课程地址:《菜菜的机器学习sklearn课堂》_哔哩哔哩_bilibili
- 第一期:sklearn入门 & 决策树在sklearn中的实现
- 第二期:随机森林在sklearn中的实现
- 第三期:sklearn中的数据预处理和特征工程
- 第四期:sklearn中的降维算法PCA和SVD
- 第五期:sklearn中的逻辑回归
- 第六期:sklearn中的聚类算法K-Means
- 第七期:sklearn中的支持向量机SVM(上)
- 第八期:sklearn中的支持向量机SVM(下)
- 第九期:sklearn中的线性回归大家族
- 第十期:sklearn中的朴素贝叶斯
- 第十一期:sklearn与XGBoost
- 第十二期:sklearn中的神经网络
目录
问题描述
数据集
代码
(一)导入数据集,探索数据
(二)对数据集进行预处理
(三)提取标签和特征矩阵,分测试集和训练集
(四)导入模型
(五)在不同max_depth下观察模型的拟合状况
(六)用网格搜索调整参数
测试并提交Kaggle
问题描述
Titanic - Machine Learning from Disaster | Kaggle
通过分类树模型来预测一下哪些人可能成为幸存者(二分类问题,Survived为1即为幸存者,为0则不是幸存者)
数据集
数据集包含两个csv格式文件,data为我们要使用的数据(既有特征又有标签,可以来训练和测试),test为kaggle提供的测试集(无标签)


代码
import pandas as pd
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
from sklearn.model_selection import GridSearchCV
from sklearn.model_selection import cross_val_score
import matplotlib.pyplot as plt(一)导入数据集,探索数据
data = pd.read_csv(r"D:\Jupyter Notebook\菜菜sklearn\1 决策树\Taitanic\data.csv") # 891行,12列(11列特征,1列标签)
data.head() # 显示前n行,不写n的话默认为5
data.info() # 观察特征的类型、是否有缺失值
- Cabin列缺失过多,Name列、Ticket列、PassengerId列和预测的y没有关系,删
- Age列有小部分缺失,采用平均值填充
- Embarked列有2行缺失,删
(二)对数据集进行预处理
#删除缺失值过多的列,和观察判断来说和预测的y没有关系的列
data.drop(["Cabin","Name","Ticket","PassengerId"],inplace=True,axis=1) # inplace=True意味着用删除列后的表覆盖原表,默认为False。axis=1意味着对列进行操作
# 或写成:data = data.drop(["Cabin","Name","Ticket"],inplace=False,axis=1)
#处理缺失值,对缺失值较多的列进行填补,有一些特征只确实一两个值,可以采取直接删除记录的方法
data["Age"] = data["Age"].fillna(data["Age"].mean()) # .fillna(0)表示用0填补
data = data.dropna() # 删掉所有有缺失值的行(默认axis=0)
#将分类变量转换为数值型变量
#将二分类变量转换为数值型变量
#astype能够将一个pandas对象转换为某种类型,和apply(int(x))不同,astype可以将文本类转换为数字,用这个方式可以很便捷地将二分类特征转换为0~1
data["Sex"] = (data["Sex"]== "male").astype("int") # 返回True为1,False为0
#将三分类变量转换为数值型变量
labels = data["Embarked"].unique().tolist() # .unique()删掉重复值,查看特征里有多少唯一值
data["Embarked"] = data["Embarked"].apply(lambda x: labels.index(x)) # 匿名函数,S—>0,C—>1,Q—>2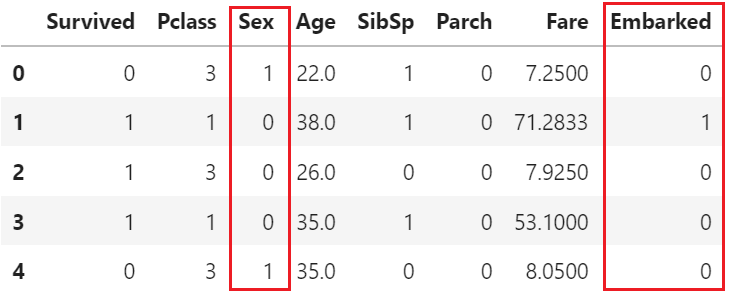
(三)提取标签和特征矩阵,分测试集和训练集
X = data.iloc[:,data.columns != "Survived"]
y = data.iloc[:,data.columns == "Survived"]
# data.loc[:,'sex'] 所有行,sex列
# data.iloc[:,3] 所有行,sex列(索引为3)
# 布尔索引用loc和iloc都行
from sklearn.model_selection import train_test_split
Xtrain, Xtest, Ytrain, Ytest = train_test_split(X,y,test_size=0.3)
#修正测试集和训练集的索引
for i in [Xtrain, Xtest, Ytrain, Ytest]:
i.index = range(i.shape[0]) # range(622),即0-621
(四)导入模型
clf = DecisionTreeClassifier(random_state=25)
clf = clf.fit(Xtrain, Ytrain)
score_ = clf.score(Xtest, Ytest)
score_ # 0.8127340823970037
score = cross_val_score(clf,X,y,cv=10).mean()
score # 0.7739274770173645(五)在不同max_depth下观察模型的拟合状况
tr = []
te = []
for i in range(10):
clf = DecisionTreeClassifier(random_state=25
,max_depth=i+1
# ,criterion="entropy" # 当模型欠拟合时用
)
clf = clf.fit(Xtrain, Ytrain)
score_tr = clf.score(Xtrain,Ytrain)
score_te = cross_val_score(clf,X,y,cv=10).mean()
tr.append(score_tr)
te.append(score_te)
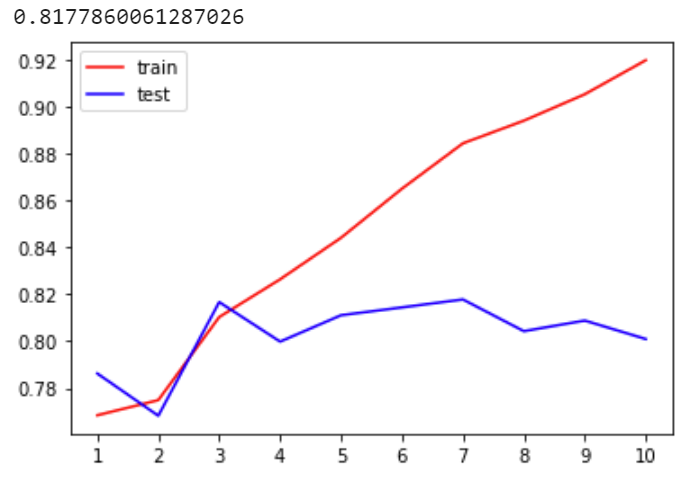
print(max(te))
# 若train曲线在test上,说明模型过拟合,需要剪枝
# 若test曲线在train上,说明模型欠拟合
plt.plot(range(1,11),tr,color="red",label="train")
plt.plot(range(1,11),te,color="blue",label="test")
plt.xticks(range(1,11)) # 显示横坐标的标尺(1-10的整数)
plt.legend()
plt.show()clf模型里一开始criterion参数默认为gini时,结果如下:

改为entropy时,结果如下:
(六)用网格搜索调整参数
网格搜索是能够帮助我们同时调整多个参数的技术,本质为枚举 —— 给网格搜索提供一个字典,字典中是一组一组的参数,对应参数的取值范围;调整参数在这些取值范围里的取值,最终返回能让模型达到最好的取值范围的组合。
缺点:多个参数交叉进行,计算量大,耗时,且无法舍弃你设定的参数
import numpy as np
# gini系数取值范围为0-0.5,entropy取值范围为0-1
gini_thresholds = np.linspace(0,0.5,20) # 在0-0.5之间取20个有顺序的随机数,但不一定等间距
# np.arange(0,0.5,0.01) 等间距
parameters = {'splitter':('best','random')
,'criterion':("gini","entropy")
,"max_depth":[*range(1,10)] # *表示解压缩
,'min_samples_leaf':[*range(1,50,5)]
,'min_impurity_decrease':[*np.linspace(0,0.5,20)] # 信息增益的最小值。当信息增益<规定的最小值时,该节点将不再进行分枝
} # 一串参数和这些参数对应的、我们希望网格搜索来搜索的参数的取值范围。是一个字典
clf = DecisionTreeClassifier(random_state=25)
GS = GridSearchCV(clf, parameters, cv=10) # 同时满足fit、score和交叉验证三种功能
GS.fit(Xtrain,Ytrain)
GS.best_params_ # 从我们输入的参数和参数取值的列表中返回最佳组合
GS.best_score_ # 网格搜索后模型的评判标准![]()
测试并提交Kaggle
test = pd.read_csv(r"D:\Jupyter Notebook\菜菜sklearn\1 决策树\Taitanic\test.csv")
test.info()
test.drop(["Cabin","Name","Ticket","PassengerId"],inplace=True,axis=1)
test["Age"] = test["Age"].fillna(data["Age"].mean())
test = test.dropna() # 删掉了Fare缺失的那一行
#将二分类变量转换为数值型变量
test["Sex"] = (test["Sex"]== "male").astype("int")
#将三分类变量转换为数值型变量
labels = test["Embarked"].unique().tolist()
test["Embarked"] = test["Embarked"].apply(lambda x: labels.index(x))
result = GS.predict(test) # nd.array()
df = pd.DataFrame(result)
df.to_csv("result.csv")
Score有点低