filebeat日志收集工具
elk:filebeat日志收集工具和logstash相同
filebeat是一个轻量级的日志收集工具,所使用的系统资源比logstash部署和启动时使用的资源要小的多
filebeat可以运行在非Java环境,它可以代理logstash在非java环境上收集日志
logstash不足
filebeat无法实现数据的过滤,一般是结合logstash的数据过滤功能一起使用
filebeat工作流程
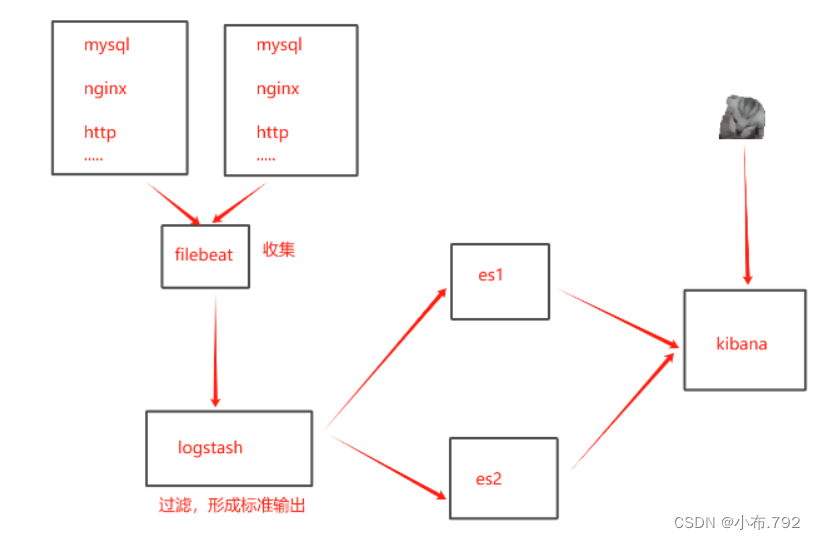
1、filebeat收集服务日志发送给logstash
2、logstash过滤,形成标准输出,发送到es主机上
3、es主机在发送给kibana
4、kiabana图形化界面
5、用户通过kiabana查看收集的日志
filebeat实验部署
安装filebeat
准备四台主机
把filebeat源码包拖到opt目录下
vim /etc/logstash/logstash.yml
64行
重启服务
做时间同步
yum install ntpdate -y
ntpdate ntp.aliyun.com
安装nginx
并重启服务
给nginx的日志文件给权限
chmod 777 access.log error.log
给filebeat的配置文件做个备份
cp filebeat.yml filebeat.yml.bak
vim filebeat.yml
filebeat inputs模块
enabled:true
paths:
- /usr/local/nginx/logs/access.log
- /usr/local/nginx/logs/error.log
tags: ["nginx"]
fileds:
service_name: 20.0.0.12_nginx
log_type: nginx
from: 20.0.0.12
mkdir log
vim file_nginx.conf
input {
beats { port => "5044"}
}
output {
if "nginx" in [tags]{
elasticsearch {
hosts => ["20.0.0.10:9200","20.0.0.11:9200"]
index => "%{[fields][service_name]}-%{YYYY.MM.dd}"
}
}
stdout{
codec => rubydebug
}
}
nohup ./filebaet -e -c filebeat.yml > filebeat.out &
nohup 表示在后台纪录执行命令的过程
./filebeat 运行文件
-e 使用标准输出的同时进行syslog文件输出
-c 配置文件
执行过程输出到filebeat.out,&后台运行
:
查看是否报错
tail -f /opt/filebeat/filebeat.out
logstash -f file_nginx.conf --path.data /opt/test 本地收集
远程收集,远程收集多个日志
mysql
vim /etc/my.cnf
general_log=ON
generl_log_file=/usr/local/mysql/data/mysql_general.log
重启服务
查看日志文件是否创建成功
在MySQL上创建表
create table xiaobu (id int(2),name varchar(20));
mysql上安装nginx,httpd
vim /etc/nginx/nginx.conf
改变端口
重启服务
http
vim /var/www/html/index.html
vim /usr/share/nginx/html/index.html
浏览器访问
20.0.0.50:8080
把filebeat拖到opt目录下
压缩
cd /filebeat
vim filebeat.yml
enabled: true
paths:
- /var/log/nginx/access.log
- /var/log/nginx/error.log
tags: ["nginx_50"]
fileds:
service_name: 20.0.0.50_nginx
log_type: nginx
from: 20.0.0.50
- type: log
enabled: true
paths:
- /etc/httpd/logs/access.log
- /etc/httpd/logs/error.log
tags: ["httpd_50"]
fileds:
service_name: 20.0.0.50_httpd
log_type: httpd
from: 20.0.0.50
- type: log
enabled: true
paths:
- /usr/log/mysql/data/mysql_general.log
tags: ["mysql_50"]
fileds:
service_name: 20.0.0.50_mysql
log_type: mysql
from: 20.0.0.50
cd /opt/log
vim file_mysql.log
input {
beats { port => "5045"}
}
output {
if "nginx_50" in [tags] {
elasticsearch {
hosts => ["20.0.0.10:9200","20.0.0.10:9200"]
index => "%{[fileds][service_name]}-%{+YYYY.MM.dd}"
}
}
if "httpd_50" in [tags] {
elasticsearch {
hosts => ["20.0.0.10:9200","20.0.0.10:9200"]
index => "%{[fileds][service_name]}-%{+YYYY.MM.dd}"
}
}
if "mysql_50" in [tags] {
elasticsearch {
hosts => ["20.0.0.10:9200","20.0.0.10:9200"]
index => "%{[fileds][service_name]}-%{+YYYY.MM.dd}"
}
}
stdout {
codec => rubydebug
}
}
nohup ./filebeat -e -c filebeat.yml > filbeat.out &
kibana
logstash -f file_mysql.conf --path.data /opt/test1logstash 可以使用任意端口,只要没被占用都可以使用,推荐从1024使用
logstash 性能上的优化
logstash启动时在JVM虚拟机当中启动,启动一次至少500MB的内存
找到logstash的配置文件
vim /etc/logstash/logstash.yml
pipeline.workers:2
定义了,logstash的工作线程,默认就是CPU数,4 1 4 8给一半即可,2核,2个
pipeline.batch.size: 125
一次性能够批量处理检索事件的大小 125条数
pipeline.batch.delay: 50
查询更新的延迟 50(毫秒),也可以自行调整 15(毫秒)