测,避免反复重测带来的计算资源开销。
0x3. 评测中碰到的HF bug修复
bug1 解码出了None
第一次尝试使用ceval来验证流程的正确性,然后发现对于一个固定的prompt会出现一个构造pytorch Tensor失败的问题,复现代码为:
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
# model = AutoModelForCausalLM.from_pretrained("/Users/bbuf/工作目录/RWKV/rwkv-5-world-1b5/", trust_remote_code=True).to(torch.float32)
tokenizer = AutoTokenizer.from_pretrained("/Users/bbuf/工作目录/RWKV/rwkv-5-world-1b5/", trust_remote_code=True)
text = "Question: 以下是中国关于工商管理考试的单项选择题,请选出其中的正确答案。\n有一项年金,前3年无流入,后5年每年年初流入500万元,假设年利率为10%,(P/A,10%,5)=3.7908,(P/S,10%,3)=0.7513,(P/S,10%,2)=0.8264,其现值为____万元。\nA. 1994\nB. 1566\nC. 1813\nD. 1523\n答案: \n\nAnswer:BQuestion: 以下是中国关于工商管理考试的单项选择题,请选出其中的正确答案。\n企业缴纳的耕地占用税,应在____科目核算。\nA. 应交税费\nB. 管理费用\nC. 在建工程\nD. 其他应付款\n答案: \n\nAnswer:CQuestion: 以下是中国关于工商管理考试的单项选择题,请选出其中的正确答案。\n注册会计师在确定重要性时通常选定一个基准。下列因素中,注册会计师在选择基准时不需要考虑的是____。\nA. 被审计单位的性质\nB. 以前年度审计调整的金额\nC. 基准的相对波动性\nD. 是否存在财务报表使用者特别关注的项目\n答案: \n\nAnswer:BQuestion: 以下是中国关于工商管理考试的单项选择题,请选出其中的正确答案。\n某投资方案,当贴现率为12%时,其净现值为22万元,当贴现率为14%时,其净现值为-11万元。该方案的内部收益率____。\nA. 大于14%\nB. 小于12%\nC. 介于12%与14%之间\nD. 无法确定\n答案: \n\nAnswer:CQuestion: 以下是中国关于工商管理考试的单项选择题,请选出其中的正确答案。\n企业期末编制资产负债表时,下列各项应包括在“存货”项目的是____。\nA. 已作销售但购货方尚未运走的商品\nB. 委托代销商品\nC. 合同约定购入的商品\nD. 为在建工程购入的工程物资\n答案: \n\nAnswer:BQuestion: 以下是中国关于工商管理考试的单项选择题,请选出其中的正确答案。\n甲公司对其家电产品实行“包退、包换、包修”的销售政策。2011年该公司共销售家电产品200万元(不含增值税),根据以往的销售经验,该公司销售的商品中,包退的商品占2﹪,包换的产品占2%,包修的产品占1%,则甲公司2011年应确认的销售收入为____万元。\nA. 196\nB. 200\nC. 190\nD. 192\n答案: \n\nAnswer:"
prompt = text
print(prompt)
inputs = tokenizer(prompt, return_tensors="pt").to("cpu")
print(inputs)
报错信息为:
Traceback (most recent call last):
File "/opt/homebrew/lib/python3.11/site-packages/transformers-4.35.0.dev0-py3.11.egg/transformers/tokenization_utils_base.py", line 748, in convert_to_tensors
tensor = as_tensor(value)
^^^^^^^^^^^^^^^^
File "/opt/homebrew/lib/python3.11/site-packages/transformers-4.35.0.dev0-py3.11.egg/transformers/tokenization_utils_base.py", line 720, in as_tensor
return torch.tensor(value)
^^^^^^^^^^^^^^^^^^^
RuntimeError: Could not infer dtype of NoneType
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "/Users/bbuf/工作目录/RWKV/debug.py", line 21, in <module>
inputs = tokenizer(prompt, return_tensors="pt").to("cpu")
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/opt/homebrew/lib/python3.11/site-packages/transformers-4.35.0.dev0-py3.11.egg/transformers/tokenization_utils_base.py", line 2796, in __call__
encodings = self._call_one(text=text, text_pair=text_pair, **all_kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/opt/homebrew/lib/python3.11/site-packages/transformers-4.35.0.dev0-py3.11.egg/transformers/tokenization_utils_base.py", line 2902, in _call_one
return self.encode_plus(
^^^^^^^^^^^^^^^^^
File "/opt/homebrew/lib/python3.11/site-packages/transformers-4.35.0.dev0-py3.11.egg/transformers/tokenization_utils_base.py", line 2975, in encode_plus
return self._encode_plus(
^^^^^^^^^^^^^^^^^^
File "/Users/bbuf/.cache/huggingface/modules/transformers_modules/tokenization_rwkv_world.py", line 408, in _encode_plus
return self.prepare_for_model(
^^^^^^^^^^^^^^^^^^^^^^^
File "/opt/homebrew/lib/python3.11/site-packages/transformers-4.35.0.dev0-py3.11.egg/transformers/tokenization_utils_base.py", line 3465, in prepare_for_model
batch_outputs = BatchEncoding(
^^^^^^^^^^^^^^
File "/opt/homebrew/lib/python3.11/site-packages/transformers-4.35.0.dev0-py3.11.egg/transformers/tokenization_utils_base.py", line 223, in __init__
self.convert_to_tensors(tensor_type=tensor_type, prepend_batch_axis=prepend_batch_axis)
File "/opt/homebrew/lib/python3.11/site-packages/transformers-4.35.0.dev0-py3.11.egg/transformers/tokenization_utils_base.py", line 764, in convert_to_tensors
raise ValueError(
ValueError: Unable to create tensor, you should probably activate truncation and/or padding with 'padding=True' 'truncation=True' to have batched tensors with the same length. Perhaps your features (`input_ids` in this case) have excessive nesting (inputs type `list` where type `int` is expected).
发现在解码的过程中出现了None,这是因为tokenizer的实现bug,后续选择直接和rwkv官方的tokenizer逻辑对齐,见:https://github.com/BBuf/RWKV-World-HF-Tokenizer/commit/6d957bc984bdb00e90d103c8aa8cd35258c4da3c。
bug2
然后再次使用ceval的prompt调试时发现进度条跑到90%之后报错,报错的关键信息为:
UnicodeDecodeError: ‘utf-8’ codec can’t decode byte 0xe5 in position 650: unexpected end of data 。

按照gpt4给的解释定位到是Tokenizer的实现有bug,不能很好的处理特殊的中文字符,我在 https://github.com/BBuf/RWKV-World-HF-Tokenizer/commit/a2489e0a8b8e97bca8eb67b6d08cdf01624947a8 修复了这个bug,并将其同步到了RWKV社区下的HF项目,解决了此问题之后就可以成功跑完ceval。
bug3: OpenCompass的ppl任务报错
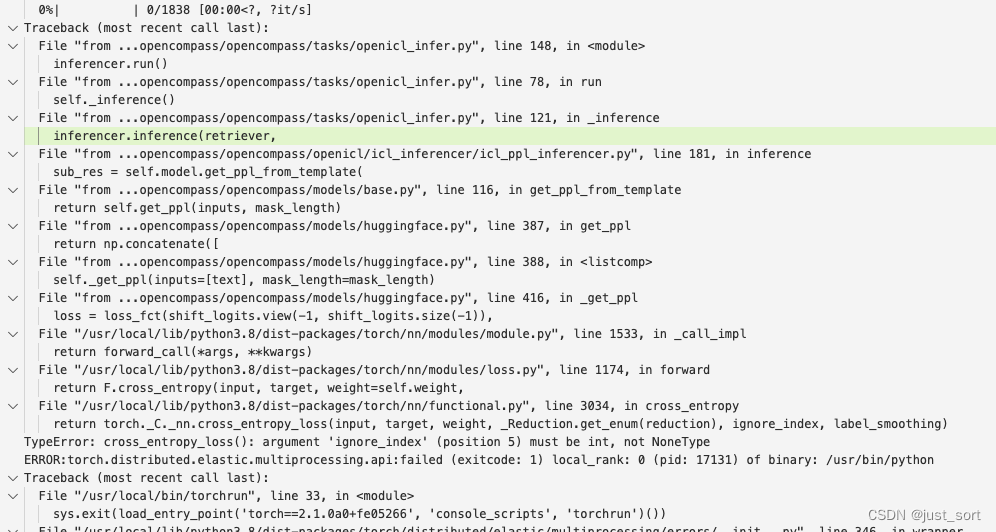
发现是RWKV World Tokenizer里面没有pad_token_id,用下面的修改hack了一下:

代码见:https://github.com/BBuf/opencompass/pull/1
bug4:修复RWKV社区HF模型prompt错误
这是另外一个问题,发现HuggingFace上的rwkv4和rwkv5模型prompt和生成参数和已经部署的服务(https://huggingface.co/spaces/BlinkDL/RWKV-Gradio-2/blob/main/app.py)有很大区别,导致输出的质量降低,对齐了这个问题之后可以获得更高质量的输出文本。具体见:https://huggingface.co/RWKV/rwkv-5-world-3b 的README改动。
0x4. 结论
尝试用OpenCompass跑一下RWKV模型,尝试的过程中也碰到了一些问题,所以这里记录一下使用OpenCompass评测的流程以及在评测RWKV过程中解决的问题。这里主要是记录如何跑通,后续可能会跑一下榜单去对比一下其它的模型。目前使用这个fork的版本(https://github.com/BBuf/opencompass)就可以正常做RWKV系列模型的评测了。