大家好!在本文中,我想分享我对经常用作标识符的数据类型的知识和看法。今天我们将同时讨论两个主题。这些是数据库端按键和键的数据类型衡量的搜索速度。
我将使用PostgreSQL数据库和演示Java服务来比较查询速度。
UUID 和 ULID
为什么我们需要某种难以理解的 ID 类型?我不会谈论分布式系统、服务的连接性、敏感数据等。如果有人对此感兴趣,他们可以谷歌它 - 目前我们对性能感兴趣。顾名思义,我们将讨论两种类型的键:UUID 和 ULID。
UUID早已为大家所熟知,但ULID可能有些人感到陌生。ULID 的主要优点是它是单调递增的并且是可排序的类型。当然,这些还不是全部差异。就我个人而言,我也喜欢其中没有特殊字符的事实。
一个小题外话,我很早之前注意到很多团队varchar(36)在PostgreSQL数据库中使用数据类型来存储UUID,而我不喜欢这样,因为这个数据库有UUID对应的数据类型。稍后,我们将看到哪种类型在数据库方面更可取。因此,我们不仅会在后端比较两种数据类型,还会在数据库端以不同格式存储 UUID 时的差异。
比较
那么让我们开始比较一下吧。
-
UUID长度为36个字符,占用128位内存。
-
ULID 长度为 26 个字符,也占用 128 位内存。
对于我的示例,我在数据库中创建了两个包含三个字段的表:
CREATE TABLE test.speed_ulid(id varchar(26) PRIMARY KEY,name varchar(50),created timestamp);CREATE TABLE test.speed_uuid(id varchar(36) PRIMARY KEY,name varchar(50),created timestamp);
varchar(36)对于第一次比较,我按照通常的做法以格式存储了 UUID 。在数据库中,我在每个表中记录了 1,000,000。
测试用例将包含 100 个使用先前从数据库中提取的标识符的请求;也就是说,当调用测试方法时,我们将访问数据库100次并通过键检索实体。连接将在测量前创建并预热。我们将进行两次测试运行,然后进行 10 次有效迭代。为了您的方便,我将在文章末尾提供 Java 代码的链接。
抱歉,这些测量是在标准 MacBook Pro 笔记本电脑上进行的,而不是在专用服务器上进行的,但我认为除了数据库和后端之间的网络流量花费的时间增加之外,结果不会有显着差异。
以下是一些背景信息:
-
# CPU I9-9980HK
-
# CPU 数量:16
-
# 内存:32GB
-
# JMH版本:1.37
-
# 虚拟机版本:JDK 11.0.12、Java HotSpot(TM) 64 位服务器虚拟机、11.0.12+8-LTS-237
-
# DB:PostgreSQL 13.4,版本 1914,64 位
将用于通过键获取实体的查询:
SELECT * FROM test.speed_ulid where id = ?SELECT * FROM test.speed_uuid where id = ?
测量结果
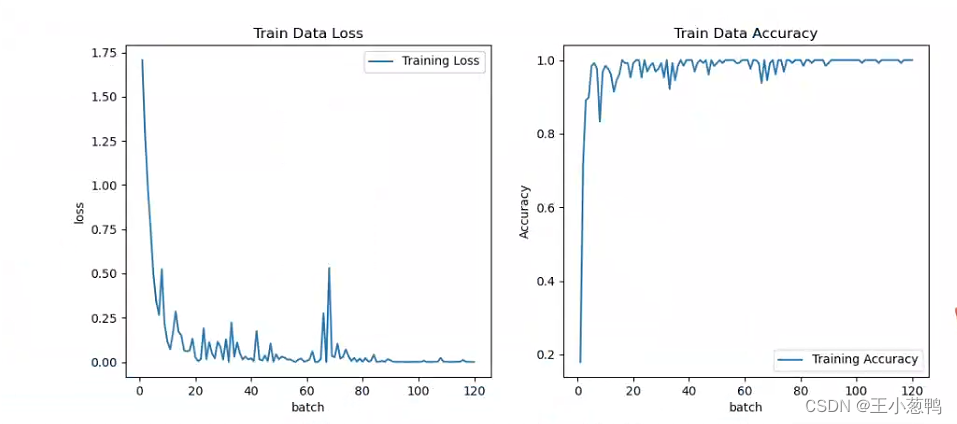
我们来看看测量结果。让我提醒您,每个表有 1,000,000 行。
-
两种类型的标识符都以 varchar 形式存储在数据库中

我多次运行此测试,结果大致相同:要么是 ULID 快一点,要么是 UUID。从百分比来看,差异几乎为零。
好吧,你可以不同意这些类型之间没有区别。我想说的是,不可能在数据库端使用其他数据类型。
-
UUID 为 uuid,ULID 为数据库中的 varchar
对于下一个测试,我将test.speed_uuid表中的数据类型从 更改varchar(36)为uuid。

在这种情况下,差异很明显:4.5% 支持 UUID。
uuid正如您所看到的,在服务端有同名类型的情况下,使用数据库端的数据类型是有意义的。这种格式的索引在 PostgreSQL 中得到了很好的优化,并显示出良好的结果。
好吧,现在我们绝对可以分道扬镳了。或不?
如果您查看索引搜索查询计划,您可以((id)::text = '01HEE5PD6HPWMBNF7ZZRF8CD9R'::text)在我们使用 varchar 的情况下看到以下内容。
一般来说,比较两个文本变量是一个相当慢的操作,因此也许不需要以这种格式存储 ID。或者还有其他方法可以加快密钥比较速度吗?hash首先,我们为具有 ULID 的表创建另一个“ ”类型的索引。
create index speed_ulid_id_indexon test.speed_ulid using hash (id);
让我们看看查询的执行计划:

我们将看到数据库使用哈希索引,而不是本例中的 B 树。让我们运行测试,看看会发生什么。
-
varchar + index(hash) 表示 ULID,uuid 表示 UUID

uuid这种组合相对于其作弊指数增加了 2.3% 。
我不确定在一个字段上保留两个索引是否合理。因此,值得考虑是否还有更多事情可以做。在这里,值得回顾过去并记住uuid过去如何存储一些其他字符串标识符。没错:文本或字节数组。
因此,让我们尝试这个选项:我删除了 ULID 的所有索引,将其转换为bytea,然后重新创建主键。
-
bytea 代表 ULID,uuid 代表 UUID

结果,我们得到了与上次运行时使用附加索引大致相同的结果,但我个人更喜欢这个选项。
数据库中2,000,000行的测量结果:

数据库中3,000,000行的测量结果:

我认为继续进一步测量是没有意义的。模式仍然是:保存为 ULID 的性能bytea略优于保存为数据库中的 UUID uuid。
如果我们从第一次测量中获取数据,很明显,在小操作的帮助下,如果使用varchar.
因此,如果您已经读到这里,我认为您对这篇文章很感兴趣,并且您已经自己得出了一些结论。
值得注意的是,测量是在后端部分和数据库的理想条件下进行的。我们没有运行任何并行进程来向数据库写入数据、更改记录或在后端执行复杂的计算。
结论
让我们回顾一下材料。你学到了什么有用的东西?
-
不要忽视 PostgreSQL 端的 uuid 数据类型。也许有一天这个数据库会出现 ULID 的扩展,但现在我们只能用现有的。
-
有时候,手动创建一个额外的所需类型的索引是值得的,但也要考虑到额外的开销。
-
如果你不怕多余的工作 - 即编写自己的类型转换器 - 那么如果数据库端没有对应的标识符类型,你应该尝试使用 bytea。
主键应该使用什么类型的数据,以及应该以什么格式存储?对这些问题我没有一个明确的答案:这一切都取决于许多因素。同样值得注意的是,对 ID 的数据类型的合理选择,不仅仅是它,有时在你的项目中可以起到重要作用。
作者:Artem Artemev
更多技术干货请关注公号【云原生数据库】
squids.cn,云数据库RDS,迁移工具DBMotion,云备份DBTwin等数据库生态工具。