2D 扩散模型极大地简化了图像内容的创作流程,2D 设计行业也因此发生了变革。近来,扩散模型已扩展到 3D 创作领域,减少了应用程序(如 VR、AR、机器人技术和游戏等)中的人工成本。有许多研究已经对使用预训练的 2D 扩散模型,生成具有评分蒸馏采样(SDS)损失的 NeRFs 方法进行了探索。然而,基于 SDS 的方法通常需要花费数小时来优化资源,并且经常引发图形中的几何问题,比如多面 Janus 问题。
另一方面,研究者对无需花费大量时间优化每个资源,也能够实现多样化生成的 3D 扩散模型也进行了多种尝试。这些方法通常需要获取包含真实数据的 3D 模型 / 点云用于训练。然而,对于真实图像来说,这种训练数据难以获得。由于目前的 3D 扩散方法通常基于两阶段训练,这导致在不分类、高度多样化的 3D 数据集上存在一个模糊且难以去噪的潜在空间,使得高质量渲染成为亟待解决的挑战。
为了解决这个问题,已经有研究者提出了单阶段模型,但这些模型大多数只针对特定的简单类别,泛化性较差。
因此,本文研究者的目标是实现快速、逼真和通用的 3D 生成。为此,他们提出了 DMV3D。DMV3D 是一种全新的单阶段的全类别扩散模型,能直接根据模型文字或单张图片的输入,生成 3D NeRF。在单个 A100 GPU 上,仅需 30 秒,DMV3D 就能生成各种高保真 3D 图像。

具体来讲,DMV3D 是一个 2D 多视图图像扩散模型,它将 3D NeRF 重建和渲染集成到其降噪器中,以端到端的方式进行训练,而无需直接 3D 监督。这避免了单独训练用于潜在空间扩散的 3D NeRF 编码器(如两阶段模型)和繁琐的对每个对象进行优化的方法(如 SDS)中会出现的问题。
本质上,本文的方法是对 2D 多视图扩散的框架进行 3D 重建。这种方法受到了 RenderDiffusion 的启发,它是一种通过单视图扩散实现 3D 生成的方法。然而,RenderDiffusion 的局限性在于,训练数据需要特定类别的先验知识,数据中的对象也需要特定的角度或姿势,因此泛化性很差,无法对任意类型的对象进行 3D 生成。
相比之下,研究者认为一组稀疏的包含一个对象的四个多视角的投影,足以描述一个没有被遮挡的 3D 物体。这种训练数据的输入源于人类的空间想象能力。他们可以根据几个对象的周围的平面视图,想象出一个完整的 3D 物体。这种想象通常是非常确定和具像化的。
然而,利用这种输入本质上仍需解决稀疏视图下 3D 重建的任务。这是一个长期存在的问题,即使在输入没有噪声的情况下,也是一个非常具有挑战性的问题。
本文的方法能够基于单个图像 / 文本实现 3D 生成。对于图像输入,他们固定一个稀疏视图作为无噪声输入,并对其他视图进行类似于 2D 图像修复的降噪。为了实现基于文本的 3D 生成,研究者使用了在 2D 扩散模型中通常会用到的、基于注意力的文本条件和不受类型限制的分类器。
他们只采用了图像空间监督,在 Objaverse 合成的图像和 MVImgNet 真实捕获的图像组成的大型数据集上进行了训练。从结果来看,DMV3D 在单图像 3D 重建方面取得了 SOTA,超越了先前基于 SDS 的方法和 3D 扩散模型。DMV3D 生成的基于文本的 3D 模型,也优于此前的方法。

-
论文地址:https://arxiv.org/pdf/2311.09217.pdf
-
官网地址:https://justimyhxu.github.io/projects/dmv3d/
我们来看一下生成的 3D 图像效果。


方法概览
单阶段 3D 扩散模型是如何训练并推理的呢?
研究者首先引入了一种新的扩散框架,该框架使用基于重建的降噪器来对有噪声的多视图图像去噪以进行 3D 生成;其次他们提出了一种新的、以扩散时间步为条件的、基于 LRM 的多视图降噪器,从而通过 3D NeRF 重建和渲染来渐进地对多视图图像进行去噪;最后进一步对模型进行扩散,支持文本和图像调节,实现可控生成。
多视图扩散和去噪
多视图扩散。2D扩散模型中处理的原始 x_0 分布在数据集中是单个图像分布。相反,研究者考虑的是多视图图像
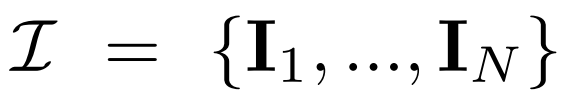
的联合分布,其中每组
都是从视点 C = {c_1, .. ., c_N} 中相同 3D 场景(资产)的图像观察结果。扩散过程相当于使用相同的噪声调度独立地对每个图像进行扩散操作,如下公式 (1) 所示。
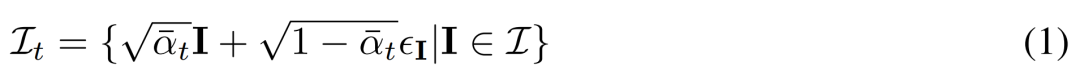
基于重建的去噪。2D 扩散过程的逆过程本质上是去噪。本文中,研究者提出利用 3D 重建和渲染来实现 2D 多视图图像去噪,同时输出干净的、用于 3D 生成的 3D 模型。具体来讲,他们使用 3D 重建模块 E (・) 来从有噪声的多视图图像
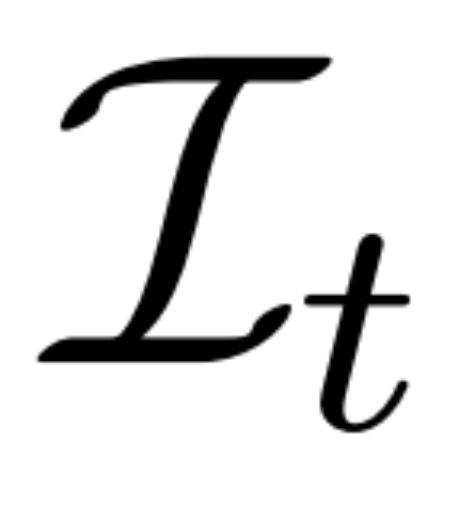
中重建 3D 表示 S,并使用可微渲染模块 R (・) 对去噪图像进行渲染,如下公式 (2) 所示。
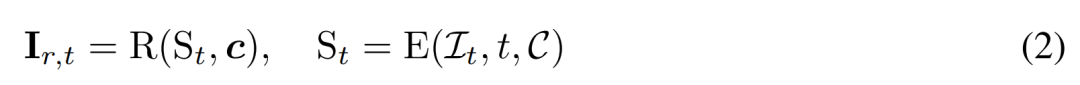
基于重建的多视图降噪器
研究者基于 LRM 构建了多视图降噪器,并使用大型 transformer 模型从有噪声的稀疏视图姿态图像中重建了一个干净的三平面 NeRF,然后将重建后的三平面 NeRF 的渲染用作去噪输出。
重建和渲染。如下图 3 所示,研究者使用一个 Vision Transformer(DINO)来将输入图像
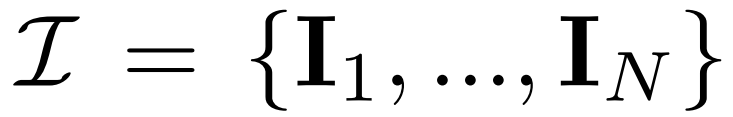
转化为 2D token,然后使用 transformer 将学得的三平面位置嵌入映射到最后的三平面,以表示资产的 3D 形状和外观。接下来将预测到的三平面用来通过一个 MLP 来解码体积密度和颜色,以进行可微体积渲染。
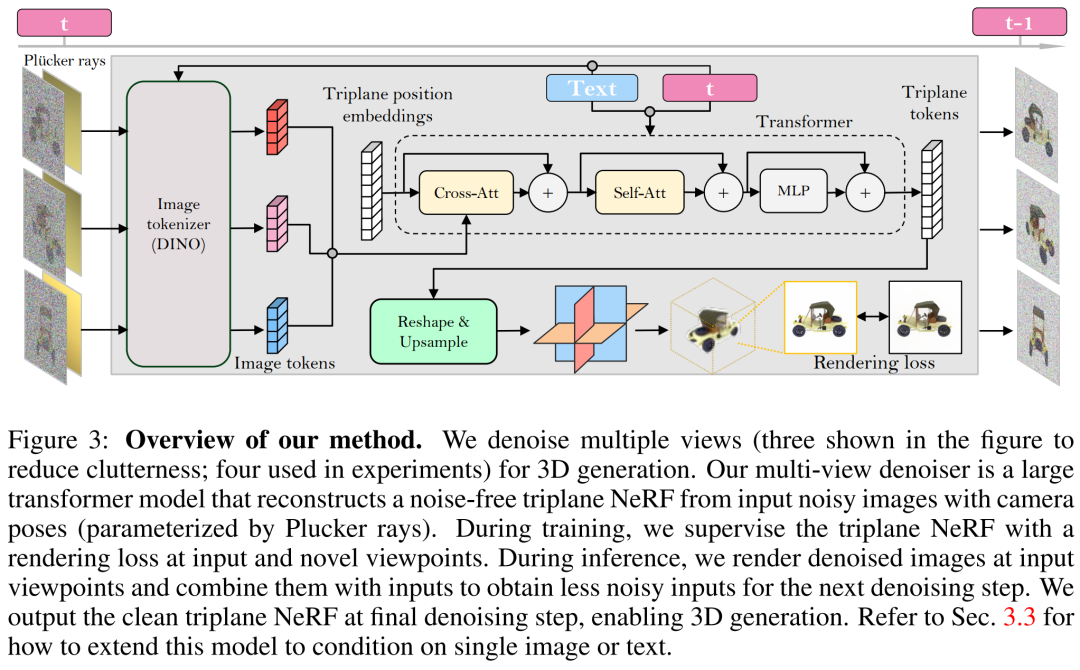
时间调节。与基于 CNN 的 DDPM(去噪扩散概率模型)相比,本文基于 transformer 的模型需要不同的时间调节设计。
相机调节。在具有高度多样化的相机内参和外参的数据集(如 MVImgNet)上训练本文的模型时,研究者表示需要对输入相机调节进行有效的设计,以促使模型理解相机并实现 3D 推理。
在单个图像或文本上调节
以上方法使研究者提出的模型可以充当一个无条件生成模型。他们介绍了如何利用条件降噪器
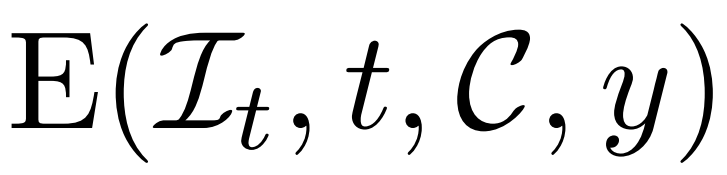
来对条件概率分布进行建模,其中 y 表示文本或图像,以实现可控 3D 生成。
图像调节。研究者提出了一种简单但有效的图像调节策略,其中不需要改变模型的架构。
文本调节。为了将文本调节添加到自己的模型中,研究者采用了类似于 Stable Diffusion 的策略。他们使用 CLIP 文本编码器生成文本嵌入,并使用交叉注意力将它们注入到降噪器中。
训练和推理
训练。在训练阶段,研究者在范围 [1, T] 内均匀地采样时间步 t,并根据余弦调度来添加噪声。他们使用随机相机姿态对输入图像进行采样,还随机采样额外的新视点来监督渲染以获得更好的质量。
研究者使用条件信号 y 来最小化以下训练目标。
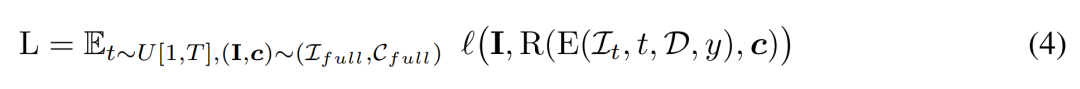
推理。在推理阶段,研究者选择了以圆圈均匀围绕对象的视点,以确保很好地覆盖生成的 3D 资产。他们将四个视图的相机市场角固定为 50 度。
实验结果
在实验环节,研究者使用了 AdamW 优化器来训练自己的模型,其中初始学习率为 4e^-4。他们针对该学习率使用了 3K 步的预热和余弦衰减,使用 256 × 256 输入图像来训练降噪器,对 128 × 128 的裁剪图像进行渲染以进行监督。
关于数据集,研究者的模型只需多视图姿态图像来训练,因而使用来自 Objaverse 数据集的约 730k 个对象的渲染后多视图图像。对于每个对象,他们按照 LRM 的设置,在对固定 50 度 FOV 的随机视点均匀照明下,渲染了 32 张图像。
首先是单图像重建。研究者将自己的图像 - 调节模型与 Point-E、Shap-E、Zero-1-to-3 和 Magic123 等以往方法在单图像重建任务上进行了比较。他们使用到的指标有 PSNR、LPIPS、CLIP 相似性得分和 FID,以评估所有方法的新视图渲染质量。
下表 1 分别展示了 GSO 和 ABO 测试集上的定量结果。研究者的模型优于所有基线方法,并在两个数据集上实现所有指标的新 SOTA。
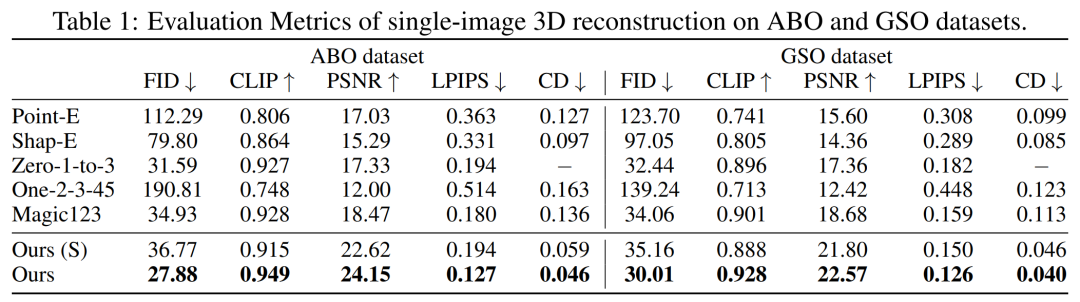
图 4 为定性结果,相比基线,本文模型生成的结果具有更高质量的几何和更清晰的外观细节。
相比之下,DMV3D 是一个以 2D 图像为训练目标的单阶段模型,无需对每个资产单独优化,在消除多视图扩散噪声的同时,直接生成 3D NeRF 的模型。总的来说,DMV3D 可以快速生成 3D 图像,并获得最优的单图像 3D 重建结果。

从文本到 3D。研究者还评估了 DMV3D 基于文本的 3D 生成结果。研究者将 DMV3D 和同样能够支持全类别的快速推理的 Shap-E 和 Point-E 进行了比较。研究者让三个模型根据 Shap-E 的 50 个文本提示进行生成,并使用了两个不同的 ViT 模型的 CLIP 精度和平均精度来评估生成结果,如表 2 所示。
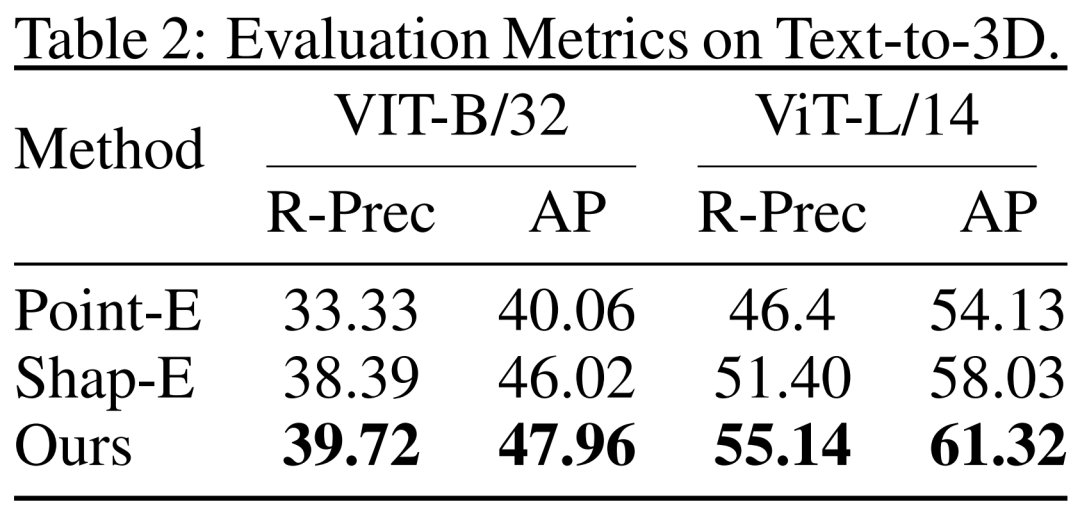
从表中可以看出,DMV3D 表现出了最佳的精度。图 5 中是定性结果,相比于其他模型的生成结果,DMV3D 生成的图形明显包含更丰富的几何和外观细节,结果也更逼真。

其他结果
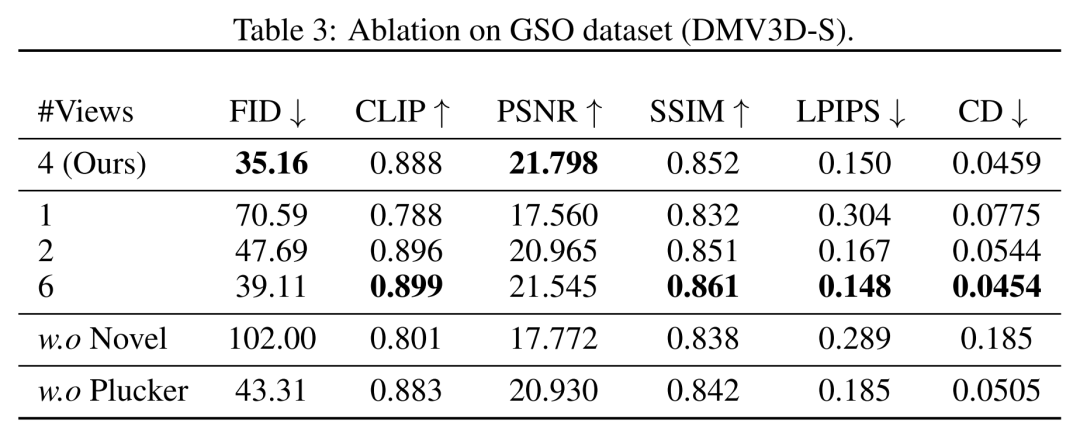
在视角方面,研究者在表 3 和图 8 中显示了用不同数量(1、2、4、6)的输入视图训练的模型的定量和定性比较。

在多实例生成方面,与其他扩散模型类似,本文提出的模型可以根据随机输入生成多种示例,如图 1 所示,展示了该模型生成结果的泛化性。

在应用方面,DMV3D 具备广泛的灵活性和通用性,在 3D 生成应用领域具备较强的发展潜力。如图 1 和图 2 所示,本文方法能够在图像编辑应用程序中通过分割(如 SAM)等方法将 2D 照片中的任意对象提升到 3D 的维度。