奇异值分解
SVD是一个很有用的矩阵因子化方法。
SVD提出的目的:任何一个
m
×
n
m\times n
m×n的矩阵都可以当作一个超椭圆(高维空间的椭圆),可以把它们当作单位球体S的像。
一个超椭圆可以通过将单位球型在正交方向
u
1
,
u
2
,
.
.
.
,
u
m
\mathbf{u_1},\mathbf{u_2},...,\mathbf{u_m}
u1,u2,...,um通过缩放因子
σ
1
,
.
.
.
,
σ
m
\sigma_1,..., \sigma_m
σ1,...,σm,其中m是维度,如果在平面上m=2
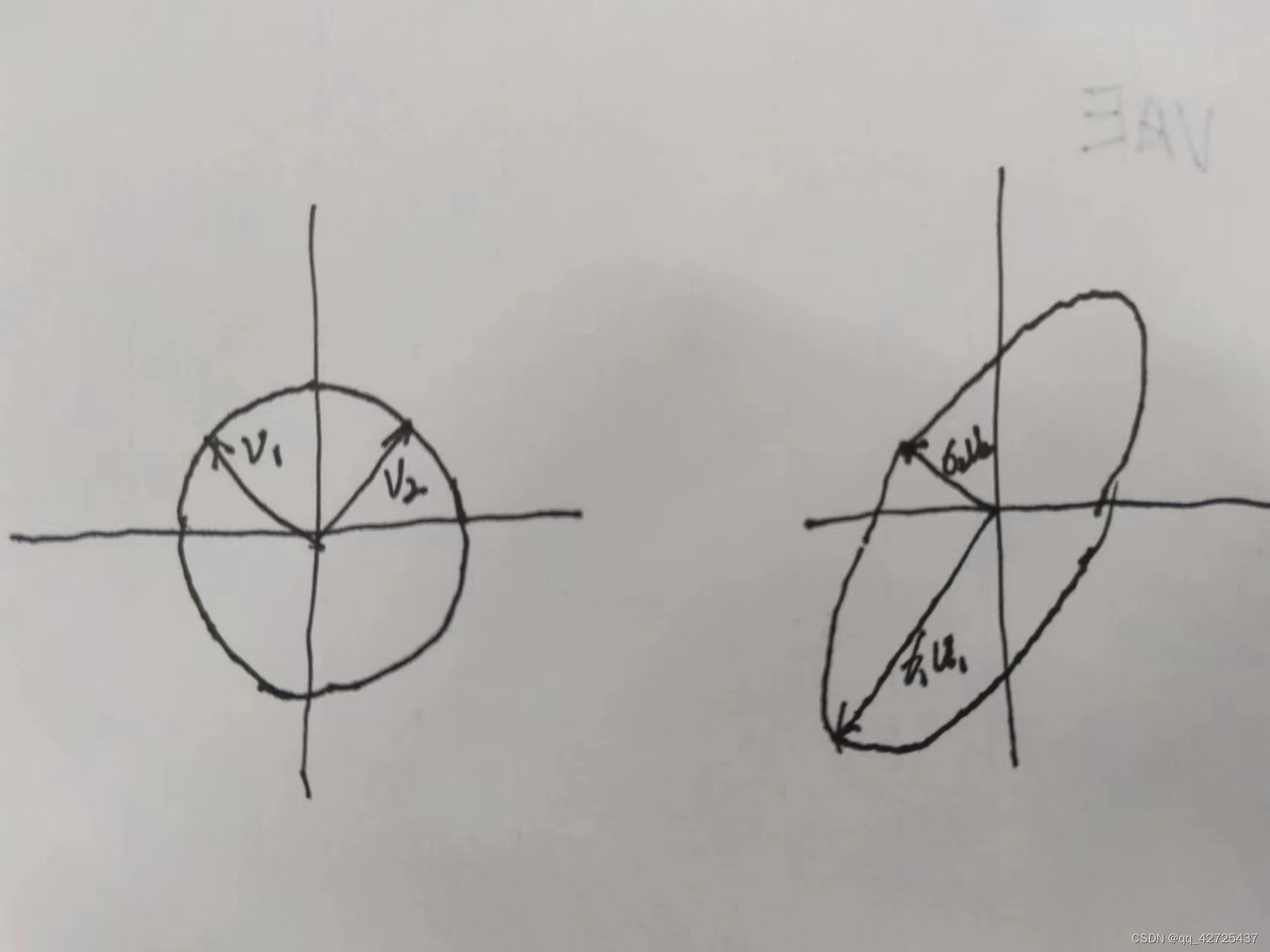
通过上面这张图,可以做出下面的定义:
- singular value: σ 1 , . . . , σ n ≥ 0 \sigma_1,..., \sigma_n\geq 0 σ1,...,σn≥0一般假设 σ 1 ≥ σ 2 ≥ . . . \sigma_1 \geq \sigma_2 \geq ... σ1≥σ2≥...
- Light singular vectors: u 1 , u 2 , . . . , u n \mathbf{u_1},\mathbf{u_2},...,\mathbf{u_n} u1,u2,...,un,单位向量
- right singular vectors:
v
1
,
v
2
,
.
.
.
,
v
n
\mathbf{v_1},\mathbf{v_2},...,\mathbf{v_n}
v1,v2,...,vn是ui的逆向满足
A
v
i
=
σ
i
u
i
Av_i = \sigma_i u_i
Avi=σiui
这个名字中左和右来自svd的公式。
把上面的公式矩阵化,可以得到:
A V = U ^ Σ ^ AV = \hat U \hat \Sigma AV=U^Σ^
在这里面 - Σ ^ ∈ R n × n \hat{\Sigma}\in\mathbb{R}^{n\times n} Σ^∈Rn×n是一个非负数对角矩阵
- U ^ ∈ R m × n \hat{U}\in\mathbb{R}^{m\times n} U^∈Rm×n是一个列正交矩阵
-
V
∈
R
n
×
n
V\in\mathbb{R}^{n\times n}
V∈Rn×n是一个列正交矩阵
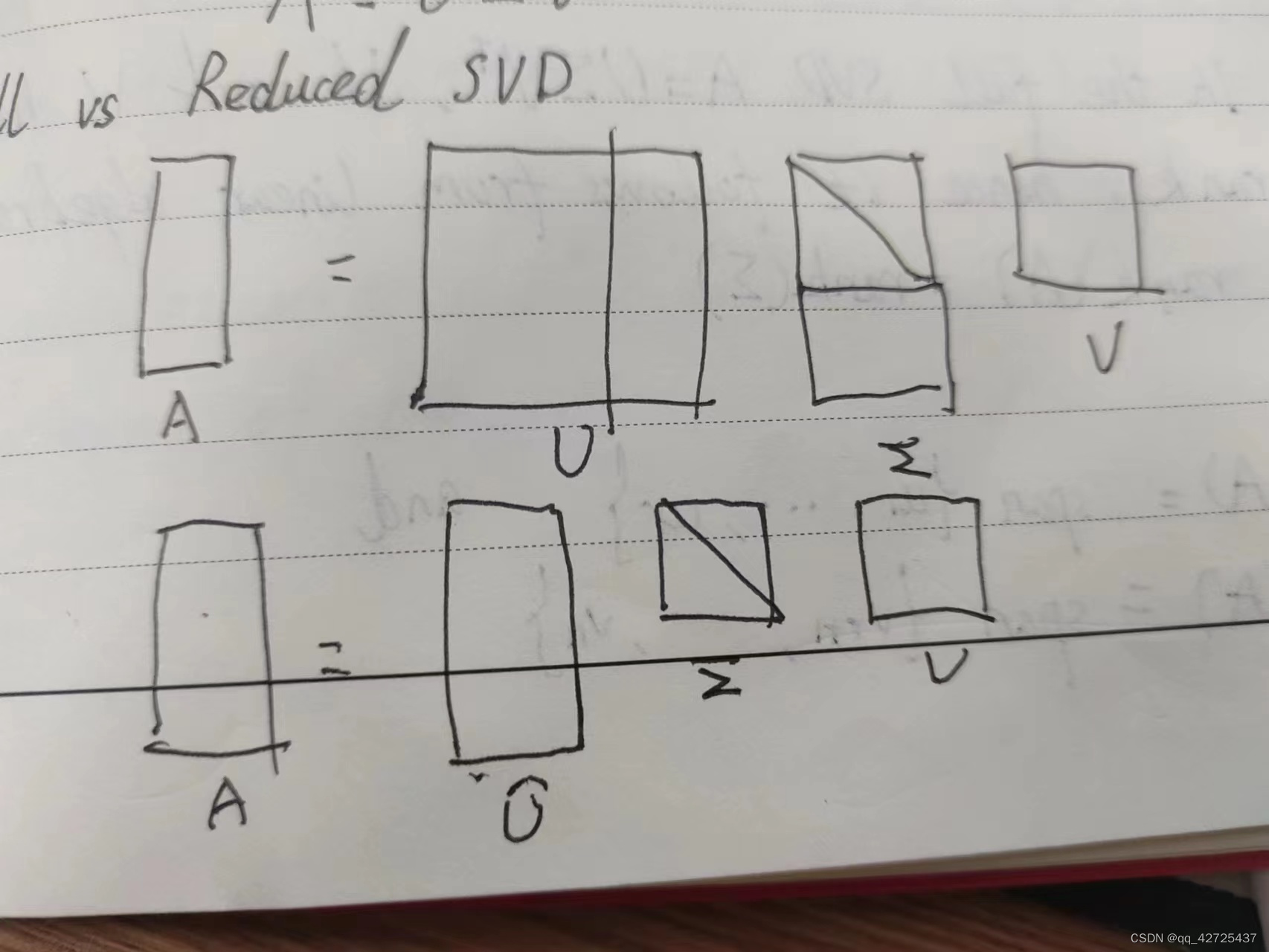
因此V是个正交矩阵,因为它是基向量,因此我们就可以得到reduced SVD:
A = U ^ Σ ^ V T A = \hat U \hat \Sigma V^T A=U^Σ^VT
正如QR分解一样,可以把扩充 U ^ \hat U U^的列使得 U ∈ R m × m U\in\mathbb{R}^{m\times m} U∈Rm×m
然后需要给 Σ ^ \hat{\Sigma} Σ^添加一些为为0的行,使得可以沉默掉新添加到U中的随机列,这样就得到了完全SVD
A = U Σ V T A = U \Sigma V^T A=UΣVT
对比reduced和full
现在重新考虑当时把球型变为超椭圆型的目的。
1 V T V^T VT是球型S
2 Σ \Sigma Σ拉伸球型得到椭球形
3 U U U旋转投射而不改变形状
通过SVD可以知道一些矩阵性质
- A的秩为r,也就是非零奇异值的个数
proof:U和V是满秩的,所以rank(A) = rank( Σ \Sigma Σ) - image(A) = span{
u
1
,
u
2
,
.
.
.
,
u
r
\mathbf{u_1},\mathbf{u_2},...,\mathbf{u_r}
u1,u2,...,ur}
null(A) = span{ v r + 1 , . . . , v n \mathbf{v_{r+1}},...,\mathbf{v_n} vr+1,...,vn} -
∣
∣
A
∣
∣
2
=
σ
1
||A||_2=\sigma_1
∣∣A∣∣2=σ1
proof: ∣ ∣ A ∣ ∣ 2 ≡ m a x ∣ ∣ V ∣ ∣ 2 = 1 ||A||_2 \equiv max_{||V||_2=1} ∣∣A∣∣2≡max∣∣V∣∣2=1||Av||_2 - A的奇异值是AAT的特征值的平方根。
根据上面的性质:可以知道SVD的两种应用
长方形矩阵的条件数
K
(
A
)
=
∣
∣
A
∣
∣
∣
∣
A
+
∣
∣
K(A)=||A||||A^+||
K(A)=∣∣A∣∣∣∣A+∣∣
其中
A
+
A^+
A+是伪逆
- ∣ ∣ A ∣ ∣ 2 = σ m a x ||A||_2 = \sigma_{max} ∣∣A∣∣2=σmax
-
∣
∣
A
+
∣
∣
2
=
1
σ
m
i
n
||A^+||_2 = \frac{1}{\sigma_{min}}
∣∣A+∣∣2=σmin1
所以 K ( A ) = σ m a x σ m i n K(A)=\frac{\sigma_{max}}{\sigma_{min}} K(A)=σminσmax
低秩近似
把SVD变为
A
=
∑
j
=
1
r
σ
j
u
j
v
j
T
A = \sum^r_{j=1}\sigma_j u_j v_j^T
A=j=1∑rσjujvjT
每个
u
j
v
j
T
u_j v_j^T
ujvjT都是一个秩为1的矩阵
Theorem:
对于
0
≤
v
≤
r
0\leq v \leq r
0≤v≤r,让
A
v
=
∑
j
=
1
v
σ
j
u
j
v
j
T
Av = \sum^v_{j=1}\sigma_ju_jv_j^T
Av=∑j=1vσjujvjT
所以
∣
∣
A
−
A
v
∣
∣
2
=
inf
B
∈
R
m
×
n
,
r
a
n
k
(
B
)
≤
v
∣
∣
A
−
B
∣
∣
2
||A-Av||_2 = \inf_{B\in \mathbb{R}^{m\times n}, rank(B)\leq v}{||A-B||_2}
∣∣A−Av∣∣2=B∈Rm×n,rank(B)≤vinf∣∣A−B∣∣2
同样的也可以在Frobenius norm中证明,这个理论说明SVD是压缩矩阵的一个好的方法。
![[机缘参悟-120] :计算机世界与佛家看世界惊人的相似](https://img-blog.csdnimg.cn/direct/0b2ff4f0f6e84f35a7cb2a54b86ad5e0.png)