作者:妙临、霁光、玺羽
一、前言
在线广告对于大多数同学来说是一个既熟悉又陌生的技术领域。「搜广推」、「搜推广」等各种组合耳熟能详,但广告和搜索推荐有本质区别:广告解决的是“媒体-广告平台-广告主”等多方优化问题,其中媒体在保证用户体验的前提下实现商业化收入,广告主的诉求是通过出价尽可能优化营销目标,广告平台则在满足这两方需求的基础上促进广告生态的长期繁荣。
广告智能决策技术在这之中起到了关键性的作用,如图 1 所示,它需要解决如下问题在内的一系列智能决策问题:1. 为广告主设计并实现自动出价策略,提升广告投放效果;2. 为媒体设计智能拍卖机制来保证广告生态系统的繁荣和健康。
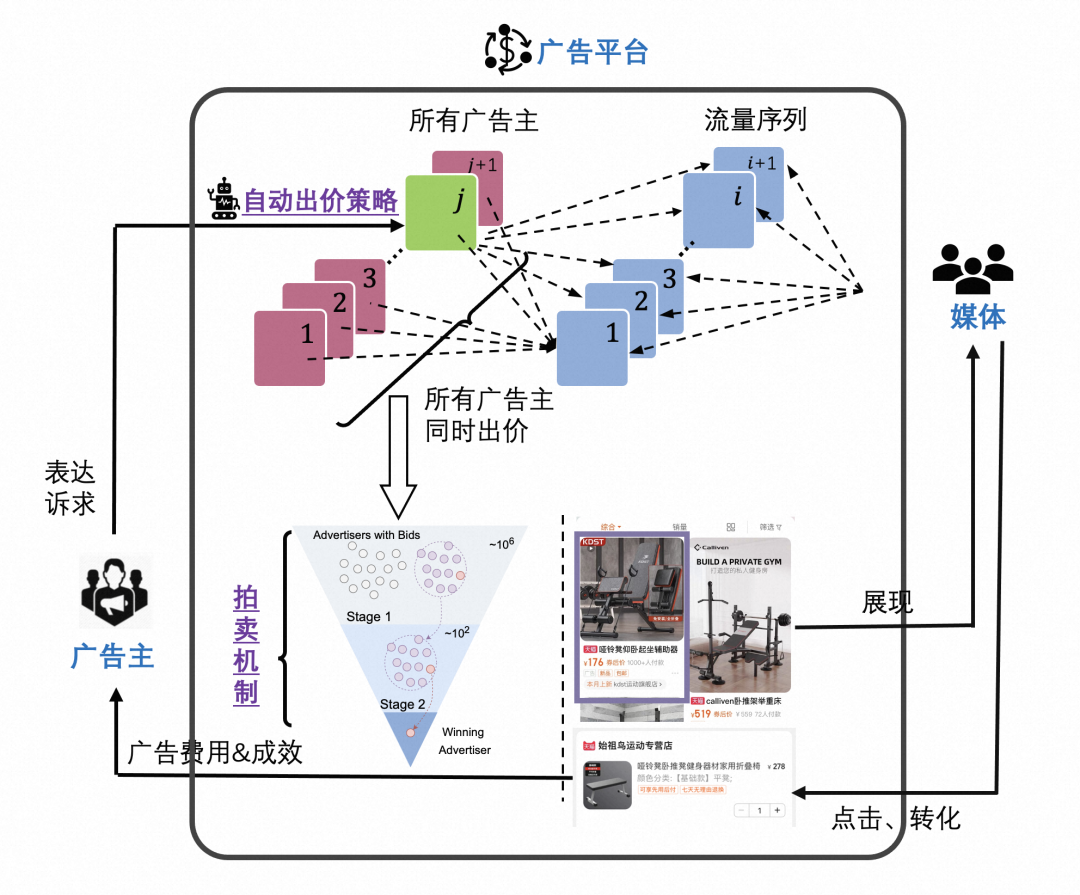
图 1:广告智能决策通过自动出价和拍卖机制等方式实现多方优化
随着智能化营销产品和机器学习的发展,阿里妈妈将深度学习和强化学习等 AI 技术越来越多地应用到广告智能决策领域,如 RL-based Bidding(基于强化学习的出价)帮助广告主显著提升广告营销效果,Learning-based Auction Design(基于学习的拍卖机制设计)使得多方利益的统筹优化更加高效。我们追根溯源,结合时代发展的视角重新审视广告智能决策技术的演化过程,本文将以阿里妈妈广告智能决策技术的演进为例,分享我们工作和思考。也希望能以此来抛砖引玉,和大家一块探讨。
二、持续突破的自动出价决策技术
广告平台吸引广告主持续投放的核心在于给他们带来更大的投放价值,典型的例子就是自动化的出价产品一经推出便深受广告主的喜爱并持续的投入预算。在电商场景下,我们不断地探索流量的多元化价值,设计更能贴近营销本质的自动出价产品,广告主只需要简单的设置就能清晰的表达营销诉求。

图 2:出价产品逐步的智能化 &自动化,广告主只需要简单的设置即可清晰的表达出营销诉求
极简产品背后则是强大的自动出价策略支撑,其基于海量数据自动学习好的广告投放模式,以提升给定流量价值下的优化能力。考虑到广告优化目标、预算和成本约束,自动出价可以统一表示为带约束的竞价优化问题。

其中 B 为广告主的预算,kj 为成本约束,该问题就是要对所有参竞的流量进行报价,以最大化竞得流量上的价值总和。如果已经提前知道要参竞流量集合的全部信息,包括能够触达的每条流量的价值和成本等,那么可以通过线性规划(LP)方法来求得最优解 。然而在线广告环境的动态变化以及每天到访用户的随机性,竞争流量集合很难被准确的预测出来。因此常规方法并不完全适用,需要构建能够适应动态环境的自动出价算法。
对竞价环境做一定的假设(比如拍卖机制为单坑下的 GSP,且流量竞得价格已知),通过拉格朗日变换构造最优出价公式,将原问题转化为最优出价参数的寻优问题[9]:

对于每一条到来的流量按照此公式进行出价,其中 vi,qi,j 为在线流量竞价时可获得的流量信息,为要求解的参数。而参数并不能一成不变,需要根据环境的动态变化不断调整。参竞流量的分布会随时间发生变化,广告主也会根据自己的经营情况调整营销设置,前序的投放效果会影响到后续的投放策略。因此,出价参数的求解本质上是动态环境下的序列决策问题。
2.1 主线:从跟随到引领,迈向更强的序列决策技术
如何研发更先进的算法提升决策能力是自动出价策略发展的主线,我们参考了业界大量公开的正式文献,并结合阿里妈妈自身的技术发展,勾勒出自动出价策略的发展演进脉络。
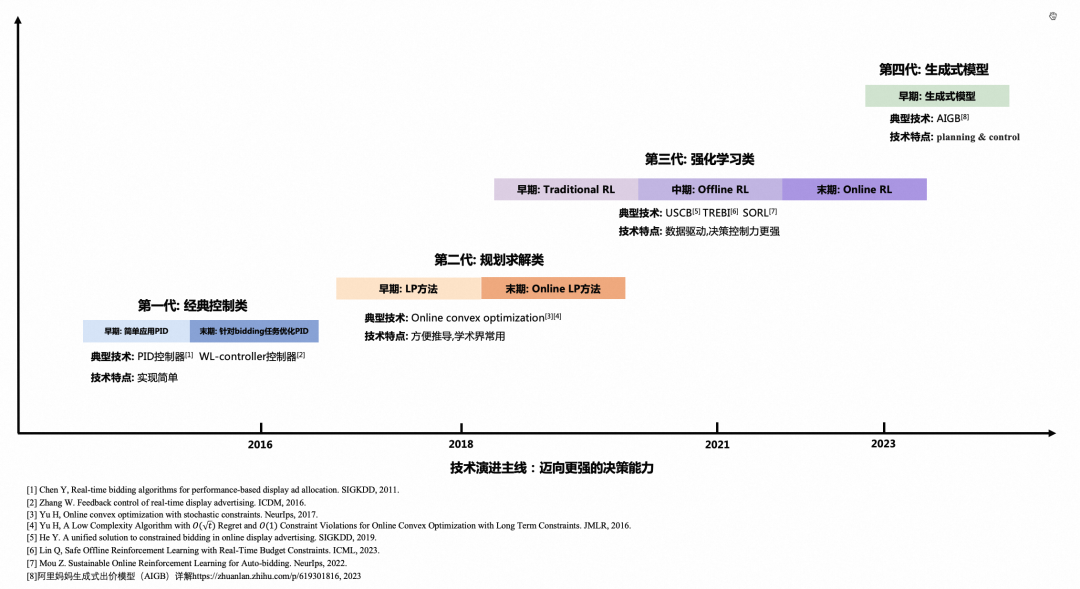
图 3:自动出价策略的演进主线:迈向更强的决策能力
整体可以划分为 4 个阶段:
●第一代:经典控制类
把效果最大化的优化问题间接转化为预算消耗的控制问题。基于业务数据计算消耗曲线,控制预算尽可能按照设定的曲线来消耗。PID[1]及相关改进[2][10]是这一阶段常用的控制算法。当竞价流量价值分布稳定的情况下,这类算法能基本满足业务上线之初的效果优化。
●第二代:规划求解类
相比于第一代,规划求解类(LP)算法直接面向目标最大化优问题来进行求解。可基于前一天的参竞流量来预测当前未来流量集合,从而求解出价参数。自动出价问题根据当前已投放的数据变成新的子问题,因此可多次持续的用该方法进行求解,即 Online LP[3][4]。这类方法依赖对未来参竞流量的精准预估,因此在实际场景落地时需要在未来流量的质和量的预测上做较多的工作。
●第三代:强化学习类
现实环境中在线竞价环境是非常复杂且动态变化的,未来的流量集合也是难以精准预测的,要统筹整个预算周期投放才能最大化效果。作为典型的序列决策问题,第三阶段用强化学习类方法来优化自动出价策略。其迭代过程从早期的经典强化学习方法落地[5][6][8][9],到进一步基于 Offline RL 方法逼近「在线真实环境的数据分布」[9],再到末期贴近问题本质基于 Online RL 方法实现和真实竞价环境的交互学习[13]。
●第四代:生成模型类
以 ChatGPT 为代表的生成式大模型以汹涌澎湃之势到来,在多个领域都表现出令人惊艳的效果。新的技术理念和技术范式可能会给自动出价算法带来革命性的升级。阿里妈妈技术团队提前布局,以智能营销决策大模型 AIGA(AI Generated Action)为核心重塑了广告智能营销的技术体系,并衍生出以 AIGB(AI Generated Bidding)[14]为代表的自动出价策略。
为了让大家有更好的理解,我们以阿里妈妈的实践为基础,重点讲述下强化学习在工业界的落地以及对生成式模型的探索。
✪ 2.1.1 强化学习在自动出价场景的大规模应用实践
跟随:不断学习、曲折摸索
作为典型的序列决策问题,使用强化学习(RL)是很容易想到的事情,但其在工业界的落地之路却是充满曲折和艰辛的。最初学术界[8]做了一些探索,在请求粒度进行建模,基于 Model-based RL 方法训练出价智能体(Agent),并在请求维度进行决策。如竞得该 PV,竞价系统返回该请求的价值,否则返回 0,同时转移到下一个状态。这种建模方法应用到工业界遇到了很多挑战,主要原因在于工业界参竞流量巨大,请求粒度的建模所需的存储空间巨大;转化信息的稀疏性以及延迟反馈等问题也给状态构造和 Reward 设计带来很大的挑战。为使得 RL 方法能够真正落地,需要解决这几个问题:
「MDP 是什么?」 由于用户到来的随机性,参竞的流量之间其实并不存在明显的马尔可夫转移特性,那么状态转移是什么呢?让我们再审视下出价公式,其包含两部分:流量价值和出价参数。其中流量价值来自于请求粒度,出价参数为对当前流量的出价激进程度,而激进程度是根据广告主当前的投放状态来决定的。一种可行的设计是将广告的投放信息按照时间段进行聚合组成状态,上一时刻的投放策略会影响到广告主的投放效果,并构成新一时刻的状态信息,因此按照时间段聚合的广告主投放信息存在马尔可夫转移特性。而且这种设计还可以把问题变成固定步长的出价参数决策,给实际场景中需要做的日志回流、Reward 收集、状态计算等提供了时间空间。典型的工作[5][6][7][8][9][12] 基本上都是采用了这样的设计理念。
「Reward 如何设计?」 Reward 设计是 RL 的灵魂。出价策略的 Reward 设计需要让策略学习如何对数亿计流量出价,以最大化竞得流量下的价值总和。如果 Reward 只是价值总和的话,就容易使得策略盲目追求好流量,预算早早花光或者成本超限,因此还需要引导策略在约束下追求更有性价比的流量。另外,自动出价是终点反馈,即直到投放周期结束才能计算出完整的投放效果。且转化等信号不仅稀疏,还存在较长时间的回收延迟。
因此我们需要精巧设计 Reward 让其能够指导每一次的决策动作。实践下来建立决策动作和最终结果的关系至关重要,比如[9]在模拟环境中保持当前的最优参数,并一直持续到终点,从而获取到最终的效果,以此来为决策动作设置较为精准的 Reward。另外,在实际业务中,为了能够帮助模型更好的收敛,往往也会把业务经验融入到 Reward 设计中。
「如何训练?」 强化学习本质是一个 Trail-and-Error 的算法,需要和环境进行交互收集到当前策略的反馈,并不断探索新的决策空间进一步更新迭代策略。但在工业界,由于广告主投放周期的设置,一个完整的交互过程在现实时间刻度上通常为一天。经典的 RL 算法要训练好一般要经历上万次的交互过程,这在现实系统中很难接受。在实践中,通常构造一个模拟竞价环境用于 RL 模型的训练,这样就摆脱现实时空的约束提升模型训练效率。当然在线竞价环境非常复杂,如何在训练效率和训练效果之间平衡是构造模拟环境中需要着重考虑的事情。这种训练模式,也一般称之为 Simulation RL-based Bidding(简称 SRLB),其流程如下图所示:
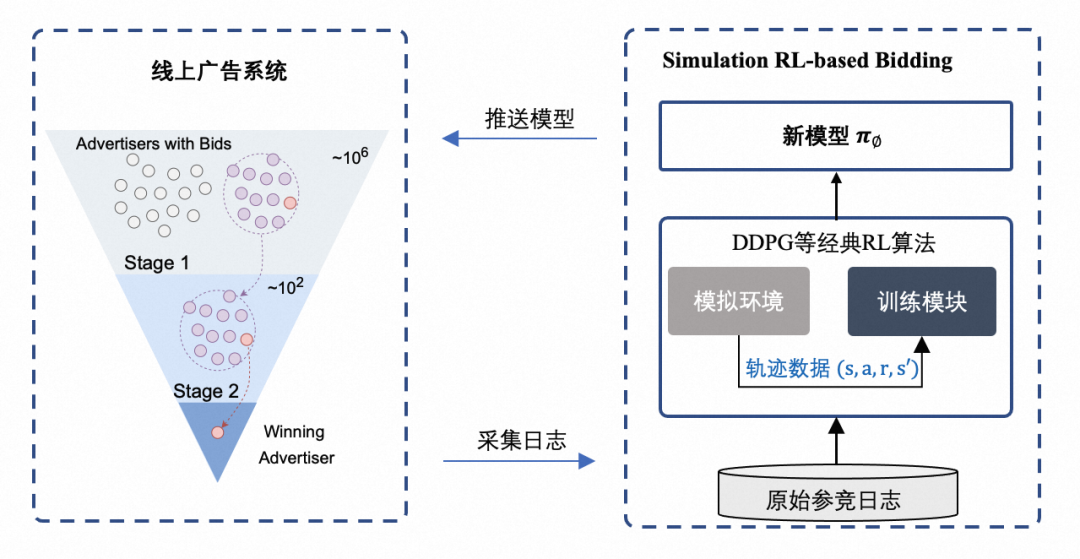
图 4:Simulation RL-based Bidding (SRLB)训练模式
基于 SRLB 训练模式,我们实现了强化学习类算法在工业界场景的大规模落地。根据我们的调研,在搜广推领域,RL 的大规模落地应用较为少见。
创新:立足业务、推陈出新
随着出价策略不断的升级迭代,“模拟环境和在线环境的差异”逐渐成为了效果进一步提升的约束。为了方便构造,模拟环境一般采用单坑 GSP 来进行分配和扣费且假设每条流量有固定的获胜价格(Winning Price)。但这种假设过于简单,尤其是当广告展现的样式越来越丰富,广告的坑位的个数和位置都在动态变化,且 Learning-based 拍卖机制也越来约复杂,使得模拟环境和在线实际环境差异越来越大。基于 Simulation RL-based Bidding 模式训练的模型在线上应用过程中会因环境变化而偏离最优策略,导致线上效果受到损失。
模拟环境也可以跟随线上环境不断升级,但这种方式成本较高难度也大。因此,我们期待能够找到一种不依赖模拟环境,能够对标在线真实环境学习的模式,以使得训练出来的 Bidding 模型能够感知到真实竞价环境从而提升出价效果。
结合业务需求并参考了 RL 领域的发展,我们先后调研了模仿学习、Batch RL、Offline RL 等优化方案,并提出的如下的 Offline RL-based Bidding 迭代范式,期望能够以尽可能小的代价的逼近线上真实的样本分布。
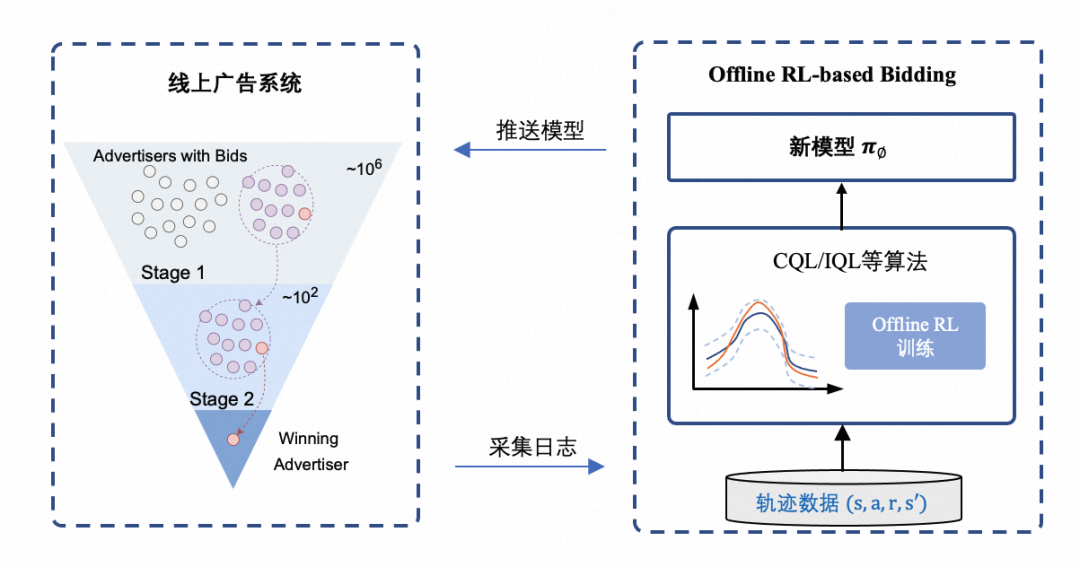
图 5:Offline RL-based Bidding 训练模式,与 SRLB 模式差异主要在训练数据来源和训练方式
在这个范式下,直接基于线上决策过程的日志,拟合 reward 与出价动作之间的相关性,从而避免模拟样本产生的分布偏差。尽管使用真实决策样本训练模型更加合理,但在实践中往往容易产生策略坍塌现象。核心原因就是线上样本不能做到充分探索,对样本空间外的动作价值无法正确估计,在贝尔曼方程迭代下不断的高估。
对于这一问题,我们可以假设一个动作所对应的数据密度越大,支撑越强,则预估越准确度越大,反之则越小。基于这一假设,参考 CQL[21]的思想,构建一种考虑数据支撑度的 RL 模型,利用数据密度对价值网络估值进行惩罚。这一方法可以显著改善动作高估问题,有效解决 OOD 问题导致的策略坍塌,从而使得 Offline RL-based 能够部署到线上并取得显著的效果提升。
后续我们又对这个方法做了改进,借鉴了 IQL[22](Implicit Q learning)中的 In-sample learning 思路,引入期望分位数回归,基于已有的数据集来估计价值网络,相比于 CQL,能提升模型训练和效果提升的稳定性。

图 6:从 CQL 到 IQL,Offline RL-based Bidding 中训练算法的迭代
总结下来,在这一阶段我们基于业务中遇到的实际问题,并充分借鉴业界思路,推陈出新。Offline RL-based Bidding 通过真实的决策数据训练出价策略,比基于模拟环境训练模式(SRLB)能够更好的逼近「线上真实环境的数据分布」。
突破:破解难题、剑走偏锋
让我们再重新审视 RL-based Bidding 迭代历程,该问题理想情况可以通过「与线上真实环境进行交互并学习」的方式求解,但广告投放系统交互成本较高,与线上环境交互所需要的漫长「训练时间成本」和在线上探索过程中可能需要遭受的「效果损失成本」,让我们在早期选择了 Simulation RL-based Bidding 范式,随后为解决这种范式下存在的环境不一致的问题,引入了 Offline RL-based Bidding 范式。

图 7:重新审视 RL-based Bidding 发展脉络
为了能够进一步突破效果优化的天花板,我们需要找到一种新的 Bidding 模型训练范式:能够不断的和线上进行交互探索新的决策空间且尽可能减少因探索带来的效果损失。还能够在融合了多种策略的样本中进行有效学习。即控制「训练时间成本」和「效果损失成本」下的 Online RL-based Bidding 迭代范式,如下图所示:
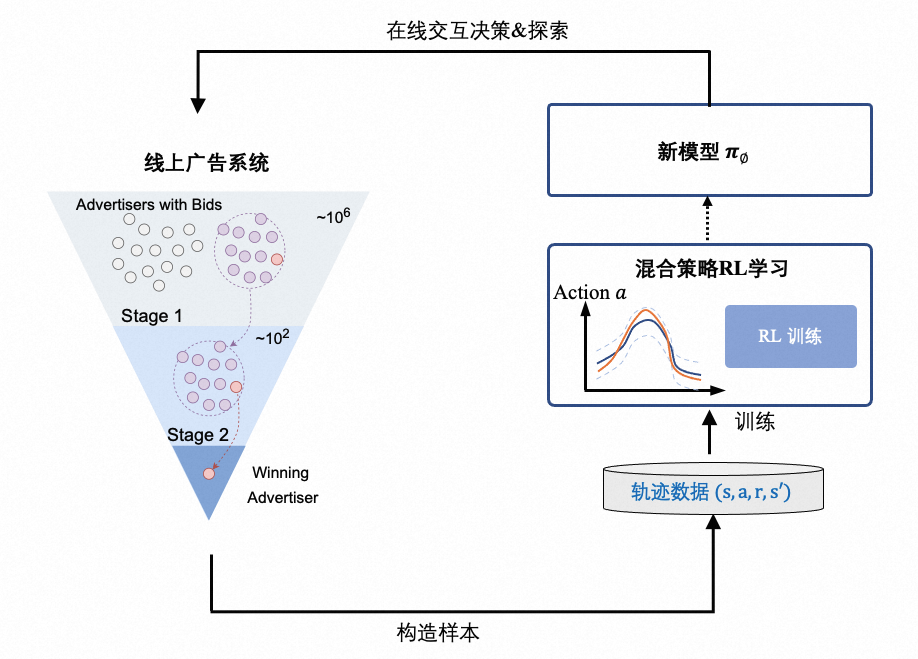
图 8:Online RL-based Bidding 训练模式,与前两种模式的差别在于能够和环境进行直接交互学习
[13]提出了可持续在线强化学习(SORL),与在线环境交互的方式训练自动出价策略,较好解决了环境不一致问题。SORL 框架包含探索和训练两部分算法,基于 Q 函数的 Lipschitz 光滑特性设计了探索的安全域,并提出了一个安全高效的探索算法用于在线收集数据;另外提出了 V-CQL 算法用于利用收集到的数据进行离线训练,V-CQL 算法通过优化训练过程中 Q 函数的形态,减小不同随机种子下训练策略表现的方差,从而提高了训练的稳定性。
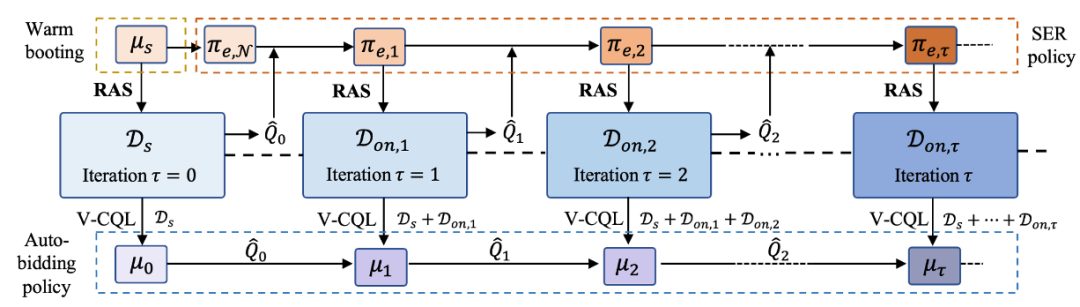
图 9:SORL 的训练模式
在这一阶段中,不断思考问题本质,提出可行方案从而使得和在线环境进行交互训练学习成为可能。
✪ 2.1.2 引领生成式 Bidding 的新时代(AIGB)
ChatGPT 为代表的生成式大模型以汹涌澎湃之势到来。一方面,新的用户交互模式会孕育新的商业机会,给自动出价的产品带来巨大改变;另一方面,新的技术理念和技术范式也会给自动出价策略带来革命性的升级。
我们在思考生成式模型能够给自动出价策略带来什么?从技术原理上来看,RL 类方法基于时序差分学习决策动作好坏,在自动出价这种长序列决策场景下会有训练误差累积过多的问题。
因此,我们提出了一种基于生成式模型构造的出价策略优化方案(AIGB - AI Generative Bidding)[14]。与强化学习的视角不同,如图 9 所示,AIGB 直接关联决策轨迹和回报信息,能够避免训练累积,更适合长序列决策场景。

图 10:Generative Bidding 相比 RL-based Bidding 模式能够避免训练误差累积,更适合长序列决策场景
从生成式模型的角度来看,我们可以将出价、优化目标和约束等具备相关性的指标视为一个联合概率分布,从而将出价问题转化为条件分布生成问题。
图 10 直观地展示了生成式出价模型的流程:在训练阶段,模型将历史投放轨迹数据作为训练样本,以最大似然估计的方式拟合轨迹数据中的分布特征。这使得模型能够自动学习出价策略、状态间转移概率、优化目标和约束项之间的相关性。在线上推断阶段,生成式模型可以基于约束和优化目标,以符合分布规律的方式输出出价策略。
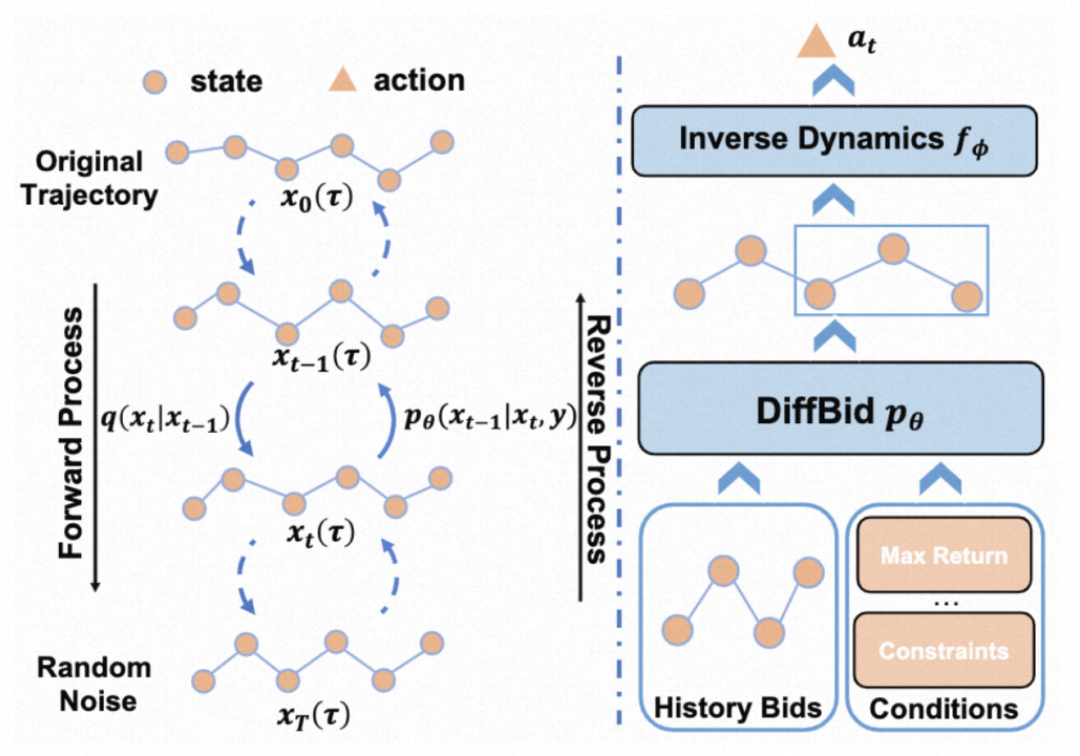
图 11:AIGB 的训练和预测算法
AIGB 基于当前的投放状态信息以及策略生成条件输出未来的投放策略,相比于以往的 RL 策略输出单步 action,AIGB 可以被理解为在规划的基础上进行决策,最大程度地避免分布偏移和策略退化问题,从而更适合长序列决策场景。这一优点有利于在实践中进一步减小出价间隔,提升策略的快速反馈能力。
与此同时,基于规划的出价策略也具备更好的可解释性,能够帮助我们更好地进行离线策略评估,方便专家经验与模型深度融合。另外,我们也还在进一步探索,是否可以把竞价领域知识融入到大模型中并帮助出价决策。
从「动作判别式」决策 到「轨迹生成式」决策 ,朝着超生成式 Bidding 的新时代大踏步迈进!
2.2 副线:百花齐放,更全面的出价决策技术
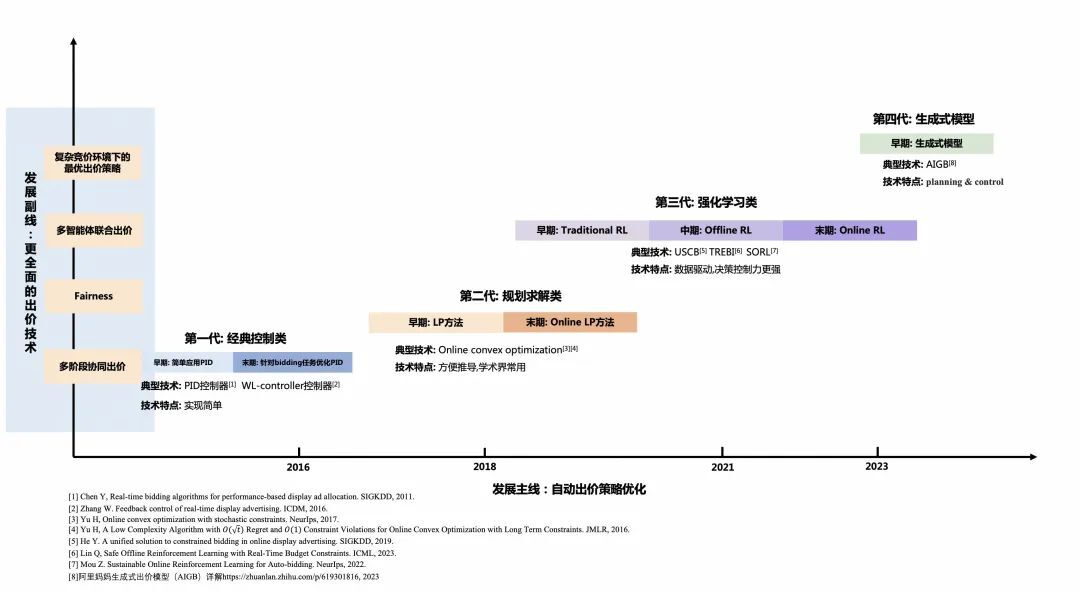
图 12:发展副线:更全面的业务实际场景的特性优化
除了更强的决策能力外,在实际场景中还会针对业务特点做更多的优化,这里介绍 3 个典型的研究技术点:
复杂的竞价环境下的最优出价策略
出价形式化建模依赖对竞价环境的假设,不同的假设下推导出来的出价公式是不同的。以 MaxReturn 计划为例,出价形式为𝒃𝒊𝒅=α*𝒑𝒄𝒖𝒓,其中α一个粗粒度与请求无关的参数,在简单竞价环境下(GSP 单坑下)这种出价形式是理论最优的。而在实际工业界竞价环境是非常复杂的:多坑、带保留价的机制或其他复杂机制,当前的出价策略并非最优。学术界和工业界针对这一问题提出了不少方法,大概分为 2 类:1)对竞价环境做进一步的假设(比如多坑)推导出闭式解,并进行求解[18];2)基于数据驱动的方法,在基础价格上结合当前流量的信息(如 Winning Price)等进行微调,比如 Bid Shading 类方法[17][19] 。
多智能体联合出价
在线广告本质上是一个多智能体竞价系统。通常情况下每一个自动出价智能体求解一个独立的优化问题,而将其他智能体出价的影响隐式地建模为环境的一部分。这种建模方式忽略了在线广告的动态博弈,即最终的拍卖结果取决于所有智能体的出价,且任一智能体的策略的改变会影响到其他所有智能体的策略。因此若不做协调,则所有智能体会处于一个无约束状态,进而降低系统的效率。典型的工作包括[7][11][12]都是针对线上环境的多智能体问题进行求解,面对线上智能体个数众多(百万级),通过广告主进行聚类等方式,把问题规模降低到可求解的程度。
Fairness
不同行业的广告主在广告投放时面临的竞价环境也是不同的,当前广泛采用的统一出价策略可能使得不同广告主的投放效果存在较大的差异,尤其是对小广告主来说,训练效果会受到大广告主的影响,即“Fairness”问题。典型的工作包括[16]将传统的统一出价策略拓展为多个能够感知上下文的策略族,其中每个策略对应一类特定的广告主聚类。这个方法中首先设计了广告计划画像网络用于建模动态的广告投放环境。之后,通过聚类技术将差异化的广告主分为多个类并为每一类广告主设计一个特定的具有上下文感知能力的自动出价策略,从而实现为每个广告主匹配特定的个性化策略。
两阶段协同出价
为平衡行业在线广告的优化性能和响应时间,在线工业场景经常会采用两阶段级联架构。在这种架构下,自动出价策略不仅需要在精竞阶段(第二阶段)进行传统的竞拍,还必须在粗竞阶段(第一阶段)参与竞争才能进入精竞阶段。
现有的工作主要集中在精竞阶段的拍卖设计和自动出价策略上,而对粗竞阶段的拍卖机制和自动出价策略研究还不够充分,这部分最主要的挑战在于粗竞阶段的广告量级会比精竞阶段多了近百倍,且自动出价依赖的流量价值预估(如 PCVR)比精竞阶段准度差,因此如何设计更大规模且能够应对不确定性预估值下的出价策略是这个方向主要研究的问题,而且还需要研究两阶段下的拍卖机制设计以引导自动出价正确报价。在这个方向上,我们依赖强大的工程基建能力上线了全链路自动出价策略,显著提升了广告主的投放效果;并设计了适用于两阶段的拍卖机制[33]。
三、拍卖机制设计也是一个决策问题
拍卖机制是对竞争性资源的一种高效的市场化分配方式,具有良好博弈性质的拍卖机制在互联网广告场景下可以引导广告主的有序竞争,从而保证竞价生态的稳定和健康。经典拍卖机制如 GSP、VCG 由于其良好的博弈性质以及易于实现的特点使得其在 2002 年前后开始被互联网广告大规模的使用。

图 13:在线广告的拍卖机制的示意图
十几年过去,互联网广告环境已经发生了巨大的改变,与经典静态拍卖机制的假设相比,现在的广告主营销目标多元、策略行为复杂,且机制的优化目标不再是单一的收入或者社会福利,需要将媒体、广告主、广告平台的利益考虑在内统一优化。而在一个智能化的广告系统中,拍卖机制需要根据系统中参与方的行为变化而调整自己的策略行为,即拍卖机制设计也是一个决策问题。因此如何结合互联网海量数据的优势去设计更符合广告主行为模式并贴近业务需求的智能拍卖机制迫在眉睫。
从经济学视角看,最优广告拍卖设计可以看作一个优化决策问题:最大化综合目标(收入、用户体验等),同时需要满足经济学性质保证,最典型的是激励相容性(Incentive Compatibility, IC)和个体理性(Individual Rationality, IR)的约束。IC 要求广告主真实报价总是能最大化其自身效用,而 IR 要求广告主付费不超过其对广告点击的真实估值,这样该机制就可以优化出稳定的效果。
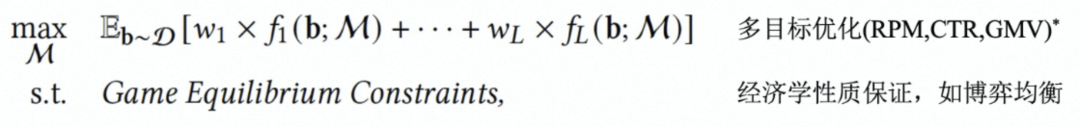
优化拍卖机制需要解决如下问题:
●机制性质如何满足:需要一种简洁的数学形式表达机制需要满足的博弈性质,并将其融入到机制的优化过程中。
●如何面向实际后验效果优化:工业界中很多优化目标指标难以得到精确解析形式(例如成交额、商品收藏加购量等),如何通过真实反馈的方式优化机制也是需要考虑的。
3.1 主线:飘然凡尘,从只远观到深度优化的拍卖机制
从经典的拍卖机制开始,如何通过数据化 &智能化提升拍卖机制的效果是发展主线,我们参考了业界大量的公开的正式文献,并结合阿里妈妈自身的技术发展,勾勒出拍卖机制的发展演进脉络。
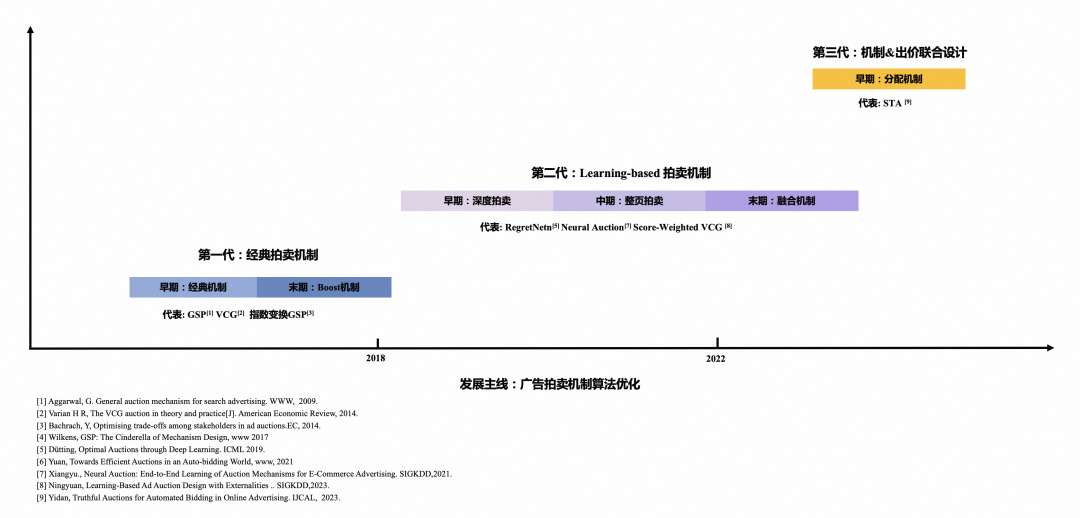
图 14:广告拍卖机制的发展主线:深度优化
整体而言可以划分为 4 个阶段:
●第一代:经典拍卖机制
经典的 GSP[23]、VCG[24]在互联网场景大规模落地后,针对场景特点的优化主要集中在 2 方面:1). 提升平台收入,最典型的是 Squashing[25]和保留价 。2). 多目标优化能力,通过在排序公式中引入更多的项来优化多目标,最典型的是 Ugsp。这些机制的分配和扣费形式相对清晰,所以关于他们的激励性质也大量被研究。
●第二代:Learning-based 拍卖机制
随着深度学习 &强化学习的蓬勃发展,大家开始探索将深度学习/强化学习引入到拍卖机制设计中,学术界典型的工作包括 RegretNet[26]、RDM[41]等,阿里妈妈结合工业界的场景特点,先后设计出 Deep GSP[31]、Neural Auction[32]、Two-Stage Auction[33]等机制,这些机制都借助了深度网络强大的学习能力,提升拍卖机制的优化效果。
●第三代:拍卖机制 &自动出价联合设计
随着自动出价能力的广泛应用,广告主竞价方式相较于之前有了大幅度的改变,广告主向平台提交高层次的优化目标和约束条件,然后由出价代理代表广告主在每次广告拍卖中做出详细的出价决策。对于广告主来说,平台需要把出价和拍卖机制看成一个整体联合设计,典型的工作包括[36]。
为了让大家有更好的理解,我们以阿里妈妈的实践为基础,重点讲述下智能拍卖机制在工业界的落地。
✪ 3.1.1 一相逢便胜却无数:当拍卖机制遇到智能化
惊艳登场:可 Learning 的拍卖机制
自 2019 年开始,学术界开始将深度学习 &强化学习引入到机制设计中,如 RegretNet[26]、RDM[41]等,他们通过引入深度网络强大的学习能力,提升拍卖机制的优化效果,为拍卖机制的发展开辟了一条新的道路。遗憾的是,这些工作都做了很强的理论假设如广告主个数固定等,没有看到在工业界大规模落地的实践。因此,我们开始思考,是否能够针对以上问题设计新型的面向多目标优化的广告拍卖机制,并能够结合工业界海量数据的优势,通过深度网络的强大学习能力来解决广告系统场景下的多目标优化问题。
我们提出一种基于深度神经网络的拍卖机制 Deep GSP[31]。Deep GSP 延续 GSP 的二价扣费机制,并通过深度网络提升其分配能力。不同于经典的广告拍卖机制,其能够通过深度网络的学习实现任意给定目标的优化,整个优化过程使用深度强化学习中确定性策略梯度算法实现。
我们对 Deep GSP 的模式进行了思考:其采用 GSP-Style 的机制设计模式,通过深度网络为每个广告计算出一个分数,排序后决定分配和扣费结果。训练时基于最终效果为参与竞价的每一条广告样本分配奖赏并采用强化学习的方法驱动模型参数更新。从机制的角度,求解最优分配问题是一个全局视角的组合优化问题,而 Deep GSP 是建模在广告粒度,如何把整体的效果分摊到每个广告上,即信用分配问题,会对训练产生很大的影响。
但排序是一个不可微的操作,在模型训练的时候无法直接像监督学习那样通过样本标签计算的 loss 反向梯度传导优化模型参数。因此我们又提出了一种新的拍卖机制 Neural Auction[32],以一种可微的计算形式来表达"排序"算子,从而能够与梯度下降训练方法结合,实现端到端优化,
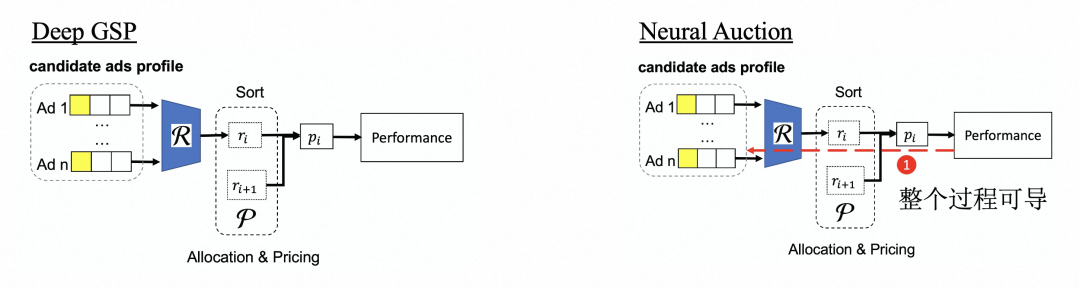
图 15:工业界 Learning-based 拍卖机制 2 个典型工作:Deep GSP 和 Neural Auction
值得注意的是,我们的工作也夯实了工业界智能拍卖机制(Learning-based Mechanism Design)方向,并得到了业界的广泛关注,其中所学术沉淀被国际会议 Meta Reviewer 和引用者使用开创新方向("contributes a new perspective to the literature")和首次("the first attempts")等方式评价。
持续发力:整页拍卖(考虑外部性)机制
广告拍卖机制的效果依赖于广告展示商品点击率(CTR)的精确预估,但在实际场景中,商品展示点击率会受到相互之间的外部性影响。这一现象在近年来开始受到学术界和工业界的广泛关注。然而,传统的广告拍卖通常简化或忽略了外部性。例如,广泛使用的 GSP 拍卖机制基于可分离 CTR 模型[37],假定广告的点击率只由广告内容和位置决定,而忽略了其他商品的影响。因此传统的广告拍卖机制在考虑外部性时不再适用。
但考虑外部性影响对于最优广告拍卖的设计带来了许多挑战。由于广告的点击率受到上下文中其他商品的影响,即使对分配进行微小修改,也可能导致广告拍卖的预期收入发生复杂的变化。一般而言,对于外部性结构不作具体假设时,计算具有最大社会福利的分配方案是 NP 困难的。因此,如何设计高效实用的分配算法是一个非平凡的问题。另一方面,由于外部性影响的存在,拍卖机制更难控制每个广告主得到的效用,因此 IC 和 IR 等约束更难满足。
我们的工作[28]提出一个数据驱动的广告拍卖框架,以在考虑外部性的情况下实现收入最大化,同时确保满足 IC 和 IR 约束。结合理论分析提出 Score-Weighted VCG 框架,将最优拍卖机制的设计拆解为一个单调得分函数的学习和一个加权福利最大化算法的设计。基于这一框架又提出一个实用的实现方案,利用数据驱动的模型实现最优拍卖机制。通过完备的理论证明了该框架在各种感知外部性的点击率模型下都能产出满足激励兼容和个体理性的近似最优广告拍卖。

图 16:Score-Weighted VCG:考虑外部性的整页拍卖机制
一片蓝海:融合机制设计
融合阶段是工业界一个非常关键的过程。在搜索和信息流等场景中,广告结果与自然结果分别由广告系统和推荐系统产生,融合机制对候选的广告和自然结果进行合并、筛选、排列,决定最终向用户展示的商品列表。
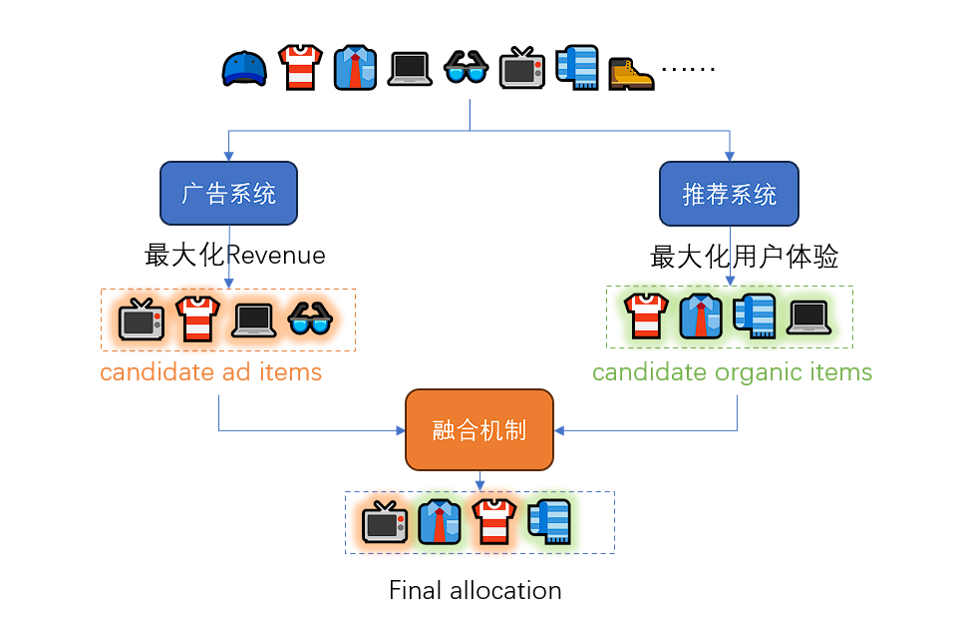
图 17:融合阶段是工业界系统中一个非常关键的过程
同时融合也是一个机制设计问题。广告结果和自然结果的分配不再是独立的,通过综合考虑广告和自然结果排列方式来优化用户体验和平台收入。另外,一个商品可能同时作为广告结果和自然结果的候选出现,这是因为广告系统和推荐系统都倾向于选择与用户偏好或搜索关键词较为匹配的商品。在此情形下,通常不允许将一个商品作为广告和自然结果同时展示给用户,导致对于广告结果和自然结果的分配不再是独立的,这也会导致广告主对广告的付费动机出现激励问题,因此必须重新审视广告与自然结果融合时的机制设计问题。
定坑可以理解为最经典的混排机制,自然结果优化用户体验,广告结果采用传统的机制如 GSP 来优化平台收入。混排通过经典的线性加权把多目标优化问题转换成一个单目标(用户体验和广告平台加权和)的优化问题。所有商品都按给定的排序公式进行打分,按分数从大到小逐个放置到所有坑位里面,并用 uGSP 进行扣费。但因外部性的普遍存在,该方式通常无法得到最优解。
业界普遍在探索的是广告和自然整页优化方式,基于组合优化思想来解该多目标优化问题,通常隐式或者显式地对外部性进行建模,目前妈妈和业界都有一些典型的优化工作[38][39],在机制性质上还有很多的研究空间。
✪ 3.1.2 浑然一体:自动出价和拍卖机制的联合设计
随着自动出价产品的广泛应用,现在广告主参竞的方式相较于之前有了大幅度的改变:广告主向平台提交其高层次的优化目标和约束条件,然后由机器学习算法驱动的出价代理代表广告主在每次广告拍卖中做出详细的出价决策。通过自动出价工具,广告主从全局角度针对其经济约束优化其整体广告目标。对于广告主来说,自动出价和拍卖机制整体才是平台真正的机制。
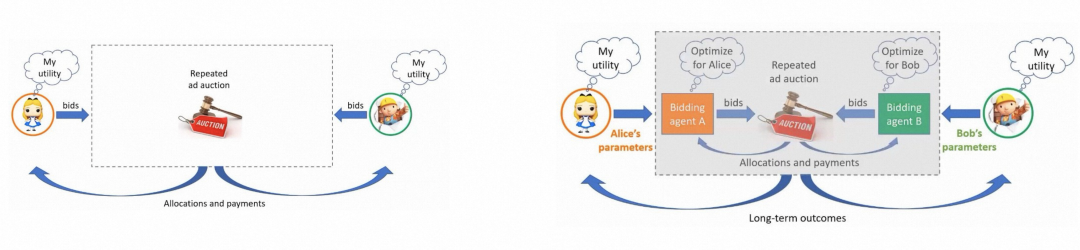
图 18:在自动出价体系下,广告主与广告平台的博弈关系已发生根本改变
在自动出价的新广告范式中,我们需要重新审视经典的拍卖机制模型是否仍然适用。由于可以获取有关广告主与用户之间互动的历史数据,平台可以估计用户的潜在行为(如点击和转化),这些行为可以被视为广告主对物品的估值。在自动出价中,广告主的私有信息实际上是其在整个广告投放过程的约束条件。这些与经典拍卖截然不同的新特点需要对应的新的广告拍卖模型,以激励广告主真实地上报其高层次的私有约束。
我们的工作[36]提出了一类基于排序函数的激励兼容机制,关键思想是采用提前确定的排序函数为每个广告主进行排序,并将阈值 ROI 设计为赢得足够多的竞价机会以消耗完预算的最大 ROI。在该机制中,给定广告主上报的预算和 ROI,首先基于排序函数计算不同广告主对于每个物品的虚拟出价。只要这些排序函数在 ROI 上是单调递减的,保证最终的拍卖机制是满足 DSIC 与 IR 的。接下来,将每个物品分配给排序分数最高的广告主,并根据第二高的排序函数计算赢得此物品所需要的 ROI。为了保证约束的 IC,我们使用前面提到的基本规则来计算关键 ROI,即赢得足够多的物品以消耗完预算的最大 ROI,其中使用关键 ROI 作为实际 ROI 来计算支付。这是一个对此类问题的初步尝试,未来还需要进一步深入思考。
3.2 副线:多样的广告主行为建模
广告主行为建模是拍卖机制设计的基础,现有的关于 VCG 和 GSP 的分析主要建立在拟线性效用模型上,也被称为效用最大化广告主(Utility Maximizer,UM),即广告主的目标是优化其分配的价值和扣费之间的差值。
雅虎公司的研究人员 Wilkens、Cavallo 和 Niazadeh 为广告主提出了另一个模型,称为价值最大化广告主(Value Maximizer,VM),该模型将分配的价值作为广告主的首要目标,将扣费作为其次的目标,只有当价值相同时才偏好扣费更少的结果。这些设定都接近于单轮拍卖形式下广告主的行为模式,但在广告主已经开始使用自动竞价(Auto-bidding)工具,利用自动竞价工具,广告主只需要设置高层次的约束条件,并由出价代理进行竞价,这与传统的机制存在非常大的差异。
因此,核心问题是使用不同的机制,在广告主与代理间的交互完成后,会得到怎样的博弈结果?什么机制对平台方或社会福利更好这些都是要回答的问题。

图 19:广告主行为建模的研究方向
四、结语
雄关漫道真如铁,而今迈步从头越。历经几代阿里妈妈同学坚持不懈的努力,在自动出价决策技术上,从推动经典强化学习类算法在工业界大规模落地,到持续革新提出 Offline RL-based Bidding、Online RL-based Bidding 等适应工业界特点的新算法,再到提出 AIGB 迈入生成式 Bidding 的新时代;在拍卖机制设计上,从只远观的高深领域,到可 Learning 的决策问题,再与工业界深入结合的 Two-Stage Auction、整页拍卖、融合机制等,以及未来的 Auto-bidding 和拍卖机制的联合优化。
一路走来,我们持续推动业界广告决策智能技术的发展,并秉承开放共赢,把我们的工作以学术化沉淀的方式实现对学术界研究的反哺。希望大家多多交流,共赴星辰大海。
五、了解我们&加入我们
核心关键词:超核心业务、大规模 RL 工业界落地、决策智能大模型、技术引领业界、团队氛围好!
「智能广告平台」基于海量数据,优化阿里广告技术体系,驱动业务增⻓,并推动技术持续走在行业前沿:精准建模以提升商业化效率,创新广告售卖机制和商业化模式以打开商业化天花板,研发最先进的出价算法帮助商家获得极致的广 告投放效果和体验,设计和升级算法架构以支撑国内顶级规模的广告业务稳健 &高效迭代等。
超大业务体量和丰富商业化场景,赋能我们在深度学习、强化学习、机制设计、投放策略、顶层业务/技术上的视野和判断极速成⻓并沉淀丰厚;超一线站位也让我们在“挖掘有价值 &有挑 战新问题,驱动产品技术能力创新等”方面有得天独厚优势。在此欢迎聪明靠谱小伙伴加入(社招、校招、实习生、高校合作、访问学者等),简历请发至 zhangzhilin.pt@alibaba-inc.com。
六、参考文献
http://alibabavideocloud.mikecrm.com/YRXNCGb