目录
8.8 内联函数 inline
8.8.1 声明内联函数
8.8.2 宏函数与内联函数的区别
8.8.3 使用内联函数需注意
8.9 函数重载
8.9.1 什么是函数重载
8.9.2 函数重载的条件
8.9.3 函数重载底层原理是如何实现的?
8.8 内联函数 inline
在C++中,inline是一个关键字,用于向编译器提出建议,希望将函数作为内联函数进行编译。并且内联函数必须在定义的时候 ,前面使用关键字inline修饰限定,注意不能在声明的时候使用inline。
8.8.1 声明内联函数
内联函数: 在编译阶段 将内联函数中的函数体 替换函数调用处。可以避免函数调用时的开销
使用inline关键字修饰函数时,编译器会尽量将函数的定义嵌入到每个调用处,而不是在编译时生成函数的独立副本。这意味着内联函数没有函数调用的开销。通常情况下,内联函数适合用于简短的函数,且频繁调用的地方。
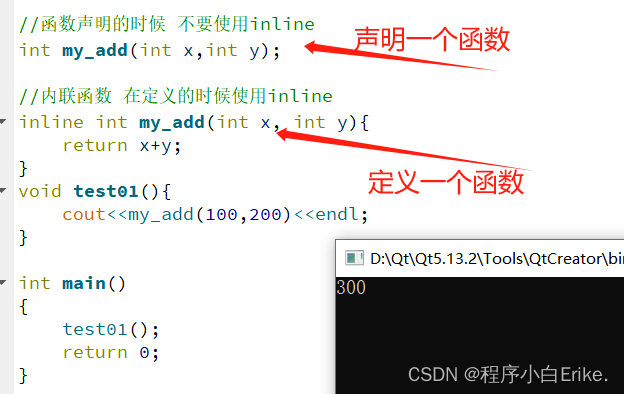
//函数声明的时候 不要使用inline
int my_add(int x,int y);
//内联函数 在定义的时候使用inline
inline int my_add(int x, int y){
return x+y;
}
void test01(){
cout<<my_add(100,200)<<endl;
}8.8.2 宏函数与内联函数的区别
宏函数和内联函数 都会在适当的位置进行展开,避免函数调用开销。
宏函数的参数没有类型,不能保证参数的完整性。
内联函数的参数有类型 能保证参数的完整性
宏函数在预处理阶段展开
内联函数在编译阶段展开
宏函数没有作用域的限制,不能作为命名空间、结构体、类的成员
内联函数有作用域的限制,能作为命名空间、结构体、类的成员
说法二:(和上面差不多解释)
区别:
- 展开方式:宏函数在编译预处理阶段进行简单的文本替换,将宏调用直接替换为宏定义的代码。而内联函数是在编译阶段进行函数体的插入,将函数调用处直接替换为函数的代码。换句话说,宏函数只是简单的文本替换,而内联函数则是代码插入。
- 类型检查:宏函数在展开时不进行类型检查,而内联函数会进行严格的类型检查。宏函数只是进行简单的文本替换,而不会关注参数的类型,容易导致意外的错误。
- 作用域:宏函数没有作用域限制,可以在任何地方使用。而内联函数需要在函数定义之前进行声明,在其作用域内有效。
共同点:
- 减少函数调用开销:宏函数和内联函数都可以减少函数调用的开销,提高程序的执行效率。
- 代码复用:宏函数和内联函数都可以用于重复使用一些代码块,避免代码的重复书写。
8.8.3 使用内联函数需注意
在内联函数定义的时候加inline修临类中的成员函数 默认都是内联函数 (不加inline 也是内联函数)有时候就算加上inline也不一定是内联函数 (内联函数条件)不能存在任何形式的循环语句
不能存在过多的条件判断语句
函数体不能过于庞大
不能对函数取地址
有时候不加inline修饰 也有可能是内联函数
是否内联是由编译器决定(与变量存放寄存器一个道理)
增加inline是为了开发人员想要这个函数变成一个内联函数,提供建议给编译器,它接受不接受完全看当时调用过程。
8.9 函数重载
C++函数重载是指在同一个作用域内,可以定义多个函数名相同但参数列表(参数类型、参数个数或参数顺序)不同的函数。能让我们使用的对象的名字更加方便使用,提高重复利用率,不同需求同一名称,不同参数的结果导向也是不一样的,是任何程序设计语言的一个重要特征!
8.9.1 什么是函数重载
函数重载,是c++的多态的特性 (静态多态)函数重载: 用同一个函数名来表示不同的函数功能。
例如:吃饭,吃饭可以是大口吃、小口吃、快吃、慢吃、可以喝、可以咬吞咽嚼烂。这些都叫吃饭,根据外面传进来的食物,使用不同的方法处理这个食物,比如吃东西进来是咀嚼、还是漱口水,处理的方式不一样,骨头你还要啃,就像牙齿有不同的功能一样。
函数重载允许我们使用相同的函数名来表示处理不同类型的数据或参数组合的操作。通过函数重载,我们可以根据不同的参数类型或参数个数来选择相应的函数进行调用。
函数重载的特点:
- 函数名称相同,但参数列表不同。
- 函数重载不仅可以根据参数类型的不同进行重载,还可以根据参数个数和参数的顺序进行重载。
- 返回类型不是重载的条件,相同的函数名称和参数列表但不同的返回类型是不允许的。
8.9.2 函数重载的条件
同一作用域,函数的参数类型不同、个数不同、顺序不同都可以实现重载。(但是返回值类型不能作为重载的条件)
函数重载的示例:
int add(int a, int b); // 加法函数,接受两个int类型参数
int add(int a, int b, int c); // 加法函数,接受三个int类型参数
double add(double a, double b); // 加法函数,接受两个double类型参数
//第三个函数的返回值是double,此时不是重载再例如下面这个案例,在同一作用域范围下定义的同名函数,可以定义4个相同名称的函数,但是由于参数类型不一样,顺序不一样,所以不会报错,符合函数重载的条件。
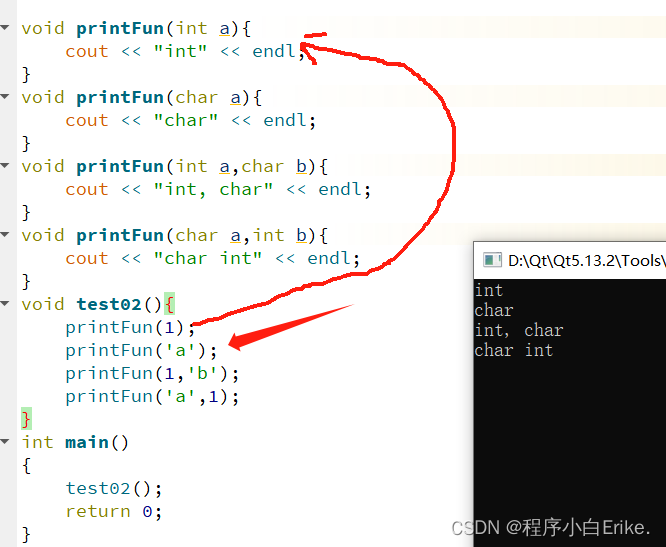
void printFun(int a){
cout << "int" << endl;
}
void printFun(char a){
cout << "char" << endl;
}
void printFun(int a,char b){
cout << "int, char" << endl;
}
void printFun(char a,int b){
cout << "char int" << endl;
}
void test02(){
printFun(1);
printFun('a');
printFun(1,'b');
printFun('a',1);
}为什么返回值类型不能作为函数重载的条件之一?
当编译器能从上下文中确定唯一的函数的时,如
int ret =func();这个当然是没有问题的。然而,我们在编写程序过程中可以忽略他的返回值。那么这个时候,
void func(int x);
int fun(int x);当我们直接使用fun(10)这个函数的时候,这个时候编译器就不确定调用那个数。所以在c++中禁止使用返回值作为重载的条件.
func(10);8.9.3 函数重载底层原理是如何实现的?
void test(){};
void test(int x){};
void test(char x){};
void test(int x,char y){};
实际上就是函数名字 test + ( ) 里面的内容 来共同决定调用哪个函数。
其底层原理是是通过名称修饰(Name Mangling)和函数签名来实现的。(实际上就是编译器会自动取个别名)
在编译源代码时,编译器会根据函数的名称、参数列表和返回值类型等信息生成一个唯一的函数签名。函数签名是一个特定的标识符,用于区分不同的函数定义。
当程序中调用一个函数时,编译器会根据函数名称和实参的类型、顺序和数量,匹配到与之对应的函数签名。通过函数签名可以准确地找到具体要调用的函数定义。
通过名称修饰和函数签名的机制,函数重载可以实现在同一个作用域中有多个同名函数的情况。编译器能够根据函数签名来确定调用哪个函数定义,从而实现函数重载的效果。
不同编译器有不同的命名方法.........这个只需要了解,不需要深入研究。


![[cocos creator]EditBox,editing-return事件,清空输入框](https://img-blog.csdnimg.cn/direct/1f6f5072c74c484192ecb32bec8d4d52.png)