文章目录
- 0. Abstract
- 1. Introduction
- 2. Related work
- 3. Methods-NERF FOR STREET VIEWS
- 3.1 CAMERA POSE PROCESSING
- 3.2 REPRESENTATION OF STREET SCENES
- 3.3 DEPTH SUPERVISION
- 3.4 Loss function
- 4. EXPERIMENTS
- 5. Conclusion
- Reference
0. Abstract
Problem introduction:
However, we conjugate that this paradigm does not fit the nature of the street views that are collected by many self-driving cars from the large-scale unbounded scenes. Also,the onboard cameras perceive scenes without much overlapping.
Solutions:
Consider novel view synthesis of both the large-scale background scenes and the foreground moving vehicles jointly.
Improve the scene parameterization function and the camera poses.
We also use the the noisy and sparse LiDAR points to boost the training and learn a robust geometry and reprojection-based confidence to address the depth outliers.
Extend our S-NeRF for reconstructing moving vehicles
Effect:
Reduce 7∼ 40% of the mean-squared error in the street-view synthesis and a 45% PSNR gain for the moving vehicles rendering
1. Introduction
Overcome the shortcomings of the work of predecessors:
-
MipNeRF-360 (Barron et al., 2022) is designed for training in unbounded scenes. But it still needs enough intersected camera rays
-
BlockNeRF (Tancik et al., 2022) proposes a block-combination strategy with refined poses, appearances, and exposure on the MipNeRF (Barron et al., 2021) base model for processing large-scale outdoor scenes. But it needs a special platform to collect the data, and is hard to utilize the existing dataset.
-
Urban-NeRF (Rematas et al., 2022) takes accurate dense LiDAR depth as supervision for the reconstruction of urban scenes. But the accurate dense LiDAR is too expensive. S-Nerf just needs the noisy sparse LiDAR signals.
2. Related work
There are lots of papers in the field of Large-scale NeRF and Depth supervised NeRF

This paper is included in the field of both of them.
3. Methods-NERF FOR STREET VIEWS
3.1 CAMERA POSE PROCESSING
SfM used in previous NeRFs fails. Therefore, we proposed two different methods to reconstruct the camera poses for the static background and the foreground moving vehicles.
-
Background scenes
For the static background, we use the camera parameters achieved by sensor-fusion SLAM and IMU of the self-driving cars (Caesar et al., 2019; Sun et al., 2020) and further reduce the inconsistency between multi-cameras with a learning-based pose refinement network.
-
Moving vehicles
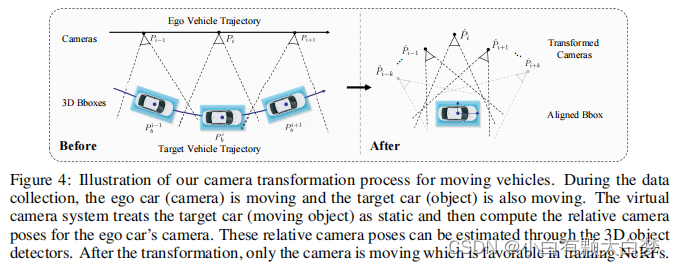
We now transform the coordinate system by setting the target object’s center as the coordinate system’s origin.
P ^ i = ( P i P b − 1 ) − 1 = P b P i − 1 , P − 1 = [ R T − R T T 0 T 1 ] . \hat{P}_i=(P_iP_b^{-1})^{-1}=P_bP_i^{-1},\quad P^{-1}=\begin{bmatrix}R^T&-R^TT\\\mathbf{0}^T&1\end{bmatrix}. P^i=(PiPb−1)−1=PbPi−1,P−1=[RT0T−RTT1].And, P = [ R T 0 T 1 ] P=\begin{bmatrix}R&T\\\mathbf{0}^T&1\end{bmatrix} P=[R0TT1]represents the old position of the camera or the target object.
After the transformation, only the camera is moving which is favorable in training NeRFs.
How to convert the parameter matrix.
3.2 REPRESENTATION OF STREET SCENES
-
Background scenes
constrain the whole scene into a bounded range

This part is from mipnerf-360
-
Moving Vehicles
Compute the dense depth maps for the moving cars as an extra supervision
-
We follow GeoSim (Chen et al., 2021b) to reconstruct coarse mesh from multi-view images and the sparse LiDAR points.
-
After that, a differentiable neural renderer (Liu et al., 2019) is used to render the corresponding depth map with the camera parameter (Section 3.2).
-
The backgrounds are masked during the training by an instance segmentation network (Wang et al., 2020).
There are three references
-
3.3 DEPTH SUPERVISION

To provide credible depth supervisions from defect LiDAR depths, we first propagate the sparse depths and then construct a confidence map to address the depth outliers(异常值).
-
LiDAR depth completion
Use NLSPN (Park et al., 2020) to propagate the depth information from LiDAR points to surrounding pixels.
-
Reprojection confidence
Measure the accuracy of the depths and locate the outliers.
The warping operation can be represented as:
X t = ψ ( ψ − 1 ( X s , P s ) , P t ) \mathbf{X}_t=\psi(\psi^{-1}(\mathbf{X}_s,P_s),P_t) Xt=ψ(ψ−1(Xs,Ps),Pt)
And we use three features to measure the similarity:
C r g b = 1 − ∣ I s − I ^ s ∣ , C s s i m = S S I M ( I s , I ^ s ) ) , C v g g = 1 − ∥ F s − F ^ s ∥ . \mathcal{C}_{\mathrm{rgb}}=1-|\mathcal{I}_{s}-\hat{\mathcal{I}}_{s}|,\quad\mathcal{C}_{\mathrm{ssim}}=\mathrm{SSIM}(\mathcal{I}_{s},\hat{\mathcal{I}}_{s})),\quad\mathcal{C}_{\mathrm{vgg}}=1-\|\mathcal{F}_{s}-\hat{\mathcal{F}}_{s}\|. Crgb=1−∣Is−I^s∣,Cssim=SSIM(Is,I^s)),Cvgg=1−∥Fs−F^s∥.
-
Geometry confidence
Measure the geometry consistency of the depths and flows across different views.
The depth:
C d e p t h = γ ( ∣ d t − d ^ t ) ∣ / d s ) , γ ( x ) = { 0 , if x ≥ τ , 1 − x / τ , otherwise . \left.\mathcal{C}_{depth}=\gamma(|d_t-\hat{d}_t)|/d_s),\quad\gamma(x)=\left\{\begin{array}{cc}0,&\text{if}x\geq\tau,\\1-x/\tau,&\text{otherwise}.\end{array}\right.\right. Cdepth=γ(∣dt−d^t)∣/ds),γ(x)={0,1−x/τ,ifx≥τ,otherwise.
The flow:
C f l o w = γ ( ∥ Δ x , y − f s → t ( x s , y s ) ∥ ∥ Δ x , y ∥ ) , Δ x , y = ( x t − x s , y t − y s ) . \mathcal{C}_{flow}=\gamma(\frac{\|\Delta_{x,y}-f_{s\rightarrow t}(x_{s},y_{s})\|}{\|\Delta_{x,y}\|}),\quad\Delta_{x,y}=(x_{t}-x_{s},y_{t}-y_{s}). Cflow=γ(∥Δx,y∥∥Δx,y−fs→t(xs,ys)∥),Δx,y=(xt−xs,yt−ys).
-
Learnable confidence combination
The final confidence map can be learned as C ^ = ∑ i ω i C i , \hat{\mathcal{C}}=\sum_{i}{\omega_{i}\mathcal{C}_{i}}, C^=∑iωiCi, where ∑ i w i = 1 \sum_iw_i=1 ∑iwi=1 and i ∈ { r g b , s s i m , v g g , d e p t h , f l o w } i \in \{rgb,ssim,vgg,depth,flow\} i∈{rgb,ssim,vgg,depth,flow}
3.4 Loss function
A RGB loss, a depth loss, and an edge-aware smoothness constraint to penalize large variances in depth.
L
c
o
l
o
r
=
∑
r
∈
R
∥
I
(
r
)
−
I
^
(
r
)
∥
2
2
L
d
e
p
t
h
=
∑
C
^
⋅
∣
D
−
D
^
∣
L
s
m
o
o
t
h
=
∑
∣
∂
x
D
^
∣
exp
−
∣
∂
x
I
∣
+
∣
∂
y
D
^
∣
exp
−
∣
∂
y
I
∣
L
t
o
t
a
l
=
L
c
o
l
o
r
+
λ
1
L
d
e
p
t
h
+
λ
2
L
s
m
o
o
t
h
\begin{aligned} &\mathcal{L}_{\mathrm{color}}=\sum_{\mathbf{r}\in\mathcal{R}}\|I(\mathbf{r})-\hat{I}(\mathbf{r})\|_{2}^{2} \\ &\mathcal{L}_{depth}=\sum\hat{\mathcal{C}}\cdot|\mathcal{D}-\hat{\mathcal{D}}| \\ &\mathcal{L}_{smooth}=\sum|\partial_{x}\hat{\mathcal{D}}|\exp^{-|\partial_{x}I|}+|\partial_{y}\hat{\mathcal{D}}|\exp^{-|\partial_{y}I|} \\ &\mathcal{L}_{\mathrm{total}}=\mathcal{L}_{\mathrm{color}}+\lambda_{1}\mathcal{L}_{depth}+\lambda_{2}\mathcal{L}_{smooth} \end{aligned}
Lcolor=r∈R∑∥I(r)−I^(r)∥22Ldepth=∑C^⋅∣D−D^∣Lsmooth=∑∣∂xD^∣exp−∣∂xI∣+∣∂yD^∣exp−∣∂yI∣Ltotal=Lcolor+λ1Ldepth+λ2Lsmooth
4. EXPERIMENTS
- Dataset: nuScenes and Waymo
- For the foreground vehicles, we extract car crops from nuScenes and Waymo video sequences.
- For the large-scale background scenes, we use scenes with 90∼180 images.
- In each scene, the ego vehicle moves around 10∼40 meters, and the whole scene span more than 200m.
-
Foreground Vehicles
Different experiments in static vehicles and moving vehicles, compared with Origin-NeRF and GeoSim(the latest non-NeRF car reconstruction method).
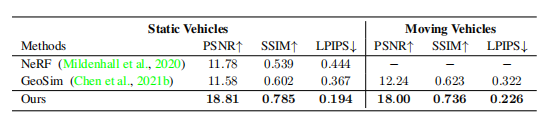
There are large room for improvement in PSNR
-
Background scenes
Compared with the state-of-the-art methods Mip-NeRF (Barron et al., 2021), Urban-NeRF (Rematas et al., 2022), and Mip-NeRF 360.

Also, show a 360-degree panorama to emphasize some details:

-
BACKGROUND AND FOREGROUND FUSION
Depth-guided placement and inpainting (e.g. GeoSim Chen et al. (2021b)) and joint NeRF rendering (e.g. GIRAFFE Niemeyer & Geiger (2021)) heavily rely on accurate depth maps and 3D geometry information.
A new method was used without an introduction? -
Ablation study

Split into RGB, depth confidence, and smooth loss.
5. Conclusion
In the future, we will use the block merging as proposed in Block-NeRF (Tancik et al., 2022) to learn a larger city-level neural representation
Reference
[1] S-NeRF (ziyang-xie.github.io)



![2023-简单点-机器学习中常用的特殊函数,激活函数[sigmoid tanh ]](https://img-blog.csdnimg.cn/cf2756c94616431bb6c1e7aef3ae82f1.png)