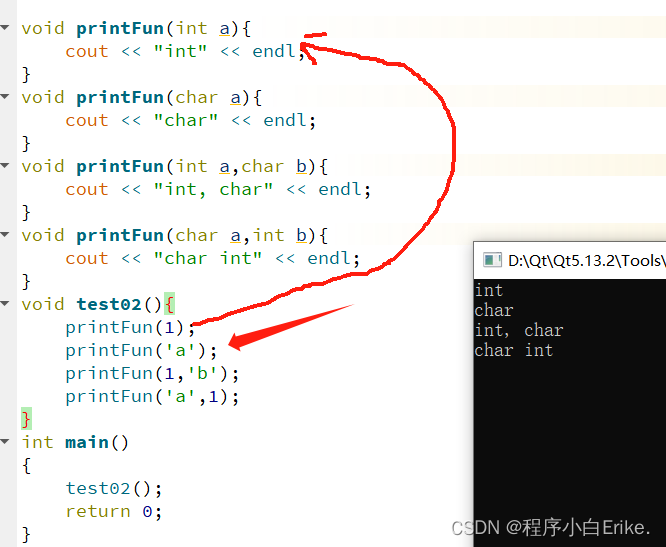
OLTP类型的业务系统采用集中式数据库还是分布式数据库是在做国产数据库改造中经常被问到的问题,无论是对技术架构发展演变,还是对现有业务长期发展提供必要的支撑,这个问题都具有讨论意义。在分布式大行其道的背景下,似乎任何架构都需要分布式赋能。现实真的是这样吗?下面将全面地进行分析与阐述。
作者:王辉
文章来源于微信公众号“基础技术研究”
一、使用现状分析
国产数据库厂商2022年就已经达到了200多家,传统集中式数据库以人大金仓、达梦为主,也有像polarDB这样的新兴数据库,分布式数据库有GaussDB、Kingwow、TDSQL、GoldenDB和OceanBase等,其实大部分这类的数据库都具备集中式和分布式两种部署模式,也就是你买分布式数据库的钱也可以用于集中式部署,可以满足你不同的业务需求。
这里有一点要注意,有的分布式数据库的厂商采用集中式部署,应用依然需要连接计算节点。通过计算节点(CN),去连接下面的数据节点,这可能是出于统一架构的考虑,也是出于计算节点在数据库发生主备切换时可以感知自动切换、对应用透明的考虑。但这样无意中增加了一层解析,会对性能产生一定的损耗。有的数据库厂商是通过自身提供的JDBC/ODBC驱动或VIP等方式直连数据库,从而避免了类似问题的出现。
从技术架构看,金融行业使用的数据库仍以集中式为主,分布式数据库在中大型金融机构形成了有力补充。《金融业数据库供应链安全发展报告(2022)》调研数据显示,集中式数据库在金融业总体占比仍高达 89%,其中银行80%,证券和保险业占比均超过 90%,集中式数据库在金融科技数字化进程中扮演重要角色。金融行业分布式数据库总体占比达到7%,银行业超过了17%,证券业和保险业相对较低。也就是说我们大部分业务采用集中式数据库是完全能够满足的。
二、真的需要分布式吗?
集中式数据库由于只有一个主数据节点,天然具备架构简单、运维方便、兼容性好和性价比高等优势。
但也存在无法突破单机硬件限制、无法横向扩容、存在性能和容量瓶颈的问题。
所以当集中式数据库无法满足我们的性能和容量要求时,分布式就给我们提供了一个很好的技术手段。当我们打算选择分布式来解决集中式的问题的时候,建议大家先做如下的提问再做考虑:
- 是否可以通过优化集中式数据库自身来解决问题,而不做大的架构改动,如优化参数、优化SQL语句,优化业务逻辑等方式。
- 是否可以通过增加主机资源配置解决问题,如采用增加CPU和内存大小,或原来采用虚拟机而改用物理机等纵向扩展的方式解决。
- 是否可以通过存算分离的方式解决问题,如果只是单机的容量无法满足要求,可以考虑外挂存储或采用存算分离架构,解决单机磁盘容量受限的问题。
- 是否可以通过应用层解决,如改变业务架构,采用微服务或单元化架构,也就是在应用层实现数据拆分、分布式事务和水平扩展等能力,而数据库依然采用集中式。这种方式对开发人员的要求高,业务改造成本大,需要综合考虑。
- 是否充分了解分布式架构的优缺点,是否做好分布式数据库的运维与备份等相关准备工作,是否充分考虑自己的业务必须要通过分布式数据库来解决。
三、何时使用分布式?
早期有2000w行的表需要拆分的说法,这个主要是针对MySQL数据库。当OLTP类型的表超过2000W行,通过公式计算B+tree叶子层数会增加到4层,从而增加IO的读取次数。但随着硬件的升级或缓存技术的实现,可以基本忽略IO的影响。因此目前比较常见地通过TPS或QPS指标来决定是否需要做分布式改造,如单点TPS瓶颈达到4000,或QPS达到8W,或数据容量达到2TB后。一般情况下需要做横向扩容解决性能或容量瓶颈,相对来说比较合理,但这里没有一个固定公式,主要还是要结合自己的业务场景来做判断。也要考虑未来业务增长的需求,如是否满足业务3-5年的增长需求,做好峰值预测,提前做好规划,避免做二次改造。同时参考上面提到的几个问题,是否必须通过分布式数据库来解决。
实验数据一(找拐点)
硬件资源为基于ARM架构的鲲鹏虚拟机环境,具体配置为16C64G,中标麒麟v10操作系统,普通ssd磁盘。
下图为某国产分布式数据库测试结果,分布式为4分片,单位:秒。
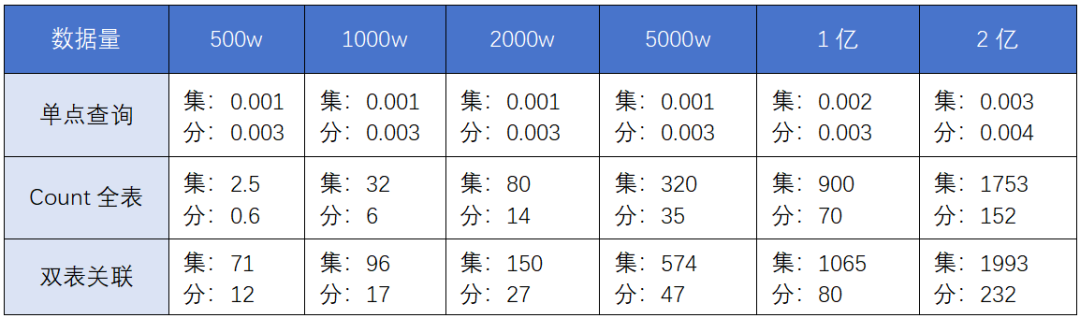
对于单点基于索引的查询基本没有差距,对于全表扫描和双表关联(关联表为统一为200w行且都基于分片键作为关联条件)都在500w数据量的时候就已经有5倍左右的明显提升,这个弯儿说实话拐的有点早,其实还是要结合自己的业务场景验证会更加准确。
对于500w以下数据量的,大家可以结合业务自行测试。当然也可能在300w或者更低的时候出现拐点,这里也希望大家能给出更多的测试结果。实验数据受多种因素影响可能存在一定偏差,还请指正,并非常期望大家能将自己的测试结果放到评论区,大家一起验证分布式与集中式的性能拐点,这样可以提供一个更加准确的数据基础为选型做参考。
实验数据二
下图是某厂商基于sysbench工具压测的结果:

可以看到集中式数据库在中等规格配置下资源使用率达到75%时,所能达到的最大TPS在4595,延迟5ms,并发400。这是一个参考值,也就是上面提到的基本TPS超过5000需要拆分的一个依据。当然如果你的资源够大,这个值可以再大。不过最准确地,需要我们通过真实环境压力测试来验证我们的TPS值进行判断。
四、如何用好分布式
顾名思义,分布式,多个人干活,具备高可用、高扩展、高性能和弹性扩缩容能力等优势。
由于数据节点数量和数据库组件的增加,必然会出现架构复杂、运维复杂和成本高等问题,同时大部分分布式数据库不支持存储过程、自定义函数等特殊对象。
分布式是一把双刃剑,我们如何用好且不受伤很重要。
1. 分片键的选择
分片键的选择非常重要,选作分片键的字段取值应该比较离散,以便数据能在各个数据节点上均匀分布。当单个字段无法满足离散条件时,可以考虑使用多个字段一起作为分片键。一般情况下,可以考虑选择表的主键作为分片键。例如,在人员信息表中选择证件号码作为分布键。且大部分分布式数据库都不支持或不建议对分片键的修改。
2. 分布方式的选择
常见的选择是hash分布,相对来说分布更加均匀,另外还有range和list等分区,当然我们最终需要结合具体业务场景进行选择。另外需要将一些经常用的配置信息表或关联查询的小表定义成全局表,确保在一个数据节点可以获取到,避免跨节点数据交互。
3. 规范SQL语句的编写
应选择分片键作为查询条件,并采用分片键作为多表关联查询条件。如果不采用分片键会出现跨节点数据传输,有的分布式数据库会出现将所有数据汇聚计算节点做汇总关联排序,当数据很大时会瞬间将计算节点资源打满,导致数据库无法对外提供服务。
4. 规避跨节点数据传输
如上所说的将查询条件作为分片键就是最大限度地避免跨节点传输,因为跨节点数据传输是基于网络进行的,网络相比较磁盘的传输读写性能存在很大的差距,所以性能会明显下降,甚至会出现结果一直跑不出来的情况。
5. 规避分布式事务
分布式事务处理路径长,这个是他的性质决定的,大部分数据库就基于2PC原理实现,因此我们要最大限度地规避分布式事务,一般情况下控制在所有事务的10%以内,过多的分布式事务一定会给我们带来性能影响,也对业务数据的一致性问题带来了挑战。
五、深入分析:分布式是数据库解决还是应用解决
分布式的实现可以通过数据库解决(分布式数据库)也可以通过应用解决,大部分开发人员,尤其是传统行业或城商行等金融机构,开发能力比不上大行,人员规模有限,他们更希望数据库做的事情更多一些,比如分布式事务的实现、数据拆分的实现,尽量对开发人员透明。所以他们会直接采用分布式数据库,以单元化架构为例如下图:
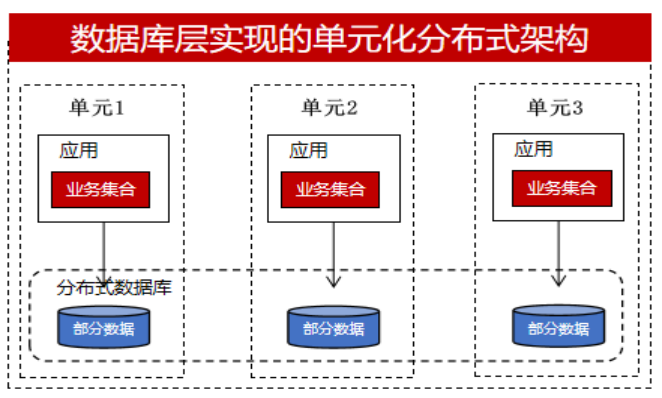
但一些重要的业务系统或具备一定开发能力的团队,更多地会考虑在应用层去实现。他们想拿到更多的控制权,如一个分布式事务出现异常,如果在数据库层实现,那么对应开发人员来说是个黑盒,他只能期盼数据库的分布式事务处理能力,他们无法介入。但如果要是在业务层实现,他们可以通过消息队列、TCC和saga等获取的日志信息并做数据补偿机制来做相应的处理。因此他们会在应用层实现分布式,数据库采用集中式的方式,每个数据库存放部分业务数据,以单元化架构为例如下图:

集中式与分布式数据库在实现分布式方式上的区别汇总如下:
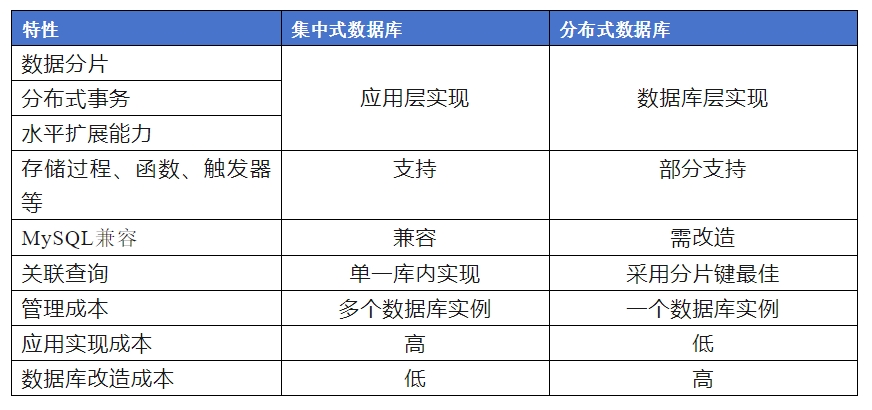
采用集中式数据库,应用层实现分布式对应用的要求比较高,要实现分布式特性,但在数据库层面反而改造的比较少,因为集中式数据库的兼容性要比分布式更好一些。
采用分布式数据库,应用不需要实现分布式特性,对应用透明,但分布式数据库对特殊对象,如存储过程、函数等兼容较差,甚至不支持,这就需要应用针对数据库做适配改造。
六、小结
在一次数据库创新的圆桌论坛上,一位同行的老师说集中式数据库就像绵羊,温顺而便于管理,而分布式数据库是一匹野马,放荡不羁难于控制,这让我想起了宋冬野在《董小姐》的歌里唱到的,“爱上一匹野马,可我的家里没有草原,这让我感到绝望...”。分布式数据库这匹野马能够驯服,会让你在大草原上飞奔驰骋,否则就会让你受尽苦难、步履维艰。其实大部分开发人员还是希望数据库做的多一些,开发人员改造少一些,数据库更透明一些,更简单一些,甚至是更智能一些。
最后我想说一句,我们国产数据库任重而道远,其实相比较新功能的增加,客户更关心基础功能的改进。如果我们能把数据库核心存储引擎做好,生态做好的话,那么OLTP的数据库我们也不会去深入讨论这个话题。
文章如有表达不准确、或不专业的地方还请大家指正,谢谢。
更多技术文章,请访问:https://opensource.actionsky.com/
关于 SQLE
SQLE 是一款全方位的 SQL 质量管理平台,覆盖开发至生产环境的 SQL 审核和管理。支持主流的开源、商业、国产数据库,为开发和运维提供流程自动化能力,提升上线效率,提高数据质量。
SQLE 获取
| 类型 | 地址 |
|---|---|
| 版本库 | https://github.com/actiontech/sqle |
| 文档 | https://actiontech.github.io/sqle-docs/ |
| 发布信息 | https://github.com/actiontech/sqle/releases |
| 数据审核插件开发文档 | https://actiontech.github.io/sqle-docs/docs/dev-manual/plugins/howtouse |



![[cocos creator]EditBox,editing-return事件,清空输入框](https://img-blog.csdnimg.cn/direct/1f6f5072c74c484192ecb32bec8d4d52.png)