相关文章
- 梯度下降算法、随机梯度下降算法、动量随机梯度下降算法、AdaGrad算法、RMSProp算法、Adam算法详细介绍及其原理详解
- 反向传播算法和计算图详细介绍及其原理详解
文章目录
- 相关文章
- 前言
- 一、反向传播算法
- 1.1 什么是反向传播算法?
- 1.2 更泛化的例子
- 二、计算图
- 2.1 什么是传播图?
- 2.2 一个简单的例子
- 总结
前言
本文总结了关于反向传播算法以及计算图的相关内容以及原理,并通过举例说明整个运算过程。下面就是本篇博客的全部内容!
一、反向传播算法
1.1 什么是反向传播算法?
假设现在有如下图的一个过程:

使用直线
y
=
w
x
+
b
y=wx+b
y=wx+b去拟合数据,初始输入值为
x
x
x,参数为
w
,
b
w,b
w,b,得到预测值
y
y
y,其真实值为
y
g
t
y_{gt}
ygt,那么可以得到损失函数为:
L
=
1
2
(
y
−
y
g
t
)
2
L=\frac{1}{2}\left(y-y_{g t}\right)^{2}
L=21(y−ygt)2
现在我们的目的是通过更新参数
w
,
b
w,b
w,b使得损失值最小,为了更直观的演示,我们先给参数赋值,其中
ε
\varepsilon
ε表示学习率:
- x = 1.5 x=1.5 x=1.5
- w = 0.8 w=0.8 w=0.8
- b = 0.2 b=0.2 b=0.2
- ε = 0.1 \varepsilon=0.1 ε=0.1
假设真实值 y g t = 0.8 y_{gt}=0.8 ygt=0.8,那么通过赋的初始值,可以得到:
- y = 0.8 × 1.5 + 0.2 = 1.4 y=0.8×1.5+0.2=1.4 y=0.8×1.5+0.2=1.4
- L = 0.17 L=0.17 L=0.17
此时就要利用之前学过的梯度下降算法来更新参数,首先要求出损失函数
L
L
L对参数
w
w
w的偏导数:
∂
L
∂
w
\frac{\partial L}{\partial w}
∂w∂L
然后更新参数
w
w
w:
w
=
w
−
ε
∂
L
∂
w
w = w-\varepsilon \frac{\partial L}{\partial w}
w=w−ε∂w∂L
另一个参数
b
b
b也是一样的过程,首先计算损失函数
L
L
L对参数
b
b
b的偏导数:
∂
L
∂
b
\frac{\partial L}{\partial b}
∂b∂L
然后更新参数
b
b
b:
b
=
b
−
ε
∂
L
∂
b
b = b-\varepsilon \frac{\partial L}{\partial b}
b=b−ε∂b∂L
上面的过程看似很简单,但是如何求得
∂
L
∂
w
\frac{\partial L}{\partial w}
∂w∂L与
∂
L
∂
b
\frac{\partial L}{\partial b}
∂b∂L呢?以参数
w
w
w为例,很明显损失函数
L
L
L是关于参数
y
y
y的函数,而
y
y
y又是关于参数
w
w
w的偏导,所以根据高等数学中学过的链式求导法则可以得到:
∂
L
∂
w
=
∂
L
∂
y
∂
y
∂
w
\frac{\partial L}{\partial w}=\frac{\partial L}{\partial y} \frac{\partial y}{\partial w}
∂w∂L=∂y∂L∂w∂y
所以首先我们要求出损失函数
L
L
L对参数
y
y
y的偏导:
∂
L
∂
y
=
y
−
y
g
t
\frac{\partial L}{\partial y}=y-y_{g t}
∂y∂L=y−ygt
然后再求出
y
y
y对
w
w
w的偏导:
∂
y
∂
w
=
x
\frac{\partial y}{\partial w}=x
∂w∂y=x
再将其代入可以得到:
∂
L
∂
w
=
∂
L
∂
y
∂
y
∂
w
=
(
y
−
y
g
t
)
x
\frac{\partial L}{\partial w}=\frac{\partial L}{\partial y} \frac{\partial y}{\partial w}=(y-y_{g t})x
∂w∂L=∂y∂L∂w∂y=(y−ygt)x
同理我们也可以求出
∂
L
∂
b
\frac{\partial L}{\partial b}
∂b∂L:
∂
L
∂
b
=
∂
L
∂
y
∂
y
∂
b
=
y
−
y
g
t
\frac{\partial L}{\partial b}=\frac{\partial L}{\partial y} \frac{\partial y}{\partial b}=y-y_{g t}
∂b∂L=∂y∂L∂b∂y=y−ygt
然后再将预设好的数据值代入,就可以得到损失函数
L
L
L关于参数
w
,
b
w,b
w,b的偏导值:
∂
L
∂
w
=
0.9
\frac{\partial L}{\partial w}=0.9\\
∂w∂L=0.9
∂ L ∂ b = 0.6 \frac{\partial L}{\partial b}=0.6 ∂b∂L=0.6
当我们所有的参数都计算出后,代入更新参数 w , b w,b w,b的公式,就可以根据梯度下降算法更新参数得到:
- w = 0.71 w=0.71 w=0.71
- b = 0.14 b=0.14 b=0.14
- y = 0.71 × 1.5 + 0.14 = 1.205 y=0.71×1.5+0.14=1.205 y=0.71×1.5+0.14=1.205
- L = 0.082 L=0.082 L=0.082
可以看到,预测值越来越接近真实值,并且损失值也变小了。可以发现,我们要更新参数 w , b w,b w,b,就要从后向前依次求偏导才能得到结果,这种利用梯度从后向前更新参数的方法,也被称为反向传播算法(Back-Propagation,BR)。
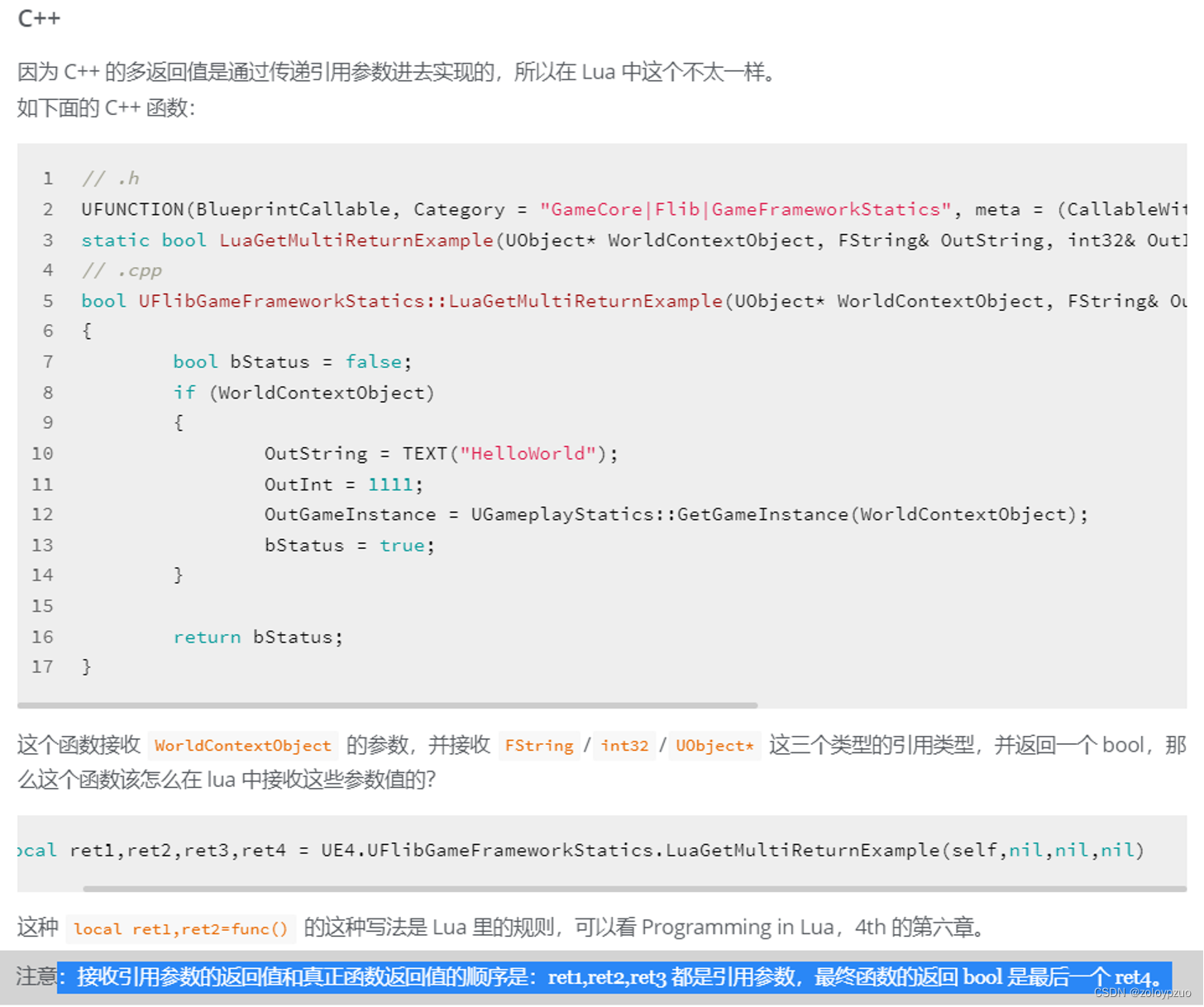
1.2 更泛化的例子
刚才介绍的例子参数比较少,计算过程也比较简单,那如果我们的情况更泛化,也更复杂呢?假设有如下图的一种情况:

此时我们要更新的参数为 w 1 , b 1 w_{1},b_{1} w1,b1,第一次计算的结果 y 1 y_{1} y1又当作参数传入下一个神经元,经过与参数 w 2 , b 2 w_{2},b_{2} w2,b2的计算得到最终的结果 y 2 y_{2} y2,然后用 L ( y 2 , y g t ) L(y_{2},y_{gt}) L(y2,ygt)表示经过两次拟合后的结果与真实值的误差。
更新参数
w
1
,
b
1
w_{1},b_{1}
w1,b1最重要的就是求出
∂
L
∂
w
1
\frac{\partial L}{\partial w_{1}}
∂w1∂L和
∂
L
∂
b
1
\frac{\partial L}{\partial b_{1}}
∂b1∂L,我们先计算
∂
L
∂
w
1
\frac{\partial L}{\partial w_{1}}
∂w1∂L,根据函数关系,我们可以得到如下链式求导公式:
∂
L
∂
w
1
=
∂
L
∂
y
2
∂
y
2
∂
y
1
∂
y
1
∂
w
1
\frac{\partial L}{\partial w_{1}}=\frac{\partial L}{\partial y_{2}} \frac{\partial y_{2}}{\partial y_{1}} \frac{\partial y_{1}}{\partial w_{\mathbf{1}}}
∂w1∂L=∂y2∂L∂y1∂y2∂w1∂y1
可以看到,整个计算过程是从后向前依次计算的,这也符合反向传播算法对此过程的描 述。当我们得到
∂
L
∂
w
1
\frac{\partial L}{\partial w_{1}}
∂w1∂L后,就可以利用参数更新公式来更新参数:
w
1
=
w
1
−
ε
∂
L
∂
w
1
w_{1} = w_{1}-\varepsilon \frac{\partial L}{\partial w_{1}}
w1=w1−ε∂w1∂L
同理,我们也可以得到关于参数
b
1
b_{1}
b1的链式求导公式:
∂
L
∂
b
1
=
∂
L
∂
y
2
∂
y
2
∂
y
1
∂
y
1
∂
b
1
\frac{\partial L}{\partial b_{1}}=\frac{\partial L}{\partial y_{2}} \frac{\partial y_{2}}{\partial y_{1}} \frac{\partial y_{1}}{\partial b_{1}}
∂b1∂L=∂y2∂L∂y1∂y2∂b1∂y1
然后再使用参数更新公式来更新参数即可:
b
1
=
b
1
−
ε
∂
L
∂
b
1
b_{1} = b_{1}-\varepsilon \frac{\partial L}{\partial b_{1}}
b1=b1−ε∂b1∂L
以上过程就是反向传播算法的全部过程,当然,在深度学习的应用中,反向传播算法需要计算的神经元个数是非常多的,但是原理与此无异,就是链式求导法则的一个应用。而在链式求导公式中的许多参数已经在上一步计算好了,所以不需要重复计算,这就使在神经网络训练过程中,节省很多不必要的计算,故反向传播算法就是神经网络中加速计算参数梯度值的方法。
二、计算图
2.1 什么是传播图?
还是刚才的例子,输入数据经过两个神经元的运算得到最终的输出数据 y 2 y_{2} y2,通过与真实值的比较得到损失函数 L ( y 2 , y g t ) L(y_{2},y_{gt}) L(y2,ygt),整个过程如下图所示:

从左往右的计算过程也叫前向传播,这个很好理解,就是一级一级的向下计算传播。那么计算机中如何表示这个过程呢?计算机会将每个运算小步骤保存下来,记录为一个参数,等待下次运算,具体的运算过程可见下图:

引入的变量 u 1 u_{1} u1就是为了存储参数 x x x和 w 1 w_{1} w1运算小步骤的结果,然后等待下次运算的时候,直接将其作为参数进行计算即可,后面的参数同理,很明显这样看起来更“舒服”,符合计算机逐步运算的逻辑,经过运算最终可以得到最终的预测值 y 2 y_{2} y2和损失函数 L {L} L,这种模块化的计算过程图就称为计算图(Computation Graphs)。
现在我们已经知道计算机如何利用计算图通过前向传播得到最终的预测值 y 2 y_{2} y2和损失函数 L {L} L了,那么计算机又如何利用计算图进行反向传播呢?也就是说,计算机如何利用计算图计算出损失函数 L L L对于各个参数的梯度呢?对于这个计算过程,可见下图:

可以看到,计算损失函数 L L L对于各个参数的梯度仍和之前的计算方法一致,只是由于引入了中间变量 u i , ( 1 ≤ i ≤ 2 ) u_{i},(1≤i≤2) ui,(1≤i≤2),所以每次计算关于损失函数 L L L对于 u u u中参数的偏导数时,要先计算损失函数 L L L对于 u u u的偏导数,其余计算过程并没有变化,其中需要注意:
- 黄色的变量:通过此步骤的之前步骤得到的运算结果
- 绿色的变量:通过前向传播得到的已知的数据
最终同样可以得到损失函数 L L L关于参数 w i , b i , ( 1 ≤ i ≤ 2 ) w_{i},b_{i},(1≤i≤2) wi,bi,(1≤i≤2)的偏导数,然后就可以利用之前介绍的梯度下降算法进行参数的优化更新了。
2.2 一个简单的例子
我们现在已经明白什么是计算图了,那么计算机如何利用计算图的原理去进行有关深度学习的计算呢?我们以Pytorch中的乘法运算为例,其运算图如下所示:

-
前向传播
Pytorch中乘法运算的前向传播代码如下所示:
class Multiply(torch.autograd.Function): @staticmethod def forward(ctx, x, y): ctx.save_for_backward(x,y) z = x * y return z可以看到,整段代码的运算过程恰如乘法运算计算图中绿色所示部分,直接获取到关于 x x x和 y y y的参数,然后进行相乘得到 z z z,最后返回 z z z即可。
-
反向传播
Pytorch中乘法运算的反向传播代码如下所示:
class Multiply(torch.autograd.Function): @staticmethod def backward(ctx, grad_z): x, y = ctx.saved_tensors grad_x = grad_z * y grad_y = grad_z * x return grad_x, grad_y这个就和前向传播的代码有所不同,因为其计算需要求损失函数 L L L关于各个参数的偏导数,所以此段代码对应乘法运算计算图中黄色所示部分。其中, g e a d _ z = ∂ L ∂ z gead\_z=\frac{\partial L}{\partial z} gead_z=∂z∂L,而我们需要求得损失函数 L L L分别对 x , y x,y x,y的偏导数,其具体表示为:
grad_x = grad_z * y对应:
∂ L ∂ x = ∂ L ∂ z ∂ z ∂ x = ∂ L ∂ z y \frac{\partial L}{\partial x}=\frac{\partial L}{\partial z} \frac{\partial z}{\partial x}=\frac{\partial L}{\partial z} y ∂x∂L=∂z∂L∂x∂z=∂z∂Ly
grad_y = grad_z * x对应:
∂ L ∂ y = ∂ L ∂ z ∂ z ∂ y = ∂ L ∂ z x \frac{\partial L}{\partial y}=\frac{\partial L}{\partial z} \frac{\partial z}{\partial y}=\frac{\partial L}{\partial z} x ∂y∂L=∂z∂L∂y∂z=∂z∂Lx
这样就可以通过计算图利用反向传播算法来更新数以亿计的网络参数了。
总结
以上就是本篇博客的全部内容了,文章内容不算太长,但是有些地方还是不太好理解的,最好有些高等数学的基础,学起来会更“舒服”。本系列还会一直更新,敬请期待!