敏感词过滤方案
敏感词过滤用的使用比较多的 Trie 树算法 和 DFA 算法。
Trie 树
Trie 树 也称为字典树、单词查找树,哈系树的一种变种,通常被用于字符串匹配,用来解决在一组字符串集合中快速查找某个字符串的问题。像浏览器搜索的关键词提示一般就是基于 Trie 树来做的。
假如我们的敏感词库中有以下敏感词:
- 高清视频
- 高清 CV
- 东京冷
- 东京热
我们构造出来的敏感词 Trie 树就是下面这样的:
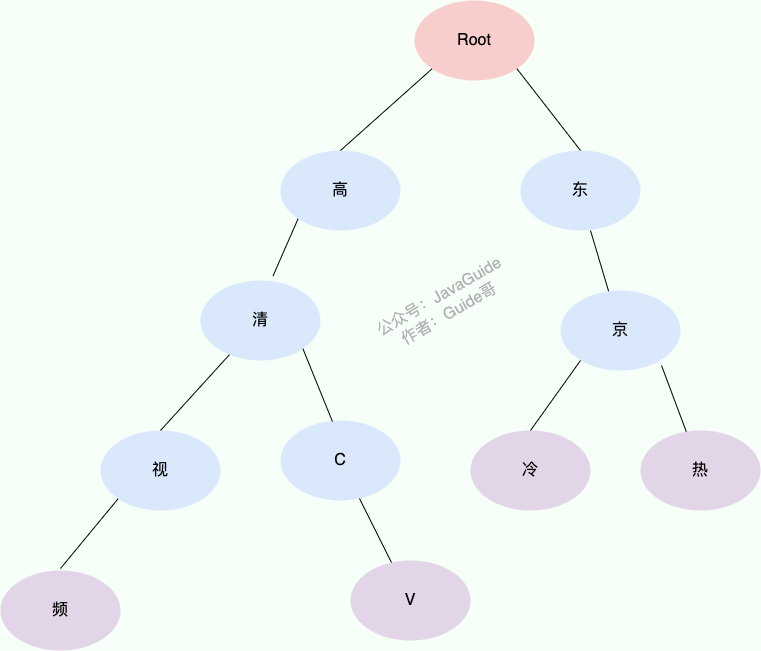
当我们要查找对应的字符串“东京热”的话,我们会把这个字符串切割成单个的字符“东”、“京”、“热”,然后我们从 Trie 树的根节点开始匹配。
可以看出, Trie 树的核心原理其实很简单,就是通过公共前缀来提高字符串匹配效率。
Trie<String, String> trie = new PatriciaTrie<>();
trie.put("Abigail", "student");
trie.put("Abi", "doctor");
trie.put("Annabel", "teacher");
trie.put("Christina", "student");
trie.put("Chris", "doctor");
Assertions.assertTrue(trie.containsKey("Abigail"));
assertEquals("{Abi=doctor, Abigail=student}", trie.prefixMap("Abi").toString());
assertEquals("{Chris=doctor, Christina=student}", trie.prefixMap("Chr").toString());
DFA
DFA(Deterministic Finite Automata)即确定有穷自动机,与之对应的是 NFA(Non-Deterministic Finite Automata,不确定有穷自动机)。
WordTree wordTree = new WordTree();
wordTree.addWord("大");
wordTree.addWord("大憨憨");
wordTree.addWord("憨憨");
String text = "那人真是个大憨憨!";
// 获得第一个匹配的关键字
String matchStr = wordTree.match(text);
System.out.println(matchStr);
// 标准匹配,匹配到最短关键词,并跳过已经匹配的关键词
List<String> matchStrList = wordTree.matchAll(text, -1, false, false);
System.out.println(matchStrList);
//匹配到最长关键词,跳过已经匹配的关键词
List<String> matchStrList2 = wordTree.matchAll(text, -1, false, true);
System.out.println(matchStrList2);
作者声明
如有问题,欢迎指正!





](https://img-blog.csdnimg.cn/direct/18584035f8424bf29b9577a875bc8db7.png)