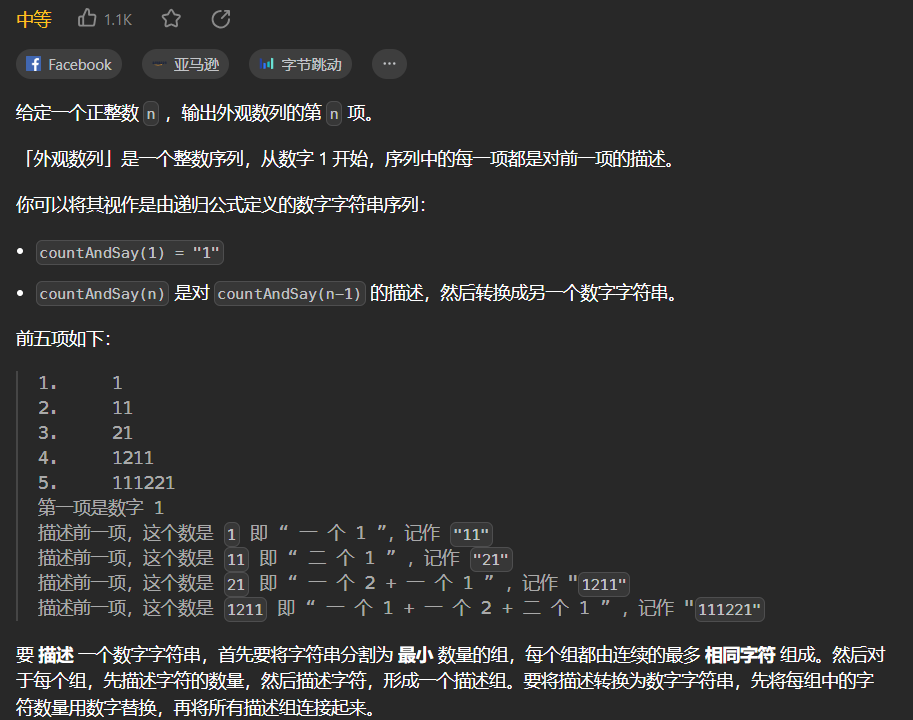
引言
基本全局命令
Redis的key的操作命令如图所示:
| 语法 | 功能 |
| set key value | 把key和value存储进去 |
| get key | 根据key来去取value |
| keys pattern | 查看数据库所有符合pattern的key |
| exists key [key…] | 判断key是否存在 |
| expire key seconds | 设置 key 的生存时间,超过时间,key 自动删除。单位是秒。 |
| ttl key | 以秒为单位,返回 key 的剩余生存时间(ttl: time to live) |
| type key | 查看 key 所存储值的数据类型 |
| del key [key…] | 删除存在的 key,不存在的 key 忽略。 |
set
set key value:把key和value存储进去
例如:set key1 1
![]()
get
get key : 根据key来去取value
例如:get key1
![]()
KEYS
keys pattern:用来查看匹配规则的key
具体的匹配规则表示如下:
- keys h?llo : “?”表示匹配任意一个字符
- keys h*llo : “*”表示匹配0个或者多个任意字符
- keys h[abcd]llo : "[]"表示只能匹配内部写的固定格式
- keys h[^e]llo : "^e"表示只排除e,其他全部匹配
- keys h[a-e]llo : "a-e"表示只匹配 a-e 之间的包括e和e
该命令的时间复杂度为:O(N),因为他需要遍历所有的 key,返回值为:所有匹配的 key
EXISTS
exists key [key…]: 判断key是否存在
例如:

时间复杂度为:O(N),官方文档上写的是O(N),事实上这里的 N 是你写了几个。
其实我们大可以不用一个个去查询,我们可以将多个key 一起查询,时间复杂度的 N 就是这里查询几个,查两个就是O(2)例如:

del
del是 delete 的缩写,
del key [key…]:删除存在的 key,不存在的 key 忽略。
时间复杂度为:O(N),这个 N 指的和上述一样,同样它们都是可能一次删除多个 key;
返回值为:删除成功的个数,key 不存在即:返回 0
例如:

EXPIRE
expire: 给指定的 key 设置过期时间(key 存活时间超出这个指定的值,就过期了)单位是秒
举例:expire key (seconds) 单位:秒
举例:pexipire key 单位:毫秒
来看看实际操作:

设置一个key,设置一个过期时间,一旦到了过期时间键值对就自动删除了。
TTL
TTL key:以秒为单位,返回 key 的剩余生存时间(ttl: time to live)
时间复杂度:O(1)返回值:剩余过期时间。-1 表⽰没有关联过期时间,-2 表⽰ key 不存在。


图二,我们并没有关联过期时间,就会返回 -1
TYPE
type key:查看 key 所存储值的数据类型
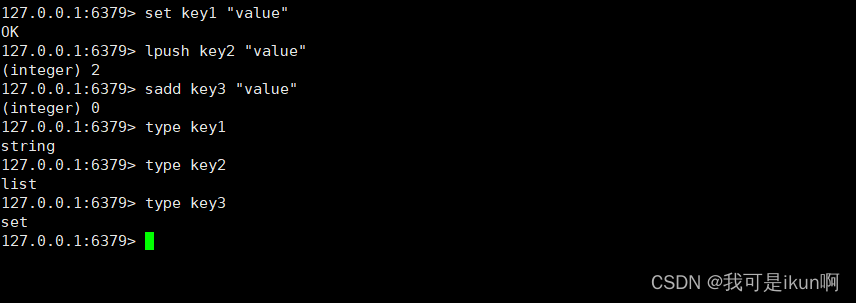
具体的类型这里先不讨论。
这些就是最最基本的几个命令了,没事的时候可以多练,熟能生巧。
这里只是抛砖引玉,为后面五种数据结构的介绍做一个热身。
Redis 的五种数据结构
五种数据结构如图所示:

简易描述:
- 字符串:Redis的字符串数据结构是由SDS(Simple Dynamic String,简单动态字符串)实现的。SDS是Redis中所有非数字键的底层实现。
- 列表:Redis的列表数据结构是由双向链表实现的。这个链表在内存中分为两部分,一部分是“统筹部分”,指向链表的头部和尾部,以及链表的长度;另一部分是“具体实施方”,是一目了然的双向链表结构,每个节点都有前驱和后继。
- 哈希:Redis的哈希数据结构底层是由字典实现的。在Redis中,哈希表被称为“字典”,其元素是键值对。
- 集合:Redis的集合数据结构底层是由哈希表实现的。集合在Redis中被称为“set”,其元素是无序的,且不允许重复。
- 有序集合:Redis的有序集合数据结构底层也是由哈希表实现的。有序集合在Redis中被称为“zset”,其元素是唯一的,但可以重复。每个元素都有一个相关的分数,这个分数用于在有序集合中按分数从小到大排序元素。
Redis 数据结构及内部编码:
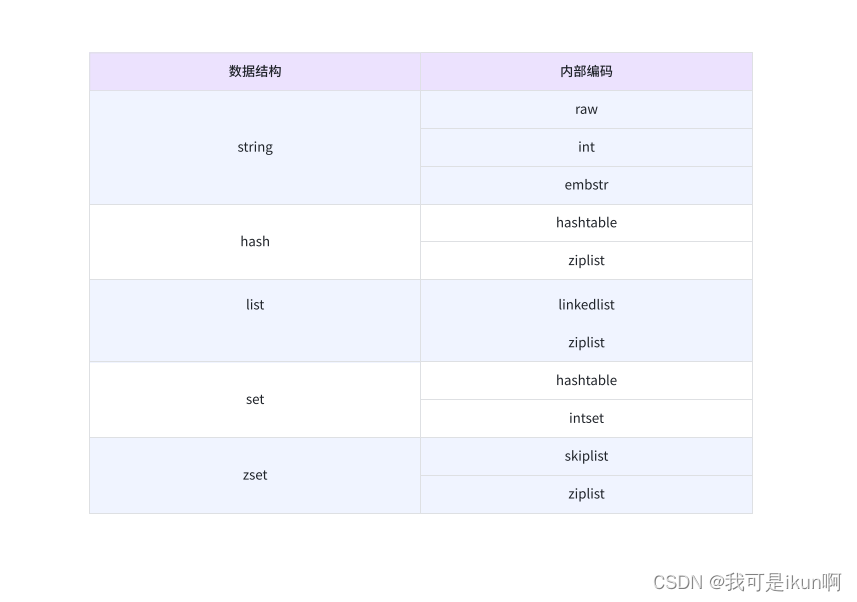
可以看到每种数据结构都有⾄少两种以上的内部编码实现,例如 list 数据结构包含了 linkedlist 和 ziplist 两种内部编码。同时有些内部编码,例如 ziplist,可以作为多种数据结构的内部实现,可以通 过 object encoding 命令查询内部编码:
例如:

可以看到 hello 对应值的内部编码是 embstr,键 mylist 对应值的内部编码是 ziplist。Redis 这样设计有两个好处:
String 类型
key都是固定的字符串,value实际上会有多种类型
redis 中的字符串,直接按照二进制数据的方式存储的(不做任何编码转换,存的是啥,取出来就是啥):可以是文本、整数、JSON、xml、二进制数据(图片、视频、音频)
String 类型中的关键命令
命令如下:
- SET key value:设置指定键的值为指定字符串。
- GET key:获取指定键对应的值。
- APPEND key value:将指定字符串追加到指定键的值末尾。
- INCR key:将指定键的值加1。
- DECR key:将指定键的值减1。
- INCRBY key increment:将指定键的值加上指定的整数。
- DECRBY key decrement:将指定键的值减去指定的整数。
- STRLEN key:获取指定键值的长度。
- SETNX key value:如果指定键不存在,则设置键的值为指定字符串。
- MSET key1 value1 key2 value2 ...:设置多个键值对。
- MGET key1 key2 ...:获取多个键值对的值。
- GETSET key value:先获取指定键的值,然后设置键的值为指定字符串。
- SETEX key seconds value:设置键的值为指定字符串,并设定生存时间(单位为秒)。
- PSETEX key milliseconds value:设置键的值为指定字符串,并设定生存时间(单位为毫秒)。
- MSETNX key1 value1 key2 value2 ...:如果所有指定的键都不存在,则设置多个键值对。
- STRALGO LCP key1 key2 ...:计算多个字符串的最长公共前缀。
这里就不一一举例了,我就简单介绍几个重点的,看不懂的可以去看一看官方文档:
Redis官方文档
在这里查询 String 类型即可,很多时候,我们还是得学会自己查看文档,未来到了公司也是一样,不可能永远都有中文文档查看的;不懂得单词使用翻译软件查一下。
我这里就简单介绍几个:
SET:
SET key value [expiration EX seconds|PX milliseconds] [NX|XX]
- EX seconds⸺使⽤秒作为单位设置 key 的过期时间。
- PX milliseconds⸺使⽤毫秒作为单位设置 key 的过期时间。
- NX ⸺只在 key 不存在时才进⾏设置,即如果 key 之前已经存在,设置不执⾏。
- XX ⸺只在 key 存在时才进⾏设置,即如果 key 之前不存在,设置不执⾏。
注意:由于带选项的 SET 命令可以被 SETNX 、 SETEX 、 PSETEX 等命令代替,所以之后的版本中,Redis 可能进⾏合并。
返回值:
-
如果设置成功,返回 OK。
-
如果由于 SET 指定了 NX 或者 XX 但条件不满⾜,SET 不会执⾏,并返回 (nil)。
如图:

MSET
一次性设置多个 key 的值
语法:
MSET key value [key value ...]
keys * 就是查询所有的 键,“ * ” 表示一个通配符。
很多正常使用的时候并非一个键一个键去操作,那么效率会非常低,这时候:MSET 就排上大用场了。
有 mset 也就有 mget,一次获取多个键
MGET
一次性处理多个get
这个命令,现在过过瘾就好,工作中千万不要使用,公司里,可能有非常非常非常非常多的键,使用一次这个命令,十分有可能将公司的机器给干崩
就像是 MySQL 中的 select * 命令。
内部编码
字符串类型的内部编码有三种:
-
int:8 个字节的⻓整型。
-
embstr:⼩于等于 39 个字节的字符串。
-
raw:⼤于 39 个字节的字符串。
redis 会根据当前值的类型和长度动态决定使用哪种内部编码实现的。
具体这么确定使用哪个呢?
字符串长度小于等于 39 个字节的字符串使用 “ embstr ”,大于 39 个字节的字符使用 “ raw ”;
如果在面试中,千万不要说 39 这个数字,事实上在不同的业务场景都是不同的(解释不清楚39是哪来的)
具体如何解决?
1. 先看 redis 是否提供了相应的配置文件,在配置文件中修改
2. 如果没有提供,就需要对 redis 的源码进行魔改
String典型使用场景
这是比较经典的缓存使用场景,其中 Redis 作为缓冲层,MySQL 作为存储层,绝大部分请求的数据都是从 Redis 中获取,由于 Redis 具有支撑高并发的特性,所以缓存通常能起到加速读写和降低后端压力的作用。
大致流程:
客户端每次读取请求都发送给 Redis,如果 Redis 的 key 有值就直接返回给客户端;如果 Redis 没有这个 key ,再由 Redis 将请求发送给 MySQL ,MySQL 返回的值将保留在 Redis 中。
计数(Counter)功能
许多应⽤都会使⽤ Redis 作为计数的基础⼯具,它可以实现快速计数、查询缓存的功能,同时数 据可以异步处理或者落地到其他数据源。例如视频⽹站的视频播放次数可以使⽤ Redis 来完成:⽤⼾每播放⼀次视频,相应的视频播放数就会⾃增 1。实际中要开发⼀个成熟、稳定的真实计数系统,要⾯临的挑战远不⽌如此简单:防作弊、按照不同维度计数、避免单点问题、数据持久化到底层数据源等。
共享会话(Session)
⼀个分布式 Web 服务将⽤⼾的 Session 信息(例如⽤⼾登录信息)保存在各⾃ 的服务器中,但这样会造成⼀个问题:出于负载均衡的考虑,分布式服务会将⽤⼾的访问请求均衡到 不同的服务器上,并且通常⽆法保证⽤⼾每次请求都会被均衡到同⼀台服务器上,这样当⽤⼾刷新⼀ 次访问是可能会发现需要重新登录,这个问题是⽤⼾⽆法容忍的。为了解决这个问题,可以使⽤ Redis 将⽤⼾的 Session 信息进⾏集中管理,在这种模式下,只要保证 Redis 是⾼可⽤和可扩展性的,⽆论⽤⼾被均衡到哪台 Web 服务器上,都集中从 Redis 中查询、更新 Session 信息
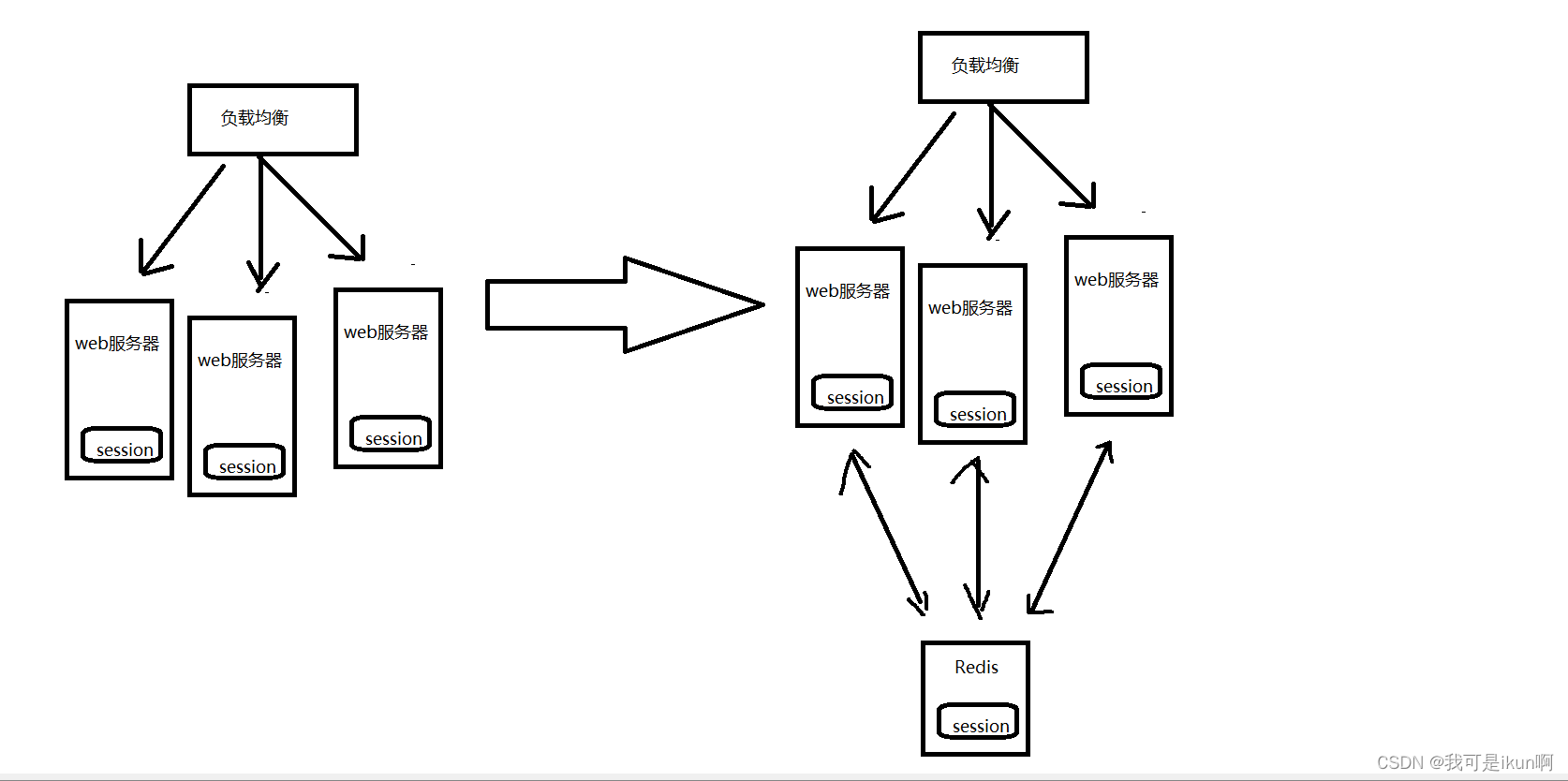
如上图所示。
手机验证码
很多应⽤出于安全考虑,会在每次进⾏登录时,让⽤⼾输⼊⼿机号并且配合给⼿机发送验证码, 然后让⽤⼾再次输⼊收到的验证码并进⾏验证,从⽽确定是否是⽤⼾本⼈。为了短信接⼝不会频繁访 ,会限制⽤⼾每分钟获取验证码的频率,例如⼀分钟不能超过 5 次
String 发送验证码(phoneNumber) {
key = "shortMsg:limit:" + phoneNumber;
// 设置过期时间为 1 分钟(60 秒)
// 使⽤ NX,只在不存在 key 时才能设置成功
bool r = Redis 执⾏命令:set key 1 ex 60 nx
if (r == false) {
// 说明之前设置过该⼿机的验证码了
long c = Redis 执⾏命令:incr key
if (c > 5) {
// 说明超过了⼀分钟 5 次的限制了
// 限制发送
return null;
}
}
// 说明要么之前没有设置过⼿机的验证码;要么次数没有超过 5 次
String validationCode = ⽣成随机的 6 位数的验证码();
validationKey = "validation:" + phoneNumber;
// 验证码 5 分钟(300 秒)内有效
Redis 执⾏命令:set validationKey validationCode ex 300;
// 返回验证码,随后通过⼿机短信发送给⽤⼾
return validationCode ;
}
// 验证⽤⼾输⼊的验证码是否正确
bool 验证验证码(phoneNumber, validationCode) {
validationKey = "validation:" + phoneNumber;
String value = Redis 执⾏命令:get validationKey;
if (value == null) {
// 说明没有这个⼿机的验证码记录,验证失败
return false;
}
if (value == validationCode) {
return true;
} else {
return false;
}
}哈希类型
所谓的哈希类型就是数据结构中的哈希表,只是这里又有些不同。
在 Redis 中,哈希类型是指值本⾝⼜是⼀个键值对结构,形如 key = "key",value = { {field1, value1 }, ..., {fieldN, valueN } }哈希类型中的映射关系通常称为 field-value,⽤于区分 Redis 整体的键值对(key-value),注意这⾥的 value 是指 field 对应的值,不是键(key)对应的值,请注意 value 在不同上下⽂的作⽤。
哈希类型中的关键命令
关键命令如下:
- HSET:向哈希表中添加一个字段和值。
- HGET:从哈希表中读取一个字段的值。
- HGETALL:从哈希表中读取所有字段和值。
- HDEL:从哈希表中删除一个或多个字段。
- HEXISTS:检查哈希表中是否存在指定的字段。
- HKEYS:获取哈希表中所有字段的名称。
- HVALS:获取哈希表中所有字段的值。
- HLEN:获取哈希表中字段的数量。
- HMSET:向哈希表中添加多个字段和值。
- HMGET:从哈希表中读取多个字段的值。
同样的这里也就不再一一介绍了,参考下列官方:
哈希类型的官方文档
内部编码
哈希的内部编码有如下两种:
-
ziplist(压缩列表):当哈希类型元素个数⼩于 hash-max-ziplist-entries 配置(默认 512 个)、 同时所有值都⼩于 hash-max-ziplist-value 配置(默认 64 字节)时,Redis 会使⽤ ziplist 作为哈 希的内部实现,ziplist 使⽤更加紧凑的结构实现多个元素的连续存储,所以在节省内存⽅⾯⽐ hashtable 更加优秀。
-
hashtable(哈希表):当哈希类型⽆法满⾜ ziplist 的条件时,Redis 会使⽤ hashtable 作为哈希 的内部实现,因为此时 ziplist 的读写效率会下降,⽽ hashtable 的读写时间复杂度为 O(1)。
举例:

当 field 个数超过 512 时,内部编码也会转换为 hashtable:这里就懒得一个个添加了
配置
- 可以在 redis.conf 文件中修改配置项 : hash-max-ziplist-entries 配置(默认512个)【当前哈希表中的元素超过多少,可以转换为 hashtable】
- 同样可以修改: hash-max-ziplist-value(默认64字节)【当前哈希表中的元素长度超过多少,可以转换为 hashtable】
使用场景
String 适合做缓存,相比于使用相⽐于使⽤ JSON 格式的字符串缓存⽤⼾信息,哈希类型变得更加直观,并且在更新操作上变得更灵活。
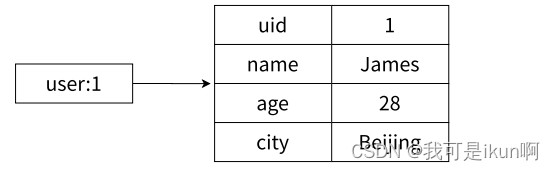
-
哈希类型是稀疏的,⽽关系型数据库是完全结构化的,例如哈希类型每个键可以有不同的 field,⽽关系型数据库⼀旦添加新的列,所有⾏都要为其设置值,即使为 null。
-
关系数据库可以做复杂的关系查询,⽽ Redis 去模拟关系型复杂查询,例如联表查询、聚合查询等基本不可能,维护成本⾼。